「行知」NLP新星:BERT的優雅解讀
- 2019 年 11 月 21 日
- 筆記
文章作者:陳桂敏(Derek) 騰訊 內容來源:IchbinDerek@公眾號 出品社區:DataFun 註:歡迎後台留言投稿「行知」專欄文章。
恰逢春節假期,研究了一下BERT。作為2018年自然語言處理領域的新星,BERT做到了過去幾年NLP重大進展的集大成,一出場就技驚四座碾壓競爭對手,刷新了11項NLP測試的最高紀錄,甚至超越了人類的表現,相信會是未來NLP研究和工業應用最主流的語言模型之一。本文嘗試由淺入深,為各位看客帶來優雅的BERT解讀。
NLP背景
BERT的應用舞台
NLP Natural Language Process,自然語言處理,是電腦科學、資訊工程以及人工智慧的子領域,專註於人機交互,特別是大規模自然語言數據的處理和分析。
除了OCR、語音識別,自然語言處理有四大類常見的任務。第一類任務:序列標註,譬如命名實體識別、語義標註、詞性標註、分詞等;第二類任務:分類任務,譬如文本分類、情感分析等;第三類任務:句對關係判斷,譬如自然語言推理、問答QA、文本語義相似性等;第四類任務:生成式任務,譬如機器翻譯、文本摘要、寫詩造句等。
GLUE benchmark General Language Understanding Evaluation benchmark,通用語言理解評估基準,用於測試模型在廣泛自然語言理解任務中的魯棒性。
BERT刷新了GLUE benchmark的11項測試任務最高記錄,這11項測試任務可以簡單分為3類。序列標註類:命名實體識別CoNNL 2003 NER;單句分類類:單句情感分類SST-2、單句語法正確性分析CoLA;句對關係判斷類:句對entailment關係識別MNLI和RTE、自然語言推理WNLI、問答對是否包含正確答案QNLI、句對文本語義相似STS-B、句對語義相等分析QQP和MRPC、問答任務SQuAD v1.1。雖然論文中沒有提及生成式任務,BERT核心的特徵提取器源於Google針對機器翻譯問題所提出的新網路框架Transformer,本身就適用於生成式任務。
語言模型的更迭
BERT之集大成
LM Language Model,語言模型,一串詞序列的概率分布,通過概率模型來表示文本語義。
語言模型有什麼作用?通過語言模型,可以量化地衡量一段文本存在的可能性。對於一段長度為n的文本,文本里每個單詞都有上文預測該單詞的過程,所有單詞的概率乘積便可以用來評估文本。在實踐中,如果文本很長,P(wi|context(wi))的估算會很困難,因此有了簡化版:N元模型。在N元模型中,通過對當前詞的前N個詞進行計算來估算該詞的條件概率。對於N元模型,常用的有unigram、bigram和trigram,N越大,越容易出現數據稀疏問題,估算結果越不準。此外,N元模型沒法解決一詞多義和一義多詞問題。

為了解決N元模型估算概率時的數據稀疏問題,研究者提出了神經網路語言模型,代表作有2003年Bengio等提出了的NNLM,但效果並不吸引人,足足沉寂了十年。在另一電腦科學領域機器視覺,深度學習混得風生水起,特別值得一提的是預訓練處理,典型代表:基於ImageNet預訓練的Fine-Tuning模型。影像領域的預處理跟現在NLP領域的預訓練處理思路相似,基於大規模影像訓練數據集,利用神經網路預先訓練,將訓練好的網路參數保存。當有新的任務時,採用相同的網路結構,載入預訓練的網路參數初始化,基於新任務的數據訓練模型,Frozen或者Fine-Tuning。Frozen指底層載入的預訓練網路參數在新任務訓練過程中不變,Fine-Tuning指底層載入的預訓練網路參數會隨著新任務訓練過程不斷調整以適應當前任務。深度學習是適用於大規模數據,數據量少訓練出來的神經網路模型效果並沒有那麼好。所以,預訓練帶來的好處非常明顯,新任務即使訓練數據集很小,基於預訓練結果,也能訓練出不錯的效果。
深度學習預訓練在影像領域的成果,吸引研究者探索預訓練在NLP領域的應用,譬如Word Embedding。2013年開始大火的Word Embedding工具Word2Vec,Glove跟隨其後。Word2Vec有2種訓練方式:CBOW和Skip-gram。CBOW指摳掉一個詞,通過上下文預測該詞;Skip-gram則與CBOW相反,通過一個詞預測其上下文。不得不說,Word2Vec的CBOW訓練方式,跟BERT「完形填空」的學習思路有異曲同工之妙。

一個單詞通過Word Embedding表示,很容易找到語義相近的單詞,但單一詞向量表示,不可避免一詞多義問題。於是有了基於上下文表示的ELMo和OpenAI GPT。
ELMo,Embedding from Language Models,基於上下文對Word Embedding動態調整的雙向神經網路語言模型。ELMo採用的是一種「Feature-based Approaches」的預訓練模式,分兩個階段:第一階段採用雙層雙向的LSTM模型進行預訓練;第二階段處理下游任務時,預訓練網路中提取出的Word Embedding作為新特徵添加到下游任務中,通過雙層雙向LSTM模型補充語法語義特徵。相比Word2Vec,ELMo很好地解決了一詞多義問題,在6個NLP測試任務中取得SOTA。

Transformer Google提出的新網路結構,這裡指Encoder特徵提取器。LSTM提取長距離特徵有長度限制,而Transformer基於self-Attention機制,任意單元都會交互,沒有長度限制問題,能夠更好捕獲長距離特徵。
GPT,Generative Pre-Training,OpenAI提出的基於生成式預訓練的單向神經網路語言模型。GPT採用的是一種「Fine-Tuning Approaches」的預訓練模式,同樣分兩個階段: 第一階段採用Transformer模型通過上文預測的方式進行預訓練;第二階段採用Fine-Tuning的模式應用到下游任務。GPT的效果同樣不錯,在9個NLP測試任務中取得SOTA。不過,GPT這種單向訓練模式,會丟失下文很多資訊,在閱讀理解這類任務場景就沒有雙向訓練模式那麼優秀。

BERT,Bidirectional Encoder Representations from Transformers,基於Transformer的雙向語言模型。同樣,BERT採用跟GPT一樣的「Fine-Tuning Approaches」預訓練模式,分兩個階段:第一階段採用雙層雙向Transformer模型通過MLM和NSP兩種策略進行預訓練;第二階段採用Fine-Tuning的模式應用到下游任務。有人戲稱:Word2Vec + ELMo + GPT = BERT,不過也並無道理,BERT吸收了這些模型的優點:「完形填空」的學習模式迫使模型更多依賴上下文資訊預測單詞,賦予了模型一定的糾錯能力;Transformer模型相比LSTM模型沒有長度限制問題,具備更好的能力捕獲上下文資訊特徵;相比單向訓練模式,雙向訓練模型捕獲上下文資訊會更加全面;等等。當然,效果才是王道,集大成者BERT拿了11項SOTA。

論文解讀
BERT原理
相關論文 2017年,Google發表《Attention Is All You Need》,提出Transformer模型; 2018年,Google發表《BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding》,提出基於Transformer的語言模型BERT。
在未來NLP領域的研究和應用,BERT有兩點值得被借鑒:其一,基於Transformer編碼器作特徵提取,結合MLM&NSP策略預訓練;其二,超大數據規模預訓練Pre-Training+具體任務微調訓練Fine-Tuning的兩階段模式。
1.特徵提取器
____________
Transformer Encoder,特徵提取器,由Nx個完全一樣的layer組成,每個layer有2個sub-layer,分別是:Multi-Head Self-Attention機制、Position-Wise全連接前向神經網路。對於每個sub-layer,都添加了2個操作:殘差連接Residual Connection和歸一化Normalization,用公式來表示sub-layer的輸出結果就是LayerNorm(x+Sublayer(x))。
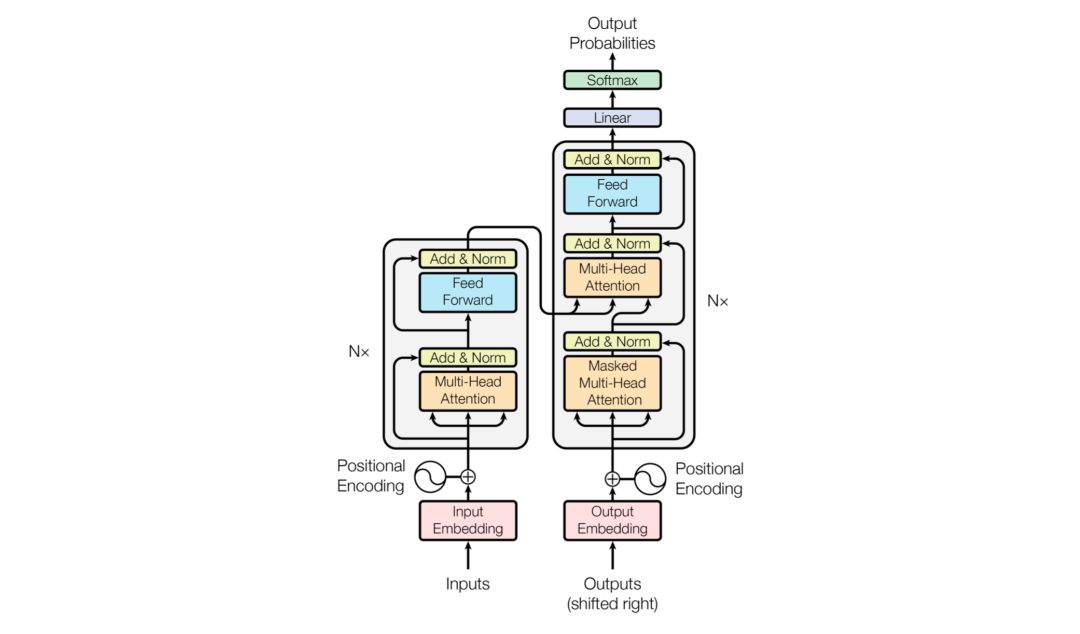
Attention Mechanism。為什麼要有注意力機制?換句話說,注意力機制有什麼好處?類比人類世界,當我們看到一個人走過來,為了識別這個人的身份,眼睛注意力會關注在臉上,除了臉之後的其他區域資訊會被暫時無視或不怎麼重視。對於語言模型,為了模型能夠更加準確地判斷,需要對輸入的文本提取出關鍵且重要的資訊。怎麼做?對輸入文本的每個單詞賦予不同的權重,攜帶關鍵重要資訊的單詞偏向性地賦予更高的權重。抽象來說,即是:對於輸入Input,有相應的向量query和key-value對,通過計算query和key關係的function,賦予每個value不同的權重,最終得到一個正確的向量輸出Output。在Transformer編碼器里,應用了兩個Attention單元:Scaled Dot-Product Attention和Multi-Head Attention。
Scaled Dot-Product Attention。Self-Attention機制是在該單元實現的。對於輸入Input,通過線性變換得到Q、K、V,然後將Q和K通過Dot-Product相乘計算,得到輸入Input中詞與詞之間的依賴關係,再通過尺度變換Scale、掩碼Mask和Softmax操作,得到Self-Attention矩陣,最後跟V進行Dot-Product相乘計算。

Multi-Head Attention。通過h個不同線性變換,將d_model維的Q、K、V分別映射成d_k、d_k、d_v維,並行應用Self-Attention機制,得到h個d_v維的輸出,進行拼接計算Concat、線性變換Linear操作。

2.輸入特徵處理
______________
BERT的輸入是一個線性序列,支援單句文本和句對文本,句首用符號[CLS]表示,句尾用符號[SEP]表示,如果是句對,句子之間添加符號[SEP]。輸入特徵,由Token向量、Segment向量和Position向量三個共同組成,分別代表單詞資訊、句子資訊、位置資訊。

3.預訓練
________
BERT採用了MLM和NSP兩種策略用於模型預訓練。為了證明這兩種策略的效果,Google額外增加了兩組對照實驗。對照組一:No NSP,保留MLM,但沒有NSP;對照組二:LTR & No NSP,沒有MLM和NSP,替換成一個Left-to-Right(LTR)模型,甚至為了增強可信性,在對照組二的基礎上增加一個隨機初始化的BiLSTM。實驗數據表明,BERT採用MLM&NSP策略完勝其他。

LM,Masked LM。對輸入的單詞序列,隨機地掩蓋15%的單詞,然後對掩蓋的單詞做預測任務。相比傳統標準條件語言模型只能left-to-right或right-to-left單向預測目標函數,MLM可以從任意方向預測被掩蓋的單詞。不過這種做法會帶來兩個缺點:1.預訓練階段隨機用符號[MASK]替換掩蓋的單詞,而下游任務微調階段並沒有Mask操作,會造成預訓練跟微調階段的不匹配;2.預訓練階段只對15%被掩蓋的單詞進行預測,而不是整個句子,模型收斂需要花更多時間。對於第二點,作者們覺得效果提升明顯還是值得;而對於第一點,為了緩和,15%隨機掩蓋的單詞並不是都用符號[MASK]替換,掩蓋單詞操作進行了以下改進,同時舉例「my dog is hairy」挑中單詞「hairy」。
80%用符號[MASK]替換:my dog is hairy -> my dog is [MASK] 10%用其他單詞替換:my dog is hairy -> my dog is apple 10%不做替換操作:my dog is hairy -> my dog is hairy
NSP,Next Sentence Prediction。許多重要的下游任務譬如QA、NLI需要語言模型理解兩個句子之間的關係,而傳統的語言模型在訓練的過程沒有考慮句對關係的學習。NSP,預測下一句模型,增加對句子A和B關係的預測任務,50%的時間裡B是A的下一句,分類標籤為IsNext,另外50%的時間裡B是隨機挑選的句子,並不是A的下一句,分類標籤為NotNext。
Input = [CLS] the man went to [MASK] store [SEP] he brought a gallon [MASK] milk [SEP] Label = IsNext Input = [CLS] the man went to [MASK] store [SEP] penguin [MASK] are flight ##less birds [SEP] Label = NotNext
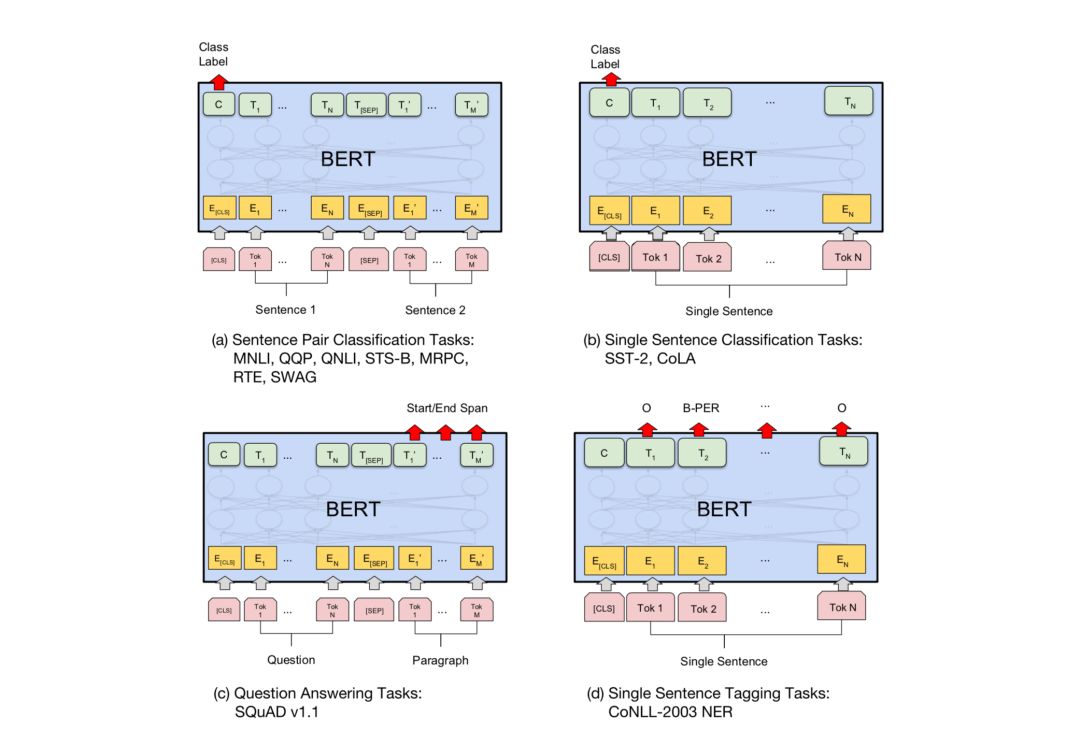
4.任務微調
__________
BERT提供了4種不同下游任務的微調方案:
(a)句對關係判斷,第一個起始符號[CLS]經過Transformer編碼器後,增加簡單的Softmax層,即可用於分類;
(b)單句分類任務,具體實現同(a)一樣;
(c)問答類任務,譬如SQuAD v1.1,問答系統輸入文本序列的question和包含answer的段落,並在序列中標記answer,讓BERT模型學習標記answer開始和結束的向量來訓練模型;
(d)序列標準任務,譬如命名實體標註NER,識別系統輸入標記好實體類別(人、組織、位置、其他無名實體)的文本序列進行微調訓練,識別實體類別時,將序列的每個Token向量送到預測NER標籤的分類層進行識別。
源碼分析
BERT實現
PyTorch Torch的python包,而Torch是一個用於機器學習和科學計算的模組化開源庫。Anaconda Python針對Interl架構調整了MKL,使得PyTorch在Interl CPU上的性能達到最佳;此外,PyTorch支援NVIDIA GPU,能夠利用GPU加速訓練。
網上已經有各個版本的BERT源碼,譬如Google開源的基於TensorFlow的BERT源碼,Google推薦的能夠載入Google預訓練模型的PyTorch-PreTrain-BERT版本。我用來源碼分析學習的是另一個PyTorch版本:Google AI 2018 BERT PyTorch Implementation,對照Google開源的tf-BERT版本開發實踐。
以下程式碼如需使用,請用網頁瀏覽器查看。
MLM模型實現:
class MaskedLanguageModel(nn.Module):
def __init__(self, hidden, vocab_size):
super(MaskedLanguageModel, self).__init__()
self.linear = nn.Linear(hidden, vocab_size)
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, x):
return self.softmax(self.linear(x))
NSP模型實現(分類模型,同樣可以適用於單句分類或句對關係判斷任務。):
class NextSentencePrediction(nn.Module):
def __init__(self, hidden):
super(NextSentencePrediction, self).__init__()
self.linear = nn.Linear(hidden, 2)
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, x):
return self.softmax(self.linear(x[:, 0]))
BERT-Encoder實現:
class BERT(PreTrainedBERTModel):
def __init__(self, vocab_size, hidden=768, n_layers=12, attn_heads=12, dropout=0.1):
config = BertConfig(vocab_size, hidden_size=hidden, num_hidden_layers=n_layers,num_attention_heads=attn_heads, hidden_dropout_prob=dropout)
super(BERT, self).__init__(config)
self.hidden = hidden
self.n_layers = n_layers
self.attn_heads = attn_heads
self.feed_forward_hidden = hidden * 4
self.embedding = BERTEmbedding(vocab_size=vocab_size, embed_size=hidden)
self.transformer_blocks = nn.ModuleList([TransformerBlock(hidden, attn_heads, hidden * 4, dropout) for _ in range(n_layers)])
def forward(self, x, segment_info):
mask = (x > 0).unsqueeze(1).repeat(1, x.size(1), 1).unsqueeze(1)
x = self.embedding(x, segment_info)
for transformer in self.transformer_blocks:
x = transformer.forward(x, mask)
return x
Transformer實現:
class TransformerBlock(nn.Module):
def __init__(self, hidden, attn_heads, feed_forward_hidden, dropout):
super(TransformerBlock, self).__init__()
self.attention = MultiHeadedAttention(h=attn_heads, d_model=hidden)
self.feed_forward = PositionwiseFeedForward(d_model=hidden, d_ff=feed_forward_hidden, dropout=dropout)
self.input_sublayer = SublayerConnection(size=hidden, dropout=dropout)
self.output_sublayer = SublayerConnection(size=hidden, dropout=dropout)
self.dropout = nn.Dropout(p=dropout)
def forward(self, x, mask):
x = self.input_sublayer(x, lambda _x: self.attention.forward(_x, _x, _x, mask=mask))
x = self.output_sublayer(x, self.feed_forward)
return self.dropout(x)
Multi-Head Attention實現:
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
super().__init__()
assert d_model % h == 0
self.d_k = d_model // h
self.h = h
self.linear_layers = nn.ModuleList([nn.Linear(d_model, d_model) for _ in range(3)])
self.output_linear = nn.Linear(d_model, d_model)
self.attention = Attention()
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
batch_size = query.size(0)
query, key, value = [l(x).view(batch_size, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linear_layers, (query, key, value))]
x, attn = self.attention(query, key, value, mask=mask, dropout=self.dropout)
x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.h * self.d_k)
return self.output_linear(x)
Self-Attention實現:
class Attention(nn.Module):
def forward(self, query, key, value, mask=None, dropout=None):
scores = torch.matmul(query, key.transpose(-2, -1))/math.sqrt(query.size(-1))
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
SubLayerConnection實現:
class SublayerConnection(nn.Module):
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
return x + self.dropout(sublayer(self.norm(x)))
參考資料:
1. Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Krisina Toutanova.2018.BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
2. Matthew Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. Deep contextualized word rep- resentations. In NAACL.
3. Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language under- standing by Generative Pre-Training. Technical re- port, OpenAI.
4. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Pro- cessing Systems, pages 6000–6010.
5. J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei- Fei. 2009. ImageNet: A Large-Scale Hierarchical Image Database. In CVPR09.
6. Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013.Efficient Estimation of Word Representations in Vector Space.
作者介紹:
陳桂敏(Derek),畢業於中山大學電腦系,現職騰訊,追求技術,方向大數據分析和自然語言處理領域。

