人機互動式機器翻譯研究與應用
- 2019 年 11 月 21 日
- 筆記
分享嘉賓:黃國平 騰訊AI Lab 高級研究員 編輯整理:趙文嬌 內容來源:DataFun AI Talk《人機互動式機器翻譯研究與應用》 出品社區:DataFun 註:歡迎轉載,轉載請註明出處。
這個題目看起來比較小眾,希望大家聽我的講座沒有白聽,可以學到一些東西,就是AI技術落地過程中的一些問題,以及解決策略和方法,技術、產品、行業問題的大雜燴。
我的分享主要包括以下幾個方面:
1. 機器翻譯現狀簡介;
2. 翻譯需求與人工翻譯行業;
3. 人機互動式機器翻譯技術;
4. 人機互動式機器翻譯應用;
5. 人工智慧落地的一些思考。
首先會過一下機器翻譯的現狀,看一下翻譯需求是怎麼回事,然後就是我本身做的事情,還有做這個事情過程中遇到的哪些問題,以及這些問題帶來的思考。
機器翻譯現狀簡介:
機器翻譯在2018年不想聽到這幾個字也很難,有的公司說起人工智慧好像也不知道做什麼,那就做一個翻譯機或者同傳吧,如果沒有技術怎麼辦,沒有技術的話,你也可以做機器翻譯,怎麼做呢?做人機耦合吧,把人關到同傳箱裡面,然後翻譯內容不由機器來生成,由人進行生成,把人工翻譯結果列印到螢幕上。翻譯其實是比較低頻的需求,但是在2018年很多公司希望在翻譯上展示出自己不一樣的能力,表現出很饑渴的樣子,大家很多時候或多或少有這樣的疑問,當大家真的需要用機器翻譯的時候,往往錯誤百出,在同傳的時候,在博鰲論壇上,翻譯連續翻譯出10幾個神奇的句子,這種神奇詭秘的地方,對於機器翻譯來說,這不是偽需求嗎?誰會花幾千塊,大幾百塊買那麼一個破玩意兒,但是各家說自己出貨又很高,我一直沒有想明白,為什麼那些翻譯機的銷量能有幾百萬,幾千萬台,然後各家的數據一綜合的話會超過億,可是在我身邊卻看不到呢,我們AI行業各家的數據都是謎一樣的存在。每家都在宣傳自己掌握核心技術,通過開源軟體知道了機器翻譯的原理,出來的東西也都差不多,一句詩來形容就是「藕花深處田田葉,葉上初生並蒂蓮」。
中國最近20年,長期投入的機器翻譯的單位大概有這麼幾家,有的資深一些,有的比較新一些,比如說騰訊在機器翻譯上的投入沒有超過3年,超過10年快20年的是前面幾個單位,比如說中國科學院自動化研究所(也是我讀博的地方),還有中國科學院電腦技術研究所,除此之外,清華,哈工大,這些時間也比較長,蘇州大學比較年輕的,最近幾年在人工智慧上的成績是有目共睹的,公司的話應該是百度和網易有道,其他的相對晚一些。機器翻譯的從業人員,應該都是從這些機構走出來的,畢業的或者跳槽的,思維趨同,做出來的產品大差不差。

機器翻譯用的框架還是雷同的,主要是細節處理或者是針對一些問題本身的改進。通行的結構就是編碼器解碼器結構,做深度學習的對這套框架應該是很熟悉的,最難用的就是先把原文句子經過每個字詞通過RNN之類的手段對它進行編碼,最後形成一個句子向量,在解碼端,從句子開始根據句子向量,生成空格段的詞,最難用的框架,問題可能是比較多的:比如它的基本原則很簡單,在解碼器一端從句子開始到句子結尾處,它才停止翻譯的過程,如果沒有遇到句子開始和句子結尾的話就一直進行翻譯過程。大家很容易想到有些問題:比如在這種框架中,有些片段沒有翻譯到,形成丟失,或者是生成的譯文和原文沒有什麼關係。大家實際中在使用線上翻譯產品中會有這樣的感知,雖然現在的機器翻譯和三四年前相比已經有了質的飛躍,但還是不合格的,仍然有很多問題,這時如果需要彌補這些問題,一般都是加模型。

最簡單的就是注意力模型,加註意力模型的本質需求是希望我生成的下一個目標詞的時候能與原文的某些詞或者某一個詞建立比較強的聯繫,並通過注意力模型,來生成隨翻譯過程不斷變化的上下文向量。它根據原文編碼,加註意力模型之後呢,它會隨著前面已經生成的詞,進行變化,這個時候翻譯效果會上升一大截。

如果用固化的方法來講,注意力模型怎麼去解釋它的物理作用呢?在翻譯這個問題下,它看起來有點像翻譯的概念,就是詞到詞之間的翻譯,但是好多詞又不一定,在使用線上翻譯的時候,輸入原文句子裡面多一個標點,少一個標點可能引起譯文端的劇烈變化,這個時候,這個時候注意力就是學偏了,它把好多東西都壓到了原文最後那個標點上面。所以我們人工單相思式的去解釋翻譯概念是不對的,既然注意力機制與翻譯概念不是那麼有關係的話,那就換一下,比如Google發表了transformer的架構。

大家如果做這個方嚮應該是比較熟悉的,不做這個方向的,要理解的東西也比較多,相比RNN結構,transformer這個結構相比RNN,對原文資訊的編碼是更充分的,比如說是在RNN的時候,對原文的編碼都是從左至右或者從右至左,但是在transformer這一套框架中,它對原文中每個詞的編碼都會參考整個句子的詞,而且編碼還不止一層,有個self-attention機制,一般我們用attention都是原文和目標端文字之間的關係,但是在transformer關係中它會計算原文和原文之間的關係,然後譯文與譯文之間的關係,這樣就會更充分了,但是參數規模會爆炸,所以也出現了比較尷尬的事實,transformer在比賽中,如果GPU狀態比較差的話,是跑不了實驗的,比如我們實際場景上線,就是訓練語料是以億句為規模的,想通過1080,或者2080那是肯定跑不出來的,因為要跑好幾個月,就算是P40,一塊P40也沒什麼用,就是它的單個顯示記憶體比較大一些,比如說24G左右,因為在面對海量數據的時候,我們一個模型,跑一個模型48塊盤,48塊P40,如果大家是玩一玩或者創業公司來做這個事情的時候,會有很多的困難,也許以後會隨著雲計算業務的普及,大家會受惠,但是短期而言的話,在做AI技術落地的時候,硬體對於創業團隊容易造成很大的經濟壓力。
State-of-the-art:基於Transformer的機器翻譯
transformer對語言的編碼不是單向的,每個詞每一輪的編碼都會參考上一輪的結果,這是transformer顯著區別於RNN的區別,編碼器如之前所言考慮句子中所有詞,解碼器默認是從左到右,從句子開始生成下一個詞,在生成下一個詞之前,對之前解碼的內容進行多輪解碼。

機器翻譯的訓練和大家做其他的訓練也沒有什麼兩樣,都是隨機初始化,或者按照某種預設方式初始化參數,然後把它載入到模型中,對訓練語句進行batch數據,計算損失,調參數,重複這個過程,直到最後收斂,把參數保留下來,沒有什麼不一樣的地方,只是需要注意計算損失這一步。因為一般而言在翻譯領域,如何去評價一個自動譯文好不好呢,我們的評價指標叫blue,它是和參考譯文去比對,一元的串匹配的有多少,二元的串匹配的有多少,三元四元有多少。但是在神經網路翻譯訓練當中,我們是沒有辦法用blue這種方式的,這時候就用PPL,用的比較廣泛,雖然在統計規律中講PPL越低,blue值會增的,但是好多時候,在一些比較狹小的空間,它會有個回饋,所以這個時候會有個模型選擇。這個模型選擇一般是構建一批比較大一點的人工測試集,就是面向開放領域,或者把大家的高頻query抓下來,埋點,然後中間會生成一堆checkpoint,然後看哪個更能體現線上實際要求,這個過程和做其他產品沒有特別大的區別,只是做數據處理充滿各種小的技巧。

比如說在做產品的過程中產品還沒有發布,買數據的錢花了好多,然後人工評估體系的構建又花了好多錢,最後都不知道這個產品能賺幾個錢。(註:當然我是很有自信的,我的產品能把產品的成本賺回來了。)現在各家都在炒作自家產品,其實用的技術沒有差太多,如果用相同的語料去訓練各大公司的機器翻譯引擎的話,大家blue值的差別不會超過3個,區別其實會很小很小,大家為什麼又拚命強調其中的差異化呢,其中最主要的原因就是:目前,翻譯的問題還沒有被徹底解決,大家還可以找出很多差異,但是大趨勢是趨同的。機器翻譯的困難呢,大家在做的過程中會有一些體會,我這裡總結了四個方面:
第一個方面就是歧義和未知現象:歧義的,像南京市長江大橋這種都老掉牙了,未知現象的,比如是在武俠小說裡面駕。。。駕。。。(模仿騎馬的這種), 再比如新產生的詞不太容易被翻譯出來。
第二個方面是翻譯不僅僅是字元串的轉換:直接翻譯不能解決所有問題,比如,青梅竹馬,直接翻譯成英文是「發青的梅子,竹子做的馬」;特定情況下的江湖(比如有人的地方就有江湖),直接翻譯過去就是「江和湖」,其實並不能表達中文中的語義;再比如特定場景下的「你媽媽叫你回家吃飯了」,都沒法直接逐字進行翻譯。
第三個方面就是翻譯的解並不唯一:缺乏量化標準,並且始終存在人為標準,這個是精準層面的,把一句話表達清楚,其實有很多方式。
第四個方面就是翻譯的高度:有的語句意境很高,上升到文學層次了,比如「最是那一低頭的溫柔」,翻譯的時候涉及到意境的體會和把握,對於人工翻譯來說困難,對於機器翻譯來說,也困難。
翻譯需求與人工翻譯行業:

翻譯行業全球的產值還是很高的,大約四到五百億人民幣,主戰場在歐洲和北美洲,最大增速在非洲,中國佔10%左右,中國主要的語種是中英互譯,利潤主要來自於外單。

獨角獸不獨,充分多樣性。其他領域獨角獸往往比重很大,佔據70%左右的市場,但是翻譯市場不是這樣。從2005年到2016年頭部公司的排名和佔比區別不大。

10人以上團隊需要工具卻無力支付正版。
人機互動式機器翻譯技術:

背景:全自動輸出翻譯結果無法保證譯文品質,這時候就需要人機交互,實現下面三個任務:
1. 在翻譯過程中接受用戶提供譯文干預,能根據干預結果生成更好的結果;
2. 及時學慣用戶的修改回饋,不能一個愚蠢的錯誤反覆出現;
3. 實時提供翻譯輔助資訊。

人工翻譯如何和機器翻譯產生交互?人工翻譯參與程度與自動翻譯的品質相關,如果自動譯文的品質較高,那就機器翻譯直接發揮作用了(人工只需要在自動譯文之後進行校驗),如果自動譯文的品質比較低,就需要比較高的人工介入,像翻譯輸入法(相當於比較多的人工標註),如果主動譯文的品質不好不差的情況下,可以用互動式機器翻譯來解決翻譯品質的問題(人工標註比較難的部分)。

在自動翻譯過程中,機器翻譯可以扮演的角色:
整句的更新(高精度的翻譯整個句子)、片段提示(在無法保證整句精準的情況下保證重點片段的精準)、翻譯輸入法、在線學習、語義理解、快速解碼。
在整個過程中,除了AI技術,還涉及到產品設計能力。需要產品經理和技術人員之間的協調和共識。

最簡單暴力的使用機器翻譯的一種,就是譯後編輯。就是首先機器翻譯,然後人工編輯。

機器翻譯不差不好的情況下使用互動式機器翻譯,就是人工翻譯片段和機器翻譯片段交替進行。

約束解碼方式,就是強制在翻譯中必須含有一部分術語,比如說一句話中必須把「深圳騰訊」,「社區」包含在內,這一點是目前難以做到的,主要是卡在翻譯速度上,時間消耗嚴重。

我們對演算法進行了一些改進,如上圖所示。
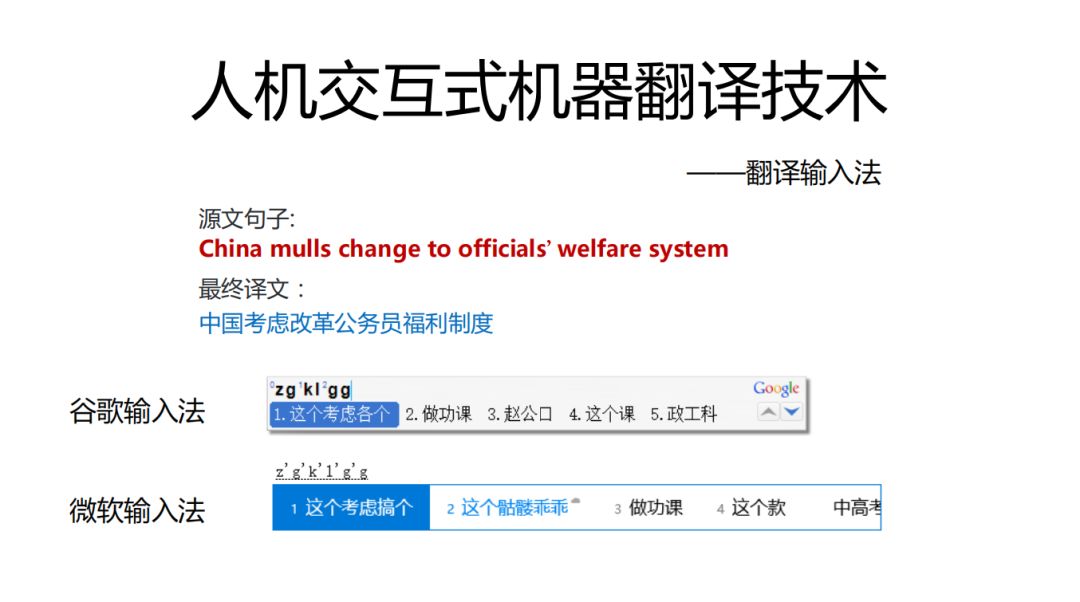
我們希望用戶打完這句話用的按鍵數越少越好,用Google和微軟輸入法結果如下,因為一般的輸入法去學習的是人的輸入歷史,我們引入機器翻譯的東西可以改進過於依賴輸入歷史的情況。


拼音輸入法:是尋找最優解的過程,需要對過程進行打分,之前主要是音字轉換概率,字音轉換概率,語言模型概率,輸入歷史。這裡我們可以進一步引入翻譯技術。


人機互動式機器翻譯研究-在線學習方法

在線學習,就是online learning,即時學慣用戶回饋,一般強化學習,增強學習比較多,我們採用的是基於隨機森林的在線翻譯模型,是一種投票機制。

根據資訊增益決定決策樹上某一支是否要分叉,同時根據當前的錯誤率決定是否刪除某棵樹,方法比較簡單,主要是基於解決實際問題以及當前可獲得的有效資源的角度進行考慮,要找到適合當前環境的方法。

比如說需要翻譯的句子A如下:「獲取或設置與批註關聯的對象」但是之前翻譯過這樣的句子包含了與A的公共子串「關聯的對象」,這樣就是如何復用以前的翻譯結果?這就是我們需要找到簡單、高效、適合當前團隊實現能力的方法,我們的方案是容易翻譯記憶的NMT(Transformer)如下圖:

不一定最新的論文就能解決當前團隊下我們的問題,很多東西還是要結合實際去思考適合自己的,最後的效果不一定差。
人機互動式機器翻譯應用:

這裡主要說人機互動式機器翻譯在騰訊的主要應用場景,分為內部場景和外部場景,騰訊不同的方向有不同的翻譯團隊,進行賽馬機制。如下,同聲傳譯,拍照翻譯,輔助翻譯。技術問題落地到實踐是一個問題,大公司和創業公司的方向可能不一樣,大公司可以內部落地也可以外部落地,創業公司只能外部落地,內部落地不一定意味著產品能夠解決問題,外部落地就很現實,所以如何外部落地,能攬到更多的外部項目是一個值得思考的問題。

工業場景對翻譯的需求還是很大的,比如華為、中興、南車、北車,他們一般有自己的翻譯部門,他們是有這個需求,實際上他們需要根據他們自己的業務背景,進行一些技術訂製,客戶就是大爺,我們聽他們的,雖然有時候感覺這些需求和高大上演算法沒什麼關係,但是沒有客戶的肯定,演算法是沒有辦法用的,最後經過挺長時間的行業調研,一開始的時候訂製的比較麻煩,後來就習慣了。
騰訊機器翻譯應用

如何把技術變成產品,這裡有許多路要走,因為用戶往往也不知道自己需要什麼,為了避免一系列莫名其妙的需求:
第一步要做的就是需要有明確的需求:比如語種、領域、用途、業務介面。
第二步就是確定合適的語料,從哪裡買,語料品質怎麼樣,價格合不合適,能不能壓價等,一般都要200萬句對以上。
第三步是集成可用的state of the art技術:輸入法,屬於抽取,翻譯片段挖掘等,很多時候是有開源工具的,但是開源工具基本上都是有坑的,很多時候面臨著自己開發和用開源工具的問題,目前我們是自己開發,因為熟悉開源工具的時間比我們自己開發還要久,但是不同的團隊有不同的情況,開源工具容易上手,能拿過來就用。
第四步就是調試GPU集群,並行加速訓練。第五步是部署上線并迭代。
難點在哪裡?
人們對於自動譯文品質過高的期望、開源系統的坑遠比計劃的多、如何甄別並且集成最新技術、如何拉通目標場景技術鏈條,關於最後一點拉通目標場景的技術鏈條,因為發論文是將問題聚焦到一個點上,而做一款產品的時候,流程和目標設定上環節比較多,鏈條比較長。
人工智慧落地的一些思考:
團隊需要什麼樣的人?需要調參大師、論文機器、程式碼工匠,說起來似乎論文機器發揮的作用最小,其實也不是這樣,如果是創業公司,老闆需要拿最新的論文去忽悠錢,沒有論文機器是不行的,調參大師和程式碼工匠是必須的,三者的關係需要高超的管理技能進行協調這是內部的問題。
外部的問題有「數據鴻溝」和「工程壁壘」,純技術團隊是沒有業務數據的,業務數據又特別寶貴,如何通過溝通把寶貴的數據弄到手是一個技術問題;另外一個是在演算法技術同質化的情況下,需要很細緻的步驟安排大量的數據清洗和工程問題,這些都是大家比拼的實力。
最後在設計產品的時候,理念選擇上,設計一個「人工智慧產品」還是一個「用人工智慧的產品」,未來的趨勢一定是人工智慧產品,但是目前我們還是要幫助產品設計出更合理的人工智慧的產品。
作者介紹:

黃國平博士畢業於中國科學院自動化研究所,現為騰訊AI Lab高級研究員,研究方向為機器翻譯和自然語言處理,研究興趣為人機互動式機器翻譯。


