應用AlphaGo Zero思路優化搜索排序
- 2019 年 11 月 21 日
- 筆記
文章作者:楊鎰銘 滴滴出行 高級演算法工程師 內容來源:記錄廣告、推薦等方面的模型積累@知乎專欄 出品社區:DataFun 註:歡迎後台留言投稿「行知」專欄文章。
在深度學習大潮之後,搜索推薦等領域模型該如何升級迭代呢?強化學習在遊戲等領域大放異彩,那是否可將強化學習應用到搜索推薦領域呢?推薦搜索問題往往也可看作是序列決策的問題,引入強化學習的思想來實現長期回報最大的想法也是很自然的,事實上在工業界已有相關探索。因此後面將會寫一個系列來介紹近期強化學習在搜索推薦業務上的應用。
本次將介紹第二篇,(戳我看第一篇)發表在SIGIR2018上,適合做搜索推薦等業務的同學精讀,鏈接為http://www.bigdatalab.ac.cn/~junxu/publications/SIGIR2018-M2Div.pdf。作者中徐君老師在SIGIR2018上做過搜索推薦中Matching相關的分享,很贊。
一、Introduction
這篇文章解決的問題是提高搜索多樣性,搜索多樣性是指搜索結果覆蓋更多的主題,問題可定義成從候選集合中選出一個最小的子集來儘可能覆蓋更多的主題。傳統的解決方法是貪心選擇,每次從候選集合里選出一個marginal relevance的文檔。貪心選擇的問題在於每次選擇局部最優的文檔會導致最終生成的文檔列表很難是全局最優的,因為每個位置選擇的文檔會影響後續文檔的選擇。如果想得到全局最優的文檔列表,如果候選文檔的數目為N,暴力搜索的時間複雜度為N的階乘,顯然在實際的應用中不現實。

模型的整體框架
文章則借鑒了AlphaGo和AlphaGo Zero的思路,結合強化學習和蒙特卡洛搜索進行多樣性排序,整體框架如上圖。訓練過程中,在每個時間步(對應每個排序的位置),基於用戶query和已產生的文檔列表,使用RNN得到當前狀態,然後基於當前狀態得到指導文檔選擇的策略函數(raw policy)以及評估當前列表的值函數。為了緩解次優解的問題,模型使用MCTS進行搜索,輸出一個更優的策略(search policy)。模型的損失函數由兩部分構成,一個是預測價值和文檔排序指標的均方誤差,另一個是raw policy和search policy的交叉熵。後面講詳細介紹整個訓練過程和預測過程。
二、模型
- 基於MDP的多樣性排序
文檔列表生成過程中每個位置的文檔選擇可以看做一個時間步,整體是一個序列決策的過程,適合用MDP來建模。下面介紹下相關的狀態、動作、轉換、值函數和策略函數的定義。
狀態:每個時間步的狀態可看做三元組,

,q是用戶查詢,

是t時間之前已經產生的文檔列表,而

是候選文檔。
動作:

中的動作對應可選擇的候選文檔。時間步t時選擇的動作

選擇了標號為

的文檔

。
狀態轉換:狀態轉換很顯然,設

表示將

加入到

中,而

表示將
從

中刪除,定義為

值函數:根據輸入狀態估計文檔排序列表的品質,通過近似一個預先設定的指標來學習。不同時間步的狀態可以一個輸入給LSTM模型,值函數以LSTM輸出作為輸入並經過一個非線性層,即為
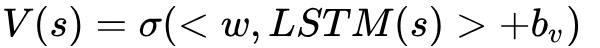
其中,

。
策略函數:策略函數也是以狀態作為輸入,輸出則是動作上的概率分布。形式化如下,其中

是待學習參數。
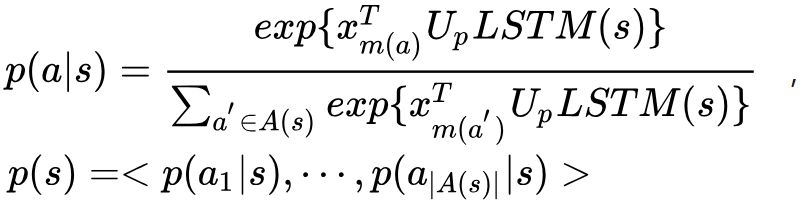
- 基於MCTS的更優策略
通過p(s)貪心地選擇文檔的方式僅基於歷史資訊去做決策,並未考慮動作

對後續決策的影響,會導致次優解。因此如下圖,文章提出了利用MCTS在排序空間進行lookahead搜索。在每個排序位置,利用當前的策略函數p和值函數V進行MCTS搜索,返回一個更優的搜索策略

。蒙特卡洛樹中節點表示狀態,邊表示狀態轉換,每條邊保存三個屬性,分別是動作值函數Q(s,a)、訪問次數N(s,a)和先驗概率p(s,a)。整體最多迭代K次,每次迭代中會在第四步Back-propagation時更新Q和N兩個變數,迭代結束之後輸出更優策略。

MCTS搜索過程-四個步驟
Selection
從根節點

開始,在每個時間步t迭代選擇使下式最大的動作

。其中,

控制exploitation,傾向於選擇價值更高的邊;而

控制exploration,
正比於先驗概率,但隨著訪問次數衰減,傾向於選擇探索次數少的邊。

其中,

。
Evaluation and Expansion
上一步一直迭代到一個葉子節點

,如果節點是一個episode的結尾則使用預設的評價指標評估,其他情況使用值函數

評估。這和AlphaGo Zero處理是一樣的,而AlphaGo中價值評估是通過快速走子模擬實現的。接著葉子節點
有可能會拓展,拓展出的新邊

會初始化

、

和

這三個屬性。
Back-propagation and Update
利用

沿著Selection經過的路徑反向一路更新。針對路徑上的每條邊e(s,a),

不變化,

加一,

做累積平均的更新:

輸出更優搜索策略
上述步驟迭代K次後可得到根節點

處的更優搜索策略。由於邊的訪問次數說明了每條邊的價值高低,新策略由每個邊的訪問次數決定,形式化為

- 基於強化學習的訓練方式
模型參數主要是LSTM和策略函數p中的參數。針對一個query,在當前的參數下,每個位置執行一次MCTS搜索,直到產生一個排序列表

,然後得到評估

,其中R是任意的多樣性評價指標,比如文中使用到的

,而J是該query下的真值。

損失函數組成
使用每個時間步積累的訓練數據

和r作為監督訊號來訓練網路。如上圖,損失函數包含兩部分,一個是值函數的預測值

和指標

的均方誤差,另一個是raw policy

和search policy

的交叉熵,形式化如下:

- 在線預測
針對線上預測需要兩種方式:一個是採用上面提到的MCTS,但是這種方式非常耗時;另一個是放棄樹搜索直接使用raw policy進行排序。在實驗中發現即使採用第二種方法的效果依然超過了基準模型。這是因為訓練時由於使用MCTS搜索產生了品質較好的序列來訓練參數,使得策略函數p更加準確。這點也使得文章提出的idea在工業界真實上線具備可能。
三、總結
- 對AlphaGo和AlphaGo Zero了解的同學讀這篇文章會很順暢,思路和AlphaGo Zero類似,借鑒了比如使用同一個網路得到策略和值函數、MCTS搜索、同時優化值函數和策略函數的損失等成功經驗。
- 在我們的業務場景中,action偏少,一般只有2-3個,引入mcts也已經很耗時了。在文章中,由於候選文檔也就是動作可能偏多,所以想要使得mcts輸出的策略儘可能平滑,mcts需要很多次的迭代,文中的k值設置的是5000,可想而知訓練過程的耗時程度,其實就是拿時間換效果的tradeoff。
- 存在一個疑問的地方是在損失函數里,因為開始時可能只搜出來一篇或者兩篇文檔,其狀態的Q值明顯和最終整個列表生成後的狀態Q值應該差別很大,但損失函數里要求使所有狀態的Q值都要和最終列表的指標r都接近。AlphaGo Zero中這裡採取類似做法,但多了一個均勻取樣。這個細節的處理,歡迎提出不同看法。
作者介紹:
楊鎰銘,滴滴出行高級演算法工程師,碩士畢業於中國科學技術大學,知乎「記錄廣告、推薦等方面的模型積累」專欄作者。


