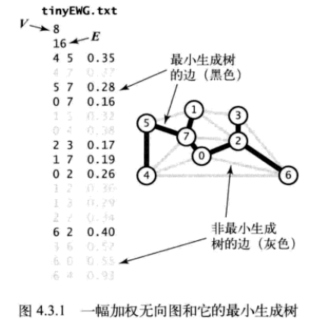
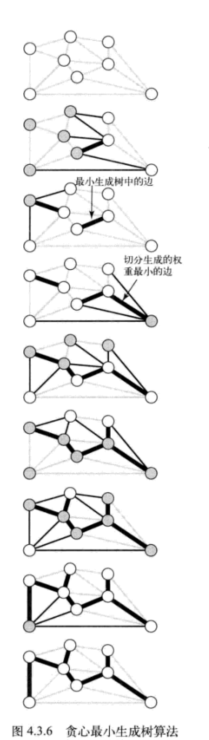
圖 – 最小生成樹
加權圖是一種為每條邊關聯一個權值或是成本的圖模型。這種圖能夠自然地表示許多應用。在一幅航空圖中,邊表示航線,權值則可以表示距離或是費用。在這些情形中,最令人感興趣的自然是將成本最小化。這裡用加權無向圖模型來解決最小生成樹:給定一幅加權無向圖,找到它的一棵最小生成樹。
圖的生成樹是它的一棵含有其所有頂點的無環連通子圖。一幅加權圖的最小生成樹(MST)是它的一棵權值(樹中所有邊的權值之和)最小的生成樹。
計算最小生成樹的兩種經典演算法:Prim 演算法和 Kruskal 演算法。
1.原理
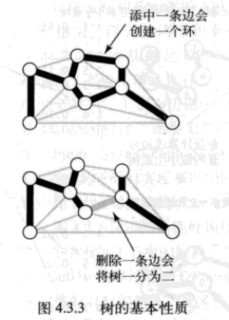
樹的兩個重要性質:
1.用一條邊連接樹中的任意兩個頂點都會產生一個新的環;
2.從樹中刪除一條邊將會得到兩棵獨立的樹。
這兩條性質是證明最小生成樹的另一條基本性質的基礎,而由這條基本性質就能夠得到最小生成樹的演算法。
1.切分定理
我們稱之為切分定理的這條性質將會把加權圖中的所有所有頂點分為兩個集合,檢查橫跨兩個集合的所有邊並識別哪條邊應屬於圖的最小生成樹。
通常,我們指定一個頂點集並隱式地認為它地補集為另一個頂點集來指定一個切分。這樣,一條橫切邊就是連接該集合地一個頂點和不在該集合地另一個頂點地一條邊。
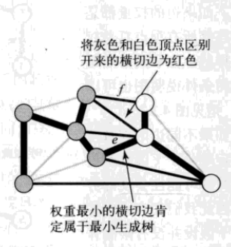
切分定理:在一幅加權圖中,給定任意得切分,它的橫切邊中權重最小者必然屬於圖的最小生成樹。
注意,權重最小的橫切邊並不一定是所有橫切邊中唯一屬於圖的最小生成樹的邊。實際上,許多切分都會產生若干條屬於最小生成樹的橫切邊:
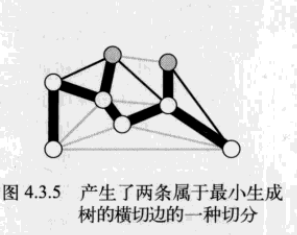
2.貪心演算法
切分定理是解決最小生成樹問題的所有演算法的基礎。更確切的說,這些演算法都是一種貪心演算法的特殊情況:使用切分定理找到最小生成樹的一條邊,不斷重複直到找到最小生成樹的所有便。這些演算法之間的不同之處在於保存切分和判定權重最小的橫切邊的方式,但它們都是一下性質特殊情況:
最小生成樹的貪心演算法:下面這種演算法會將含有 V 個頂點的任意加權連通圖中屬於最小生成樹的邊標記為黑色:初始狀態下所有邊均為灰色,找到一種切分,它產生的橫切邊均不為黑色。將它權重最小的橫切邊標記為黑色。反覆,直到標記了 V – 1 條黑色邊為止。
2.加權無向圖的數據類型

namespace MinimumSpanningTrees { public class Edge:IComparable<Edge> { private int v;//頂點之一 private int w;//另一個頂點 private double weight;//邊的權重 public Edge(int v, int w, double weight) { this.v = v; this.w = w; this.weight = weight; } public double Weight() { return weight; } public int Either() { return v; } public int Other(int vertex) { if (vertex == v) return w; else if (vertex == w) return v; else throw new ArgumentException(); } public int CompareTo([AllowNull] Edge other) { if (this.Weight() < other.Weight()) return -1; else if (this.Weight() > other.Weight()) return 1; else return 0; } public override string ToString() { return string.Format("%d-%d %.2f",v,w,weight); } } }
加權無向圖的實現使用了 Edge 對象。

namespace MinimumSpanningTrees { public class EdgeWeightedGraph { private int v;//頂點總數 private int e;//邊的總數 private List<Edge>[] adj;//鄰接表 public EdgeWeightedGraph(int V) { this.v = V; e = 0; adj = new List<Edge>[V]; for (int _v = 0; _v < V; _v++) { adj[_v] = new List<Edge>(); } } public int V() { return v; } public int E() { return e; } public void AddEdge(Edge edge) { int v = edge.Either(); int w = edge.Other(v); adj[v].Add(edge); adj[w].Add(edge); e++; } public IEnumerable<Edge> Adj(int _v) { return adj[_v]; } } }
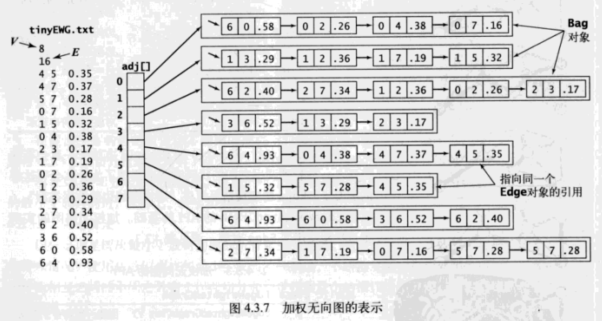
為了整潔,用一對 int 值和一個 double 值表示每個 Edge 對象。實際的數據結構是一個鏈表,其中每個元素都是一個指向含有這些值的對象的指針。需要注意的是,雖然每個Edge對象都有兩個引用,但圖中的每條邊所對應的 Edge 對象只有一個。
用權重來比較邊
Edge 類實現了 IComparable 介面的 CompareTo 方法。一幅加權無向圖中的邊的自然次序就是按權重排序。
平行邊
和無環圖的實現一樣,這裡也允許存在平行邊。我們也可以用更複雜的方法來消除平行邊,比如保留平行邊中權重最小者。
自環
允許存在自環,這對最小生成樹演算法沒有影響,因為最小生成樹肯定不會含有自環。
有個 Edge 對象之後用例的程式碼就可以變得更加乾淨整潔。這也有小的代價:每個鄰接表的結點都是一個都是一個指向 Edge 對象的引用,它們含有一些冗餘的資訊, v 的鄰接鏈表中的每個結點都會用一個變數保存 v 。使用對象也會帶來一些開銷。雖然每條邊的 Edge 對象都只有一個,但鄰接表中還是會含有兩個指向同一 Edge 對象的引用。
另一種廣泛使用的方案是與 Graph 一樣,用兩個結點對象表示一條邊,每個結點對象都會保存頂點的資訊和邊的權重。這種方法也是有代價的 — 需要兩個結點,每條邊的權重都會被保存兩次。
3.最小生成樹 API
按照慣例,在 API 中會定義一個接受加權無向圖為參數的構造函數並且支援能夠為用例返回圖的最小生成樹和其權重的方法。那麼應該如何表示最小生成樹?由於圖的最小生成樹是圖的一幅子圖並且同時也是一棵樹,因此可以有一下選擇:
1.一組邊的列表;
2.一幅加權無向圖;
3.一個以頂點為索引且含有父結點鏈接的數組。
在為了各種應用選擇這些表示方法時,我們希望儘可能給予最小生成樹的實現以最大的靈活性,採用如下 API :

4.Prim 演算法
Prim 演算法,它的每一步都會為一棵生長中的樹添加一條邊。一開始這棵樹只有一個頂點,然後會向它添加 V-1 條邊,每次總是將下一條連接樹中的頂點與不在樹中的頂點且權重最小的邊加入樹中。
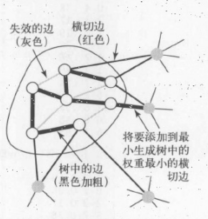
Prim 演算法能夠得到任意加權連通圖的最小生成樹。這棵不斷生長的樹定義了一個切分且不存在樹中的橫切邊。該演算法會選擇權重最小的橫切邊並根據貪心演算法不斷將他們標記。
數據結構
實現 Prim 演算法需要一些簡單常見的數據結構。具體來說,我們會用一下方法表示樹中的頂點,邊和橫切邊:
1.頂點:使用一個由頂點索引的布爾數組 marked[ ] ,如果頂點 v 在樹中,那麼 marked[v] 的值為 true。
2.邊:選擇以下兩種數據結構之一:一條隊列 mst 來保存最小生成樹中的邊,或者一個由頂點索引的Edge對象的數組 edgeTo[ ] ,其中 edgeTo[ v ] 為將 v 連接到樹中的 Edge 對象;
3.橫切邊:使用一條優先隊列 MinPQ<Edge> 來根據權重比較所有邊。
有了這些數據結構就可以回答 「哪條邊的權重最小」 這個基本問題了。
維護橫切邊的集合
每當我們向樹中添加了一條邊後,也向樹中添加一個頂點。要維護一個包含所有橫切邊的集合,就要將連接這個頂點(新加入樹)和其他所有不在樹中的頂點的邊加入優先隊列。但還有一點:連接新加入樹中的頂點和其他已經在樹中的頂點的所有邊都要失效(這樣的邊已經不是橫切邊了,因為它的兩個頂點都在樹中)。Prim 演算法的即時實現可以將這樣的邊從優先隊列中刪掉,先來看一種延時實現,將這些邊先留在優先隊列中,等到要刪除它們的時候再檢查邊的有效性。
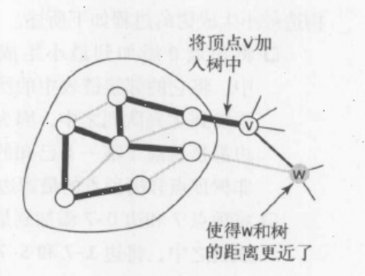
演算法構造最小生成樹的過程:
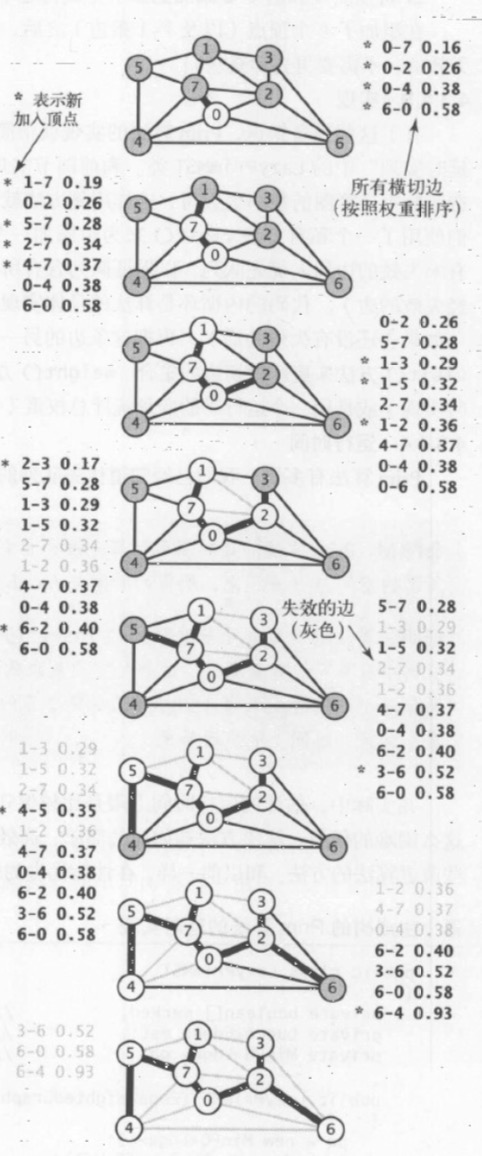
1.將頂點 0 添加到最小生成樹,將它的鄰接鏈表中的所有邊添加到優先隊列中。
2.取權重最小的邊 0-7,將頂點 7 和 邊 0-7 添加到最小生成樹中,將頂點 7 的鄰接鏈表中的所有邊添加到優先隊列中。
3.將頂點 1 和邊 1-7 添加到最小生成樹中,將頂點的鄰接鏈表中的所有邊添加到優先隊列中。
4.將頂點 2 和邊 0-2 添加到最小生成樹,將邊 2-3 和 6-2 添加到優先隊列。邊 2-7 和 1-2 失效(因為邊的兩個頂點都在樹中,最後刪除)。
5.將頂點 3 和邊 2-3 添加到最小生成樹,將邊 3-6 添加到優先隊列。邊 1-3 失效。
6.將頂點 5 和邊 5-7 添加到最小生成樹,將邊 4-5 添加到優先隊列。邊 1-5 失效。
7.從優先隊列刪除失效的邊 1-3,1-5 和 2-7 。
8.將頂點 4 和邊 4-5 添加到最小生成樹中,將邊 6-4 添加到優先隊列。邊 4-7 和 0-4 失效。
9.從優先隊列刪除失效的邊 1-2,4-7 和 0-4 。
10.將頂點 6 和邊 6-2 添加到最小生成樹中,和頂點 6 相關聯的其他邊均失效。
在添加了 V 個頂點以及 V-1 條邊之後,最小生成樹就完成了。優先隊列中剩下的邊都是無效的,可以不用去檢查。
實現
我們使用一個私有方法 Visit()來為樹添加一個頂點,將它標記為「已訪問」並將與它關聯的所有未失效的邊加入優先隊列,以保證隊列含有所有連接樹頂點和非樹頂點的邊(也可能含有一些已失效的邊)。程式碼的內循環是演算法的具體實現:從優先隊列中取出一條邊並將它添加到樹中(如果沒有失效),再把這條邊的另一個頂點也添加到樹中,然後用新頂點作為參數調用 Visit 方法來更新橫切邊的集合。 Weight 方法可以遍歷樹的所有邊並得到權重之和。
namespace MinimumSpanningTrees { public class LazyPrimMST { private bool[] marked;//最小生成樹的頂點 private Queue<Edge> mst;//最小生成樹的邊 private MinPQ<Edge> pq;//橫切邊(包括失效的邊) public LazyPrimMST(EdgeWeightedGraph G) { pq = new MinPQ<Edge>(); marked = new bool[G.V()]; mst = new Queue<Edge>(); Visit(G,0); while (!pq.Count > 0) { Edge e = pq.Dequeue(); int v = e.Either(); int w = e.Other(v); if (marked[v] && marked[w]) continue; pq.Enqueue(e); if (!marked[v]) Visit(G,v); if (!marked[w]) Visit(G,w); } } private void Visit(EdgeWeightedGraph G, int v) { marked[v] = true; foreach (Edge e in G.Adj(v)) { if (!marked[e.Other(v)]) pq.Enqueue(e); } } public IEnumerable<Edge> Edges() { return mst; } public double Weight() { return mst.Sum(o=>o.Weight()); } } }
性能
Prim 演算法的延時實現計算一幅含有 V 個頂點和 E 條邊的連通加權無向圖的最小生成樹所需的空間和 E 成正比,所需的時間與 ElogE成正比(最壞情況)。演算法的瓶頸在於優先隊列的刪除和添加方法中比較邊的權重的次數。優先隊列最多可能含有 E 條邊,這就是空間需求的上限。在最壞情況下,一次插入成本為 ~lgE ,刪除最小元素的成本為 ~2lgE 。因為最多只能插入 E 條邊,刪除 E 次最小元素,時間上限顯而易見。
5. Prim 演算法的即時實現
要改進 LazyPrimMST ,可以嘗試從優先隊列中刪除失效的邊,這樣優先隊列就只有樹頂點和非樹頂點之間的橫切邊,但還可以刪除更多的邊。關鍵在於,我們感興趣的只是連接樹頂點和非樹頂點中權重最小的邊。當我們將頂點 v 添加到樹中,對於每個非樹頂點 w 產生的變化只可能使得 w 到最小生成樹的距離更近。簡而言之,我們不需要在優先隊列中保存所有從 w 到樹頂點的邊 —— 而只需保存其中權重最小的那條。在將 v 添加到樹中後檢查是否需要更新這條權重最小的邊(因為 v-w 的權重可能更小)。我們只需遍歷 v 的鄰接鏈表就可以完成這個任務。換句話說,我們只會在優先隊列中保存每個非樹頂點 w 的一條邊:將它與樹中頂點連起來的權重最小的那條邊。將 w 和樹的頂點連接起來的其他權重較大的邊遲早都會失效,所以沒必要在優先隊列中保存他們。
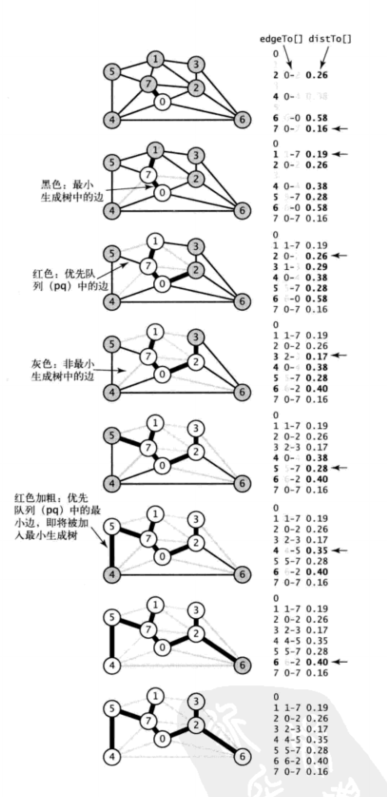
演算法類 PrimMST 將 LazyPrimMST 類中 marked[ ] 和 mst[ ] 替換為兩個頂點索引的數組 edgeTo[ ] 和 distTo[ ] :
1.如果頂點 v 不在樹中但至少含有一條邊和樹相連,那麼 edgeTo[v] 是將 v 和樹連接的最短邊,distTo[v] 為這條邊的權重。
2.所有這類頂點 v 都保存在一條索引優先隊列中,索引 v 關聯的值是 edgeTo[v] 的邊的權重。
這些性質的關鍵在於優先隊列中的最小鍵即是權重最小的橫切邊的權重,而和它相關聯的頂點 v 就是下一個將被添加到樹中的頂點。marked[ ] 數組已經沒有必要了,因為判斷條件 !marked[w] 等價於 distTo[w] 是無窮的(且 edgeTo[w] 為 null)。要維護這些數據結構,PrimMST 會從優先隊列中取出一條邊並檢查它的鄰接鏈表中的每條邊 v-w 。如果 w 已經被標記過,那這條邊就已經失效了;如果 w 不在優先隊列中或者 v-w 的權重小於目前已知的最小值 edgeTo[w],程式碼會更新數組,將 v-w 作為將 w 和樹連接的最佳選擇。
namespace MinimumSpanningTrees { public class PrimMST { private Edge[] edgeTo;//距離樹最近的邊 private double[] distTo;//distTo[w]=edgeTo[w].weight() private bool[] marked;//如果 v 在樹中則為 true public IndexMinPQ<double> pq;//有效的橫切邊 public PrimMST(EdgeWeightedGraph G) { edgeTo = new Edge[G.V()]; distTo = new double[G.V()]; marked = new bool[G.V()]; for (int v = 0; v < G.V(); v++) { distTo[v] = Double.MaxValue; } pq = new IndexMinPQ<double>(G.V()); distTo[0] = 0.0; pq.Insert(0,0.0); //用頂點 0 和權重 0 初始化 pq while (pq.Count > 0) { Visit(G,pq.DelMin());//將最近的頂點添加到樹中 } } private void Visit(EdgeWeightedGraph G, int v) { //將頂點 v 添加到樹中,更新數據 marked[v] = true; foreach (Edge e in G.Adj(v)) { int w = e.Other(v); if (marked[w]) continue; if (e.Weight() < distTo[w]) { edgeTo[w] = e; distTo[w] = e.Weight(); if (pq.Contains(w)) pq.Change(w, distTo[w]); else pq.Insert(w,distTo[w]); } } } } }
Prim 演算法的即時實現計算一幅含有 V 個頂點和 E 條邊的連通加權無向圖的最小生成樹所需的空間和 V 成正比,所需的時間與 ElogV成正比(最壞情況)。
6.Kruskal 演算法
第二種生成最小生成樹的主要思想是按照邊的權重順序(從小到大)處理它們,將邊加入最小生成樹中,加入的邊不會與已經加入的邊構成環,直到樹中含有 V-1 條邊為止。這些邊逐漸由一片森林合共成一棵樹。
為什麼 Kruskal 演算法能夠計算任意加權連通圖的最小生成樹?
如果下一條將被加入最小生成樹中的邊不會和已有的邊構成環,那麼它就跨越了由所有和樹頂點相鄰的頂點組合的合集以及它們的補集所構成的一個切分。因為加入的邊不會形成環,它是目前已知的唯一一條橫切邊且是按照權重順序選擇的邊,所以它必然是權重最小的橫切邊。因此,該演算法能夠連續選擇權重最小的橫切邊,和貪心演算法一致。
Prim 演算法是一條邊一條邊地來構造最小生成樹,每一步都為一棵樹添加一條邊。 Kruskal 演算法構造最小生成樹地時候也是一條邊一條邊地構造,但不同的是它尋找的邊會連接一片森林中的兩棵樹。我們從一片由 V 棵單頂點的樹構成的森林開始並不斷將兩棵樹合併(用可以找到的最短邊)直到只剩下一棵樹,它就是最小生成樹。
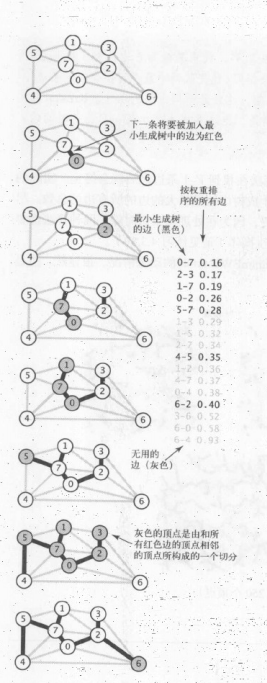
實現
我們將會使用一條優先隊列來將邊按照權重排序,用一個 union-find 數據結構來識別會形成環的邊,以及一條隊列來保存最小生成樹的所有邊。
public class KruskalMST { private Queue<Edge> mst; public KruskalMST(EdgeWeightedGraph G) { mst = new Queue<Edge>();//最小生成樹的邊 MinPQ<Edge> pq = new MinPQ<Edge>(G.Edges);//所有邊 UF uf = new UF(G.V()); while (!pq.IsEmpty() && mst.Count < G.V() - 1) { Edge e = pq.DelMin();//從 pq 得到權重最小的邊和它的頂點 int v = e.Either(), w = e.Other(v); if (uf.Connected(v, w))//忽略失效的邊 continue; uf.Union(v,w);//合併分量 mst.Enqueue(e);//將邊添加到最小生成樹中 } } }
Kruskal 演算法的計算一幅含有 V 個頂點和 E 條邊的連通加權無向圖的最小生成樹所需的空間和 E 成正比,所需的時間和 ElogE 成正比(最壞情況)。
演算法的實現在構造函數中使用所有邊初始化優先隊列,成本最多為 E 次比較(請見 union-find)。優先隊列構造完成後,其餘的部分和 Prim 演算法完全相同。優先隊列中最多可能含有 E 條邊,即所需空間的上限。每次操作的成本最多為 2lgE 次比較,這就是時間上限的由來。 Kruskal 演算法最多還會進行 E 次 Connected() 和 V 次 Union()操作,但這些成本相比 ElogE 的總時間的增長數量級可以忽略不計。
與 Prim 演算法一樣,這個估計是比較保守的,因為演算法在找到 V-1 條邊之後就會終止。實際成本應該與 E+E0 logE 成正比,其中 E0 是權重小於最小生成樹中權重最大的邊的所有邊的總數。儘管擁有這個優勢,Kruskal 演算法一般還是比 Prim 演算法要慢,因為在處理每條邊時,兩種方法都要完成優先隊列操作之外,它還需要進行一次 Connect() 操作。




