RandomAccess介面
序言:許多人看完,ArrayList源碼後,自我感覺良好,一問 RandomAccess 這玩意幹嘛的,一臉懵,
所以今天來盤盤這個介面
RandomAccess介面的作用
咱先看看官方怎麼介紹這個介面的,摘自注釋
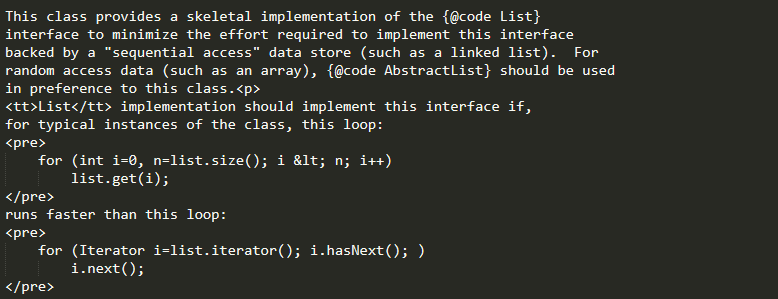
譯:這個介面是被用來List實現的標記介面,支援快速隨機訪問,且只要你實現了它,你使用for循環遍歷,效率會高於迭代器的遍歷(說明一下,這裡說的 for 循環是普通循環,而 增強 for-each 本質就等同於 迭代器遍歷)
//避免自動裝箱拆箱影響,不聲明泛型
List list = new ArrayList<>();
int total = 40000000;
for (int i = 0; i<total; i++){
list.add(i);
}
//1.使用普通for循環的效率
long start1 = System.currentTimeMillis();
for(int i = 0; i < total; i++){
Object temp = list.get(i);
}
long end1 = System.currentTimeMillis();
System.out.println("普通循環的時間效率:" + (end1 - start1));
//2.使用迭代器的循環效率
long start2 = System.currentTimeMillis();
Iterator iterator = list.iterator();
while(iterator.hasNext()){
Object temp = iterator.next();
}
long end2 = System.currentTimeMillis();
System.out.println("迭代器循環的時間效率:" + (end2 - start2));
//3.使用增強for循環(其實底層也是用迭代器玩的)
long start3 = System.currentTimeMillis();
for(Object num: list){
Object temp = num;
}
long end3 = System.currentTimeMillis();
System.out.println("增強for循環的時間效率:" + (end3 - start3));

這裡的隨機訪問,就是能夠隨機的訪問 List 中的任何一個元素,不要想多
雖然所有的 List 實現 都支援隨機訪問,只是由於數據結構不同,導致訪問效率不同。但是這裡的快速隨機訪問,不是所有 List 集合能幹的。
- ArrayList,底層為數組,有下標,指哪打哪,隨機訪問效率 O(1)
- LinkedList,底層為鏈表,訪問一個元素,需要遍歷,隨機訪問效率 O(n)
所以 ArrayList 實現了 RandomAccess,LinkedList 則沒有
實現了 RandomAccess 的介面有:
- ArrayList
- Vector
- CopyOnWriteArrayList
- RandomAccessSubList
- UnmodifiableArrayList
可能你看到這,又有疑問了,我知道這個介面是標誌介面了,實現了它就能快速隨機訪問,所以它有什麼用 ?
在上文中,我們通過測試發現只要實現了這個介面,普通 for 循環的 效率要高於迭代器,所以你可能會說在追求效率的時候我全用 普通 for循環 就行了,這個介面的作用還是沒有凸顯出來。
那麼下面我們看這樣一個測試, 這次測試對象為 LinkedList。
//注意這次我們使用雙線鏈表LinkedList
List list = new LinkedList();
int total = 100000;
for (int i = 0; i<total; i++){
list.add(i);
}
//1.使用普通for循環的效率
long start1 = System.currentTimeMillis();
for(int i = 0; i < total; i++){
Object temp = list.get(i);
}
long end1 = System.currentTimeMillis();
System.out.println("普通循環的時間效率:" + (end1 - start1));
//2.使用迭代器的循環效率
long start2 = System.currentTimeMillis();
Iterator iterator = list.iterator();
while(iterator.hasNext()){
Object temp = iterator.next();
}
long end2 = System.currentTimeMillis();
System.out.println("迭代器循環的時間效率:" + (end2 - start2));

明白了不,不同 List 集合 使用不同的遍歷方式,效率完完全全不一樣,不是使用誰效率就一定高,得看對象是誰
所以如果你有這麼個訴求,你有個List 對象 A,但是它可能是 LinkedList,可能是ArrayList,也可能是 CopyOnWriteArrayList,但是你就想它是以最高效率去遍歷的,這個時候你可以根據這個RandomAccess 去決定以哪種方式去遍歷
if(A instanceof RandomAccess){
//使用普通for循環遍歷
} else {
//使用迭代器遍歷
}
演算法的差異
上文我們提到有沒有實現 RandomAccess介面,會導致不同的集合採取不同的遍歷方式,會有不一樣的訪問效率。但是為什麼會這樣呢,底層是怎麼做的
我們看一下 java.util.Collections#binarySearch
public static <T>
int binarySearch(List<? extends Comparable<? super T>> list, T key) {
if (list instanceof RandomAccess || list.size()<BINARYSEARCH_THRESHOLD)
return Collections.indexedBinarySearch(list, key);
else
return Collections.iteratorBinarySearch(list, key);
}
我們可以看到,在進行二分查找時,會進行判斷是否實現了 RandomAccess介面 從而採取不一樣的遍歷方式
所以看到這你應該明白了,數據結構決定了演算法的根本,RandomAccess介面 僅僅是個標誌介面
不僅是二分查找,底層的普通遍歷也會根據其數據結構選擇相應的執行策略,選對了和數據結構相性匹配的策略當然就快了
總結:數據結構決定演算法