論文閱讀——LIFT: Learned Invariant Feature Transform
- 2020 年 11 月 29 日
- AI
一、概述
本文是一篇非常經典的基於深度學習的局部特徵提取的論文,也是最早將特徵檢測和描述放在一起優化(即joint learning)的論文之一。此前對於局部特徵描述的各個模組,包括興趣點檢測、方向估計和特徵描述,均已有相應的基於CNN的方法提出,其中深度特徵描述這一方向吸引了大部分關注,而興趣點檢測上的成果相對少一些。本文則認為之前對於單獨模組的研究報道的高性能,在實際任務pipeline中可能並不能達到最佳。
局部特徵描述任務(以SIFT和Harris等為代表)通常以完整影像為輸入,首先提取出其中潛在的興趣點,然後對興趣點周圍的鄰域patch提取固定長度的特徵作為其描述。要使用單個神經網路完成該流程,主要難點在於保持梯度流。比如要從檢測模組輸出的特徵圖提取出K個興趣點,這一步通常需要NMS來輔助,而傳統的NMS演算法並不可微。本文為了完成該流程使用了一系列trick,其中很多trick在後續的patch-based文章中(如LF-Net等)均有沿用。從理解論文的角度來說,搞懂本文對於閱讀後續一些流程更複雜的文章比較有幫助。
以下為原文摘要:
我們提出了一種新的深度神經網路結構,該結構實現了完整的特徵點處理管道,即興趣點檢測,方向估計和特徵描述。 儘管先前的工作已成功地單獨解決了每個問題,但我們展示了如何在保持端到端的可區分性的同時以整體的方式完成各個模組的學習。 然後,我們證明了該深度學習的管線在許多基準數據集上無需重新訓練,性能即可超過此前的SOTA方法。
二、方法
由於本文插圖繪製地比較詳細,這一部分就直接結合插圖,以演算法流程的形式記錄LIFT中的主要內容。
首先,本文的CNN以patch為輸入,而非全圖。作者的解釋是這樣可以在不損失資訊的情況下以更輕量級的方式解決該任務,因為全圖中包含關鍵點的patch數量並不多。因此為了得到patch,作者首先需要對整個訓練集通過某種方式提取出興趣點位置。作者構建數據集的步驟大致如下:
-
選擇multi-view的影像來構建訓練數據
-
利用SIFT檢測每張影像的興趣點
-
將multi-view影像利用VisualSFM演算法進行3D重建,剩下的興趣點將作為本文演算法的GT

以下為LIFT的完整預測流程。可見該流程基本是按照傳統的局部特徵提取演算法設計的。

以下為LIFT的訓練過程:




2.1 訓練過程
-
LIFT網路在訓練時需要輸入一個四元對,即P1-4,其中P1和P2代表同一個3D點經不同視角投影得到的2D點對應patch;P3和P1為不同3D點投影的2D點對應patch;P4則為不包含興趣點的patch。
-
對每個patch先使用檢測模組進行預測。該模組較簡單,直接用單層卷積+分段線性激活(來自TILDE論文)對原圖提取特徵並返回一個score map,記為
,其中\mu代表了檢測模型的權重。
-
在對
進行訓練時,不同於TILDE論文中使用sfm得到的關鍵點位置作為S的GT,本文認為S在除了sfm產生的興趣點之外的位置也可以有maxima,這體現在檢測模組的損失設計上。
- 本文早期實驗發現,強行讓檢測模組將興趣點預測為sfm模型得到的位置是有害的。(我的理解應該說的是直接用sfm模型得到的興趣點生成GT score map,然後做強監督的方式)
-
對DET預測的score map提取關鍵點。本文提出可以使用softargmax代替nms,在保持可微的同時實現相似的功能。然後根據提取到的特徵點x和原patch,送入STL(spatial transformer layer)進行crop,得到refine之後的小p(大寫P代表原Patch),該過程記為
-
softargmax是一個用於計算物體質心的函數,其公式如下。softargmax在LF-Net中也有用到。

-
STN在這類任務中扮演著的角色,簡單來說就是可微版本的OpenCV warpPerspective函數,通常都不是訓練模組。
-
-
將p送入方向估計模組,預測出當前patch的方向θ。然後同4中的做法,利用spatial transformer crop將P進行crop,不同的是這次需要考慮在轉換中加入方向資訊。記為pθ=Rot(P,x,θ)
-
注意,送入第二個STL的patch是原始輸入Patch,而非第一個STL crop的patch。說明第一個STL的patch唯一作用在於預測方向。
-
問題:對p估計出的方向θ,是p->pθ的方向還是pθ->p的方向?這裡涉及對STN細節的理解。
-
-
將旋轉之後的patch pθ送入特徵描述網路,提取出固定維度的embedding d
-
根據輸入四元組構建的patch之間的關係,計算檢測、方向估計、特徵描述三個部分的損失:
-
a. 檢測模組:
- 第3步提到,檢測模組如果使用sfm得到的GT score map做強監督可能是有害的。故作者利用P1和P2的關係,利用相同興趣點的可靠性reliability,即最小化d1和d2之間的距離來訓練檢測模組。即下式:

- 此外,作者認為還需要對某個原本包含興趣點的patch在預測中漏檢的情況進行懲罰,體現在損失函數上為:
 image.png
image.png- 這裡的softmax應該是對四個Patch中的每一個,即Pi,輸出其包含興趣點的概率,所以求softmax的維度應該是在??
-
b. 方向估計模組:
-
該模組的優化目標比較隱式,需要反映到下游的特徵提取模組。因為方向估計的目的就是為了使同一個3D點在不同視角下的投影點的描述儘可能接近(描述子的可靠性,或者可重複性)

其中,

- 注意這個式子其實和檢測模組的
基本一樣,唯一的不同在於輸入中的x是已經提取出來的興趣點位置,因此這部分梯度不需要再從x傳遞到輸入P,作者還是很嚴謹的
- 注意這個式子其實和檢測模組的
-
-
c.特徵描述模組:
-
本文的特徵描述部分損失相對來說是很簡單的了,因為patch之間的關係不需要在線構造,而是直接通過輸入構造好的。直接給出損失函數的計算:

-
-






2.2 預測過程
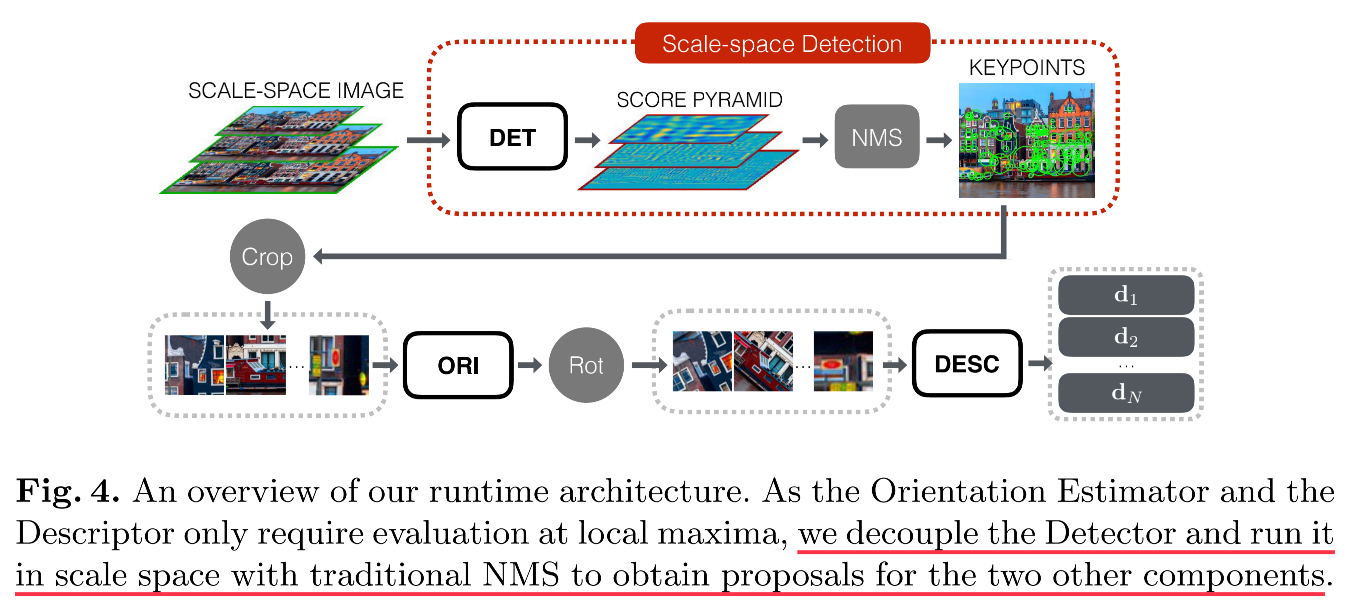
LIFT的預測過程和訓練稍有差異。由於方向估計和特徵描述模組只需要在局部最大值處運行,作者認為可以在預測時將檢測網路和後續兩模組解耦:
- 構建原始大圖輸入的影像金字塔,利用DET預測出score map金字塔(scale space score map,這一概念在LFNet中進一步延伸),然後利用NMS直接估計出所有興趣點坐標
- 再對各個興趣點位置提取patch,分別進行方向估計和特徵描述。
-

三、實驗
-
結果示例(和SIFT對比,每行代表一個測試集)

-
另外,作者做了一個比較有意思的實驗:將LIFT的各個模組分別替換成SIFT的組件,並比較在Strecha數據集上的評估指標:

這個實驗說明,LIFT和SIFT的模組設計高度一致;將LIFT的任意一個模組替換為SIFT都會導致結果下降。




