自己動手實現java數據結構(九) 跳錶
1. 跳錶介紹
在之前關於數據結構的部落格中已經介紹過兩種最基礎的數據結構:基於連續記憶體空間的向量(線性表)和基於鏈式節點結構的鏈表。
有序的向量可以通過二分查找以logn對數複雜度完成隨機查找,但由於插入/刪除元素時可能導致內部數組內整體數據的平移複製,導致隨機插入/刪除的效率較低。而普通的一維鏈表結構雖然可以做到高效的插入/刪除元素(只是關聯的節點拓撲結構改變),但是在隨機查找時卻效率較低,因為其只能從頭/尾節點順序的進行遍歷才能找到對應節點。
電腦科學家發明了能夠兼具向量與鏈表優點的平衡二叉搜索樹(Balance Binary Search Tree BBST),這其中紅黑樹是平均性能最高,也最複雜的一種BBST。
正是因為高性能的平衡二叉樹過於複雜,使得電腦科學家另闢蹊徑,發明了被稱為跳錶(Skip List)的數據結構。跳錶通過建立具有層次結構的索引節點,解決了普通鏈表無法進行二分查找的缺陷。跳錶是基於鏈表的,因此其插入和刪除效率和鏈表一樣優秀;而由於索引節點的引入,也使得跳錶可以以類似二分查找的形式進行特定元素的搜索,其查找性能也達到了O(logn)的對數複雜度,和有序向量以及平衡二叉樹查詢漸進時間複雜度一致。
總的來說,跳錶是一個平均性能很優秀,結構相對簡單的數據結構,在redis以及LevelDB、RocksDB等KV鍵值對資料庫中被廣泛使用。
2. 跳錶工作原理
跳錶查詢:
跳錶是一個擁有多層索引節點的鏈表,最低層是一個鏈表,保存著全部的原始數據節點。而索引節點是建立在最底層鏈表節點之上的,且從下到上索引節點的數量逐漸稀疏。
在查詢時,從最高層開始以類似二分查找的方式跳躍著的逐步向下層逼近查找最終的目標節點。
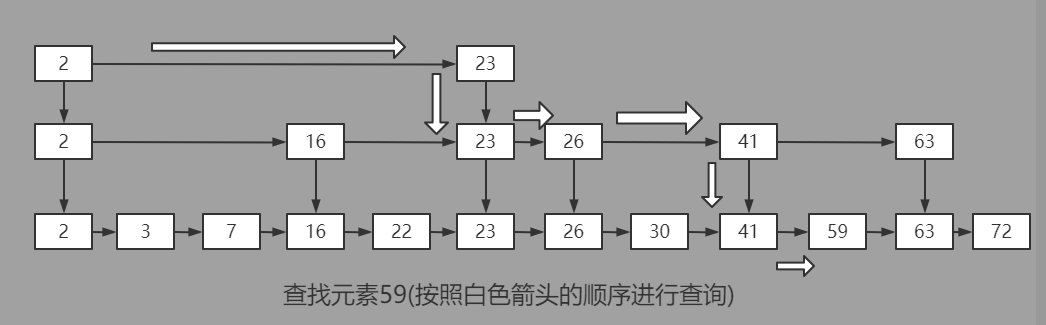
跳錶結構示意圖:
跳錶插入:
了解了跳錶的結構,以及其能夠高效隨機查詢的原理之後。很自然的會想到一個問題,跳錶的索引節點是如何維護的?換句話說,當插入/刪除節點時跳錶的索引結構是如何變化的?
要想保證跳錶高效的查詢效率,需要令跳錶相鄰的上下層節點的數量之比大致為1:2,且同一層索引節點的分布盡量均勻(二分查找)。
一種自然的想法是每次插入新節點時,詳細的檢查每一層的索引節點,精心維護相鄰水平層索引節點1:2的數量,並控制節點排布的稀疏程度(必要時甚至可以重建整個索引)。但這樣使得跳錶的插入性能大大降低,所以實際上跳錶並沒有選擇這種容易想到但低效方式維護索引。
在跳錶中,通過類似丟硬幣的方式,以概率來決定索引節點是否需要被創建。具體的說,每當插入一個新節點時,根據某種概率演算法計算是否需要為其建立上一層的索引節點。如果判斷需要建立,那麼再接著進行一次基於概率的判斷,如果為真則在更高一層也建立索引節點,並循環往複。
假設概率演算法為真的數學期望為1/2,則插入新節點時有50%(1/2)的概率建立第一層的索引節點,25%(1/2^2)的概率建立第兩層的索引節點,12.5%(1/2^3)的概率建立第三層的索引節點,以此類推。這種基於概率的索引節點建立方式,從宏觀的數學期望上也能保證相鄰上下層d的索引節點個數之比為1:2。同時由於插入節點數值的大小和插入順序都是完全隨機的,因此從期望上來說,同一水平層索引節點的分布也是大致均勻的。
總的來說,插入新節點時基於概率的索引建立演算法插入效率相對來說非常高,雖然在極端情況下會導致索引節點上下、水平的分布不均,但依然是非常優秀的實現。同時,可以通過控制概率演算法的數學期望,靈活的調整跳錶的空間佔用與查詢效率的取捨(概率演算法為真的數學期望從1/2降低到1/4時,建立上級索引的概率降低,索引的密度下降,因此其隨機查詢效率降低,但其索引節點將會大大減少以節約空間,跳錶的這一特性在對空間佔用敏感的記憶體資料庫應用中是很有價值的)。
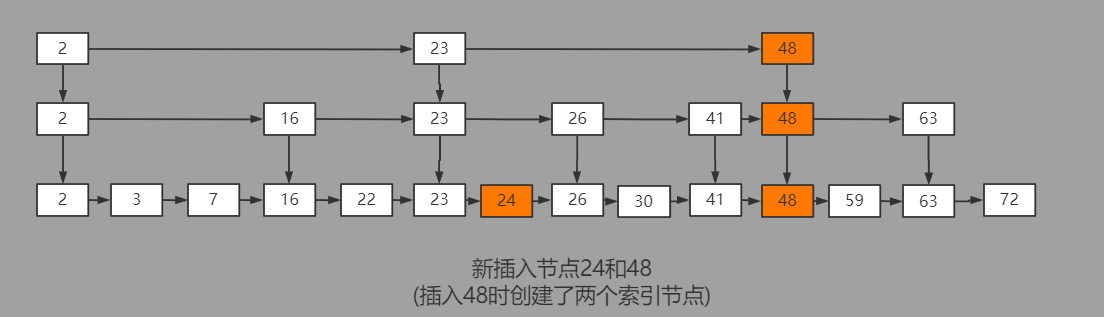
跳錶插入節點示意圖:
跳錶刪除:
在理解了跳錶插入的原理後,跳錶的刪除就很好理解了。當最底層的數據節點被刪除時,只需要將其之上的所有索引節點一併刪除即可。
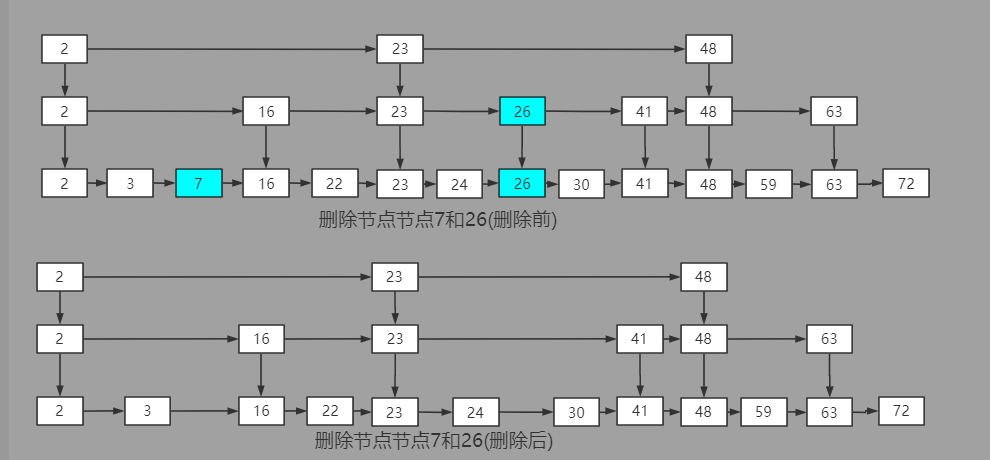
跳錶刪除節點示意圖:
3. 跳錶實現細節
下面介紹跳錶的實現細節。本篇部落格的跳錶SkipListMap是用java實現的,為了令程式碼更容易理解,在一些地方選擇了效率相對較低,但更容易理解的實現。
跳錶節點實現
為了令整個跳錶的實現更加簡單,局別與jdk的ConcurrentSkipListMap。當前版本跳錶的定義的節點結構既用於最底層的數據節點,也用於上層的索引節點;且節點持有上、下、左、右關聯的四個節點的引用。在每一水平層引入了左右兩個哨兵節點,通過節點中的NodeType枚舉區分哨兵節點與普通的索引/數據節點。
為了能夠在後續介紹的插入/刪除等操作中,更加簡單的定位到臨近的節點,簡化程式碼的理解難度。相比jdk、redis等工程化的高性能跳錶實現,當前版本實現的跳錶節點冗餘了一些不必要的欄位屬性以及額外的哨兵節點,額外的浪費了一些空間,但跳錶實現的核心思路是一致的。
跳錶Node節點定義:
private static class Node<K,V> implements EntryNode<K,V>{ K key; V value; Node<K,V> left; Node<K,V> right; Node<K,V> up; Node<K,V> down; NodeType nodeType; private Node(K key,V value) { this.key = key; this.value = value; this.nodeType = NodeType.NORMAL; } private Node() { } private Node(NodeType nodeType) { this.nodeType = nodeType; } /** * 將一個節點作為"當前節點"的"右節點" 插入鏈表 * @param node 需要插入的節點 * */ private void linkAsRight(Node<K,V> node){ // 先設置新增節點的 左右節點 node.left = this; node.right = this.right; // 將新增節點插入 當前節點和當前節點的左節點之間 this.right.left = node; this.right = node; } /** * 將"當前節點"從當前水平鏈表移除(令其左右節點直接牽手) * */ private void unlinkSelfHorizontal(){ // 令當前鏈表的 左節點和右節點建立關聯 this.left.right = this.right; // 令當前鏈表的 右節點和左節點建立關聯 this.right.left = this.left; } /** * 將"當前節點"從當前垂直鏈表移除(令其上下節點直接牽手) * */ private void unlinkSelfVertical(){ // 令當前鏈表的 左節點和右節點建立關聯 this.up.down = this.down; // 令當前鏈表的 右節點和左節點建立關聯 this.down.up = this.up; } @Override public String toString() { if(this.key != null){ return "{" + "key=" + key + ",value=" + value + '}'; }else{ return "{" + "nodeType=" + nodeType + '}'; } } @Override public K getKey() { return this.key; } @Override public V getValue() { return this.value; } @Override public void setValue(V value) { this.value = value; } }
NodeType枚舉:
private enum NodeType{ /** * 普通節點 * */ NORMAL, /** * 左側哨兵節點 * */ LEFT_SENTINEL, /** * 右側哨兵節點 * */ RIGHT_SENTINEL, ; }
跳錶的基礎結構
跳錶是一個能夠支援高效增刪改查、平均性能很高的數據結構,對標的是紅黑樹為首的平衡二叉搜索樹。因此在我們參考jdk的實現,跳錶和之前系列部落格中的TreeMap一樣也實現了Map介面。
跳錶的每一個水平層是從左到右,有小到大進行排序的,具體的比較邏輯由compare函數來完成。
跳錶定義:
public class SkipListMap<K,V> extends AbstractMap<K,V>{ private Node<K,V> head; private Node<K,V> tail; private Comparator<K> comparator; private int maxLevel; private int size; /** * 插入新節點時,提升的概率為0.5,期望保證上一層和下一層元素的個數之比為 1:2 * 以達到查詢節點時,log(n)的對數時間複雜度 * */ private static final double PROMOTE_RATE = 1.0/2.0; private static final int INIT_MAX_LEVEL = 1; public SkipListMap() { // 初始化整個跳錶結構 initialize(); } public SkipListMap(Comparator<K> comparator) { this(); // 設置比較器 this.comparator = comparator; } private void initialize(){ this.size = 0; this.maxLevel = INIT_MAX_LEVEL; // 構造左右哨兵節點 Node<K,V> headNode = new Node<>(); headNode.nodeType = NodeType.LEFT_SENTINEL; Node<K,V> tailNode = new Node<>(); tailNode.nodeType = NodeType.RIGHT_SENTINEL; // 跳錶初始化時只有一層,包含左右哨兵兩個節點 this.head = headNode; this.tail = tailNode; // 左右哨兵牽手 this.head.right = this.tail; this.tail.left = this.head; } 。。。。。。 }
compare比較邏輯實現:
private int doCompare(K key1,K key2){ if(this.comparator != null){ // 如果跳錶被設置了比較器,則使用比較器進行比較 return this.comparator.compare(key1,key2); }else{ // 否則強制轉換為Comparable比較(對於沒有實現Comparable的key會拋出強制類型轉換異常) return ((Comparable)key1).compareTo(key2); } }
跳錶查詢實現
跳錶實現的一個關鍵就是如何進行快速的隨機查找。
對於指定key的查找,首先從最上層的跳錶head節點開始,從左到右的進行比對,當找到一個節點比key小,而且其相鄰的右節點比key大時,則沿著找到的節點進入下一層繼續查找。(每一個水平層的左哨兵節點視為無窮小,而右哨兵節點視為無窮大)
由於跳錶的相鄰上下兩層的節點稀疏程度不同,進入下一水平層更有可能逼近指定key對應的數據節點。通過在水平層大跨步的跳躍,並在對應的節點處進入下一層,循環往複的如此操作直到最底層。跳躍式的進行鏈表節點的查找方式,也是跳錶名稱SkipList的來源。
從程式碼實現中可以看到,跳錶通過建立在其上的索引節點進行查找,比起原始的一維鏈表,能夠更快的定位到所要查找的節點。且如果按照概率演算法構建的索引節點分布比較平均的話,跳錶的查找效率將能夠媲美有序向量、平衡二叉樹的查找效率。
跳錶查找方法實現:
/** * 找到最逼近參數key的前驅數據節點 * (返回的節點的key並不一定等於參數key,也有可能是最逼近的) * */ private Node<K,V> findPredecessorNode(K key){ // 從跳錶頭結點開始,從上層到下層逐步逼近 Node<K,V> currentNode = head; while(true){ // 當前遍歷節點的右節點不是右哨兵,且data >= 右節點data while (currentNode.right.nodeType != NodeType.RIGHT_SENTINEL && doCompare(key,currentNode.right.key) >= 0){ // 指向同一層的右節點 currentNode = currentNode.right; } // 跳出了上面循環,說明找到了同層最接近的一個節點 if(currentNode.down != null){ // currentNode.down != null,未到最底層,進入下一層中繼續查找、逼近 currentNode = currentNode.down; }else{ // currentNode.down == null,說明到了最下層保留實際節點的,直接返回 // (currentNode.key並不一定等於參數key,可能是最逼近的前綴節點) return currentNode; } } } /** * 找到key對應的數據節點 * 如果沒有找到,返回null * */ private Node<K,V> searchNode(K key){ Node<K,V> preNode = findPredecessorNode(key); if(preNode.key != null && Objects.equals(preNode.key,key)){ return preNode; }else{ return null; } }
跳錶插入實現
跳錶在插入節點的過程中,首先通過findProdecessorNode查詢到最逼近key的前驅數據節點,如果發現當前key並不存在,則在最底層的數據節點鏈表中插入新的數據節點。
在新的數據節點插入完成後,根據random生成一個0-1之間的隨機數,與定義的PROMOTE_RATE常量進行比對,判斷是否需要為當前新插入的節點創建更上一層的索引節點。這一比對可能會進行多次,相對應的也會為新插入節點在垂直方向上創建更多的索引節點。
跳錶插入程式碼:
private Node<K,V> putNode(K key,V value){ if(key == null){ throw new RuntimeException("key required"); } // 從最底層中,找到其直接最接近的前驅節點 Node<K,V> predecessorNode = findPredecessorNode(key); if(Objects.equals(key,predecessorNode.key)){ // data匹配,已經存在,直接返回false代表未插入成功 return predecessorNode; } // 當前跳錶元素個數+1 this.size++; // 之前不存在,需要新插入節點 Node<K,V> newNode = new Node<>(key,value); // 將新節點掛載至前驅節點之後 predecessorNode.linkAsRight(newNode); int currentLevel = INIT_MAX_LEVEL; Random random = new Random(); Node<K,V> hasUpNodePredecessorNode = predecessorNode; Node<K,V> newNodeUpperNode = newNode; boolean doPromoteLevel = false; while (random.nextDouble() < PROMOTE_RATE && !doPromoteLevel) { // 當前插入的節點需要提升等級,在更高層插入索引節點 if(currentLevel == this.maxLevel){ promoteLevel(); // 保證一次插入節點,做多只會提升一層(否則將會有小概率出現高位的許多層中只有極少數(甚至只有1個)元素的情況) doPromoteLevel = true; } // 找到上一層的前置節點 while (hasUpNodePredecessorNode.up == null) { // 向左查詢,直到找到最近的一個有上層節點的前驅節點 hasUpNodePredecessorNode = hasUpNodePredecessorNode.left; } // 指向上一層的node hasUpNodePredecessorNode = hasUpNodePredecessorNode.up; Node<K,V> upperNode = new Node<>(key,value); // 將當前data的up節點和上一層最接近的左上的node建立連接 hasUpNodePredecessorNode.linkAsRight(upperNode); // 當前data這一列的上下節點建立關聯 upperNode.down = newNodeUpperNode; newNodeUpperNode.up = upperNode; // 由於當前data節點可能需要在更上一層建立索引節點,所以令newNodeUpperNode指向更上層的up節點 newNodeUpperNode = newNodeUpperNode.up; // 當前迭代層次++ currentLevel++; } return null; }
在通過概率演算法決定是否建立更高層索引節點的過程中,有可能需要額外的再升高一層。這時需要通過promoteLevel方法將整個跳錶的水平層抬高一層,並令跳錶的head作為新增水平層的左哨兵節點。
promoteLevel方法實現:
/** * 提升當前跳錶的層次(在當前最高層上建立一個只包含左右哨兵的一層,並令跳錶的head指向左哨兵) * */ private void promoteLevel(){ // 最大層數+1 this.maxLevel++; // 當前最高曾左、右哨兵節點 Node<K,V> upperLeftSentinel = new Node<>(NodeType.LEFT_SENTINEL); Node<K,V> upperRightSentinel = new Node<>(NodeType.RIGHT_SENTINEL); // 最高層左右哨兵牽手 upperLeftSentinel.right = upperRightSentinel; upperRightSentinel.left = upperLeftSentinel; // 最高層的左右哨兵,和當前第一層的head/right建立上下連接 upperLeftSentinel.down = this.head; upperRightSentinel.down = this.tail; this.head.up = upperLeftSentinel; this.tail.up = upperRightSentinel; // 令跳錶的head/tail指向最高層的左右哨兵 this.head = upperLeftSentinel; this.tail = upperRightSentinel; }
跳錶刪除實現
跳錶的刪除相對簡單,在找到需要被刪除的最底層數據節點之後,通過up引用找到其對應的所有索引節點刪除即可。
當刪除某一索引節點後,如果發現對應水平層只剩下左/右哨兵時,還需要通過destoryLevel方法將對應的水平層刪除。
跳錶刪除節點:
private Node<K,V> removeNode(Node<K,V> needRemoveNode){ if (needRemoveNode == null){ // 如果沒有找到對應的節點,不需要刪除,直接返回 return null; } // 當前跳錶元素個數-1 this.size--; // 保留需要返回的最底層節點Node Node<K,V> returnCache = needRemoveNode; // 找到了對應節點,則當前節點以及其所有層的up節點都需要被刪除 int currentLevel = INIT_MAX_LEVEL; while (needRemoveNode != null){ // 將當前節點從該水平層的鏈表中移除(令其左右節點直接牽手) needRemoveNode.unlinkSelfHorizontal(); // 當該節點的左右都是哨兵節點時,說明當前層只剩一個普通節點 boolean onlyOneNormalData = needRemoveNode.left.nodeType == NodeType.LEFT_SENTINEL && needRemoveNode.right.nodeType == NodeType.RIGHT_SENTINEL; boolean isLowestLevel = currentLevel == INIT_MAX_LEVEL; if(!isLowestLevel && onlyOneNormalData){ // 不是最底層,且只剩當前一個普通節點了,需要刪掉這一層(將該層的左哨兵節點傳入) destroyLevel(needRemoveNode.left); }else{ // 不需要刪除該節點 currentLevel++; } // 指向該節點的上一點 needRemoveNode = needRemoveNode.up; } return returnCache; }
跳錶刪除水平層destoryLevel實現:
private void destroyLevel(Node<K,V> levelLeftSentinelNode){ // 最大層數減1 this.maxLevel--; // 當前層的右哨兵節點 Node<K,V> levelRightSentinelNode = levelLeftSentinelNode.right; if(levelLeftSentinelNode == this.head){ // 需要刪除的是當前最高層(levelLeftSentinelNode是跳錶的頭結點) // 令下一層的左右哨兵節點的up節點清空 levelLeftSentinelNode.down.up = null; levelRightSentinelNode.down.up = null; // 令跳錶的head/tail指向最高層的左右哨兵 this.head = levelLeftSentinelNode.down; this.tail = levelRightSentinelNode.down; }else{ // 需要刪除的是中間層 // 移除當前水平層左哨兵,令其上下節點建立連接 levelLeftSentinelNode.unlinkSelfVertical(); // 移除當前水平層右哨兵,令其上下節點建立連接 levelRightSentinelNode.unlinkSelfHorizontal(); } }
4. 跳錶性能分析
跳錶空間效率分析
高效的跳錶實現(例如jdk的ConcurrentSkipListMap)相對於本篇部落格的簡易版實現,上層的索引節點只需要持有down和right兩個關聯節點的引用即可(K/V引用也可以簡化為對底層數據節點的引用),而最底層的數據節點則僅維護關聯的right節點即可。同時,通過邊界條件的判斷,也並不需要水平層的左右哨兵節點。
可以看到,高效跳錶的空間效率其實很高,其空間佔用正比於數據節點的數目,漸進的空間複雜度為O(n)。在redis的zset實現中,就是使用跳錶作為其底層實現的。redis的zset跳錶實現中,建立上一級索引節點的概率被設置為1/4,綜合來看每個節點所持有的平均引用數量大約為1.33,比紅黑樹節點2個引用(左右孩子節點,都不考慮value的引用)的空間效率要高。
跳錶時間效率分析
跳錶的查詢性能
跳錶通過概率演算法建立起了均勻分布的索引節點層(從數學期望上來看是均勻分布的,但存在一定波動),能夠以正比於跳錶層數的O(logn)對數時間複雜度完成隨機查詢。
跳錶的查詢操作效率與跳錶的層數有關,因此跳錶查詢操作的漸進時間複雜度為O(logn)。
跳錶和哈希表在對空間/時間的取捨上類似,哈希表可以通過調整負載因子進行空間效率與查詢時間效率的取捨;而跳錶也可以通過設置增加上一層索引節點的概率來調節查詢效率與空間效率。
跳錶的插入性能
跳錶的插入依賴於跳錶的查詢(logn),且需要根據概率決定是否創建對應的上一層索引節點。在最壞情況下,可能需要創建n+1個索引節點(n為跳錶當前層數,1表示可能會增加新的一層);最好情況下不需要創建任何索引節點。
跳錶的插入操作效率與跳錶的層數有關,因此跳錶插入操作的漸進時間複雜度為O(logn)。
跳錶的刪除性能
跳錶的刪除同樣依賴於跳錶的查詢,刪除最底層數據節點時也需要將被刪除節點對應的索引節點一併刪除。在最壞情況下,可能需要刪除至多n個索引節點(n為跳錶層數),最好情況下不需要刪除任何索引節點。
跳錶的刪除操作效率與跳錶的層數有關,因此跳錶刪除操作的漸進時間複雜度為O(logn)。
為什麼redis使用跳錶而不是紅黑樹實現ZSET?
下面是redis作者給出的回答:
1) They are not very memory intensive. It』s up to you basically. Changing parameters about the probability of a node to have a given number of levels will make then less memory intensive than btrees.
2) A sorted set is often target of many ZRANGE or ZREVRANGE operations, that is, traversing the skip list as a linked list. With this operation the cache locality of skip lists is at least as good as with other kind of balanced trees.
3) They are simpler to implement, debug, and so forth. For instance thanks to the skip list simplicity I received a patch (already in Redis master) with augmented skip lists implementing ZRANK in O(log(N)). It required little changes to the code.
大致的翻譯:
1) 跳錶是否很消耗記憶體,這取決於你。通過改變提升跳錶節點索引等級的概率參數可以令跳錶的記憶體消耗少於B樹。
2) 一個有序集合通常被作為ZRANGE或是ZREVERANGE操作的目標。也就是說,通常是以鏈表的形式來遍歷跳錶的,在這種遍歷操作下,快取了相鄰節點位置的跳錶性能將至少和其它類型的自平衡樹一樣優秀。
3) 跳錶更容易實現和調試,等等。得益於跳錶的簡單性,我收到了一個能夠在跳錶中以O(logN)效率實現ZRANK的修補程式(已經在redis的master分支中了),而這隻需要對程式碼稍作修改。
經過前面部落格中對跳錶原理的介紹,是否對redis作者的回答有了更深的體會呢?
5.總結
通過自己的思路實現了一個簡易版的跳錶之後,理解了跳錶的設計思想,也使得我有能力更進一步的去理解jdk、redis中更為高效的跳錶實現。同時也加深了對跳錶、平衡二叉樹、哈希表等不同數據結構的理解,以及如何在不同場景下應該如何選擇更高效、更符合實際需求的數據結構。
本系列部落格的程式碼在我的 github上://github.com/1399852153/DataStructures (SkipListMap類),存在許多不足之處,還請多多指教。


