Mesos Marathon能做什麼?理念是什麼?(轉)
Mesos功能和特點?
Mesos是如何實現整個數據中心統一管理的呢?
核心的概念就是資源兩級供給和作業兩級調度。先說說從下而上的資源兩級供給吧。
- 在Mesos集群中,資源的供應方都來自Mesos Slave所在的物理節點。資源可以包括CPU、記憶體、存儲空間、IO吞吐能力等
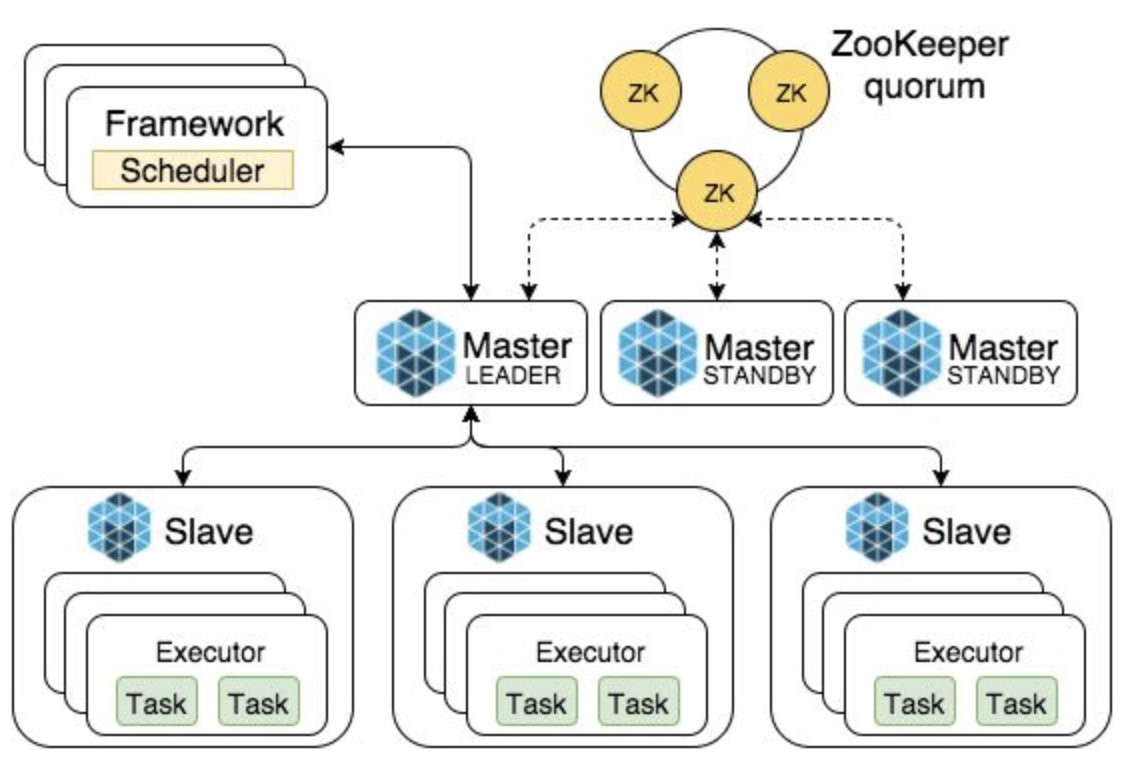
圖片來自mesos.apache.org,圖⽚片版權歸屬原作者
這些資源通過供給的方式,從Mesos Slave提供給了Mesos Master的Leader。(具體的領導者選舉過程將在後續容器編排章節詳細闡述)這就是第一級的資源供給。 - Mesos master進一步將資源整合後,作為可選項提供給了各種framework框架。這些框架中最主流的就是Marathon長服務框架,但也可能是其他如Jenkins CI/CD框架、Spark大數據框架、Kafka中間件框架、Chronos任務管理框架、Aurora應用管理框架等。各種框架可以有選擇地對Mesos Master整合後的數據中心資源提出要求。

而Mesos和各種框架對於資源的要求處理過程,正是從上而下的兩級調度機制的核心:
- 首先,各個框架都有自己的調度器Scheduler,它會根據用戶需求啟動特定的工作任務。調度器在上層第一級確定工作任務需要的資源情況,是否需要接受Mesos提供的CPU、記憶體和存儲資源來運行特定的工作負載。
- 同時Mesos對於上層框架的需求也不是予取予求。他會採用默認的DRF優勢資源公平演算法(Dominant Resource Faireness)來決定各種框架任務的資源分配情況,從而使整個數據中心利益最大化。比如上層框架中的Marathon調度器需要啟動Nginx任務,而同時Spark框架需要啟動streaming任務,Mesos的DRF演算法會根據框架提出的資源請求,將盡量多的記憶體和CPU分配給Nginx用於進行反向代理服務,同時將儘可能多的IO吞吐性能提供給Spark進行流處理。
Mesos的主要特點包括:
- 輕量級的master:僅保留了framework和slave的一些狀態,易於重構,因此採用zookeeper很容易解決HA問題
- 配合container技術的slave:利用Linux-Container和Docker技術可以實現很方便地實現任務間的CPU與記憶體資源隔離
- 資源分配調度比較簡單:默認的DRF演算法可以輕鬆實現資源的最大化利用,不需要複雜的人工干預和配置
Marathon功能和特點?
一個作業系統有了優秀的內核只是完成了一半工作,強大易用的服務管理(如init、systemd系統等)才是作業系統得以生存發展的另一半天。
相同的道理,有了Mesos這個分散式作業系統內核,還得有一個可以支援分散式的長服務運行調度框架,這就是Marathon。
圖片來自360doc.com,圖⽚片版權歸屬原作者
Marathon的主要特點有:
- 高可用性:Marathon作為主動/被動群集運行,領導者選舉可以實現100%的高可用運行時間。
- 資源分布可控:可以允許每個機架/節點等僅放置應用程式的一個實例,從而緩解單點故障的影響。
- 服務發現和負載平衡:可以通過HA Proxy和DNS等方式自動實現負載均衡。
- 健康檢查:可以使用HTTP或TCP檢查評估應用程式的運行狀況。
- 活動訂閱:提供HTTP端點以接收通知。例如,與外部負載均衡器集成。
- UI:美麗而強大的UI。
- API:完整的REST API,易於集成和編寫腳本.
- 安全:Basic Auth和SSL
- 監控:以JSON格式在/metrics查詢它們或將它們推送到諸如graphite,statsd和Datadog之類的系統。
使用場景
如果想運行長生命周期的應用服務(而不是短時作業等),想將數據中心的多種形式的任務結合管理(如CI/CD連續集成連續部署、大數據、消息中間件、搜索引擎等),但應用之間不需要太強的集群耦合(如Oracle資料庫心跳、Keepalive節點心跳等),Mesos+Marathon這一對數據中心作業系統解決方案,可以成為您的首選。

