python爬蟲分析報告
在python課上布置的作業,第一次進行爬蟲,走了很多彎路,也學習到了很多知識,藉此記錄。
1. 獲取學堂在線合作院校頁面
要求:
爬取學堂在線的電腦類課程頁面內容。
要求將課程名稱、老師、所屬學校和選課人數資訊,保存到一個csv文件中。
鏈接://www.xuetangx.com/search?query=&org=&classify=1&type=&status=&page=1
1.確定目標
打開頁面,通過查看網頁源程式碼並沒有相關內容。可以猜測具體數據由前端通過ajax請求後端具體數據。在開發者工具中,捕獲了如下的json數據:
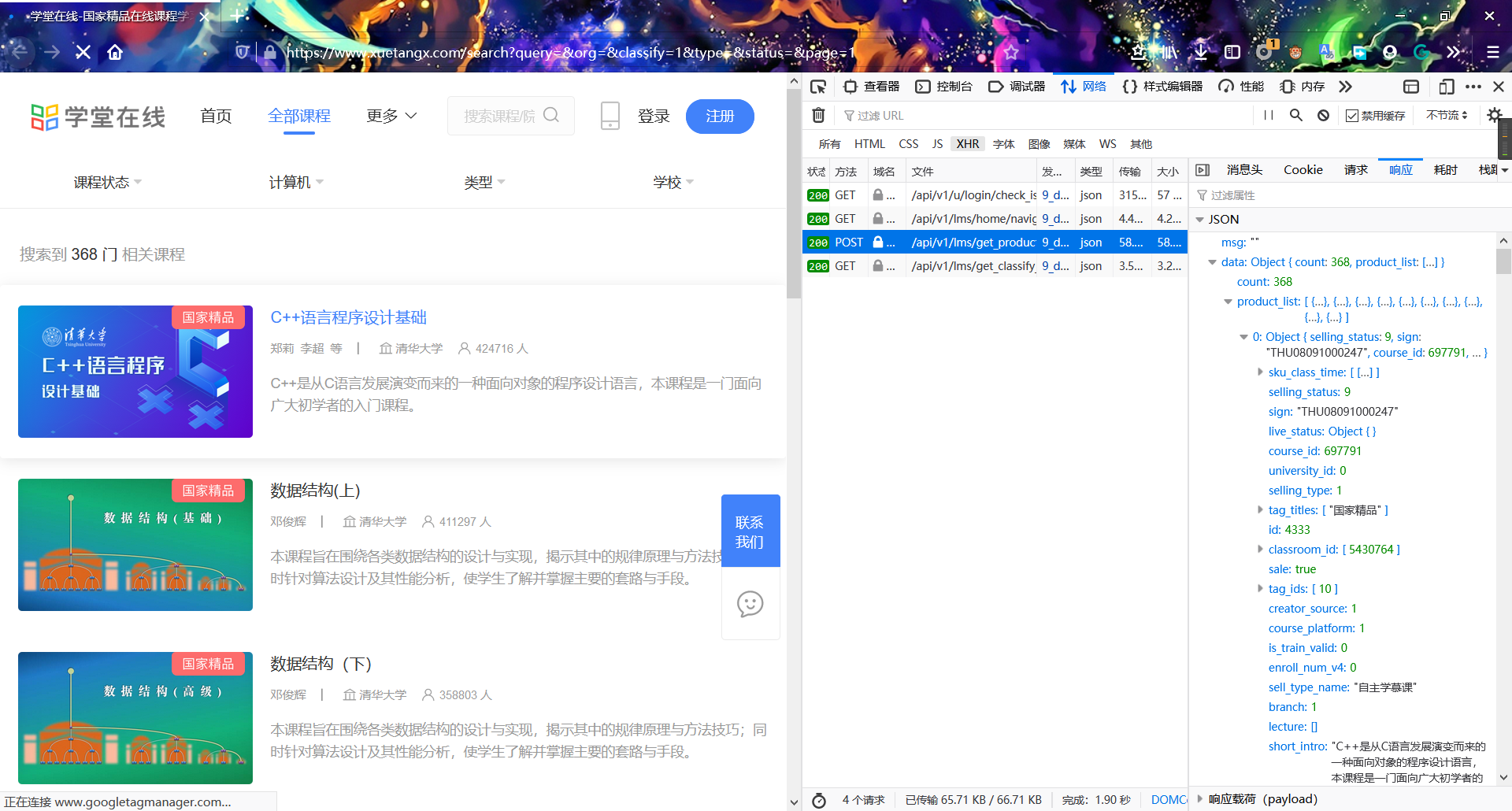
可以看到這個就是我們要求的json數據。考慮如何獲取json數據並取出來,分析一下瀏覽器的請求,將cURL命令轉換成Python請求如下:
import requests
cookies = {
'provider': 'xuetang',
'django_language': 'zh',
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0',
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'zh',
'Content-Type': 'application/json',
'django-language': 'zh',
'xtbz': 'xt',
'x-client': 'web',
'Origin': '//www.xuetangx.com',
'Connection': 'keep-alive',
'Referer': '//www.xuetangx.com/search?query=&org=&classify=1&type=&status=&page=1',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache',
'TE': 'Trailers',
}
params = (
('page', '1'),
)
data = '{query:,chief_org:[],classify:[1],selling_type:[],status:[],appid:10000}'
response = requests.post('//www.xuetangx.com/api/v1/lms/get_product_list/', headers=headers, params=params, cookies=cookies, data=data)
#NB. Original query string below. It seems impossible to parse and
#reproduce query strings 100% accurately so the one below is given
#in case the reproduced version is not "correct".
# response = requests.post('//www.xuetangx.com/api/v1/lms/get_product_list/?page=1', headers=headers, cookies=cookies, data=data)
分析請求的網頁是//curl.trillworks.com/,可以在瀏覽器的開發工具里,選擇network選項卡(chrome)或者網路選項卡(Firefox),右鍵點擊某個請求文件,在菜單中選擇複製→複製為cURL命令,然後到這個網頁中粘貼轉換為python的request即可
2.設計爬蟲
要選取的數據為課程名稱、老師、所屬學校和選課人數。設計的items.py如下:
# items.py
import scrapy
class XuetangItem(scrapy.Item):
name = scrapy.Field()
teachers = scrapy.Field()
school = scrapy.Field()
count = scrapy.Field()
pass
接下來是重頭戲設計spider.py文件。因為爬取的是json數據而不是html靜態頁面,需要設計start_requests函數來發送請求。結合之前分析的Python request,具體程式碼如下:
import scrapy
import json
from xuetang.items import XuetangItem
class mySpider(scrapy.spiders.Spider):
name = "xuetang"
allowed_domains = ["www.xuetangx.com/"]
url = "url_pat = '//www.xuetangx.com/api/v1/lms/get_product_list/?page={}'"
data = '{"query":"","chief_org":[],"classify":["1"],"selling_type":[],"status":[],"appid":10000}'
# data由分析中得來
headers = {
'Host': 'www.xuetangx.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0',
'authority': 'www.xuetangx.com',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh',
'Accept-Encoding': 'gzip, deflate, br',
'django-language': 'zh',
'xtbz': 'xt',
'content-type': 'application/json',
'x-client': 'web',
'Connection': 'keep-alive',
'Referer': '//www.xuetangx.com/university/all',
'Cookie': 'provider=xuetang; django_language=zh',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache'
}
# 直接從瀏覽器抄過來,防止伺服器辨析到不是瀏覽器而導致失敗
def start_requests(self):
for page in range(1, 6):
yield scrapy.FormRequest(
url=self.url.format(page),
headers=self.headers,
method='POST',
# 瀏覽器的請求是POST,而且響應頭中寫明只允許POST
body=self.data,
callback=self.parse
)
def parse(self, response):
j = json.loads(response.body)
for each in j['data']['org_list']:
item = XuetangItem()
item['name'] = each['name']
item['school'] = each['org']['name']
item['count'] = each['count']
teacher_list = []
for teacher in each['teacher']:
teacher_list.append(teacher['name'])
# 因為有些課程有多個老師,需要逐個保存,寫入一條記錄里
item['teacher'] = ','.join(teacher_list)
yield item
然後設計pipelines.py文件,將爬取到的數據保存為csv文件:
import csv
class XuetangPipeline(object):
dict_data = {'data': []}
def open_spider(self, spider):
try:
self.file = open('data.csv', "w", encoding="utf-8", newline='')
self.csv = csv.writer(self.file)
except Exception as err:
print(err)
def process_item(self, item, spider):
self.csv.writerow(list(item.values()))
return item
def close_spider(self, spider):
self.file.close()
這樣就可以就行爬蟲了,當然還要在setting.py中設置ITEM_PIPELINES。之後可以命令行啟動爬蟲,也可以運行執行cmd命令的python文件:
from scrapy import cmdline
cmdline.execute("scrapy crawl xuetang".split())
3.數據展示
保存的csv文件內容如下,正好內容為50條,這裡僅展示開頭一部分:
C++語言程式設計基礎,清華大學,424718,"鄭莉,李超,徐明星"
數據結構(上),清華大學,411298,鄧俊輝
數據結構(下),清華大學,358804,鄧俊輝
……
2. 獲取鏈家二手房資訊
要求:
爬取鏈家官網二手房的數據 //bj.lianjia.com/ershoufang/
要求爬取北京市東城、西城、海淀和朝陽四個城區的數據(每個區爬取5頁),將樓盤名稱、總價、平米數、單價保存到json文件中。
1.確定目標
打開網頁,查看網頁源程式碼,可以看到在源程式碼中間已經包含了二手房資訊,說明頁面由後端渲染完畢後返回到瀏覽器,這樣可以通過Xpath來爬取相關內容。分析一下某個樓盤的資訊結構:
<html>
<head></head>
<body>
<a class="noresultRecommend img LOGCLICKDATA" href="//bj.lianjia.com/ershoufang/101109392759.html" target="_blank" data-log_index="1" data-el="ershoufang" data-housecode="101109392759" data-is_focus="" data-sl="">
<!-- 熱推標籤、埋點 -->
<img src="//s1.ljcdn.com/feroot/pc/asset/img/vr/vrgold.png?_v=202011171709034" class="vr_item" /><img class="lj-lazy" src="//image1.ljcdn.com/110000-inspection/pc1_hAjksKeSW_1.jpg.296x216.jpg" data-original="//image1.ljcdn.com/110000-inspection/pc1_hAjksKeSW_1.jpg.296x216.jpg" alt="北京西城長椿街" style="display: block;" /></a>
<div class="info clear">
<div class="title">
<a class="" href="//bj.lianjia.com/ershoufang/101109392759.html" target="_blank" data-log_index="1" data-el="ershoufang" data-housecode="101109392759" data-is_focus="" data-sl="">槐柏樹街南里 南北通透兩居室 精裝修</a>
<!-- 拆分標籤 只留一個優先順序最高的標籤-->
<span class="goodhouse_tag tagBlock">必看好房</span>
</div>
<div class="flood">
<div class="positionInfo">
<span class="positionIcon"></span>
<a href="//bj.lianjia.com/xiaoqu/1111027374889/" target="_blank" data-log_index="1" data-el="region">槐柏樹街南里 </a> -
<a href="//bj.lianjia.com/ershoufang/changchunjie/" target="_blank">長椿街</a>
</div>
</div>
<div class="address">
<div class="houseInfo">
<span class="houseIcon"></span>2室1廳 | 60.81平米 | 南 北 | 精裝 | 中樓層(共6層) | 1991年建 | 板樓
</div>
</div>
<div class="followInfo">
<span class="starIcon"></span>226人關注 / 1個月以前發布
</div>
<div class="tag">
<span class="subway">近地鐵</span>
<span class="isVrFutureHome">VR看裝修</span>
<span class="five">房本滿兩年</span>
<span class="haskey">隨時看房</span>
</div>
<div class="priceInfo">
<div class="totalPrice">
<span>600</span>萬
</div>
<div class="unitPrice" data-hid="101109392759" data-rid="1111027374889" data-price="98668">
<span>單價98668元/平米</span>
</div>
</div>
</div>
<div class="listButtonContainer">
<div class="btn-follow followBtn" data-hid="101109392759">
<span class="follow-text">關注</span>
</div>
<div class="compareBtn LOGCLICK" data-hid="101109392759" log-mod="101109392759" data-log_evtid="10230">
加入對比
</div>
</div>
</body>
</html>
可以看到房子的名稱在class=”title”的div下的a標籤內,平米數保存在class=”houseInfo”的div里,但需要截取一下字元串,單價和總價均保存在class=”priceInfo”的div中,有趣的是有些資訊沒有單價顯示,即span里的元素為空,但是觀察到其父元素div內有一個屬性data-price,其值正好等於單價,因此提取這個即可。
2.設計爬蟲
需要保存的數據為樓盤名字、平米數、總價、單價。items.py如下:
import scrapy
class YijiaItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
square = scrapy.Field()
price = scrapy.Field()
total = scrapy.Field()
pass
分析要爬蟲的頁面,網頁提供了選擇區的篩選,點擊「西城區」後網頁地址變為了//bj.lianjia.com/ershoufang/xicheng/,因此可以將網頁地址的變動部分用format去填充。spider.py的內容如下:
from yijia.items import YijiaItem
import scrapy
class mySpider(scrapy.spiders.Spider):
name = 'lianjia'
allowed_domains = ["bj.lianjia.com/"]
url = "//bj.lianjia.com/ershoufang/{}/pg{}/"
# 第一個地方為地區,第二個為頁數
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache',
}
#抄來瀏覽器的header
def start_requests(self):
positions = ["dongceng", "xicheng", "chaoyang", "haidian"]
for position in positions:
for page in range(1, 6):
yield scrapy.FormRequest(
url=self.url.format(position, page),
method="GET",
headers=self.headers,
callback=self.parse
)
def parse(self, response):
for each in response.xpath("/html/body/div[4]/div[1]/ul/li"):
item = YijiaItem()
item['name'] = each.xpath("div[1]/div[1]/a/text()").extract()[0]
house_info = each.xpath("div[1]/div[3]/div[1]/text()").extract()[0].split('|')
item['square'] = house_info[1].strip()
item['total'] = each.xpath("div[1]/div[6]/div[1]/span/text()").extract()[0] + "萬元"
item['price'] = each.xpath("div[1]/div[6]/div[2]/@data-price").extract()[0] + "元/平米"
yield item
然後是設計管道文件,將內容保存為一個json文件:
import json
class YijiaPipeline(object):
dict_data = {'data': []}
def open_spider(self, spider):
try:
self.file = open('data.json', "w", encoding="utf-8")
except Exception as err:
print(err)
def process_item(self, item, spider):
dict_item = dict(item)
self.dict_data['data'].append(dict_item)
return item
def close_spider(self, spider):
self.file.write(json.dumps(self.dict_data, ensure_ascii=False, indent=4, separators=(',', ':')))
self.file.close()
最後仿照前一個樣例進行爬蟲即可。
3.數據展示
保存的json文件內容如下所示,這裡只提供前三條供展示:
{
"data":[
{
"name":"此房南北通透格局,採光視野無遮擋,交通便利",
"square":"106.5平米",
"total":"1136萬元",
"price":"106667元/平米"
},
{
"name":"新安南里 南北通透 2層本房滿五年唯一",
"square":"55.08平米",
"total":"565萬元",
"price":"102579元/平米"
}
/*省略之後的N條數據*/
]
}


