Kafka高性能揭秘:sequence IO、PageCache、SendFile的應用詳解
- 2020 年 11 月 20 日
- 筆記
- kafka, Kafka高性能揭秘, 分散式消息系統
大家都知道Kafka是將數據存儲於磁碟的,而磁碟讀寫性能往往很差,但Kafka官方測試其數據讀寫速率能達到600M/s,那麼為什麼Kafka性能會這麼高呢?
首先producer往broker發送消息時,採用batch的方式即批量而非一條一條的發送,這種方式可以有效降低網路IO的請求次數,提升性能。此外這些批次消息會”暫存”在緩衝池中,避免頻繁的GC問題。批量發送的消息可以進行壓縮並且傳輸的時候可以進行高效的序列化,從而減少數據大小。
Kafka除了在producer發送消息方面做了很多優化,還有很多其他的優化,比如Kafka利用了sequence IO、PageCache、SendFile這3種處理方案:
sequence IO
首先來了解一下磁碟的特性:快速順序讀寫、慢速隨機讀寫。因為磁碟是典型的IO塊設備,每次讀寫都會經歷定址,其中定址中尋道是比較耗時的。隨機讀寫會導致定址時間延長,從而影響磁碟的讀寫速度。
大家有沒有想過MapReduce進行shuffle的時候,為什麼map端和reduce端要進行排序,不排序不也不影響正常業務的處理,排序反而因為消耗資源增加了處理時間?
以map端為例,執行過程中會產生很多小文件,這些小文件要經歷歸併排序等一系列處理後才會被reduce端進行處理。提前對未合併的文件進行排序正是利用了磁碟快速順序讀寫的特性來提高歸併排序的速度。
而Kafka在將數據持久化到磁碟時,採用只追加的順序寫,有效降低了定址時間,提高效率。下圖展示了Kafka寫入數據到partition的方式:
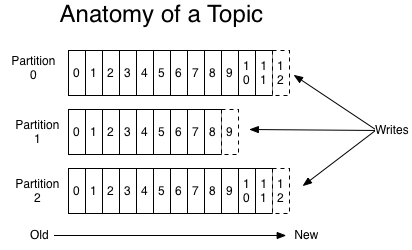
可以看到Kafka會將數據插入到文件末尾,並且Kafka不會”直接”刪除數據,而是把所有數據保存到磁碟,每個consumer會指定一個offset來記錄自己訂閱的topic的partition中消費的位置。當然我們可以設置策略來清理數據,比如通過參數log.retention.hours指定過期時間,當達到過期時間時,Kafka會清理數據。
PageCache
PageCache是系統級別的快取,它把儘可能多的空閑記憶體當作磁碟快取使用來進一步提高IO效率,同時當其他進程申請記憶體,回收PageCache的代價也很小。
當上層有寫操作時,作業系統只是將數據寫入PageCache,同時標記Page屬性為Dirty。當讀操作發生時,先從PageCache中查找,如果發生缺頁才進行磁碟調度,最終返回需要的數據。
PageCache同時可以避免在JVM內部快取數據,避免不必要的GC、以及記憶體空間佔用。對於In-Process Cache,如果Kafka重啟,它會失效,而作業系統管理的PageCache依然可以繼續使用。
對應到Kafka生產和消費消息中:
producer把消息發到broker後,數據並不是直接落入磁碟的,而是先進入PageCache。PageCache中的數據會被內核中的處理執行緒採用同步或非同步的方式寫回到磁碟。
Consumer消費消息時,會先從PageCache獲取消息,獲取不到才回去磁碟讀取,並且會預讀出一些相鄰的塊放入PageCache,以方便下一次讀取
如果Kafka producer的生產速率與consumer的消費速率相差不大,那麼幾乎只靠對broker PageCache的讀寫就能完成整個生產和消費過程,磁碟訪問非常少。
SendFile
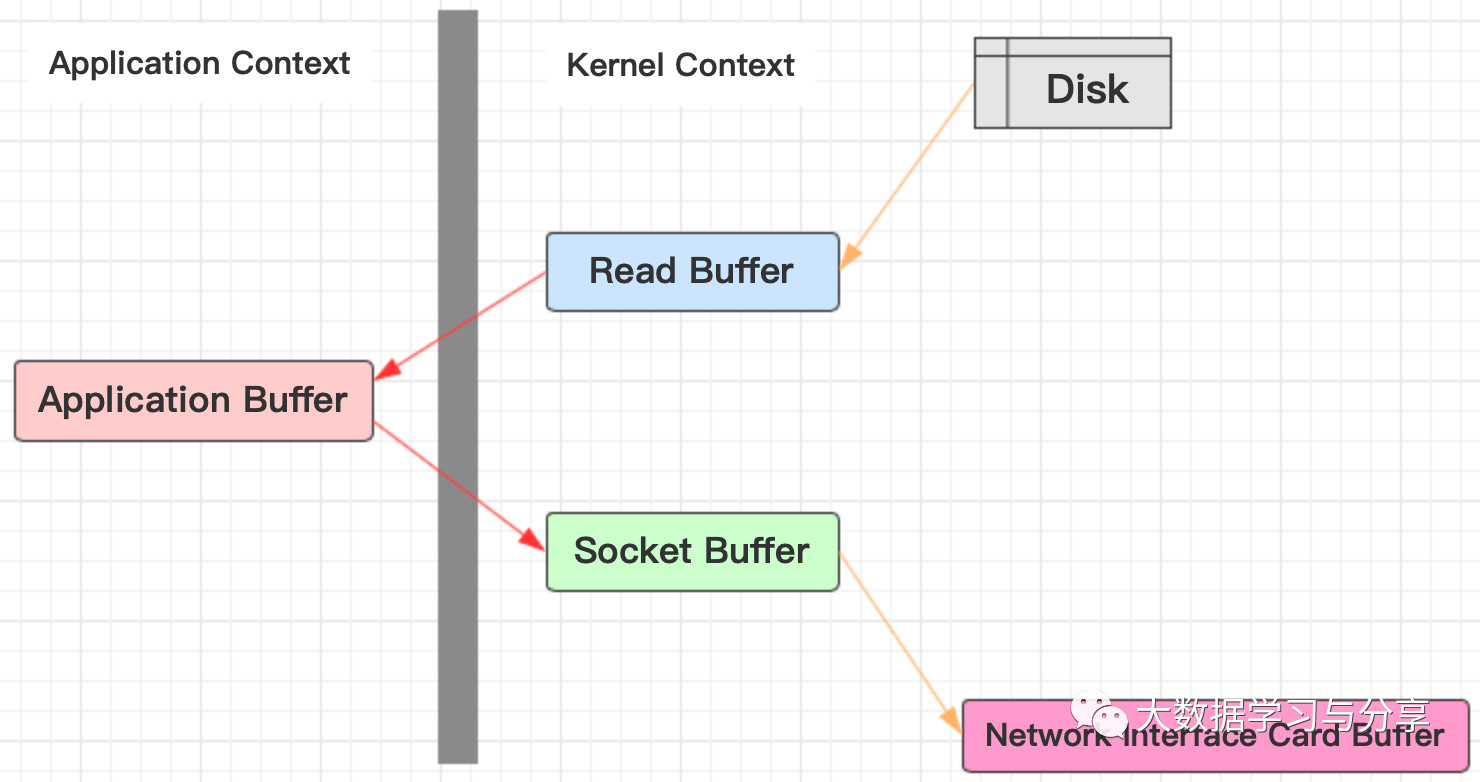
傳統的網路I/O過程:
1. 作業系統從磁碟把數據讀到內核區
2. 用戶進程把數據從內核區copy到用戶區
3. 然後用戶進程再把數據寫入到socket,數據流入內核區的Socket Buffer上
4. 最後把數據從socket Buffer中發送到到網卡,這樣完成一次發送
可以發現,同一份數據在內核Buffer與用戶Buffer之間拷貝兩次:
但是通過SendFile(又稱zero copy)優化後,直接把數據從內核區copy到socket,然後發送到網卡,避免了在內核Buffer與用戶Buffer來回拷貝的弊端:
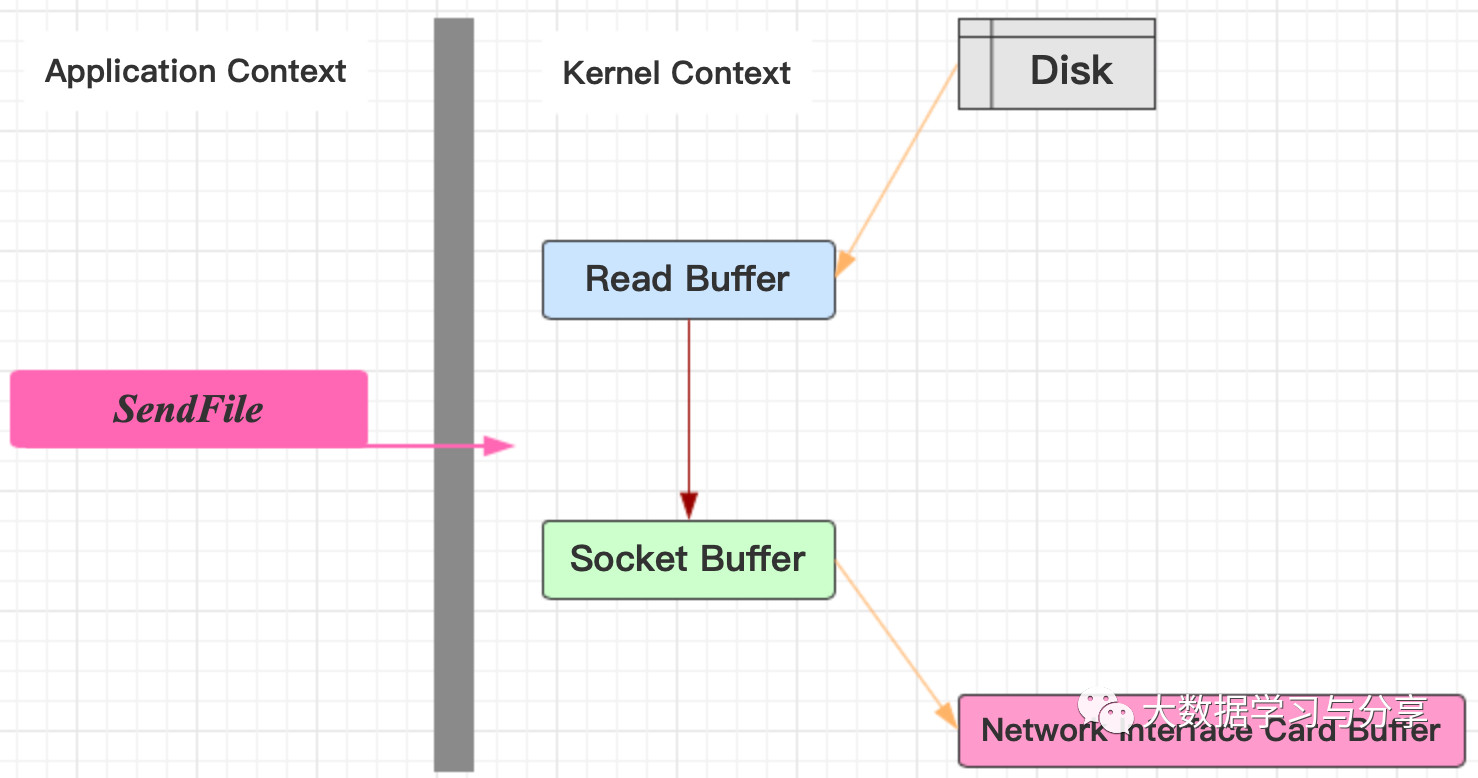
不僅是Kafka,Java的NIO提供的FileChannle,它的transferTo、transferFrom方法也利用了這種在內核區完成數據傳輸的功能。
關注微信公眾號:大數據學習與分享,獲取更對技術乾貨


