資訊理論-Turbo碼學習
- 2020 年 11 月 19 日
- 筆記
1.Turbo碼:
信道編碼的初期:分組碼實現編碼,缺點有二:只有當碼字全部接收才可以開始解碼,需要精確的幀同步時延大,增益損失多
解決方案:卷積碼:充分利用前一時刻和後一時刻的碼組,延時小,缺點:計算複雜度高
Turbo碼,依靠迭代解碼解決計算複雜性問題,通過在編解碼器中交織器和解交織器的使用,有效地實現隨機性編解碼的思想,通過短碼的有效結合實現長碼,達到了接近Shannon理論極限的性能(在兩個分量解碼器之間迭代解碼)
缺點:時延問題。
百科結論:Turbo碼採用回饋卷積碼是為了獲得更大的交織增益;Turbo碼的性能主要取決於它的有效自由距離;Turbo碼在低信噪比下具有近Shannon界糾錯能力的原因;自由距離較低引起Turbo碼在中信噪比下出現糾錯平台現象等等。
在信噪比較低的高雜訊環境下性能優越(信道條件差的移動通訊系統中有很大的應用潛力),而且具有很強的抗衰落、抗干擾能力
Turbo碼引起超乎尋常的優異解碼性能,可以糾正高速率數據傳輸時發生的誤碼。在直擴(CDMA) 系統中採用Turbo 碼技術可以進一步提高系統的容量。
在短幀情況下的模擬結果表明短交織Turbo碼在AWGN信道和Rayleigh衰落下仍然具有接近信道容量的糾錯能力
提出背景:在加性白高斯雜訊的環境下, 採用編碼效率R=1/2、交織長度為 65536的Turbo碼,經過18次迭代解碼後,在 Eb/N0=0.7dB時, 其誤碼率到達10-5,與香農極限只相差0.5dB。
2.Turbo碼理解:
將兩個簡單分量碼通過偽隨機交織器並行級聯來構造具有偽隨機特性的長碼,並通過在兩個軟入/軟出(SISO)解碼器之間進行多次迭代實現了偽隨機解碼。
交織:在實際應用中,比特差錯經常成串發生,這是由於持續時間較長的衰落谷點會影響到幾個連續的比特,而信道編碼僅在檢測和校正單個差錯和不太長的差錯串時才最有效(如RS只能糾正8個位元組的錯誤)。
為了糾正這些成串發生的比特差錯及一些突發錯誤,可以運用交織技術來分散這些誤差,使長串的比特差錯變成短串差錯,從而可以用前向碼對其糾錯。
偽隨機特性:頻譜會因數據出現連「1」和連「0」而包含大的低頻成分,不適應信道的傳輸特性,也不利於從中提取出時鐘資訊。解決辦法之一是採用擾碼技術,使訊號受到隨機化處理,變為偽隨機序列
擾碼不但能改善位定時的恢復品質,還可以使訊號頻譜平滑,使幀同步和自適應同步和自適應時域均衡等系統的性能得到改善。
3.Turbo碼的編碼結構:
三種:並行級聯卷積碼PCCC,串列級聯卷積碼SCCC,混合級聯卷積碼結構HCCC。
3.1並行級聯卷積碼結構:
是由兩個回饋的系統卷積編碼器通過一個交織器並行連接而成,編碼後的校驗位經過刪余陣,從而產生不同的碼率的碼字。
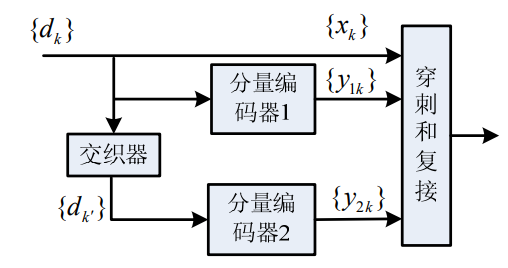
分量編碼器:分量碼的最佳選擇是遞歸系統卷積碼:
Turbo碼編碼器一般包括兩個結構相同的遞歸系統卷積編碼器和一個隨機交織器。長度為N的資訊序列u一方面直接進入第1個分量編碼器RSC1,另一方面經過隨機交織器處理後送入第2個分量編碼器RSC2。隨機交織器的處理是輸入序號至輸出序號的一映射,它的輸出為長度相同,但比特位置經隨機排列的交織序列。兩個分量編碼器RSC1和RSC2分別產生兩個不同的校驗比特序列x和x。為了提高Turbo碼的碼率,除可以選用高碼率的分量碼外,還可以採用打孔(Puncturing)技術從這兩個校驗序列中刪除一些校驗位,然後再與資訊序列x復用在一起輸出。
遞歸系統卷積碼:BER性能在高信噪比好,高碼率(R≥2/3)的情況下,對任何信噪比,它的性能均比等效的高碼率(R≥2/3)的情況下,對任何信噪比它的性能均比等效的非系統卷積碼NSC要好,
遞歸系統卷積碼(RSC)不同於一般的卷積碼器在於其結構中不僅有向前結構,還有向後回饋結構:
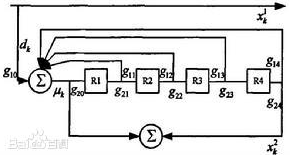
RSC 編碼器一般有2-5 級移位暫存器,
Turbo 碼在高信噪比下的性能主要由它的自由距離所決定。因為Turbo碼的自由距離主要由重量為2的輸入資訊序列所產生的碼字間的最小距離所決定,用本原多項式作為回饋連接多項式的分量編碼器所產生的碼字的最小重量為最大,因此當Turbo碼交織器的大小給定後,如果分量碼的回饋連接多項式採用本原多項式,則Turbo碼的自由距離會增加,從而Turbo碼在高斯信噪比情況下的「錯誤平層(errorfloor)」會降低。錯誤平層效應指的是在中高信噪比情況下,誤碼曲線變平。
3.2交織器的設計
作用:可以使得Turbo碼的距離譜細化,即碼重分布更為集中。
交織器實際上是一個一一映射函數,作用是將輸入資訊序列中的比特位置進行重置,以減小分量編碼器輸出校驗序列的相關性和提高碼重。通常在輸入資訊序列較長時可以採用近似隨機的映射方式,相應的交織器稱為偽隨機交織器。
交織:交織是對資訊序列加以重新排列的一個過程。如果定義一個集合A , A={1,2,…,N}。則交織器可以定義為一個一一對應的映射函數π(A–>A):J=π(i),(i,j屬於A) 這裡的i ,j 分別是未交織序列C 和交織序列C’ 中的元素標號。映射函數可以表示為πN = (π⑴,π⑵,π⑶,…,π(N))。
有三原則:
最大程度的置亂原來的數據排列順序,避免置換前相距較近的數據在置換後仍然相距較近,特別是要避免相鄰的數據在置換後仍然相鄰
盡量提高最小碼重碼字的重量和減小低碼重碼字的數量;儘可能避免與同一資訊位直接相關的兩個分量編碼器中的校驗位均被刪除
對於不歸零的編碼器,交織器設計時要避兔出現”尾效應” 圖案。
交織器和分量碼的結合可以確保Turbo碼編碼輸出碼字都具有較高的漢明重量。在Turbo編碼器中交織器的作用是將資訊序列中的比特順序重置。當資訊序列經過第一個分量編碼器後輸出的碼字重量較低時,交織器可以使交織後的資訊序列經過第二個分量編碼器編碼後以很大的概率輸出較高重碼字,從而提高碼字的漢明重量:同時好的交織器還可以奇效地降低校驗序列間的相關性
內置交織器:
Turbo碼內置的交織器是在第2個分量編碼器RSC2編碼處理之前將資訊序列的N個比特的位置進行隨機排列,它起著關鍵的作用,很大程度上影響著Turbo碼的性能。通過隨機交織,使得編碼由簡單的短碼得到了近似長碼。當交織器充分大時,Turbo碼就具有近似於隨機長碼的特性。
4.迭代解碼
Turbo碼解碼器採用迭代解碼方法,其中使用兩個分量解碼器,並在第一分量解碼器與第二分量解碼器之間傳遞軟解碼資訊,如圖3-35所示。無衝突交織器支援並行解碼的主要原理是:在進行迭代解碼時,第一分量解碼器將資訊序列進行分段,每個分段使用單獨的一個專用的解碼處理單元獨立地進行解碼,各分段解碼過程可以並行進行,提高解碼速度。但是第二分量解碼器也需要採用相同的、並行的分段解碼方法,這就要求第二分量解碼器的每個獨立專用的解碼處理單元同一時刻訪問不同的分段,這樣才能避免資訊序列分段地訪問衝突,從而實現第二分量解碼器的並行分段解碼,提高整個迭代解碼的速度。
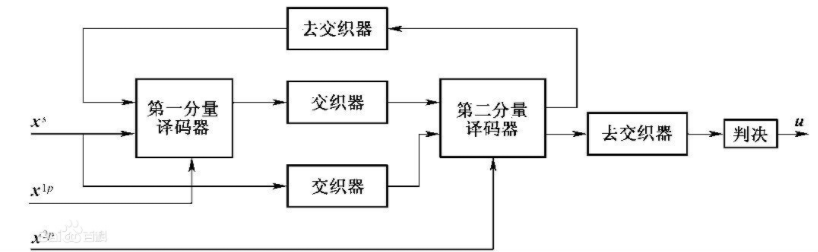
圖3-36所示為無衝突交織器的示意圖,4個窗口(Windows)A、B、C、D分別代表獨立的分段解碼,它們需要通過交織器獲取各自的原始數據,此時4個窗口A、B、C、D在讀取原始數據時,不會出現在同一時刻訪問同一分段,不會發生資源訪問衝突的問題,這樣保證了4個窗口A、B、C、D可以並行地分段解碼。

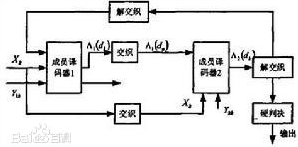
5.解碼原理
Turbo碼的解碼演算法採用了最大後驗概率演算法:解碼時首先對接收資訊進行處理,兩個成員解碼器之間外部資訊的傳遞就形成了一個循環迭代的結構。由於外部資訊的作用,一定信噪比下的誤比特率將隨著循環次數的增加而降低。但同時外部資訊與接受序列間的相關性也隨著解碼次數的增加而逐漸增加,外部資訊所提供的糾錯能力也隨之減弱,在一定的循環次數之後,解碼性能將不再提高。
在解碼的結構上又做了改進,再次引入回饋的概念,取得了性能和複雜度之間的折衷。
解碼演算法:MAP-Log-MAP演算法、Max-Log-MAP以及軟輸入軟輸出(SOVA)演算法。
5.1解碼演算法
軟輸入軟輸出的解碼演算法。軟輸出解碼器的輸出不僅應包含硬判決值
標準MAP演算法
Log-MAP演算法
Max-Log-MAP演算法


