Adaboost演算法的一個簡單實現——基於《統計學習方法(李航)》第八章
最近閱讀了李航的《統計學習方法(第二版)》,對AdaBoost演算法進行了學習。
在第八章的8.1.3小節中,舉了一個具體的演算法計算實例。美中不足的是書上只給出了數值解,這裡用程式碼將它實現一下,算作一個課後作業。
一、演算法簡述
Adaboost演算法最終輸出一個全局分類模型,由多個基本分類模型組成,每個分類模型有一定的權重,用於表示該基本分類模型的可信度。最終根據各基本分類模型的預測結果乘以其權重,通過表決來生成最終的預測(分類)結果。
AdaBoost演算法的訓練流程圖如下:
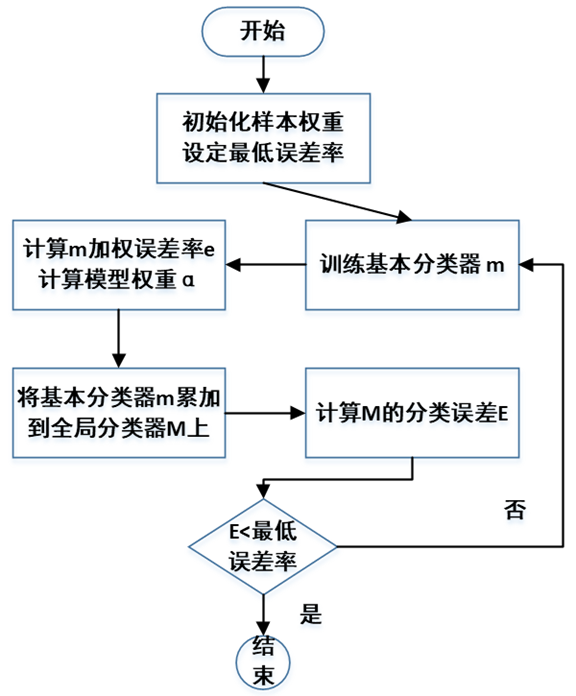 AdaBoost在訓練過程中,每一輪循環生成一個基本分類器,並計算其權重,並將其加權累加到全局分類器中,最終在全局分類器的分類誤差小於預設值時,結束訓練,輸出全局分類器。
AdaBoost在訓練過程中,每一輪循環生成一個基本分類器,並計算其權重,並將其加權累加到全局分類器中,最終在全局分類器的分類誤差小於預設值時,結束訓練,輸出全局分類器。
流程圖中幾個符合的含義和計算公式說明如下:
訓練樣本:共計10組數值,輸入(X),輸出(Y)如下:
1 data_X = [0,1,2,3,4,5,6,7,8,9] 2 data_Y = [1,1,1,-1,-1,-1,1,1,1,-1]
m:即基本分類器,這裡用的是一個決策樹樁,即在X<v時,分類為-1或1,當X>v時,分類為1或-1。
e:基本分類器的加權誤差率,權重為10個樣本各自對應的權重。即統計預測錯的樣本其權重之和。書中公式如下:
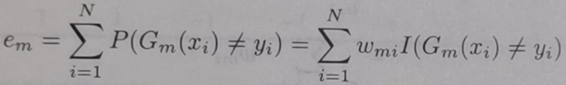
α:基本分類器的權重,就是其預測結果的可信度。書中公式如下:

M:全局分類器,由多個基本分類器與其可信度的乘積加和後得到。
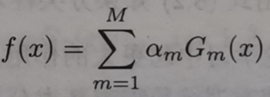
全局分類器在上述公式中即 f(x)。
另外還需要樣本權值更新的公式,其中w即各個樣本對應的權重,共N個樣本,本例中N=10:
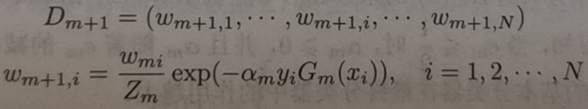
這裡簡單的引用公式講解演算法,具體可以看書中第八章的描述。不知道粘太多書中的內容會不會侵權=,=
二、程式碼講解
下面講一下程式碼。
考慮到後續有可能會將其他機器學習演算法應用到AdaBoost中,為保證其有一定的拓展性,定義AdaBoost類。
1 class Adaboost(object): 2 def __init__(self,minist_error_rate): 3 self.minist_error_rate = minist_error_rate # 臨界誤差值,小於該誤差即停止訓練 4 self.model_list = [] # 記錄模型,每一個模型包括[權重,v,方向]三個參數
這裡僅初始了兩個變數,一個是最低誤差率,用來決定什麼時候結束訓練;另一個是全局分類器對象,list類型;而基本分類器也是list,格式為[權重,v,方向],其中,v就是決策樹樁m的分界值。
定義權重初始化函數:
1 def ini_weight(self,sample_x,sample_y): # 初始化樣本權重 D ,即D1 2 self.D = [float(1)/len(sample_y)] 3 self.D = self.D*len(sample_y)
使用均值法來進行初始化,10個樣本,每個樣本的初始權重設為0.1。
之後,再定義單樣本預測函數及基本分類器的訓練函數。其中,基本分類器訓練函數將初始的v值設為0.5,每循環自增1來遍歷所有可能性,尋找加權錯誤率(e)最低的v值。
1 def prediction(self,v_num,direct,input_num): 2 if(input_num<v_num): 3 return direct 4 else: 5 return -direct 6 7 def train_op(self,sample_x,sample_y): # 獲取在樣本權重下的訓練結果 8 error_temp = 9999.9 9 v_record = 0.0 10 direct = 0 # 預測方向,即輸入小於v_record時, 樣本的預測值為 1 還是 -1 , 11 for i in range(len(sample_x)-1): 12 v_num = float(i)+0.5 13 # 正向計算一次,即小於v_num 為-1,否則1 14 error_1 = 0.0 15 for j in range(len(sample_x)): 16 pred = self.prediction(v_num,-1,sample_x[j]) 17 if(pred!=sample_y[j]): 18 error_1 += self.D[j]*1 19 if(error_1<error_temp): 20 v_record = v_num 21 direct = -1 22 error_temp = error_1 23 # 相反方向再計算一次,即小於v_num 為1,否則-1 24 error_1 = 0.0 25 for j in range(len(sample_x)): 26 pred = self.prediction(v_num,1,sample_x[j]) 27 if(pred!=sample_y[j]): 28 error_1 += self.D[j]*1 29 if(error_1<error_temp): 30 v_record = v_num 31 direct = 1 32 error_temp = error_1 33 return error_temp,v_record,direct
有了單個基本訓練器的計算函數,下面就需要構建AdaBoost演算法的主循環,即計算該基本訓練器的權重α並將其納入全局分類器M。主要依靠update函數實現。
1 def update(self,sample_x,sample_y): 2 error_now,v_record,direct = self.train_op(sample_x,sample_y) 3 print(error_now,v_record,direct) 4 alpha = 0.5*math.log((1-error_now)/error_now) 5 print(alpha) 6 self.model_list.append([alpha,v_record,direct]) 7 err_rate = self.error_rate(sample_x,sample_y) 8 while(err_rate>self.minist_error_rate): 9 Zm = 0.0 10 for i in range(len(sample_x)): 11 Zm += self.D[i]*math.exp(-alpha*self.prediction(v_record,direct,sample_x[i])*sample_y[i]) 12 # 更新 樣本權重向量self.D 13 for i in range(len(sample_y)): 14 self.D[i] = self.D[i] * math.exp(-alpha*self.prediction(v_record,direct,sample_x[i])*sample_y[i]) / Zm 15 error_now,v_record,direct = self.train_op(sample_x,sample_y) 16 alpha = 0.5*math.log((1-error_now)/error_now) 17 self.model_list.append([alpha,v_record,direct]) 18 err_rate = self.error_rate(sample_x,sample_y)
主循環靠while循環來實現,全局模型分類誤差率小於設定的最低誤差率時,停止循環,輸出全局分類器。
最終在main函數中,調用該類,按順序執行初始化樣本權重、執行主循環、列印模型結構。
1 if __name__ == "__main__": 2 ada_obj = Adaboost(0.005) 3 ada_obj.ini_weight(data_X,data_Y) 4 ada_obj.update(data_X,data_Y) 5 ada_obj.print_model()
其中,最低誤差率設為0.005,在本例中即要求10個樣本全部分類正確。最終程式輸出:

可以看出全局分類器由3個基本分類器組成,權重即為基本分類器的可信度,臨界值則為v值,方向則設定為輸入小於v值時,分類的結果。即第一個模型(0 layer)為當輸入小於2.5時,分類結果為1;否則為-1。解得的答案也與書中結果相同。
下面是全部程式碼,感興趣同學可以在python環境中試一試。
1 # coding:utf-8 2 3 import math 4 import numpy as np 5 6 data_X = [0,1,2,3,4,5,6,7,8,9] 7 data_Y = [1,1,1,-1,-1,-1,1,1,1,-1] 8 9 # data_X = [0,1,2,3,4,5,6,7,8,9,10,11,12,13] 10 # data_Y = [1,1,1,-1,-1,-1,1,1,1,-1,1,1,-1,-1] 11 12 print(len(data_X),len(data_Y)) 13 14 class Adaboost(object): 15 def __init__(self,minist_error_rate): 16 self.minist_error_rate = minist_error_rate # 臨界誤差值,小於該誤差即停止訓練 17 self.model_list = [] # 記錄模型,每一個模型包括[權重,v,方向]三個參數 18 19 def ini_weight(self,sample_x,sample_y): # 初始化樣本權重 D ,即D1 20 self.D = [float(1)/len(sample_y)] 21 self.D = self.D*len(sample_y) 22 23 def prediction(self,v_num,direct,input_num): 24 if(input_num<v_num): 25 return direct 26 else: 27 return -direct 28 29 def train_op(self,sample_x,sample_y): # 獲取在樣本權重下的訓練結果 30 error_temp = 9999.9 31 v_record = 0.0 32 direct = 0 # 預測方向,即輸入小於v_record時, 樣本的預測值為 1 還是 -1 , 33 for i in range(len(sample_x)-1): 34 v_num = float(i)+0.5 35 # 正向計算一次,即小於v_num 為-1,否則1 36 error_1 = 0.0 37 for j in range(len(sample_x)): 38 pred = self.prediction(v_num,-1,sample_x[j]) 39 if(pred!=sample_y[j]): 40 error_1 += self.D[j]*1 41 if(error_1<error_temp): 42 v_record = v_num 43 direct = -1 44 error_temp = error_1 45 # 相反方向再計算一次,即小於v_num 為1,否則-1 46 error_1 = 0.0 47 for j in range(len(sample_x)): 48 pred = self.prediction(v_num,1,sample_x[j]) 49 if(pred!=sample_y[j]): 50 error_1 += self.D[j]*1 51 if(error_1<error_temp): 52 v_record = v_num 53 direct = 1 54 error_temp = error_1 55 return error_temp,v_record,direct 56 57 def one_model_pred(self,input_num,model_num): # 計算單個子模型的預測結果 58 m = self.model_list[model_num] 59 return self.prediction(m[1],m[2],input_num) 60 61 def error_rate(self,sample_x,sample_y): # 計算各子模型投票表決的錯誤率 62 wrong_num = 0 63 for i in range(len(sample_y)): 64 out = 0.0 65 for j in range(len(self.model_list)): 66 out_temp = self.model_list[j][0]*self.one_model_pred(sample_x[i],j) 67 out += out_temp 68 if(out>=0): 69 out = 1 70 else: 71 out = -1 72 if(out==sample_y[i]): 73 pass 74 else: 75 wrong_num += 1 76 return float(wrong_num)/len(sample_y) 77 78 def update(self,sample_x,sample_y): 79 error_now,v_record,direct = self.train_op(sample_x,sample_y) 80 # print(error_now,v_record,direct) 81 alpha = 0.5*math.log((1-error_now)/error_now) 82 # print(alpha) 83 self.model_list.append([alpha,v_record,direct]) 84 err_rate = self.error_rate(sample_x,sample_y) 85 while(err_rate>self.minist_error_rate): 86 Zm = 0.0 87 for i in range(len(sample_x)): 88 Zm += self.D[i]*math.exp(-alpha*self.prediction(v_record,direct,sample_x[i])*sample_y[i]) 89 # 更新 樣本權重向量self.D 90 for i in range(len(sample_y)): 91 self.D[i] = self.D[i] * math.exp(-alpha*self.prediction(v_record,direct,sample_x[i])*sample_y[i]) / Zm 92 error_now,v_record,direct = self.train_op(sample_x,sample_y) 93 alpha = 0.5*math.log((1-error_now)/error_now) 94 self.model_list.append([alpha,v_record,direct]) 95 err_rate = self.error_rate(sample_x,sample_y) 96 97 def print_model(self): 98 print('模型列印: 權重 臨界值 方向') 99 for i in range(len(self.model_list)): 100 print(str(i)+' layer :'+str(self.model_list[i][0])+' '+str(self.model_list[i][1])+' '+str(self.model_list[i][2])) 101 102 if __name__ == "__main__": 103 ada_obj = Adaboost(0.005) 104 ada_obj.ini_weight(data_X,data_Y) 105 ada_obj.update(data_X,data_Y) 106 ada_obj.print_model()
參考:


