記在Linux上定位後台服務偶發崩潰的問題
- 2020 年 11 月 17 日
- 筆記
- C/C++ 語言學習
問題描述
在最近的後台服務中,新增將某個指令的請求數據落盤保存的功能。在具體實現時,採用成員變數來保存請求消息代理頭,在接收響應以及消息管理類釋放時進行銷毀。測試回饋,該服務偶發崩潰。
問題分析
測試環境上運行的是rel版程式,由於在編譯時去掉了調試資訊(-g)以及開啟O3級別優化,從崩潰dump的堆棧上,只看到程式崩潰的調用棧,函數入參等被優化掉,由於此處沒有打日誌,只能想其他辦法來複現。猜測是重複釋放指針導致的崩潰,接下來繼續分析。
從rel版本的調用棧上看,只看見最後銷毀的函數調用,而在實際程式碼中,有兩處銷毀的函數調用入口,為什麼在dump中看到的調用棧順序與實際程式碼不一致呢?猜測是開啟O3優化,將函數內聯。
做了以下實驗來分析,
void test_dump()
{
int* p = NULL;
*p = 2; // occur dump
}
void test_f2(int b)
{
b += 1;
test_dump();
}
void test_f1(int a)
{
a+=1;
test_f2(a);
}
int main()
{
test_f1(1);
return 0;
}
在Debug以及Rel模式下,觸發崩潰,使用gdb來輸出堆棧資訊分別如下:
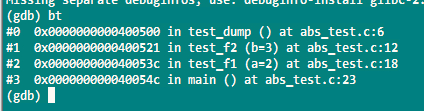

結論:在Rel模式下,O3級別的優化內聯了調用函數,如果從崩潰點往上回溯有多個可能入口點,那僅憑dump資訊不能確認是哪個入口觸發的崩潰。
構造測試環境
通過分析程式碼,得知要觸發可能的多重釋放,需要構造一邊創建,一邊銷毀的場景。
- 創建:可通過測試工具,定時高頻發送特定指令,觸發創建流程
- 銷毀:可在定時任務中,進行無效狀態上報,觸發銷毀流程
為了加快崩潰復現速度,創建以及銷毀的速度需要合理匹配,如果太快銷毀,會導致無法進入創建流程。經過分析嘗試,最終
設定測試工具每50毫秒發送一次,後台服務每50ms上報無效狀態。
為進一步驗證崩潰的想法,在銷毀操作等關鍵路徑添加日誌,啟動Rel版來重現。經過長時間的測試,獲得了2次寶貴的崩潰dump以及對應的日誌。每次dump要花費2個半小時甚至更多才能復現,說明這個問題是偶發問題,很可能與多執行緒競態有關。復現該問題的時間成本有點高,不過,從獲得的dump以及日誌已足以定位問題。
日誌分析
同一後台服務,不同業務模組的日誌分布在不同日誌文件中,在分析時,需要將各部分日誌聚合起來,方便復現全流程。在聚合時,可以按需截取各模組的最後若干行日誌,每種日誌中包含正常以及異常的日誌,將其匯總到單一文件,然後結合程式碼進行逐行關聯分析。
在分析過程中,遇到一些框架方面的疑問,通過詢問相關同事得到解答。目前的消息收發框架在接收消息時,先將消息放入執行緒池的消息隊列,通過訊號量來喚醒執行緒,執行緒從消息隊列中獲取消息,從消息中取出處理函數進行處理。
在應用層處理不同消息時,可能處理同一個變數時,會有發生競態。通過對釋放指針的分析,正常釋放指針指都有一定的規律,當觸發崩潰時,釋放的指針值與正常的值有明顯區別。
經驗小結
- 發現有dump文件時,查看dump文件生成時間,將當時的日誌以及可執行文件,連同dump文件一併放在獨立的文件夾中,便於後續分析。因為當前的日誌文件以及可執行文件可能被刪除以及更新。
- 每一次問題的解決,都是一次對已有系統的再深入認識,理解。
- 構造復現環境時,要使用Rel版本,且只能通過日誌來確認程式流程,而不是斷點。
- 在linux上,不能使用嵌套屬性的互斥鎖,它會破壞設計意圖,讓潛在的死鎖更加難以發現。讓錯誤儘早暴露好過後續找錯。
- 大膽假設,小心求證,勝利的曙光終會出現。
參考文章:
線上問題 不能gdb調試怎麼處理
Linux 環境下多執行緒 C/C++ 程式的記憶體問題調試


