Databricks說的Lakehouse是什麼?
- 2020 年 11 月 17 日
- 筆記
- Databricks, LakeHosue, 大數據, 數據湖

在過去的幾年裡,Lakehouse作為一種新的數據管理範式,已獨立出現在Databricks的許多用戶和應用案例中。在這篇文章中,我們將闡述這種新範式以及它相對於之前方案的優勢。
數據倉庫在決策支援和商業智慧應用方面有著悠久的歷史。自20世紀80年代末問世以來,數據倉庫技術一直在持續不斷的發展,並且MPP體系架構使系統能夠處理更大的數據量。儘管數據倉庫非常適合處理結構化數據,但是對於很多現代企業,對非結構化數據、半結構化數據以及具有高多樣性、高速度、高容量特性的數據處理也往往是必須的,數據倉庫並不適用於此類場景的處理,並且成本方面也不是最具效益的。
隨著很多公司開始從很多不同的數據源收集大量數據,架構師開始構想通過一個單一的系統來容納不同分析產品和工作負載的數據。大約十年前,很多公司開始構建數據湖(存儲各種格式原始數據的倉庫)。雖然數據湖適合存儲數據,但缺少一些關鍵功能(如不支援事務、無法提高數據品質、缺乏一致性/隔離性)導致幾乎不可能融合處理數據的追加和讀取、批和流處理任務。由於這些原因,數據湖之前的許多承諾沒有兌現,並且在許多情況下還會喪失數據倉庫原本的很多優勢。
很多公司對各類數據應用包括SQL分析、實時監控、數據科學和機器學習的靈活性、高性能系統的需求並未減少。AI的大部分最新進展是有可用於更好處理非結構化數據(如text、images、video、audio)的模型,但這些恰恰是數據倉庫未針對優化的數據類型。一種常見的解決方案是使用融合了數據湖、多個數據倉庫以及其他的如流、時間序列、圖和影像資料庫的系統。但是維護這一整套系統是非常複雜的(維護成本相對較高),此外,數據專業人員通常需要跨系統進行數據的移動或複製,這又會導致一定的延遲。
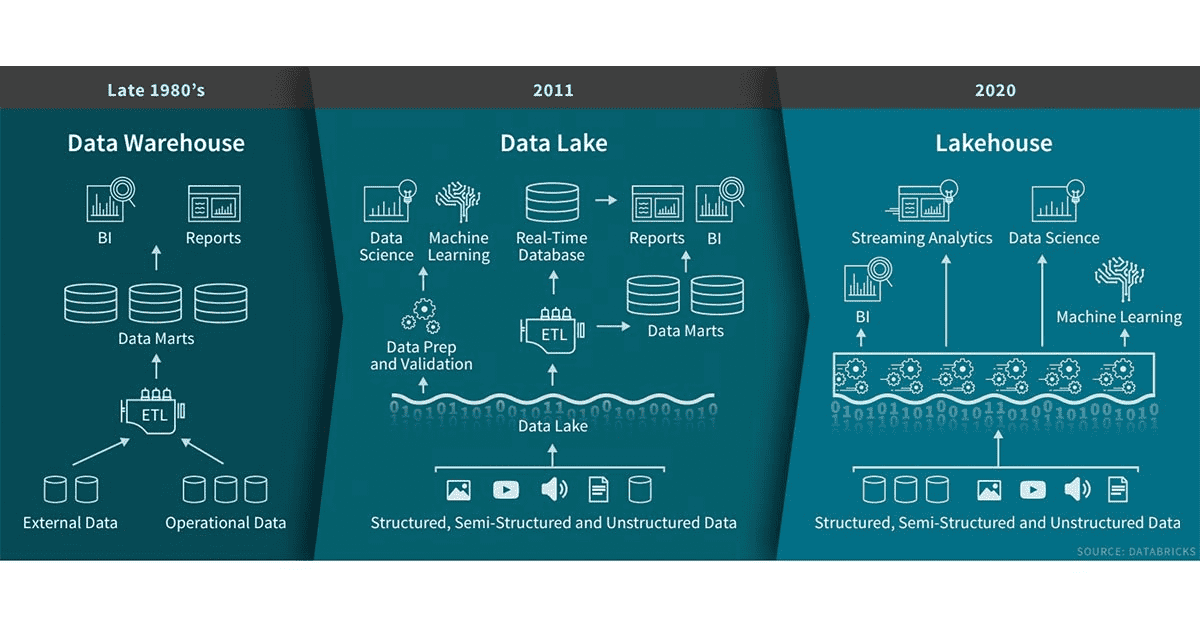
什麼是Lakehouse?
Lakehouse是一種結合了數據湖和數據倉庫優勢的新範式,解決了數據湖的局限性。Lakehouse使用新的系統設計:直接在用於數據湖的低成本存儲上實現與數據倉庫中類似的數據結構和數據管理功能。如果你現在需要重新設計數據倉庫,現在有了廉價且高可靠(以對象存儲的格式)的存儲可用,不妨考慮使用Lakehouse。
Lakehouse有如下關鍵特性:
- 事務支援
- 企業內部許多數據管道通常會並發讀寫數據。對ACID事務的支援確保了多方並發讀寫數據時的一致性問題
- Schema enforcement and governance
- Lakehouse應該有一種方式可以支援模式執行和演進、支援DW schema的範式(如星星或雪花模型),能夠對數據完整性進行推理,並且具有健壯的治理和審計機制
- BI支援
- Lakehouse可以直接在源數據上使用BI工具。這樣可以提高數據新鮮度、減少延遲,並且降低了在數據池和數據倉庫中操作兩個數據副本的成本
- 存儲與計算分離
- 在實踐中,這意味著存儲和計算使用單獨的集群,因此這些系統能夠擴展到支援更大的用戶並發和數據量。一些現代數倉也具有此屬性
- 開放性
- 使用的存儲格式是開放式和標準化的(如parquet),並且為各類工具和引擎,包括機器學習和Python/R庫,提供API,以便它們可以直接有效地訪問數據
- 支援從非結構化數據到結構化數據的多種數據類型
- Lakehouse可用於存儲、優化、分析和訪問許多數據應用所需的包括image、video、audio、text以及半結構化數據
- 支援各種工作負載
包括數據科學、機器學習以及SQL和分析。可能需要多種工具來支援這些工作負載,但它們底層都依賴同一數據存儲庫
- 端到端流
實時報表是許多企業中的標準應用。對流的支援消除了需要構建單獨系統來專門用於服務實時數據應用的需求。
作為企業級的系統,除了要求具有以上特性外,還需要其他額外的功能特性。比如安全和訪問控制工具是基本要求。特別是考慮到最近的隱私法規,數據治理功能變得至關重要(包括審計、保留和血緣關係)。對於數據發現工具,例如數據catalog和數據使用metrics也是需要的。
通過使用Lakehouse,這些企業功能特性只需要在一個系統中就能達到實現、測試和管理的目的。
早期示例
Databricks平台具有Lakehouse的特性。
微軟的Azure Synapse Analytics服務與Azure Databricks集成,可實現類似Lakehouse模式。其他託管服務(例如BigQuery和Redshift Spectrum)具有上面列出的一些LakeHouse功能特性,但它們是主要針對BI和其他SQL應用。對於想要構建和實現自己系統的公司,可參考適合構建Lakehouse的開源文件格式(Delta Lake,Apache Iceberg,Apache Hudi)。
將數據湖和數據倉庫合併至一個系統可以避免數據團隊不必要的跨多個系統進行數據的訪問,從而提高效率。對於大多數企業數據倉庫來說,這些早期的Lakehouse中的SQL支援和與BI工具的集成級別通常已經能夠滿足需求。雖然可以使用物化視圖和存儲過程,但用戶可能需要使用其他與傳統數據倉庫中的機制不同的機制。後者對於”lift and shift scenarios”(要求系統實現與舊的商業數據倉庫幾乎相同的語義)尤為重要。
Lakehouse對其他類型數據應用的支援又如何呢?Lakehouse的用戶可以使用各種標準工具(Spark,Python,R,機器學習庫)來處理像數據科學和機器學習等非BI工作負載。數據探索和精化是許多分析和數據科學應用的標準。Delta Lake的設計目的是讓用戶逐步提高Lakehouse中數據品質,直到數據可以使用為止(關於Delta Lake,建議閱讀:
//databricks.com/blog/2020/02/24/introducing-databricks-ingest-easy-data-ingestion-into-delta-lake.html)。
雖然分散式文件系統可以用於存儲層,但對象存儲在Lakehouse中更為常見。對象存儲提供低成本、高可用的存儲,在大規模並發讀取方面表現出色,這是現代數據倉庫的基本要求。
從BI到AI
Lakehouse是一種新的數據管理範式,它從根本上簡化了企業數據基礎設施,並且有望在機器學習即將顛覆每個行業的時代加速創新。過去,公司產品或決策過程中涉及的大多數數據都是來自作業系統的結構化數據,而如今,許多產品以電腦視覺和語音模型、文本挖掘等形式將AI融入其中。為什麼要用Lakehouse而不是數據湖來進行AI?Lakehouse提供了數據版本控制、治理、安全性和ACID屬性,即使是非結構化數據也需要這些屬性。
當前Lakehouse降低了成本,但其性能仍可能落後於擁有多年投資和實際部署的專業系統(如數據倉庫)。用戶可能更喜歡某些工具(BI工具、IDEs, notebooks),因此Lakehouse還需要改進其用戶體驗和與流行工具的連接,以便更具吸引力。隨著技術的不斷發展和成熟,這些問題將得到解決。隨著時間的推移,Lakehouse將縮小這些差距,同時保留更簡單、更具成本效益和更能為多種數據應用服務的核心特性。
本文參譯於:
//databricks.com/blog/2020/01/30/what-is-a-data-lakehouse.html —— by Ben Lorica, Michael Armbrust, Ali Ghodsi, Reynold Xin and Matei Zaharia Posted in Company Blog | January 30, 2020
關注微信公眾號:大數據學習與分享,獲取更對技術乾貨


