Spring Cloud 整合分散式鏈路追蹤系統Sleuth和ZipKin實戰,分析系統瓶頸
- 2020 年 11 月 14 日
- 筆記
- Spring Cloud, 分散式架構, 技術乾貨
導讀
微服務架構中,是否遇到過這種情況,服務間調用鏈過長,導致性能遲遲上不去,不知道哪裡出問題了,巴拉巴拉….,回歸正題,今天我們使用SpringCloud組件,來分析一下微服務架構中系統調用的瓶頸問題~
SpringCloud鏈路追蹤組件Sleuth實戰
官網

主要功能:做日誌埋點
什麼是Sleuth
專門用於追蹤每個請求的完整調用鏈路。
例如:【order-service,f674cc8202579a50,4727309367e0b514,false】
-
- 第一個值:spring.application.name
- 第二個值,sleuth生成的一個ID,交Trace ID,用來標識一條請求鏈路,一條請求鏈路中包含一個Trace ID,多個Span ID
- 第三個值:spanid基本的工作單元,獲取元數據,如發送一個http請求
- 第四個值:false,是否要將該資訊輸出到zipkin服務中來收集和展示
添加依賴
牽扯到的服務都得加這個依賴!(我這裡是在order-service、product-service加的依賴)
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-sleuth</artifactId> </dependency>
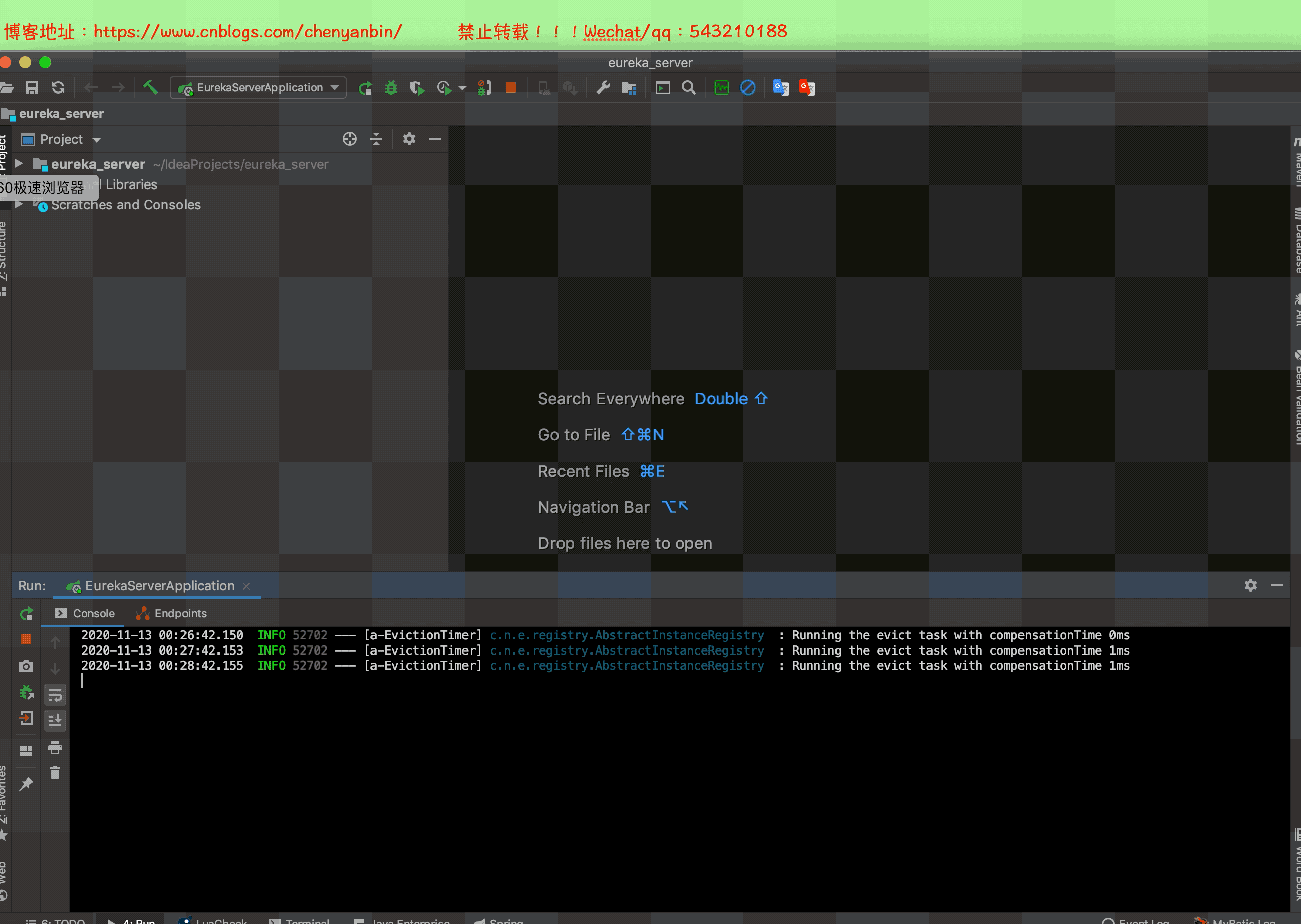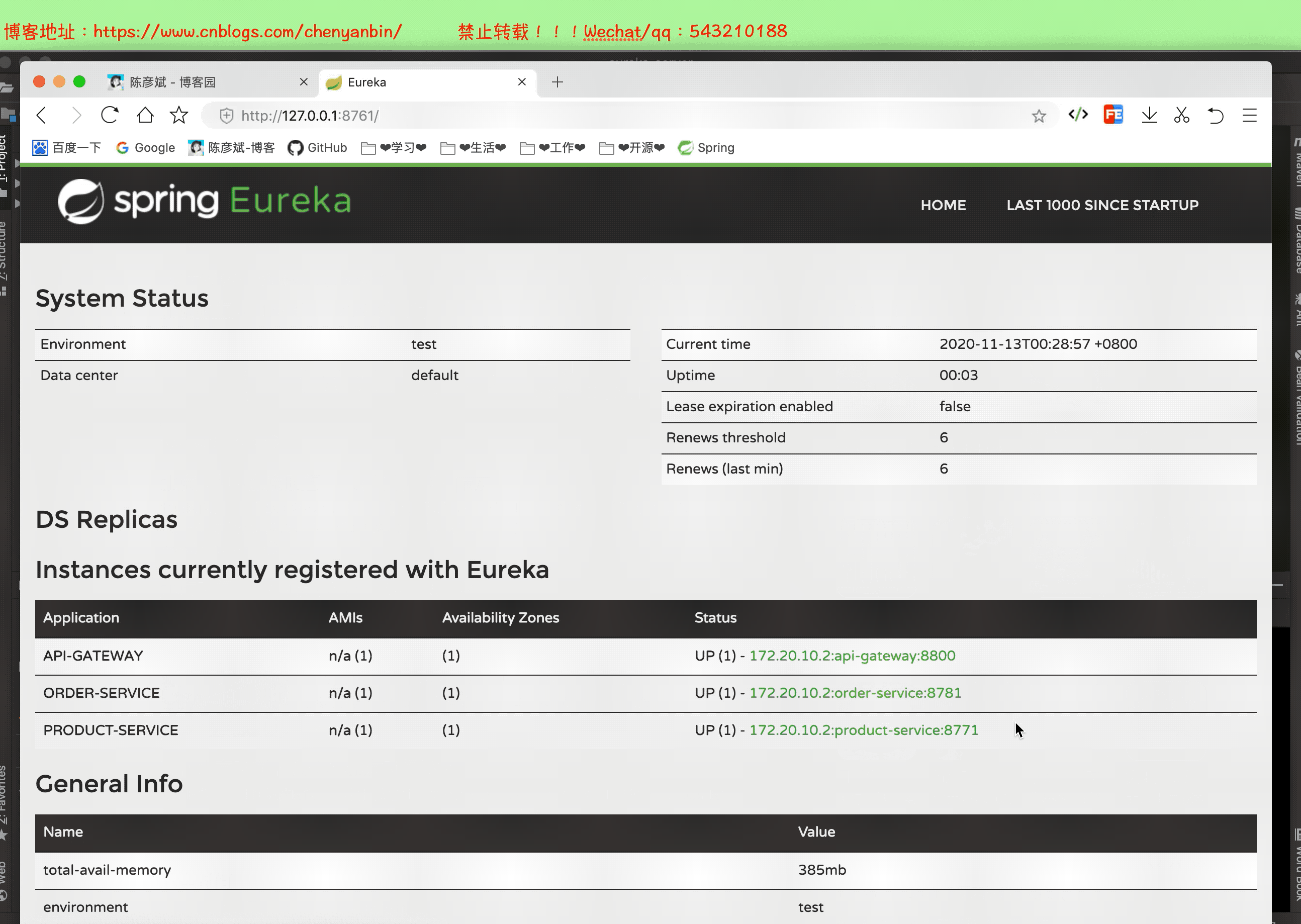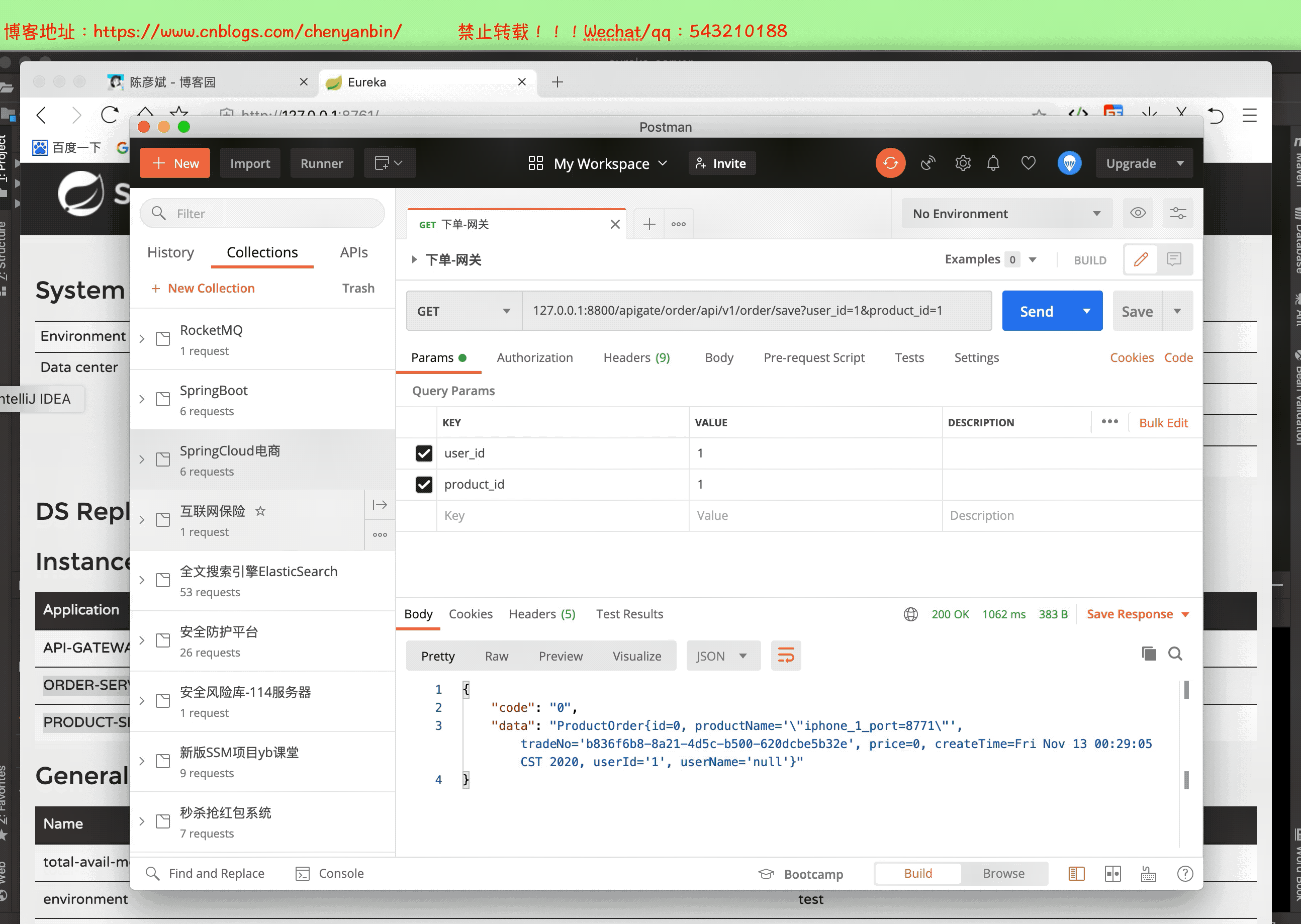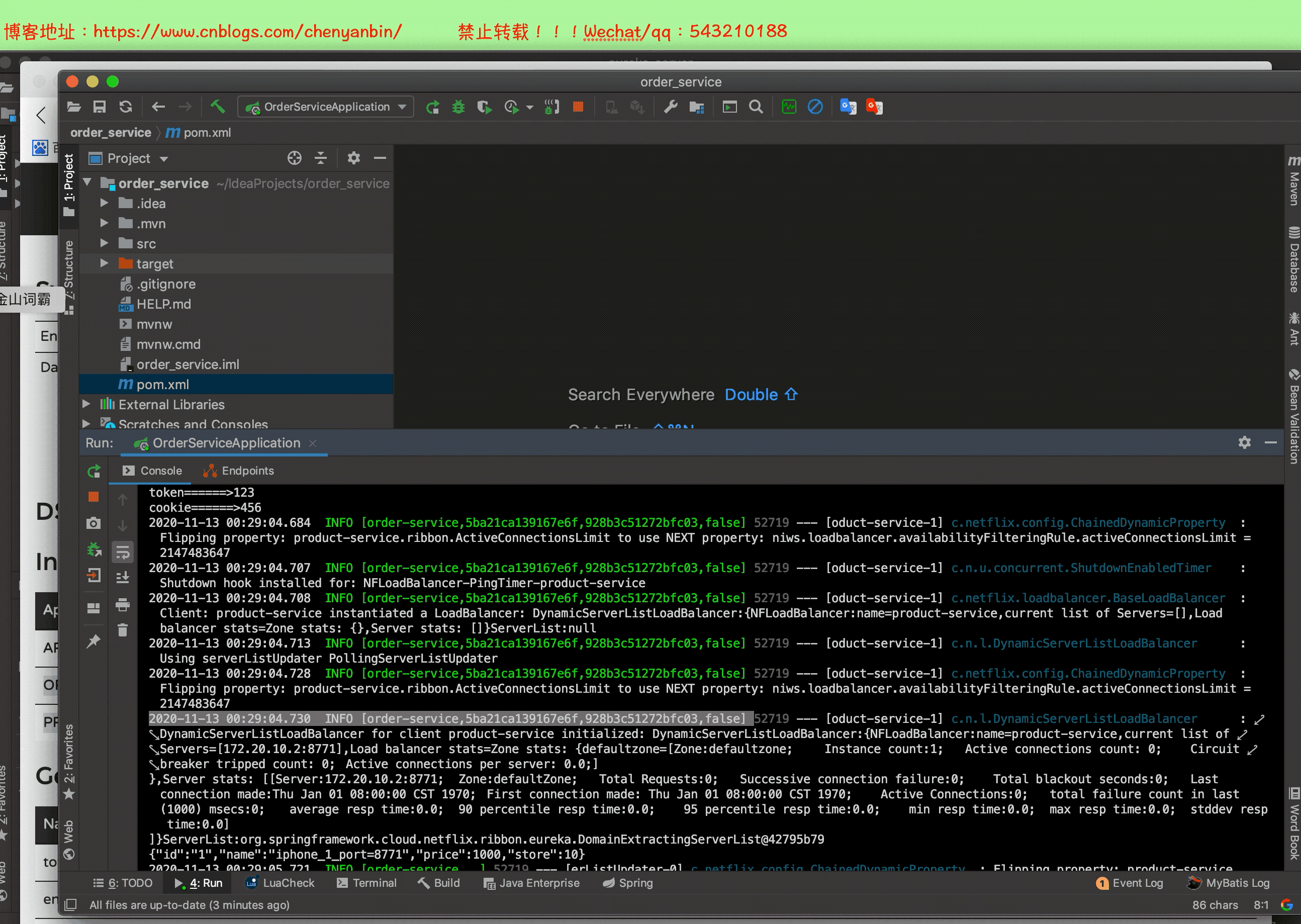
啟動整個微服務測試
部署可視化鏈路追蹤Zipkin
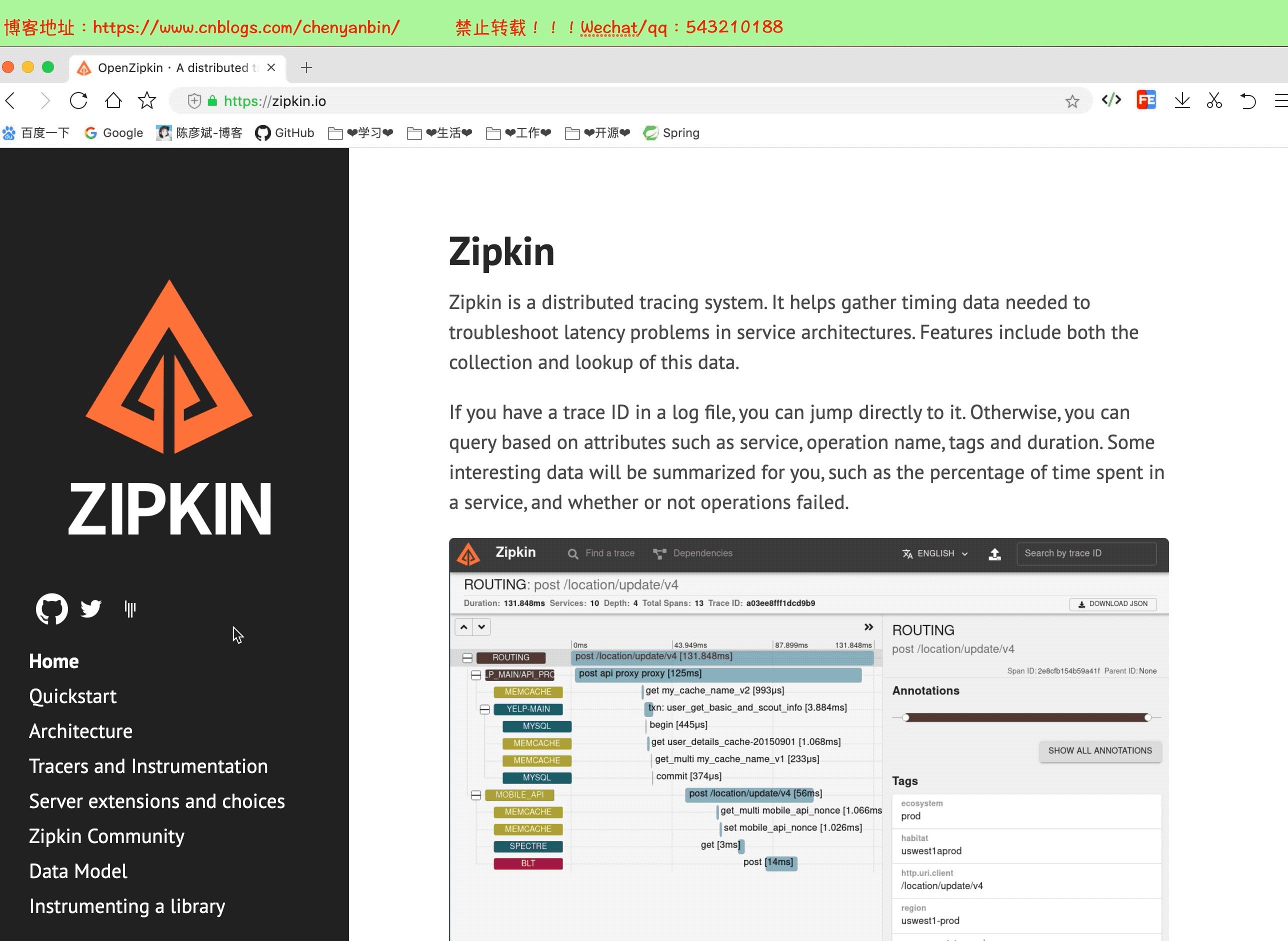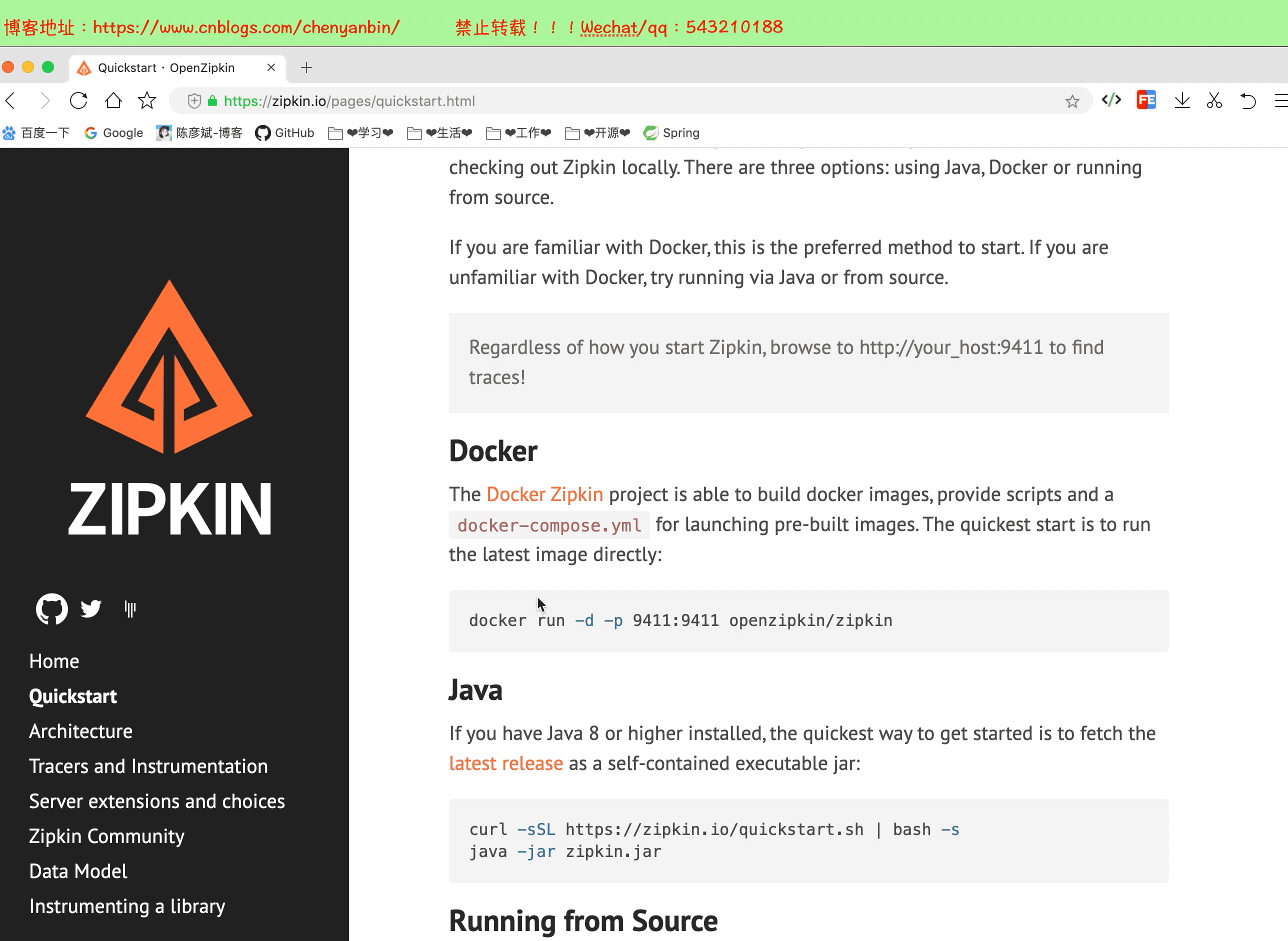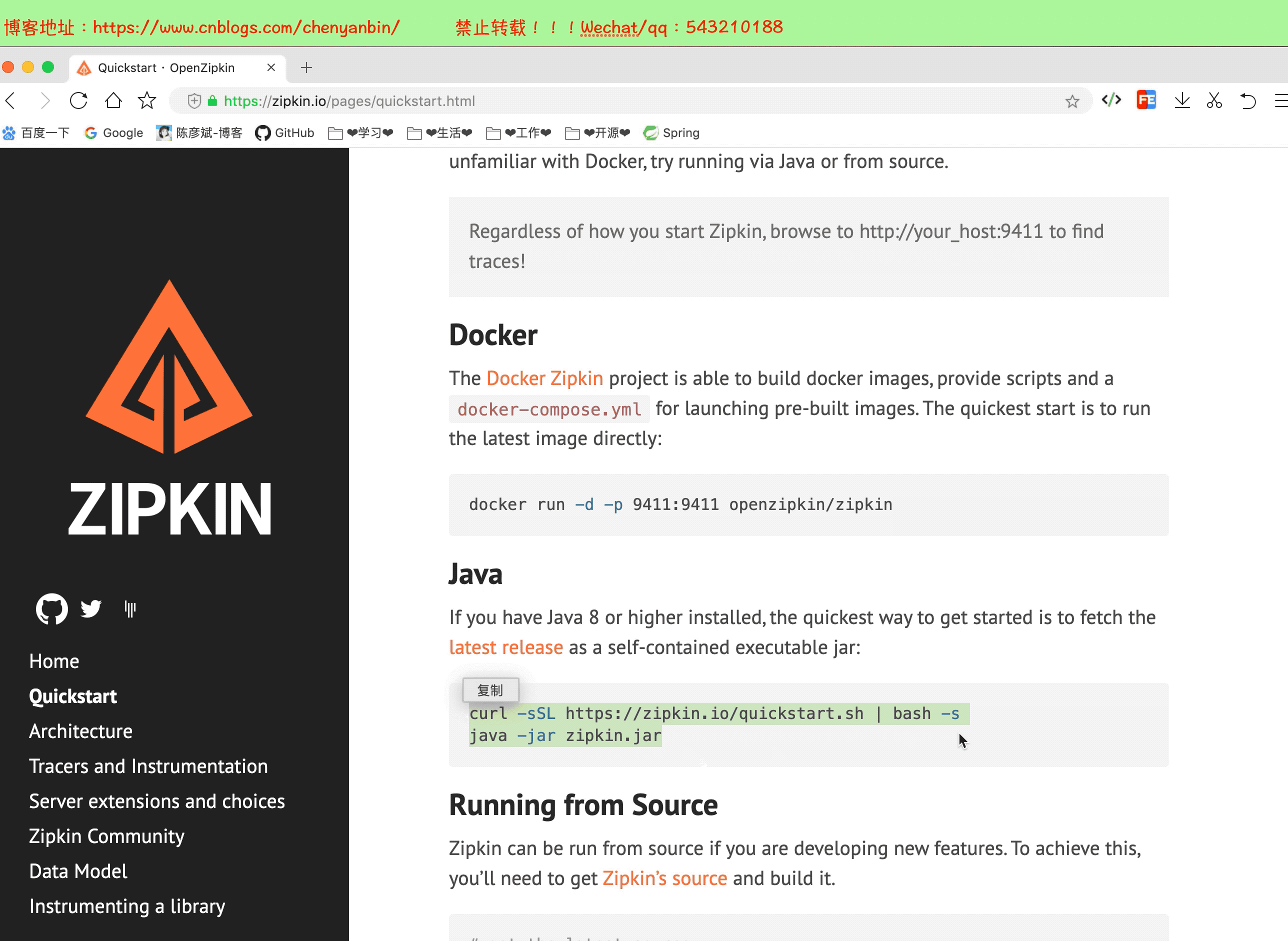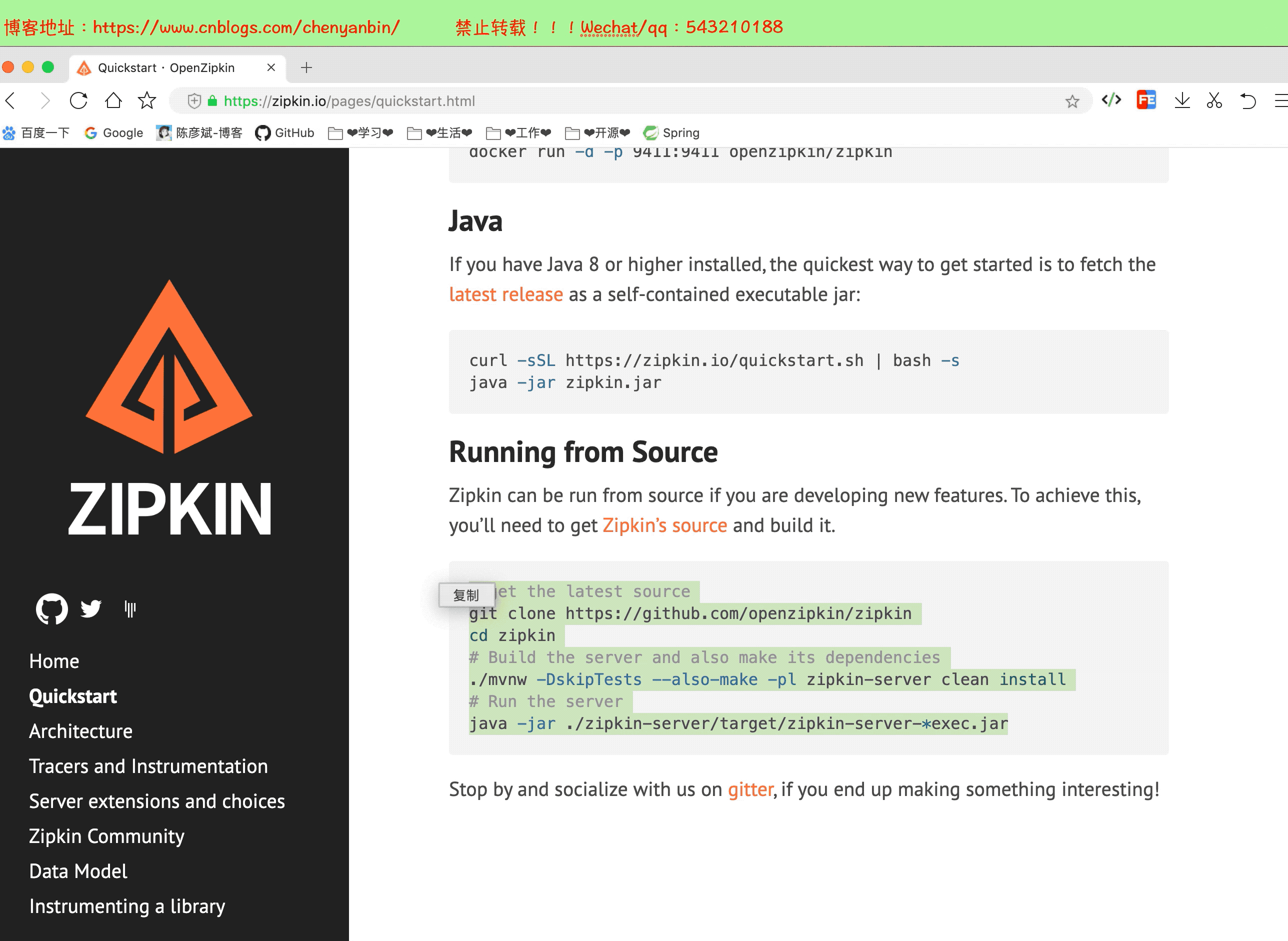
簡介
大規模分散式系統的APM工具,基於Google Dapper的基礎實現,和Sleuth結合可以提供可視化web介面分析調用鏈路耗時情況。
官網
部署
這裡我使用下載源碼的方式
# get the latest source
git clone //github.com/openzipkin/zipkin
cd zipkin
# Build the server and also make its dependencies
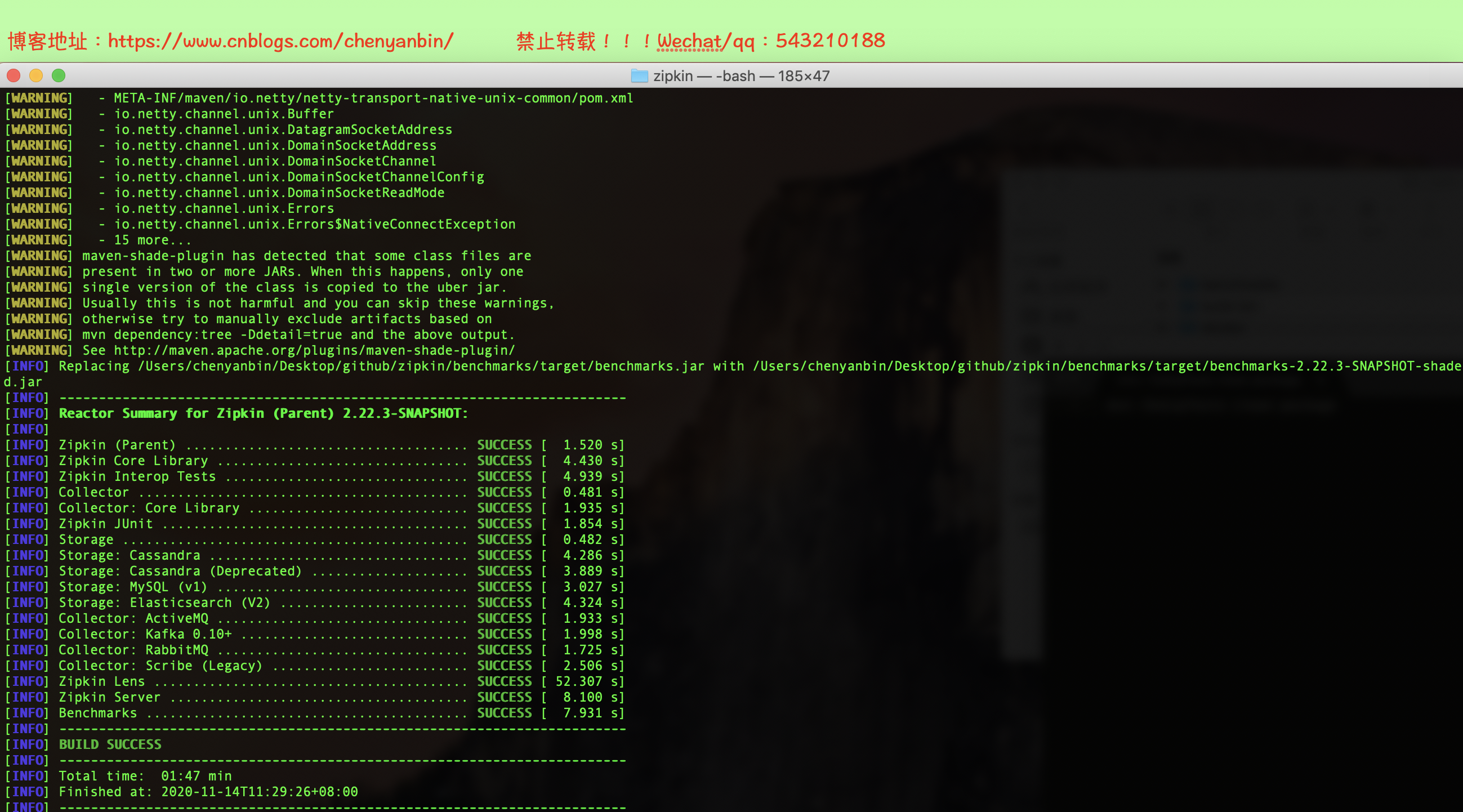
./mvnw -DskipTests --also-make -pl zipkin-server clean install
# Run the server
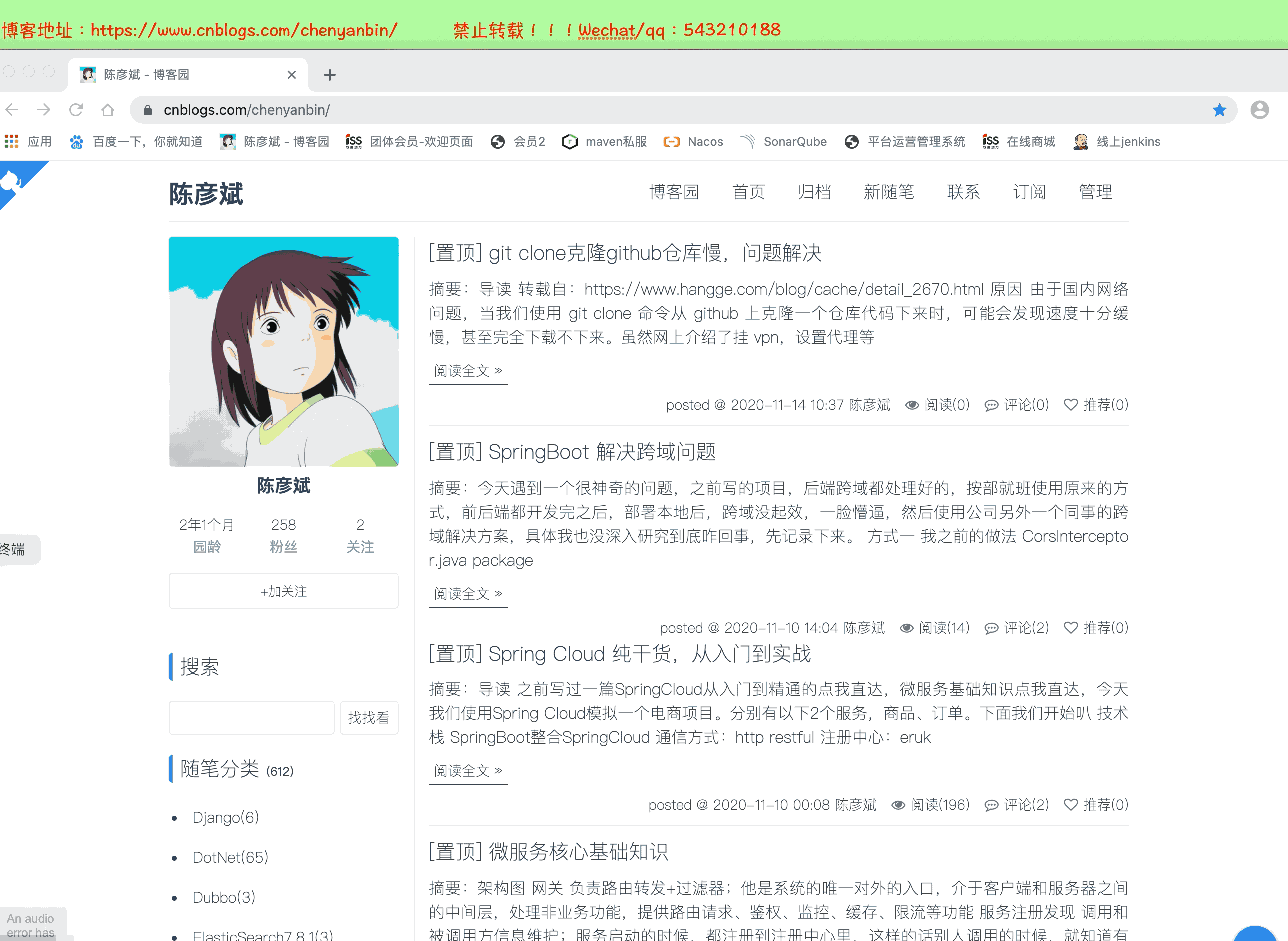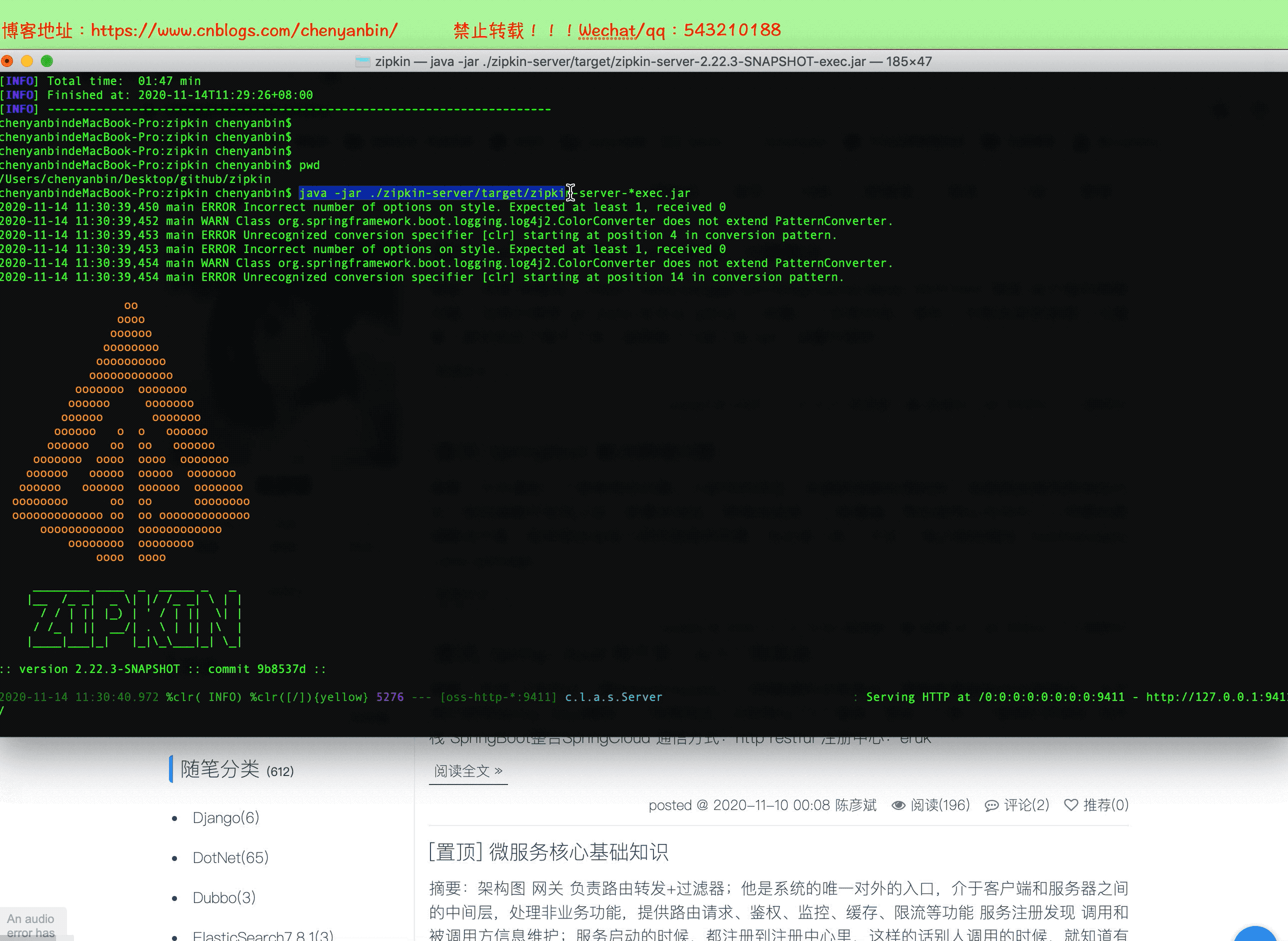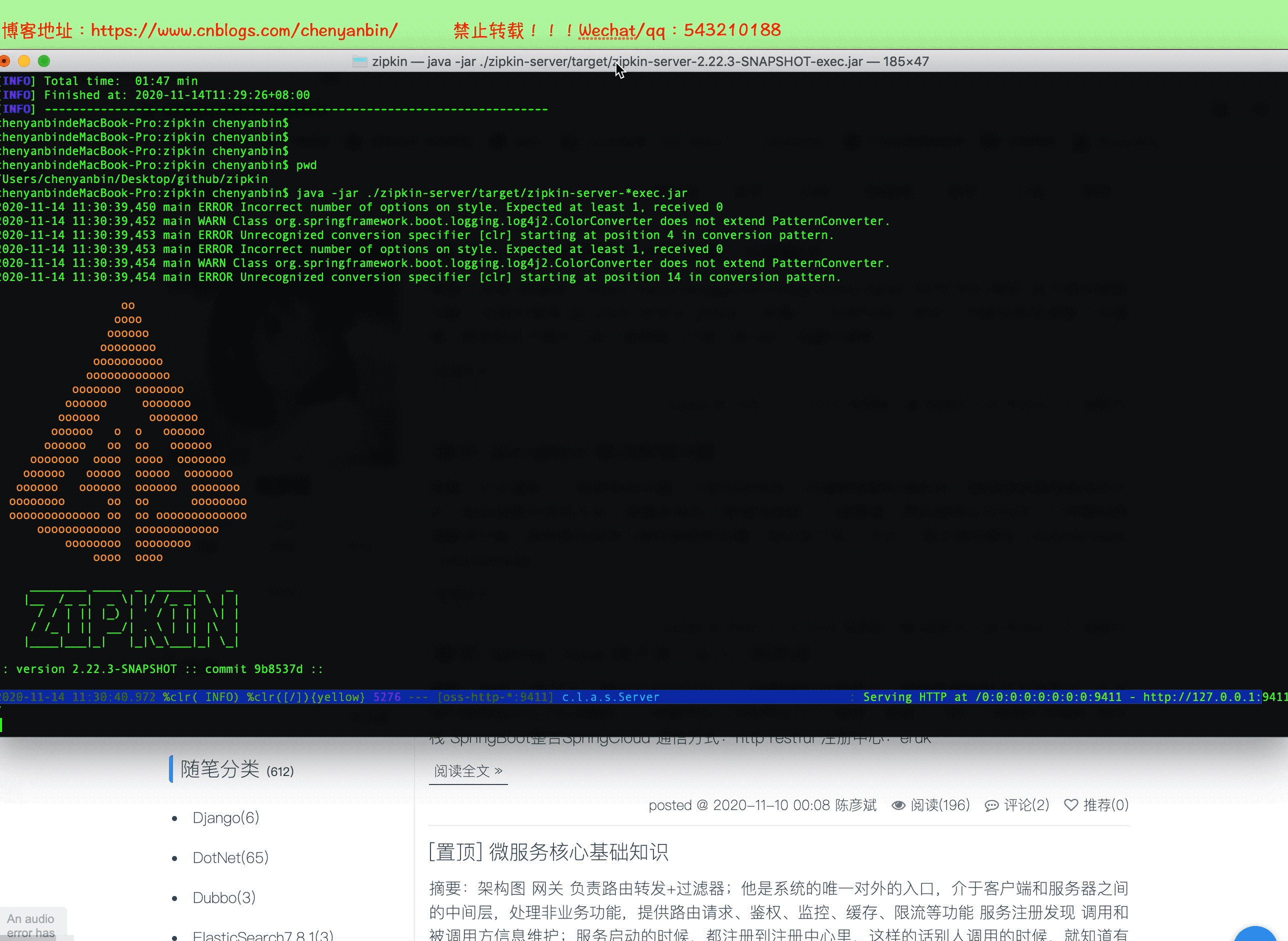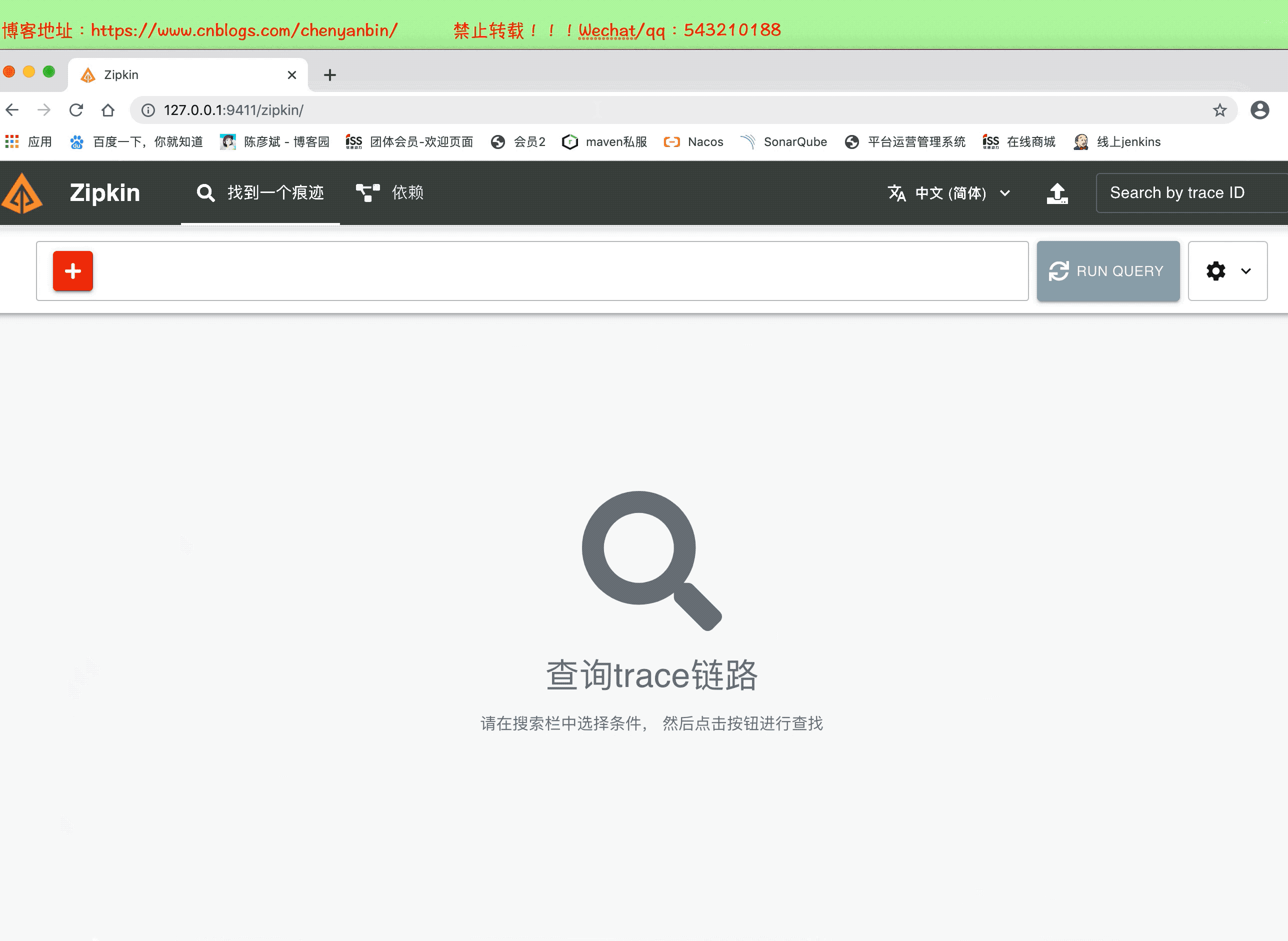
java -jar ./zipkin-server/target/zipkin-server-*exec.jar
備註
因為種種原因,從github上下載這個源碼包,非常慢,可以使用這種方式解決:點我直達
git clone //gitee.com/mirrors/zipkin.git
cd zipkin
mvn -DskipTests clean package
java -jar ./zipkin-server/target/zipkin-server-*exec.jar
啟動
地址:ip:9411
Zpikin+Sleuth整合
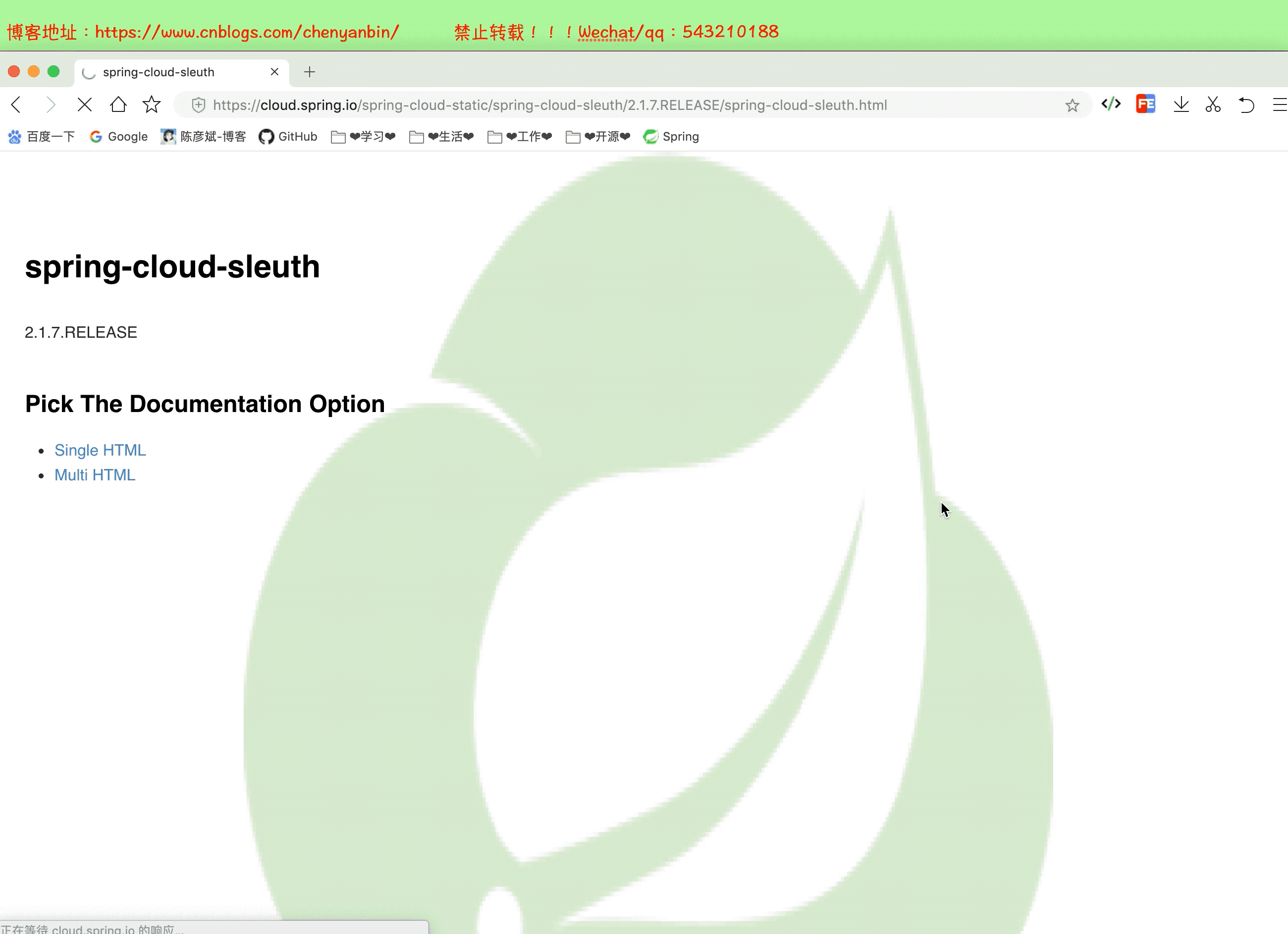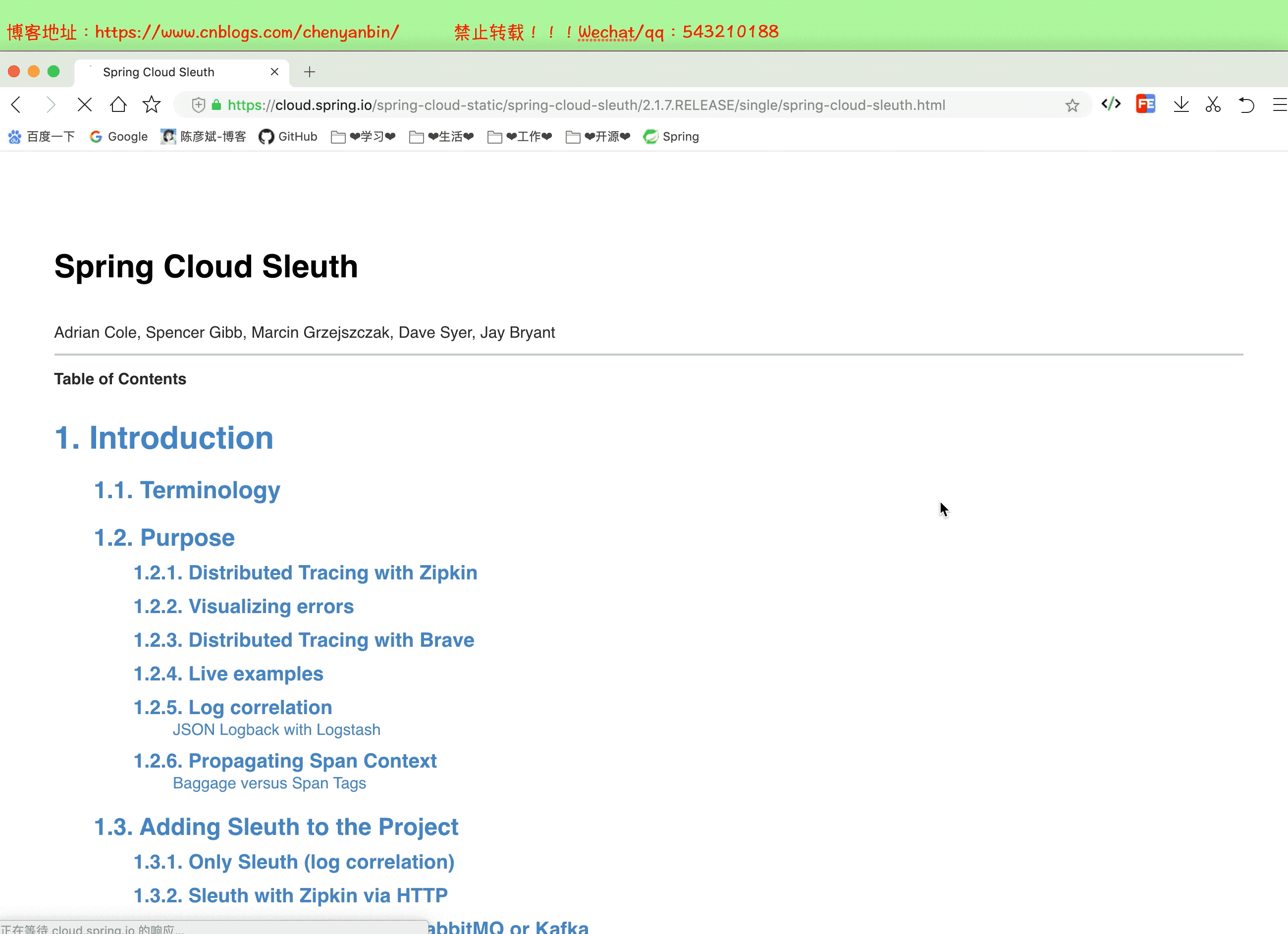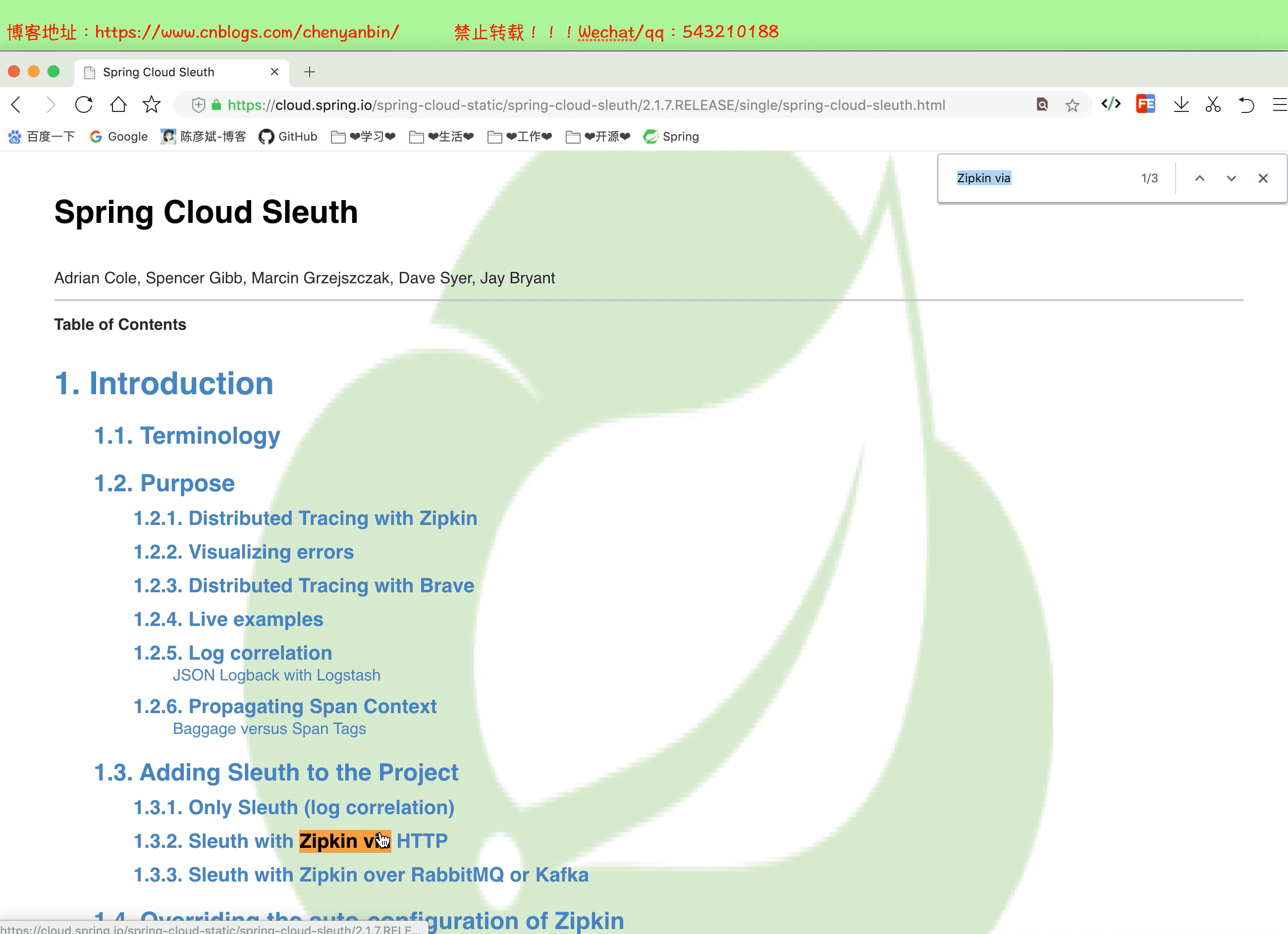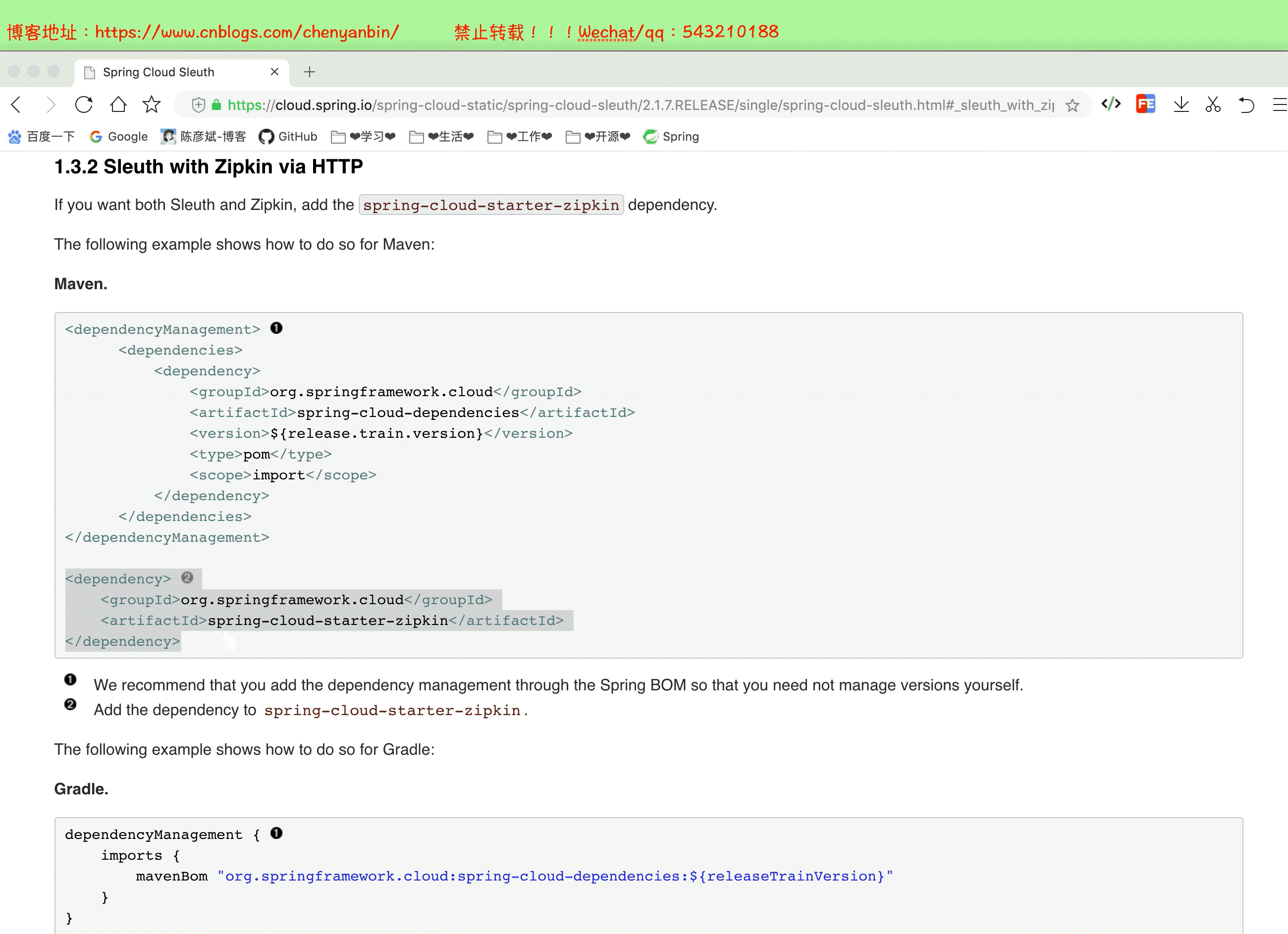
添加依賴
涉及到的服務都得加!(我這裡是在order-service、product-service加的依賴)
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency>

注意
之前加過Sleuth依賴,現在加zipkin依賴,2.x的zipkin已經包含sleuth了,這裡可以把之前的sleuth依賴去掉
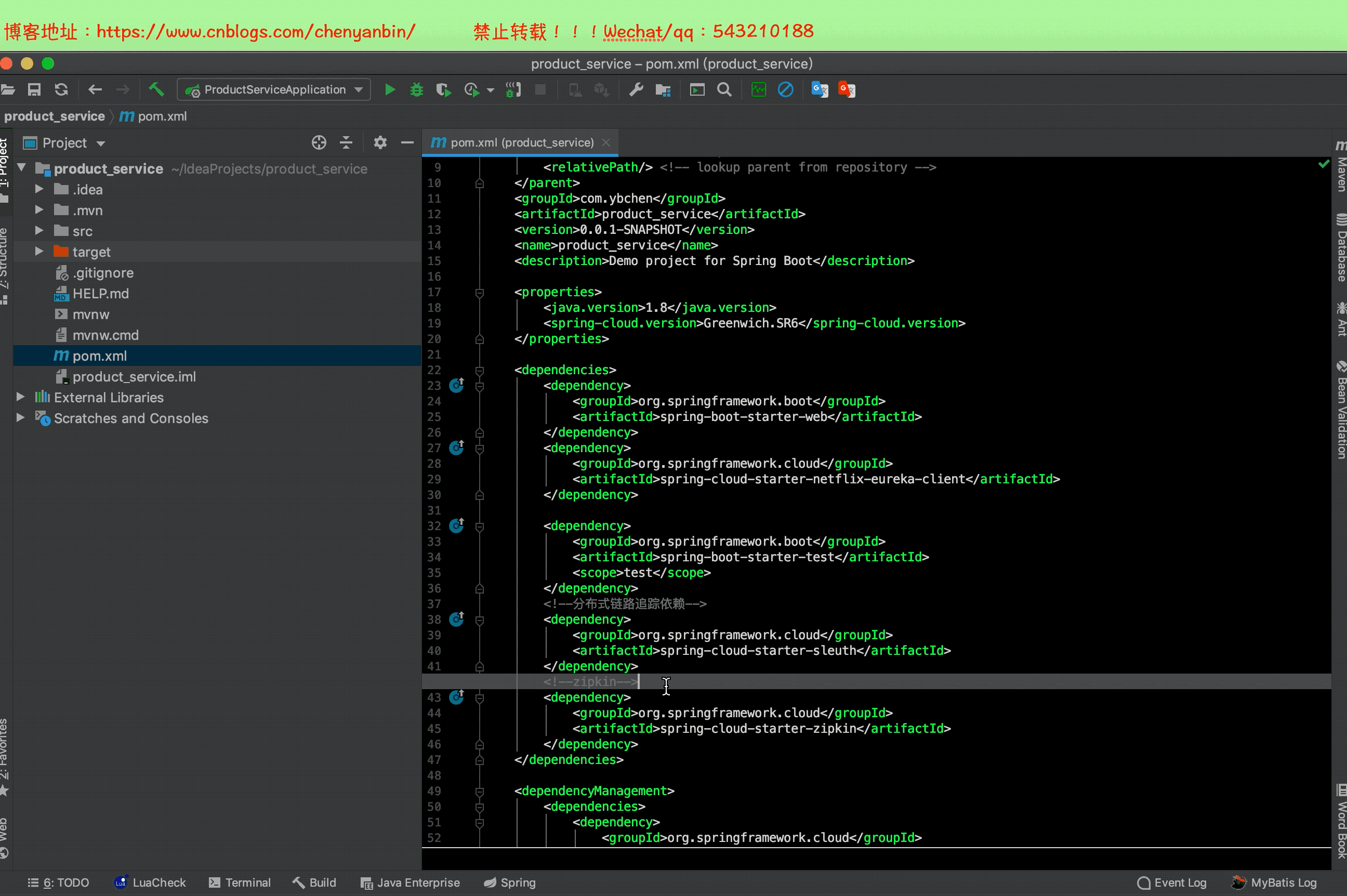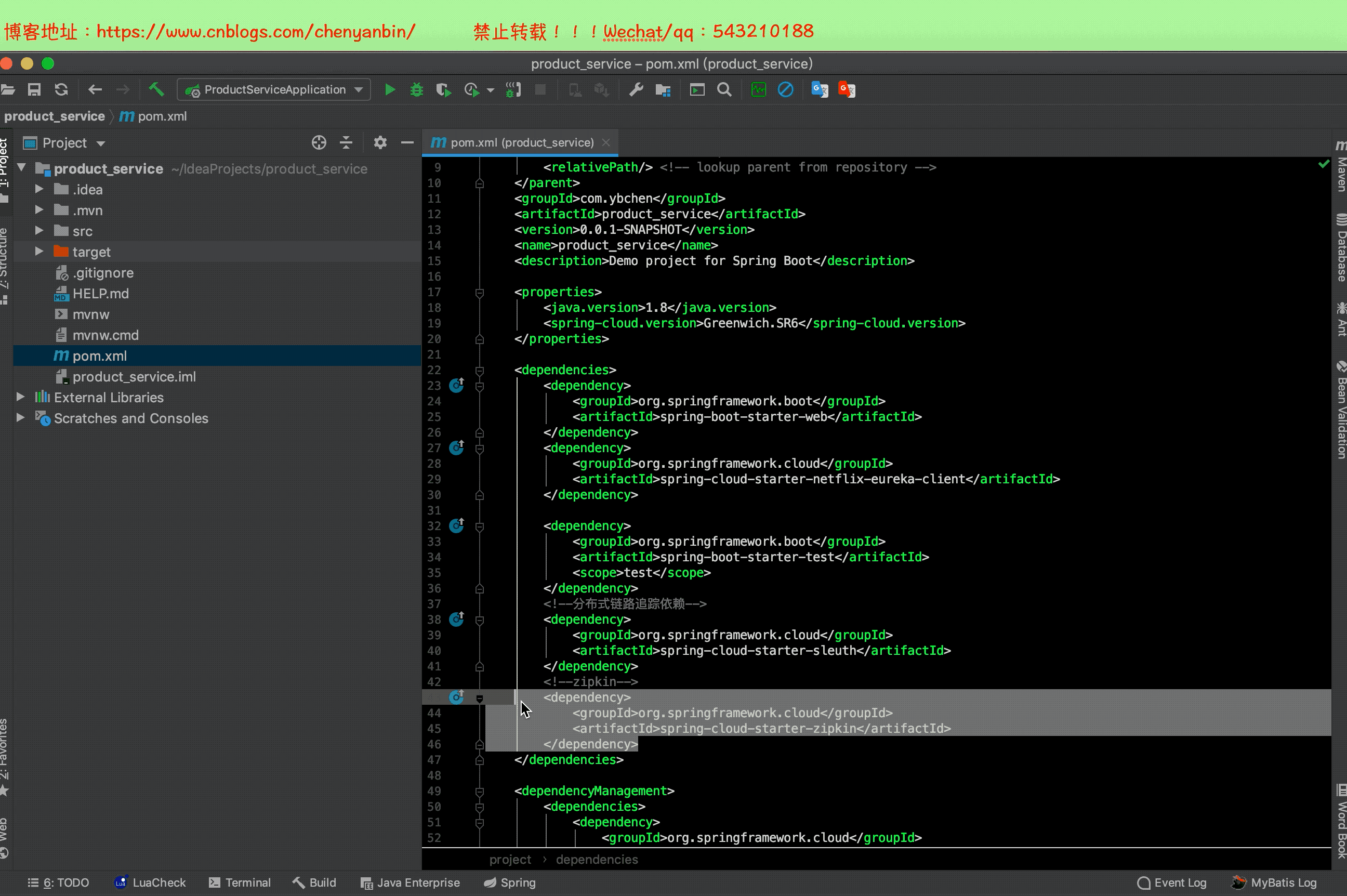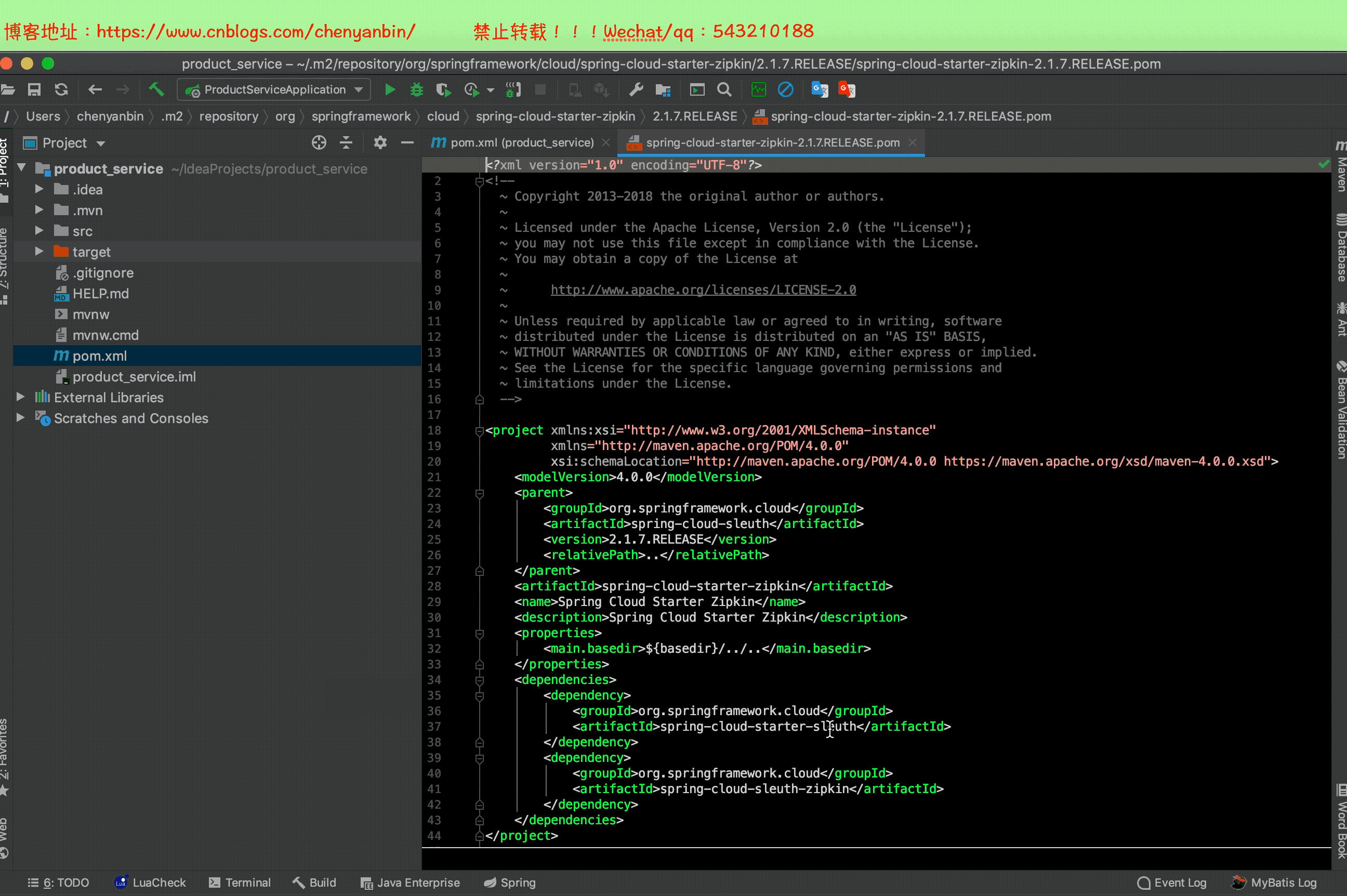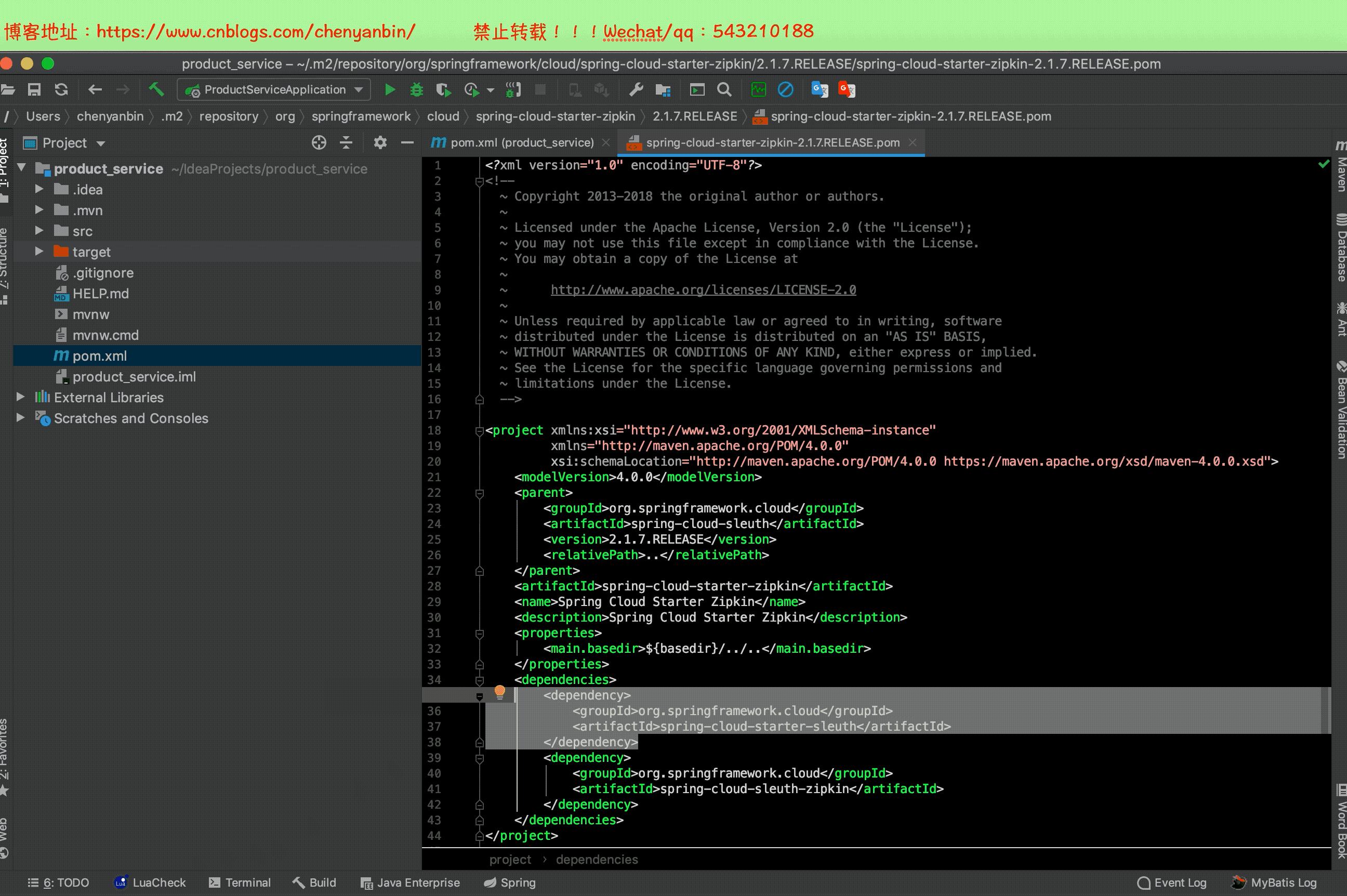
修改配置文件
默認指向的zipkin地址為本機地址://localhost:9411/
默認收集百分比為:10%
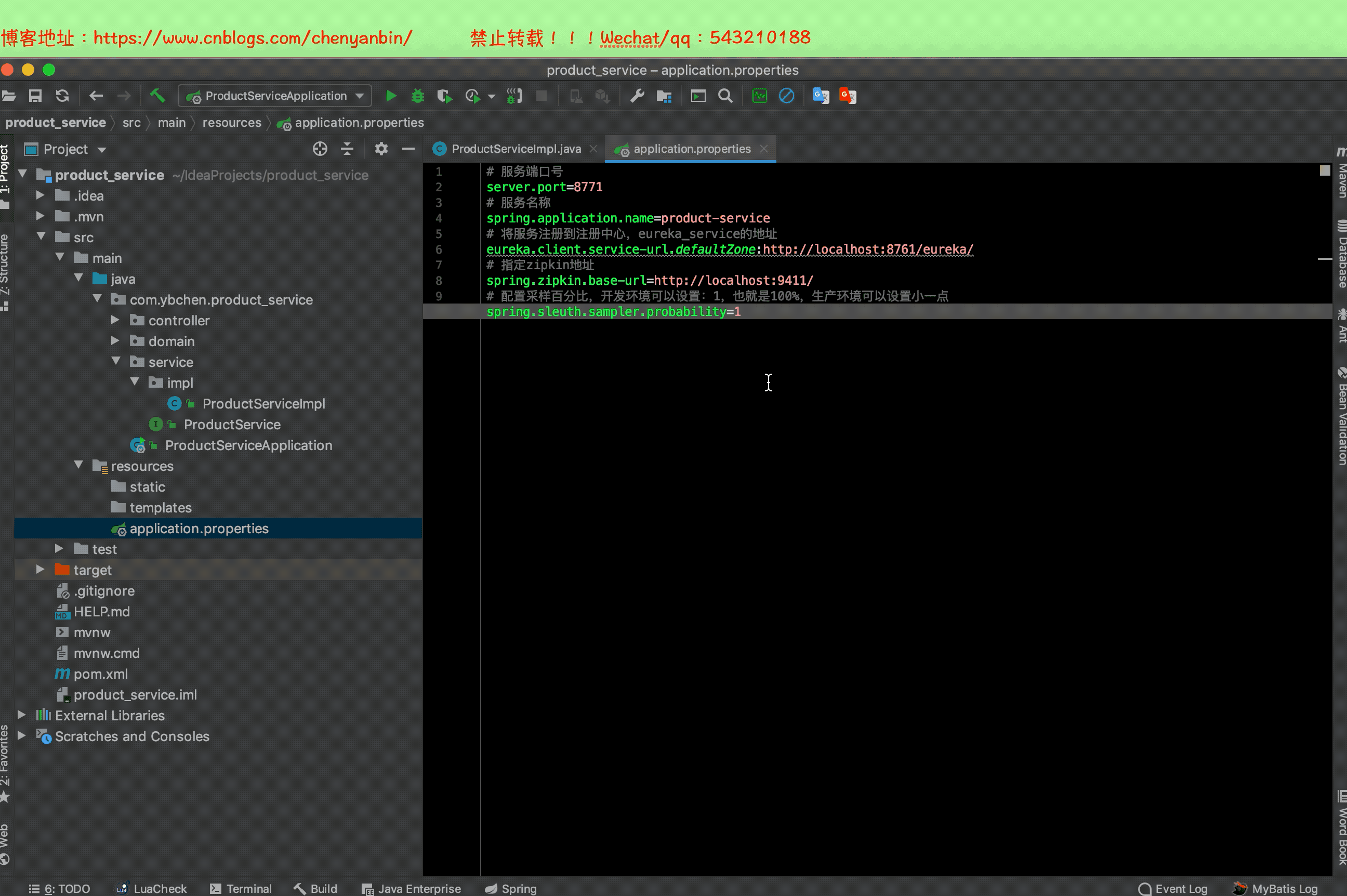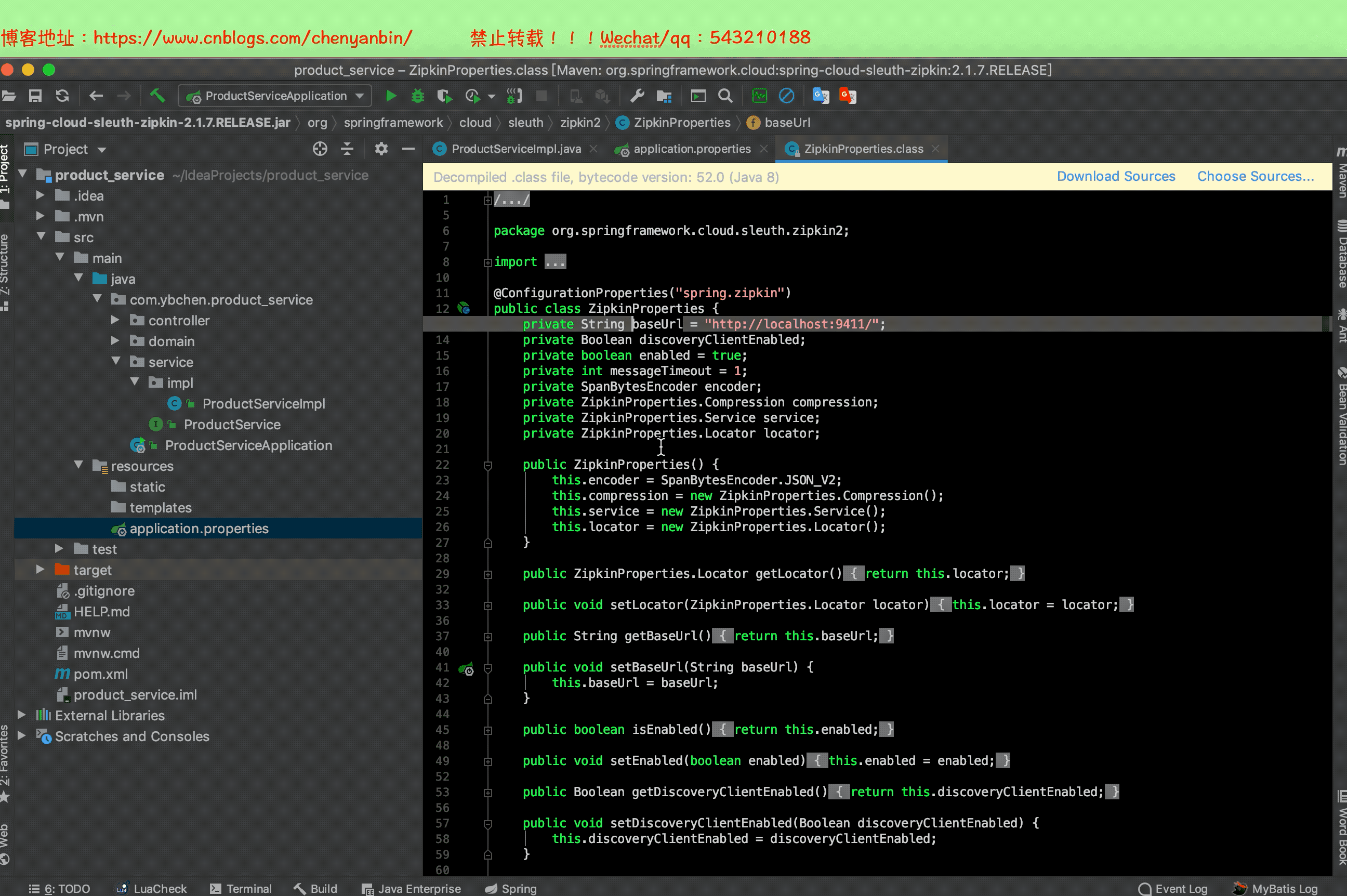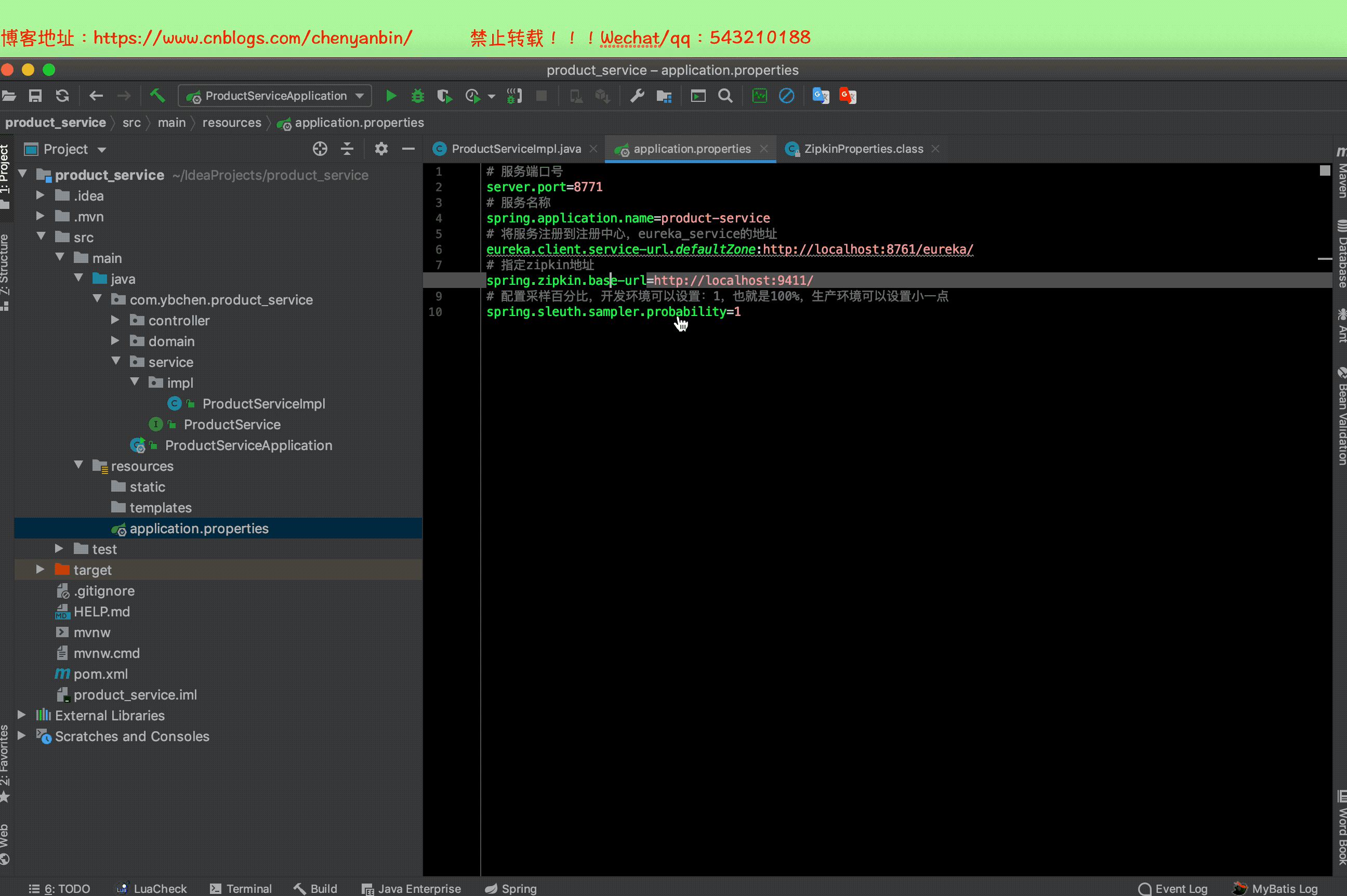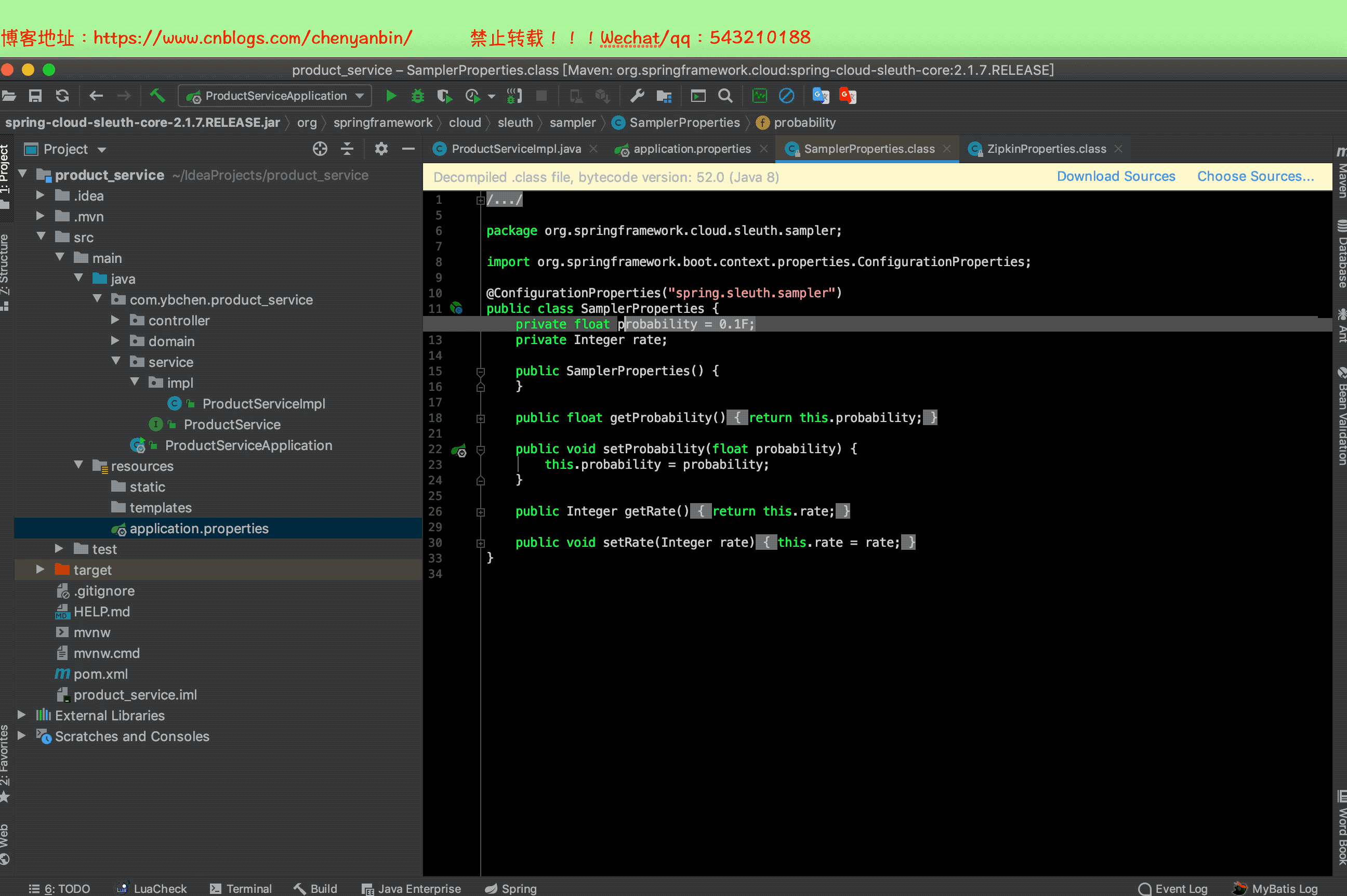
application.properties
# 指定zipkin地址
spring.zipkin.base-url=//localhost:9411/
# 配置取樣百分比,開發環境可以設置:1,也就是100%,生產環境可以設置小一點
spring.sleuth.sampler.probability=1
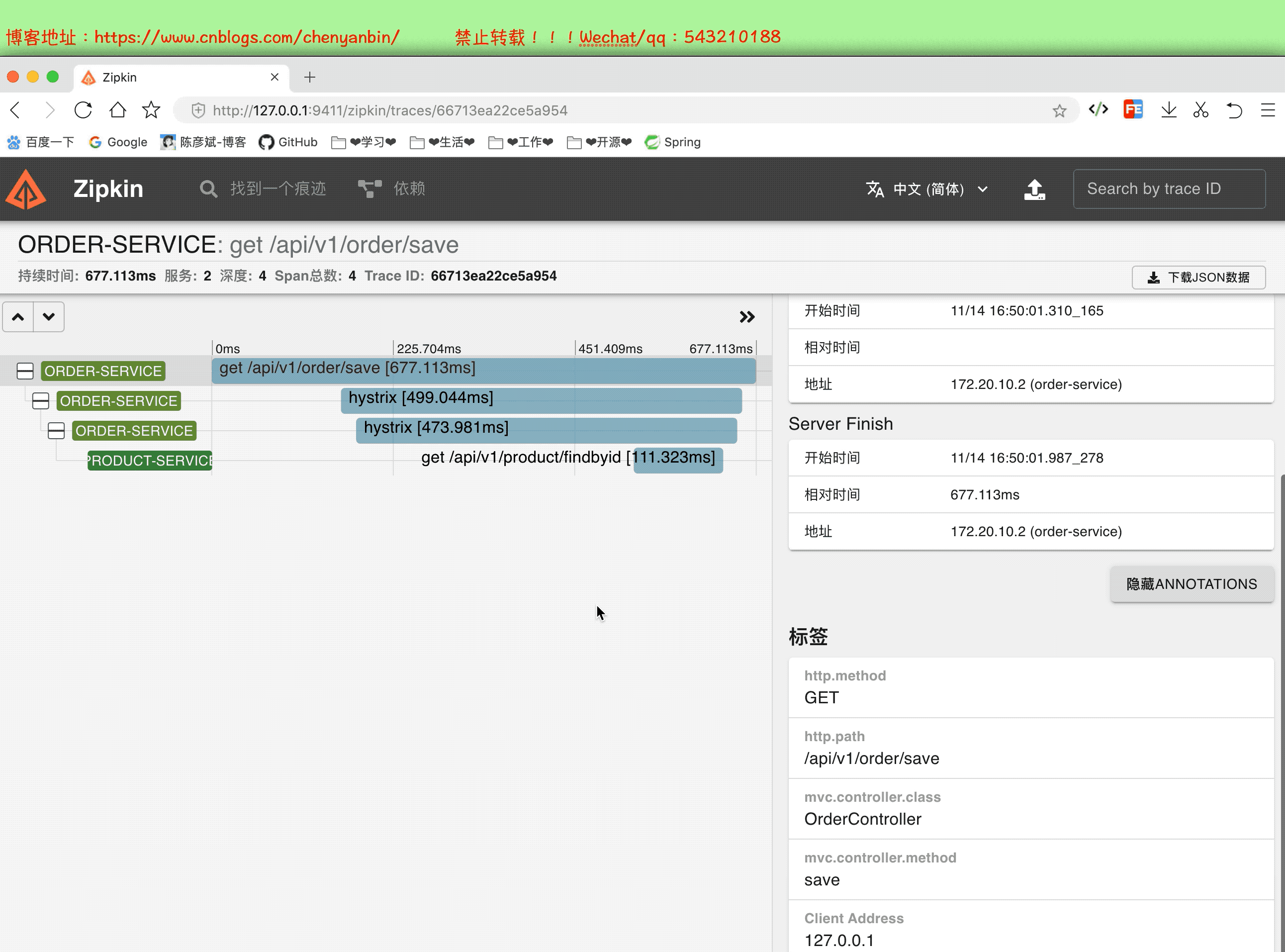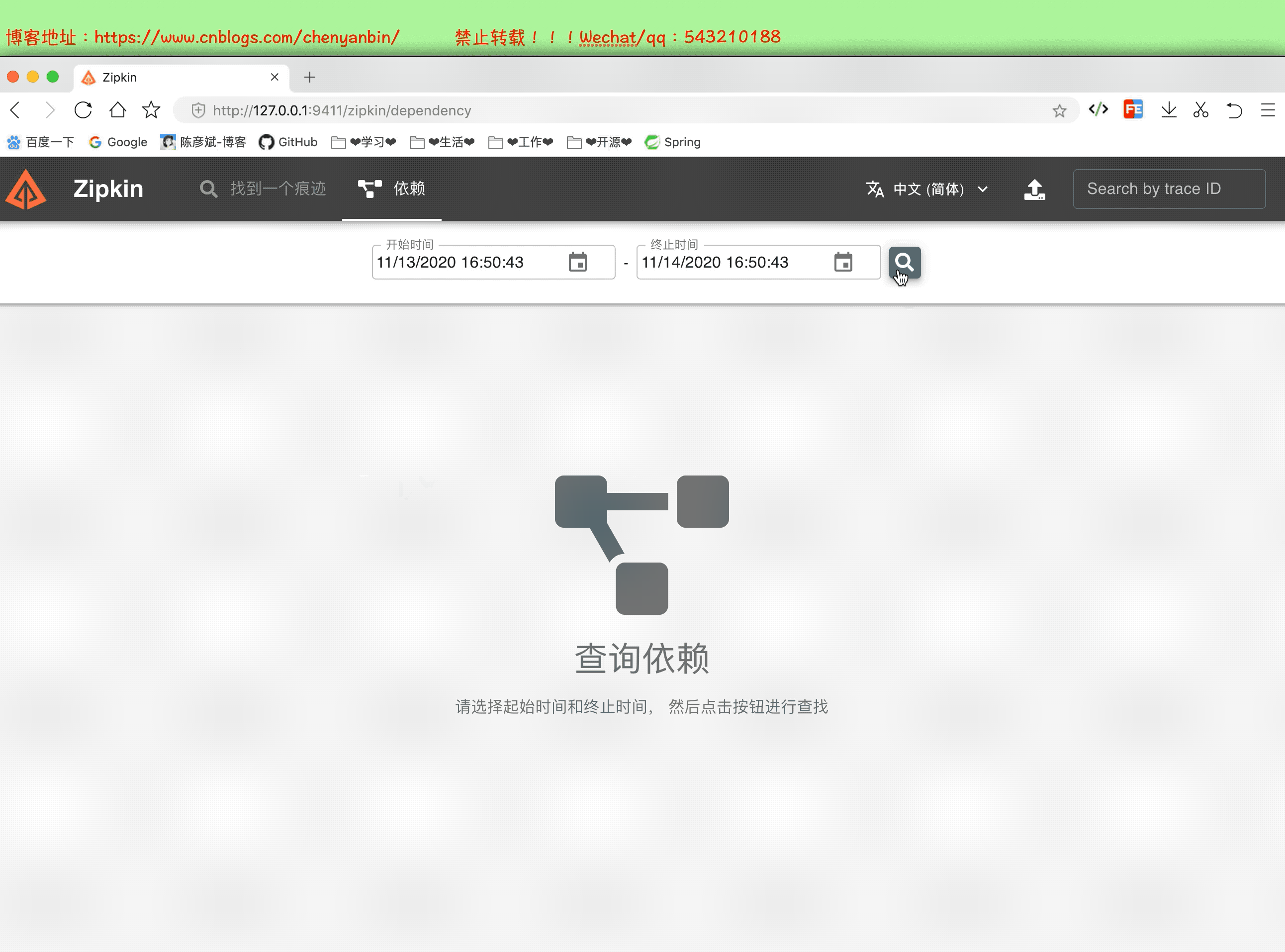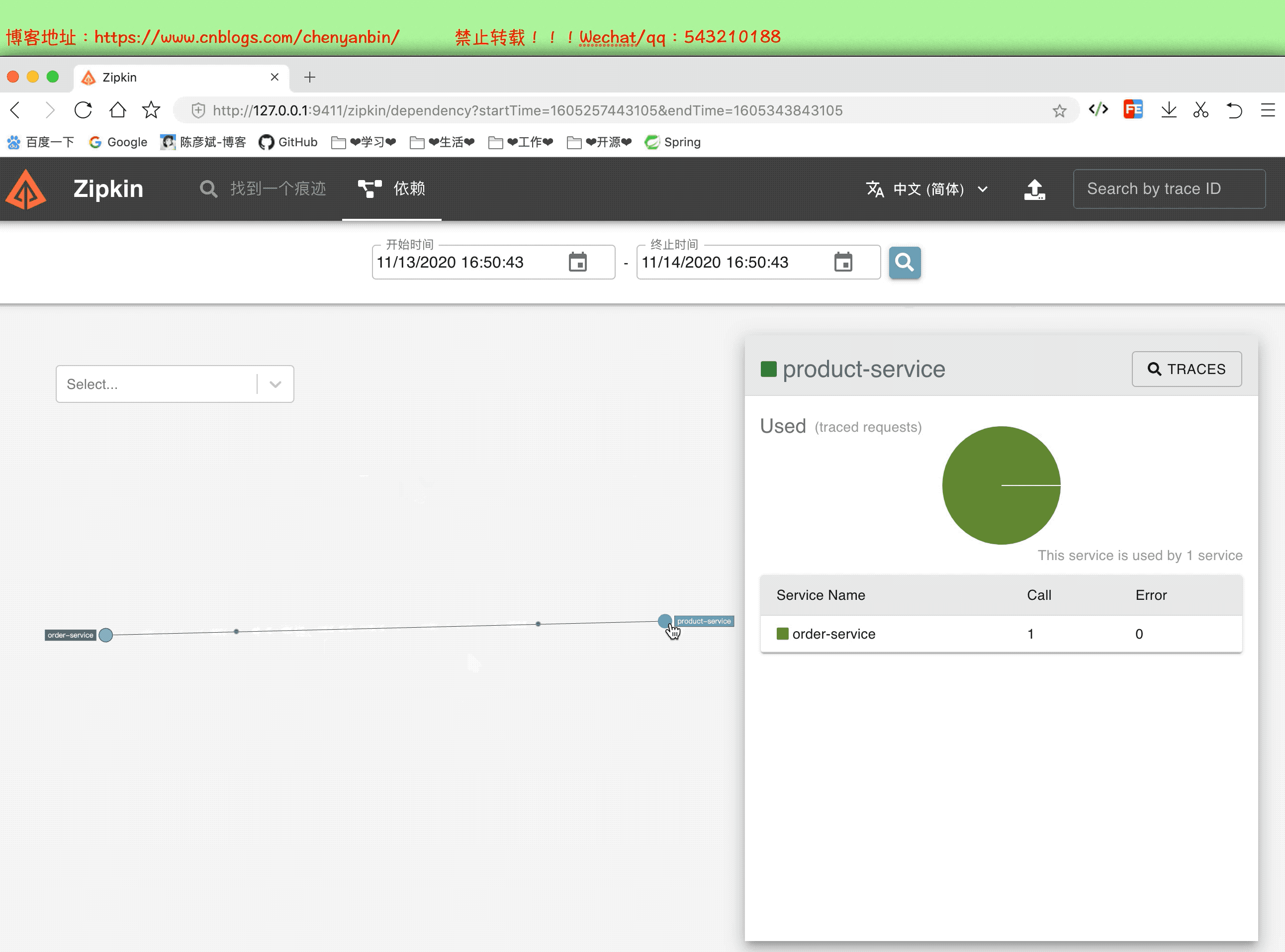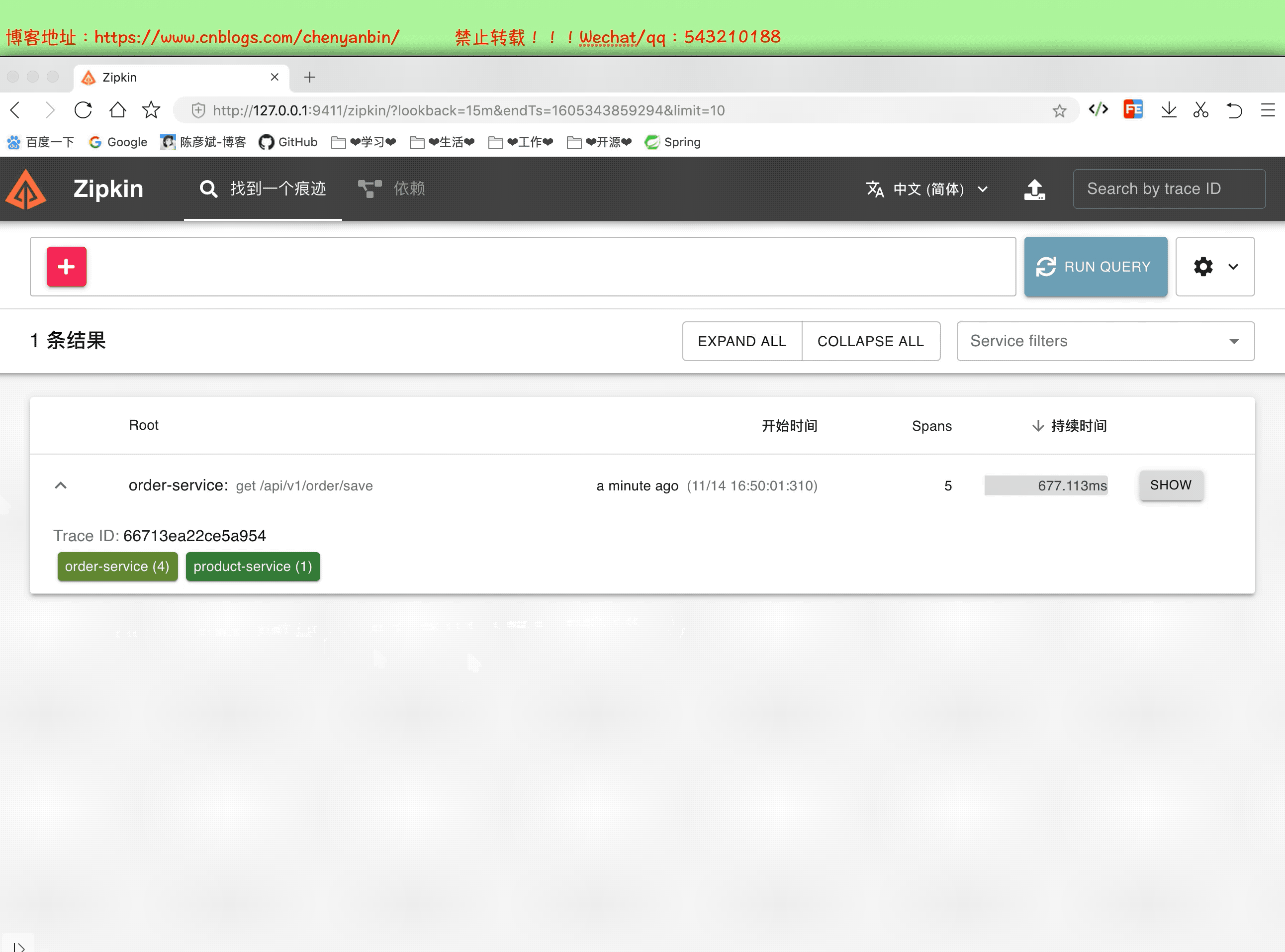
啟動並分析數據
通過這個分析,我們可以知道,微服務中那個服務耗時多,可以在這個服務上做性能優化,可以考慮加:快取、非同步、演算法等等~
源碼下載
好了,今天先到這,只可意會不可言傳,自己體會他的好處~
鏈接: //pan.baidu.com/s/1c4ZWufjmDgzgAAiOOzRg9A 密碼: or12


