綜述 | SLAM迴環檢測方法
- 2019 年 10 月 3 日
- 筆記
本文作者任旭倩,公眾號:電腦視覺life成員,由於格式原因,公式顯示可能出問題,建議閱讀原文鏈接:綜述 | SLAM迴環檢測方法
在視覺SLAM問題中,位姿的估計往往是一個遞推的過程,即由上一幀位姿解算當前幀位姿,因此其中的誤差便這樣一幀一幀的傳遞下去,也就是我們所說的累積誤差。一個消除誤差有效的辦法是進行迴環檢測。迴環檢測判斷機器人是否回到了先前經過的位置,如果檢測到迴環,它會把資訊傳遞給後端進行優化處理。迴環是一個比後端更加緊湊、準確的約束,這一約束條件可以形成一個拓撲一致的軌跡地圖。如果能夠檢測到閉環,並對其優化,就可以讓結果更加準確。
在檢測迴環時,如果把以前的所有幀都拿過來和當前幀做匹配,匹配足夠好的就是迴環,但這樣會導致計算量太大,匹配速度過慢,而且沒有找好初值的情況下,需要匹配的數目非常巨大。因此迴環檢測是SLAM問題的一個難點,針對這個問題,在這裡我們總結幾種經典的方法供大家參考。
詞袋模型(Bag Of Words,BOW)
原理
簡介:現有的SLAM系統中比較流行的迴環檢測方法是特徵點結合詞袋的方法(如ORB-SLAM,VINS-Mono)等。基於詞袋的方法是預先載入一個詞袋字典樹,通知這個預載入的字典樹將影像中的每一局部特徵點的描述子轉換為一個單詞,字典里包含著所有的單詞,通過對整張影像的單詞統計一個詞袋向量,詞袋向量間的距離即代表了兩張影像之間的差異性。在影像檢索的過程中,會利用倒排索引的方法,先找出與當前幀擁有相同單詞的關鍵幀,並根據它們的詞袋向量計算與當前幀的相似度,剔除相似度不夠高的影像幀,將剩下的關鍵幀作為候選關鍵幀,按照詞袋向量距離由近到遠排序[1]。
字典、單詞、描述子之間的關係是:
[ 字典supset單詞 supset 差距較小的描述子的集合 ]
因此,可將基於詞袋模型的迴環檢測方法分為以下三個步驟[2]:
1.提取特徵
2.構建字典(所有單詞的集合)
[ D=left(omega_{1}, omega_{2}, omega_{3} dots omega_{n-1}, omega_{n}right) ]
3.確定一幀中具有哪些單詞,形成詞袋向量 (1表示具有該單詞,0表示沒有)
[ F=1 cdot omega_{1}+0 cdot omega_{2}+0 cdot omega_{3}+ldots+1 cdot omega_{n-1}+0 cdot omega_{n} ]
4.比較兩幀描述向量的差異。
下面分模組逐個介紹:
構建字典
相當於描述子聚類過程,可以用K近鄰演算法,或者使用已經探索過的環境中的特徵在線動態生成詞袋模型[3]。
(1)k近鄰演算法
根據已經離線採集的影像,提取特徵描述子,用k近鄰演算法形成字典的流程是:
1.在字典中的多個描述子中隨機選取k個中心點:
[ c_{1}, dots, c_{k} ]
2.對於每一個樣本,計算它與每個中心點之間的距離,取最小的中心點作為它的歸類。
3.重新計算每個類的中心點。
4.如果每個中心點都變化很小,則演算法收斂,退出,否則繼續迭代尋找。
每個歸好的類就是一個單詞,每個單詞由聚類後距離相近的描述子組成。
其他類似方法還有層次聚類法、K-means++等。
Kmeans++演算法是基於Kmeans改進而來,主要改進點在於中心點的初始化上,不像原始版本演算法的隨機生成,它通過一些策略使得k個初始中心點彼此間距離盡量地遠,以期獲得這些中心點具有更好的代表性,有利於後面的分類操作的效果[8]。
Kmeans++演算法中中心點初始化的流程如下:
1.從n個樣本中隨機選取一個點作為第一個中心點;
2.計算樣本中每個點和距離它最近的中心點之間的距離(D_{i}),根據策略選擇新的中心點
3.重複2直至得到k個中心點。
(2)在線動態生成詞袋模型:
傳統的BOW模型生成離線的字典,更靈活的方法是動態地創建一個字典,這樣沒有在訓練集中出現地特徵可以被有效地識別出來。典型論文有[4],[5]。
在論文中將影像識別中詞袋模型進行了擴展,並用貝葉斯濾波來估計迴環概率。迴環檢測問題涉及識別已建圖區域的困難,而全局定位問題涉及在現有地圖中檢索機器人位置的困難。當在當前影像中找到一個單詞時,之前看到過這個單詞的圖片的tf-idf 分數將會更新。該方法根據探索環境時遇到的特徵動態地構建字典,以便可以有效識別訓練集中未表示的特徵的環境。
字典樹
因為字典太過龐大,如果一一查找匹配單詞,會產生很大的計算量,因此可以用k叉樹的方式來表達字典,建立字典樹流程是這樣的[6]:
-
對應用場景下的大量訓練影像離線提取局部描述符(words)(每張影像可能會有多個描述符)
-
將這些描述符KNN聚成k類;
-
對於第一層的每一節點,繼續KNN聚成k類,得到下一層;
-
按這個循環,直到聚類的層次數達到閾值d,葉子節點表示一個word,中間節點則是聚類的中心。
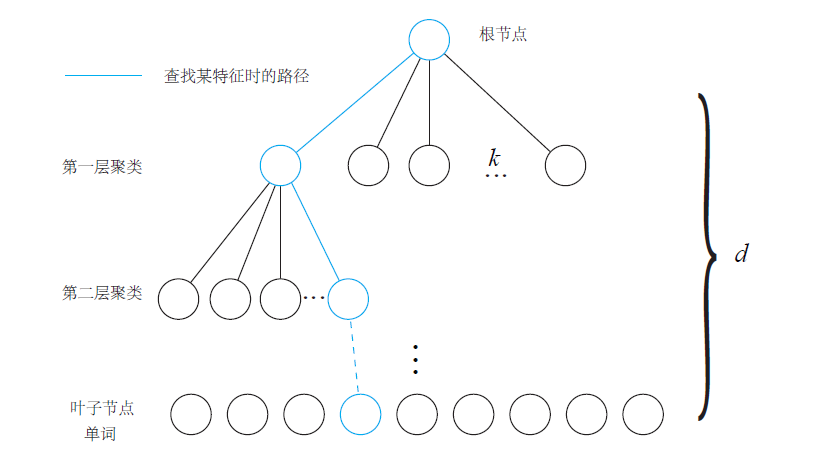
(圖源:視覺SLAM十四講)
然而建立詞袋的一個主要缺點是,它需要預先載入一個訓練好的詞袋字典樹,這個字典樹一般包含大量的特徵單詞,為了保證有良好的區分能力,否則對影像檢索結果有較大影響,但是這會導致這個字典文件比較大,對於一些移動應用來說會是一個很大的負擔。為了解決這個問題,可以通過動態建立k-d樹來避免預載入字典的麻煩。在添加關鍵幀的過程中維護一個全局的k-d樹,將每個特徵點以幀為單位添加到這個k-d樹中。在影像檢索過程中,尋找最接近的節點進行匹配,根據匹配結果對每個關鍵幀進行投票,獲得的票數即可作為該幀的分數,從而生成與當前幀相似的關鍵幀候選集[1]。
詞袋向量
關鍵幀和查詢幀的相似度是通過詞袋向量之間的距離來衡量的。假定一幅影像I的局部描述符集合是[6]
[ D_{I}=left{d_{1}, d_{2}, cdots, d_{n}right} ]
每個描述符(d_{i})在字典樹中查找距離最近的word,假定其word_id為(j),其對應的權重為(w_{j})。查找過程從字典樹的根節點開始,每一層都找距離最近的節點,然後下一層中繼續,直至到達葉子節點。
記詞表的大小為(|V|),定義這個在字典樹中查找的映射為
[ V T(cdot) : D rightarrow{1,2, cdots,|V|} ]
如果兩個描述符映射到同一個word,則權重相加,得到一個定長的向量:
[ V_{I}=left{v_{1}, v_{2}, cdots, v_{j}, cdots, v_{|V|}right} ]
其中
[ v_{j}=sum_{i, V Tleft(d_{i}right)=j} w_{j} ]
這樣在根據word查找關鍵幀時,就不用遍歷所有的關鍵幀,只要把查詢幀描述符映射的那些words索引的關鍵幀找到即可。
相似度計算
一些詞在用來識別兩個影像是否顯示同一個地方比其他詞更加有用,而有一些詞對識別貢獻不大,為了區分這些詞的重要性,可以為每個詞分配特定權重,常見方案是TF-IDF。它綜合了影像中的詞的重要性(TF-Term Frequency)和收集過程中詞的重要性(IDF-Inverse Document Frequency),用以評估一個詞對於一個文件或者一個語料庫中的一個領域文件集的重複程度。
對於單幅影像,假設在單幅影像中一共出現的單詞次數為(n),某個葉子節點單詞(w_{i})出現了(n_{i})次,則TF為[7]:
TF:某個特徵在單幅影像中出現的頻率,越高則它的區分度就越高
[ T F_{i}=frac{n_{i}}{n} ]
在構建字典時,考慮IDF,假設所有特徵數量為(n),葉子節點 (w_{i})的數量為(n_{i}),則IDF為
IDF:某單詞在字典中出現的頻率越低,則區分度越低
[ I D F_{i}=ln left(frac{n}{n_{i}}right) ]
則(w_{i})的權重等於TF和IDF的乘積:
[ eta_{i}=T F_{i} times I D F_{i} ]
考慮權重後,對於某個影像(A),它的特徵點可以對應很多單詞,組成它的詞袋:
[ A=left{left(w_{1}, eta_{1}right),left(w_{2}, eta_{2}right), ldots,left(w_{N}, eta_{N}right)right} triangleq v_{A} ]
這樣便用單個向量(v_{A})描述了一個影像(A),這個向量是一個稀疏向量,非零部分代表含有哪些單詞,這些值即為TF-IDF的值。
得到(A) 、(B) 兩幅影像的(v_{A})和(v_{B})後,可以通過(L_{1})範式形式計算差異性:
[ sleft(v_{A}-v_{B}right)=2 sum_{i=1}^{N}left|v_{A i}right|+left|v_{B i}right|-left|v_{A i}-v_{B i}right| ]
其中,(v_{A i})表示只在(A)中有的單詞,(v_{B i})表示只在(B)中有的單詞,(v_{A i}-v_{B i})表示在(A)、(B)中都有的單詞。(s)越大,相似性越大,當評分(s)足夠大時即可判斷兩幀可能為迴環。
此外,如果只用絕對值表示兩幅影像的相似性,在環境本來就相似的情況下幫助並不大,因此,可以取一個先驗相似度(boldsymbol{S}left(boldsymbol{v}_{t}, boldsymbol{v}_{t-Delta t}right)),它表示某時刻關鍵幀影像與上一時刻關鍵幀的相似性,然後,其他分之都參照這個值進行歸一化:
[ sleft(boldsymbol{v}_{t}, boldsymbol{v}_{t_{j}}right)^{prime}=sleft(boldsymbol{v}_{t}, boldsymbol{v}_{t_{j}}right) / sleft(boldsymbol{v}_{t}, boldsymbol{v}_{t-Delta t}right) ]
因此,可以定義如果當前幀與之前某關鍵幀的相似度,超過當前幀與上一關鍵幀相似度的3倍,就認為可能存在迴環。
此外,還有其他的方法,分為局部(Squared TF, Frequency logarithm, Binary,BM25 TF等等)和全局(Probabilistic IDF, Squared IDF)等,感興趣可以繼續搜索。
迴環驗證
詞袋模型的另一個問題是它並不完全精確,會出現假陽性數據。在迴環檢測檢索的後期階段需要用其他方法加以驗證。如果當前跟蹤已經完全丟失,需要重定位給出當前幀的位姿來調整。在重定位的驗證中,使用空間資訊進行篩選,可以使用PnP進行後驗校正,或者使用條件隨機場。這個驗證可以去掉那些和參考影像不符合幾何一致性的影像[3]。得到準確的影像匹配後,可以根據匹配結果去求解相機位姿。
如果系統跟蹤正常,發現了之前訪問過的場景,需要進行迴環檢測添加新約束。基於詞袋的迴環檢測方法只在乎單詞有無,不在乎單詞的排列順序,會容易引發感知偏差,此外,詞袋迴環完全依賴於外觀而沒有利用任何的幾何資訊,會導致外觀相似的影像容易被當作迴環,因此需要加一個驗證步驟,驗證主要考慮以下三點[1]:
1)不與過近的幀發生迴路閉合如果關鍵幀選得太近,那麼導致兩個關鍵幀之間的相似性過高,檢測出的迴環意義不大,所以用於迴環檢測的幀最好是稀疏一些,彼此之間不太相同,又能涵蓋整個環境[7]。且為了避免錯誤的迴環,某一位姿附近連續多次(ORB-SLAM中為3次)與歷史中某一位姿附近出現迴環才判斷為迴環;迴環候選幀仍然要匹配,匹配點足夠才為迴環。
2)閉合的結果在一定長度的連續幀上都是一致的。如果成功檢測到了迴環,比如說出現在第1 幀和第(n) 幀。那麼很可能第(n+1) 幀,(n+2) 幀都會和第1 幀構成迴環。但是,確認第1 幀和第(n) 幀之間存在迴環,對軌跡優化是有幫助的,但再接下去的第(n + 1) 幀,(n + 2) 幀都會和第1 幀構成迴環,產生的幫助就沒那麼大了,因為已經用之前的資訊消除了累計誤差,更多的迴環並不會帶來更多的資訊。所以,我們會把「相近」的迴環聚成一類,使演算法不要反覆地檢測同一類的迴環。
3)閉合的結果在空間上是一致的。即是對迴環檢測到的兩個幀進行特徵匹配,估計相機的運動,再把運動放到之前的位姿圖中,檢查與之前的估計是否有很大出入。
經典詞袋模型源碼
DBOW
這個庫已經很舊了,簡要介紹:DBow庫是一個開源C ++庫,用於索引影像並將影像轉換為詞袋錶示。它實現了一個分層樹,用於近似影像特徵空間中的最近鄰並創建可視辭彙表。DBow還實現了一個基於逆序文件結構的影像資料庫,用於索引影像和快速查詢。DBow不需要OpenCV(演示應用程式除外),但它們完全兼容。
源碼地址:https://github.com/dorian3d/DBow
DBOW2
DBoW2是DBow庫的改進版本,DBoW2實現了具有正序和逆序指向索引圖片的的影像資料庫,可以實現快速查詢和特徵比較。與以前的DBow庫的主要區別是:
- DBoW2類是模板化的,因此它可以與任何類型的描述符一起使用。
- DBoW2可直接使用ORB或BRIEF描述符。
- DBoW2將直接文件添加到影像資料庫以進行快速功能比較,由DLoopDetector實現。
- DBoW2不再使用二進位格式。另一方面,它使用OpenCV存儲系統來保存辭彙表和資料庫。這意味著這些文件可以以YAML格式存儲為純文本,更具有兼容性,或以gunzip格式(.gz)壓縮以減少磁碟使用。
- 已經重寫了一些程式碼以優化速度。DBoW2的介面已經簡化。
- 出於性能原因,DBoW2不支援停止詞。
DBoW2需要OpenCV和Boost::dynamic_bitset類才能使用BRIEF版本。
DBoW2和DLoopDetector已經在幾個真實數據集上進行了測試,執行了3毫秒,可以將影像的簡要特徵轉換為詞袋向量量,在5毫秒可以在資料庫中查找影像匹配超過19000張圖片。
源碼地址:https://github.com/dorian3d/DBoW2
DBoW3
DBoW3是DBow2庫的改進版本,與以前的DBow2庫的主要區別是:
- DBoW3隻需要OpenCV。DLIB的DBoW2依賴性已被刪除。
- DBoW3能夠適用二進位和浮點描述符。無需為任何描述符重新實現任何類。
- DBoW3在linux和windows中編譯。
- 已經重寫了一些程式碼以優化速度。DBoW3的介面已經簡化。
- 使用二進位文件。二進位文件載入/保存比yml快4-5倍。而且,它們可以被壓縮。
- 兼容DBoW2的yml文件
源碼地址:https://github.com/rmsalinas/DBow3
FBOW
FBOW(Fast Bag of Words)是DBow2 / DBow3庫的極端優化版本。該庫經過高度優化,可以使用AVX,SSE和MMX指令加速Bag of Words創建。在載入辭彙表時,fbow比DBOW2快約80倍(參見tests目錄並嘗試)。在使用具有AVX指令的機器上將影像轉換為詞袋時,它的速度提高了約6.4倍。
源碼地址:https://github.com/rmsalinas/fbow
FAB-MAP
是一種基於外觀識別場所問題的概率方法。我們提出的系統不僅限於定位,而是可以確定新觀察來自以前看不見的地方,從而增加其地圖。實際上,這是一個外觀空間的SLAM系統。我們的概率方法允許我們明確地考慮環境中的感知混疊——相同但不明顯的觀察結果來自同一地點的可能性很小。我們通過學習地方外觀的生成模型來實現這一目標。通過將學習問題分成兩部分,可以僅通過對一個地方的單個觀察來在線學習新地點模型。演算法複雜度在地圖中的位置數是線性的,特別適用於移動機器人中的在線環閉合檢測。
源碼地址:https://github.com/arrenglover/openfabmap
詞袋模型在V-SLAM上的實現
c++版本
部落格介紹:https://nicolovaligi.com/bag-of-words-loop-closure-visual-slam.html
源碼地址:https://github.com/nicolov/simple_slam_loop_closure
python版本
Loop Closure Detection using Bag of Words
源碼地址:https://github.com/pranav9056/bow
matlab:
部落格介紹:http://www.jaijuneja.com/blog/2014/10/bag-words-localisation-mapping-textured-scenes/
源碼地址:https://github.com/jaijuneja/texture-localisation-matlab
ORB-SLAM
源碼地址:https://github.com/raulmur/ORB_SLAM
ORB-SLAM2
源碼地址:https://github.com/raulmur/ORB_SLAM2
VINS-Mono
https://github.com/HKUST-Aerial-Robotics/VINS-Mono
kintinous
https://github.com/mp3guy/Kintinuous
文獻資料
[1] 鮑虎軍,章國峰 ,秦學英.增強現實:原理、演算法與應用[M].科學出版社:北京,2019:114-115.
[2] https://zhuanlan.zhihu.com/p/45573552
[3] J. Fuentes-Pacheco, J. Ruiz-Ascencio, and J. M. Rendón-Mancha, 「Visual simultaneous localization and mapping: a survey,」 Artif Intell Rev, vol. 43, no. 1, pp. 55–81, Jan. 2015.
[4] A. Angeli, S. Doncieux, J.-A. Meyer, and D. Filliat, 「Real-time visual loop-closure detection,」 in 2008 IEEE International Conference on Robotics and Automation, Pasadena, CA, USA, 2008, pp. 1842–1847.
[5] T. Botterill, S. Mills, A. Ltd, and C. St, 「Bag-of-Words-driven Single Camera Simultaneous Localisation and Mapping,」 p. 28.
[6] https://www.zhihu.com/question/49153462
[7] 高翔,張濤.視覺SLAM十四講[M].電子工業出版社,2017:306-316.
[8] https://blog.csdn.net/lwx309025167/article/details/80524020
隨機蕨法(Random ferns)
原理
這種重定位方法將相機的每一幀壓縮編碼,並且有效的對不同幀之間相似性進行評估。而壓縮編碼的方式採用隨機蕨法。在這個基於關鍵幀的重定位方法中,採用基於fern的幀編碼方式:輸入一個RGB-D圖片,在影像的隨機位置評估簡單的二進位測試,將整個幀進行編碼,形成編碼塊,每個fern產生一小塊編碼,並且編碼連接起來可以表達一個緊湊的相機幀。每一個編碼塊指向一個編碼表的一行,和具有等效的編碼、存儲著關鍵幀id的fern關聯起來,編碼表以哈希表的形式存儲。
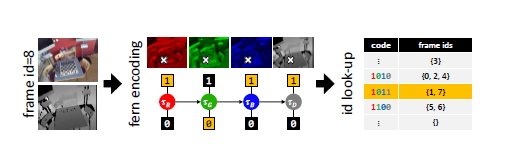
當不斷採集新的圖片時,如果不相似性大於閾值,新進來的幀的id將會被添加到行中。在跟蹤恢復的時候,從哈希表中檢索姿態,將最相似的關鍵幀關聯起來。一個新的幀和之前所有編碼幀之間的不相似程度通過逐塊漢明距離(BlockHD)來度量。
[ operatorname{BlockHD}left(b_{C}^{I}, b_{C}^{J}right)=frac{1}{m} sum_{k=1}^{m} b_{F_{k}}^{I} equiv b_{F_{k}}^{J} ]
當返回值是0時,兩個編碼塊是相似的。當返回值是1時,代表至少有一位不同。因此,BlockHD代表不同編碼塊的個數。塊的長短不同,會直接影響到BlockHD在找相似幀時的精度/召回性質。判斷一張圖片是否滿足足夠的相似性需要設定一個最小BlockHD, 對於每一張新來的幀,計算
[ kappa_{I}=min _{forall J} mathrm{B} operatorname{lockHD}left(b_{C}^{I}, b_{C}^{J}right)=min _{forall J}left(frac{m-q_{I J}}{m}right) ]
(kappa_{I})表示新的一個幀提供了多少有用的資訊,如果新的一幀(kappa_{I})值很低,代表該幀和之前的幀很相似,如果(kappa_{I})值高,表示這個姿態是從一個新的視角拍攝的,理應被存為關鍵幀。通過這樣的觀測,可以試試捕獲追蹤幀,並且自動決定哪些應該被存為關鍵幀。通過值(kappa_{I})和一個實現確定好的閾值(t),可以決定新來的一幀是應該添加到哈希表中,還是被剔除。這種找到關鍵幀並檢索位姿的方法可以有效的減少三維重建的時間,並且適用於目前開源的slam演算法。
程式碼
Random Fern在VSLAM中的應用
kinect fusion
https://github.com/Nerei/kinfu_remake
elastic fusion
https://github.com/mp3guy/ElasticFusion
PTAM
PTAM中的重定位方法和random ferns很像。PTAM是在構建關鍵幀時將每一幀影像縮小並高斯模糊生成一個縮略圖,作為整張影像的描述子。在進行影像檢索時,通過這個縮略圖來計算當前幀和關鍵幀的相似度。這種方法的主要缺點是當視角發生變化時,結果會發生較大的偏差,魯棒性不如基於不變數特徵的方法。
https://github.com/Oxford-PTAM/PTAM-GPL
文獻資料
[1] B. Glocker, S. Izadi, J. Shotton, and A. Criminisi, 「Real-time RGB-D camera relocalization,」 in 2013 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Adelaide, Australia, 2013, pp. 173–179.
[2] B. Glocker, J. Shotton, A. Criminisi, and S. Izadi, 「Real-Time RGB-D Camera Relocalization via Randomized Ferns for Keyframe Encoding,」 IEEE Trans. Visual. Comput. Graphics, vol. 21, no. 5, pp. 571–583, May 2015.
[3] https://blog.csdn.net/fuxingyin/article/details/51436430
基於深度學習的方法
基於深度學習的影像檢索方法是全局檢索方法,需要大量的數據進行預訓練,但對場景變化容忍度好。一些端到端的相機位姿估計方法取得了不錯的成果。深度學習和視覺定位結合的開創性工作PoseNet就使用的是神經網路直接從影像中得到6自由度的相機位姿。相較於傳統的視覺定位方法,省去了複雜的影像匹配過程,並且不需要對相機位姿進行迭代求解,但是輸入影像必須在訓練場景中。後來在此基礎上,他們又在誤差函數中使用了投影誤差,進一步提高了位姿估計的精度。同樣,MapNet使用了傳統方法求解兩張圖象的相對位姿,與網路計算出來的相對位姿對比得到相機的相對位姿誤差,將相對位姿誤差添加到網路的損失函數中,使得求解出來的相機位姿更加平滑,MapNet還可以將連續多幀的結果進行位姿圖優化,使得最終估計出的相機位姿更為準確。
有監督的方法
基本都是用周博磊的Places365
原理介紹:Places365是Places2資料庫的最新子集。Places365有兩個版本:Places365-Standard和Places365-Challenge。Places365-Standard的列車集來自365個場景類別的約180萬張影像,每個類別最多有5000張影像。我們已經在Places365-Standard上訓練了各種基於CNN的網路,並將其發布如下。同時,一系列的Places365-Challenge列車還有620萬張圖片以及Places365-Standard的所有圖片(總共約800萬張圖片),每個類別最多有40,000張圖片。Places365-Challenge將與2016年的Places2挑戰賽一起舉行ILSVRC和COCO在ECCV 2016上的聯合研討會。
Places3-標準版和Places365-Challenge數據在Places2網站上發布。
Places365-Standard上經過預先培訓的CNN模型:
- AlexNet-places365
- GoogLeNet-places365
- VGG16-places365
- VGG16-hybrid1365
- ResNet152-places365
- ResNet152-hybrid1365
源碼地址:https://github.com/CSAILVision/places365

無監督的方法
CALC原理
在大型實時SLAM中採用無監督深度神經網路的方法檢測迴環可以提升檢測效果。該方法創建了一個自動編碼結構,可以有效的解決邊界定位錯誤。對於一個位置進行拍攝,在不同時間時,由於視角變化、光照、氣候、動態目標變化等因素,會導致定位不準。卷積神經網路可以有效地進行基於視覺的分類任務。在場景識別中,將CNN嵌入到系統可以有效的識別出相似圖片。但是傳統的基於CNN的方法有時會產生低特徵提取,查詢過慢,需要訓練的數據過大等缺點。而CALC是一種輕量級地實時快速深度學習架構,它只需要很少的參數,可以用於SLAM迴環檢測或任何其他場所識別任務,即使對於資源有限地系統也可以很好地運行。
這個模型將高維的原始數據映射到有旋轉不變性的低維的描述子空間。在訓練之前,圖片序列中的每一個圖片進行隨機投影變換,重新縮放成120×160產生影像對,為了捕捉運動過程中的視角的極端變化。然後隨機選擇一些圖片計算HOG運算元,採用固定長度的HOG描述子可以幫助網路更好地學習場景的幾何。將訓練圖片的每一個塊的HOG存儲到堆棧里,定義為(X_{2})維度為(N times D),其中(N)是塊大小,(D)是每一個HOG運算元的維度。網路有兩個帶池化層的卷積層,一個純卷積層,和三個全連接層,同時用ReLU做卷積層的激活單元。在該體系結構中,將圖片進行投影變換,提取HOG描述子的操作僅針對整個訓練數據集計算一次,然後將結果寫入資料庫以用於訓練。在訓練時,批量大小N設置為1,並且僅使用boxed區域中的層。
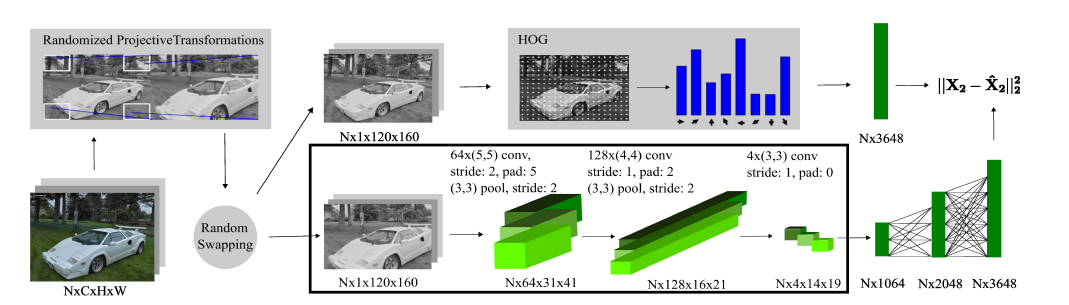
相關文獻
[1] N. Merrill and G. Huang, 「Lightweight Unsupervised Deep Loop Closure,」 in Robotics: Science and Systems XIV, 2018.
程式碼
CALC
原理介紹:用於迴環檢測的卷積自動編碼器。它該程式碼分為兩個模組。TrainAndTest用於訓練和測試模型,DeepLCD是一個用於在線迴環檢測或影像檢索的C ++庫。
源碼地址:https://github.com/rpng/calc
關注公眾號,點擊「學習圈子」,「SLAM入門「」,從零開始學習三維視覺核心技術SLAM,3天內無條件退款。早就是優勢,學習切忌單打獨鬥,這裡有教程資料、練習作業、答疑解惑等,優質學習圈幫你少走彎路,快速入門!

推薦閱讀
如何從零開始系統化學習視覺SLAM?
從零開始一起學習SLAM | 為什麼要學SLAM?
從零開始一起學習SLAM | 學習SLAM到底需要學什麼?
從零開始一起學習SLAM | SLAM有什麼用?
從零開始一起學習SLAM | C++新特性要不要學?
從零開始一起學習SLAM | 為什麼要用齊次坐標?
從零開始一起學習SLAM | 三維空間剛體的旋轉
從零開始一起學習SLAM | 為啥需要李群與李代數?
從零開始一起學習SLAM | 相機成像模型
從零開始一起學習SLAM | 不推公式,如何真正理解對極約束?
從零開始一起學習SLAM | 神奇的單應矩陣
從零開始一起學習SLAM | 你好,點雲
從零開始一起學習SLAM | 給點雲加個濾網
從零開始一起學習SLAM | 點雲平滑法線估計
從零開始一起學習SLAM | 點雲到網格的進化
從零開始一起學習SLAM | 理解圖優化,一步步帶你看懂g2o程式碼
從零開始一起學習SLAM | 掌握g2o頂點編程套路
從零開始一起學習SLAM | 掌握g2o邊的程式碼套路
從零開始一起學習SLAM | 用四元數插值來對齊IMU和影像幀
零基礎小白,如何入門電腦視覺?
SLAM領域牛人、牛實驗室、牛研究成果梳理
我用MATLAB擼了一個2D LiDAR SLAM
可視化理解四元數,願你不再掉頭髮
最近一年語義SLAM有哪些代表性工作?
視覺SLAM技術綜述
匯總 | VIO、雷射SLAM相關論文分類集錦
研究SLAM,對編程的要求有多高?
2018年SLAM、三維視覺方向求職經驗分享
2018年SLAM、三維視覺方向求職經驗分享
深度學習遇到SLAM | 如何評價基於深度學習的DeepVO,VINet,VidLoc?
AI資源對接需求匯總:第1期
AI資源對接需求匯總:第2期
