從零到千萬用戶,我是如何一步步優化MySQL資料庫的?
寫在前面
很多小夥伴留言說讓我寫一些工作過程中的真實案例,寫些啥呢?想來想去,寫一篇我在以前公司從零開始到用戶超千萬的資料庫架構升級演變的過程吧。
本文記錄了我之前初到一家創業公司,從零開始到用戶超千萬,系統壓力暴增的情況下是如何一步步優化MySQL資料庫的,以及資料庫架構升級的演變過程。升級的過程極具技術挑戰性,也從中收穫不少。希望能夠為小夥伴們帶來實質性的幫助。
業務背景
我之前呆過一家創業工作,是做商城業務的,商城這種業務,表面上看起來涉及的業務簡單,包括:用戶、商品、庫存、訂單、購物車、支付、物流等業務。但是,細分下來,還是比較複雜的。這其中往往會牽扯到很多提升用戶體驗的潛在需求。例如:為用戶推薦商品,這就涉及到用戶的行為分析和大數據的精準推薦。如果說具體的技術的話,那肯定就包含了:用戶行為日誌埋點、採集、上報,大數據實時統計分析,用戶畫像,商品推薦等大數據技術。
公司的業務增長迅速,僅僅2年半不到的時間用戶就從零積累到千萬級別,每天的訪問量幾億次,高峰QPS高達上萬次每秒。數據的寫壓力來源於用戶下單,支付等操作,尤其是趕上雙十一大促期間,系統的寫壓力會成倍增長。然而,讀業務的壓力會遠遠大於寫壓力,據不完全統計,讀業務的請求量是寫業務的請求量的50倍左右。
接下來,我們就一起來看看資料庫是如何升級的。
最初的技術選型
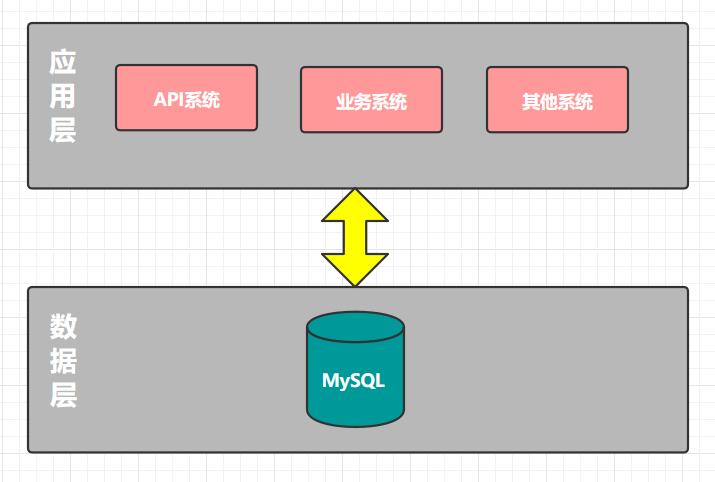
作為創業公司,最重要的一點是敏捷,快速實現產品,對外提供服務,於是我們選擇了公有雲服務,保證快速實施和可擴展性,節省了自建機房等時間。整體後台採用的是Java語言進行開發,資料庫使用的MySQL。整體如下圖所示。
讀寫分離
隨著業務的發展,訪問量的極速增長,上述的方案很快不能滿足性能需求。每次請求的響應時間越來越長,比如用戶在H5頁面上不斷刷新商品,響應時間從最初的500毫秒增加到了2秒以上。業務高峰期,系統甚至出現過宕機。在這生死存亡的關鍵時刻,通過監控,我們發現高期峰MySQL CPU使用率已接近80%,磁碟IO使用率接近90%,slow query(慢查詢)從每天1百條上升到1萬條,而且一天比一天嚴重。資料庫儼然已成為瓶頸,我們必須得快速做架構升級。
當Web應用服務出現性能瓶頸的時候,由於服務本身無狀態,我們可以通過加機器的水平擴展方式來解決。 而資料庫顯然無法通過簡單的添加機器來實現擴展,因此我們採取了MySQL主從同步和應用服務端讀寫分離的方案。
MySQL支援主從同步,實時將主庫的數據增量複製到從庫,而且一個主庫可以連接多個從庫同步。利用此特性,我們在應用服務端對每次請求做讀寫判斷,若是寫請求,則把這次請求內的所有DB操作發向主庫;若是讀請求,則把這次請求內的所有DB操作發向從庫,如下圖所示。
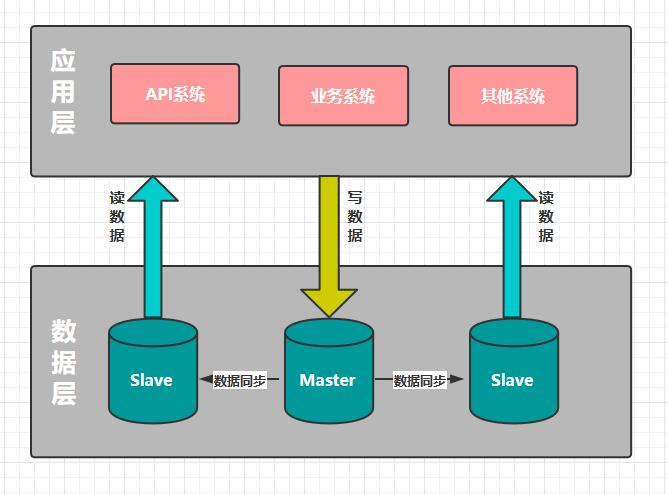
實現讀寫分離後,資料庫的壓力減少了許多,CPU使用率和IO使用率都降到了5%以內,Slow Query(慢查詢)也趨近於0。主從同步、讀寫分離給我們主要帶來如下兩個好處:
-
減輕了主庫(寫)壓力:商城業務主要來源於讀操作,做讀寫分離後,讀壓力轉移到了從庫,主庫的壓力減小了數十倍。
-
從庫(讀)可水平擴展(加從庫機器):因系統壓力主要是讀請求,而從庫又可水平擴展,當從庫壓力太時,可直接添加從庫機器,緩解讀請求壓力。
當然,沒有一個方案是萬能的。讀寫分離,暫時解決了MySQL壓力問題,同時也帶來了新的挑戰。業務高峰期,用戶提交完訂單,在我的訂單列表中卻看不到自己提交的訂單資訊(典型的read after write問題);系統內部偶爾也會出現一些查詢不到數據的異常。通過監控,我們發現,業務高峰期MySQL可能會出現主從複製延遲,極端情況,主從延遲高達數秒。這極大的影響了用戶體驗。
那如何監控主從同步狀態?在從庫機器上,執行show slave status,查看Seconds_Behind_Master值,代表主從同步從庫落後主庫的時間,單位為秒,若主從同步無延遲,這個值為0。MySQL主從延遲一個重要的原因之一是主從複製是單執行緒串列執行(高版本MySQL支援並行複製)。
那如何避免或解決主從延遲?我們做了如下一些優化:
- 優化MySQL參數,比如增大innodb_buffer_pool_size,讓更多操作在MySQL記憶體中完成,減少磁碟操作。
- 使用高性能CPU主機。
- 資料庫使用物理主機,避免使用虛擬雲主機,提升IO性能。
- 使用SSD磁碟,提升IO性能。SSD的隨機IO性能約是SATA硬碟的10倍甚至更高。
- 業務程式碼優化,將實時性要求高的某些操作,強制使用主庫做讀操作。
- 升級高版本MySQL,支援並行主從複製。
垂直分庫
讀寫分離很好的解決了讀壓力問題,每次讀壓力增加,可以通過加從庫的方式水平擴展。但是寫操作的壓力隨著業務爆髮式的增長沒有得到有效的緩解,比如用戶提交訂單越來越慢。通過監控MySQL資料庫,我們發現,資料庫寫操作越來越慢,一次普通的insert操作,甚至可能會執行1秒以上。
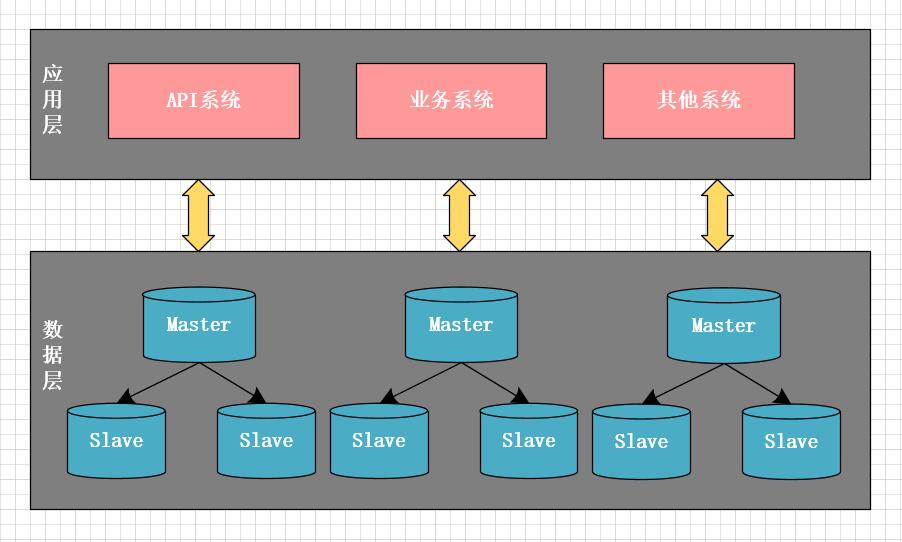
另一方面,業務越來越複雜,多個應用系統使用同一個資料庫,其中一個很小的非核心功能出現延遲,常常影響主庫上的其它核心業務功能。這時,主庫成為了性能瓶頸,我們意識到,必需得再一次做架構升級,將主庫做拆分,一方面以提升性能,另一方面減少系統間的相互影響,以提升系統穩定性。這一次,我們將系統按業務進行了垂直拆分。如下圖所示,將最初龐大的資料庫按業務拆分成不同的業務資料庫,每個系統僅訪問對應業務的資料庫,盡量避免或減少跨庫訪問。
垂直分庫過程,我們也遇到不少挑戰,最大的挑戰是:不能跨庫join,同時需要對現有程式碼重構。單庫時,可以簡單的使用join關聯表查詢;拆庫後,拆分後的資料庫在不同的實例上,就不能跨庫使用join了。
例如,通過商家名查詢某個商家的所有訂單,在垂直分庫前,可以join商家和訂單表做查詢,也可以直接使用子查詢,如下如示:
select * from tb_order where supplier_id in (select id from supplier where name=』商家名稱』);
分庫後,則要重構程式碼,先通過商家名查詢商家id,再通過商家id查詢訂單表,如下所示:
select id from supplier where name=』商家名稱』
select * from tb_order where supplier_id in (supplier_ids )
垂直分庫過程中的經驗教訓,使我們制定了SQL最佳實踐,其中一條便是程式中禁用或少用join,而應該在程式中組裝數據,讓SQL更簡單。一方面為以後進一步垂直拆分業務做準備,另一方面也避免了MySQL中join的性能低下的問題。
經過近十天加班加點的底層架構調整,以及業務程式碼重構,終於完成了資料庫的垂直拆分。拆分之後,每個應用程式只訪問對應的資料庫,一方面將單點資料庫拆分成了多個,分攤了主庫寫壓力;另一方面,拆分後的資料庫各自獨立,實現了業務隔離,不再互相影響。
水平分庫
讀寫分離,通過從庫水平擴展,解決了讀壓力;垂直分庫通過按業務拆分主庫,快取了寫壓力,但系統依然存在以下隱患:
- 單表數據量越來越大。如訂單表,單表記錄數很快就過億,超出MySQL的極限,影響讀寫性能。
- 核心業務庫的寫壓力越來越大,已不能再進一次垂直拆分,此時的系統架構中,MySQL 主庫不具備水平擴展的能力。
此時,我們需要對MySQL進一步進行水平拆分。
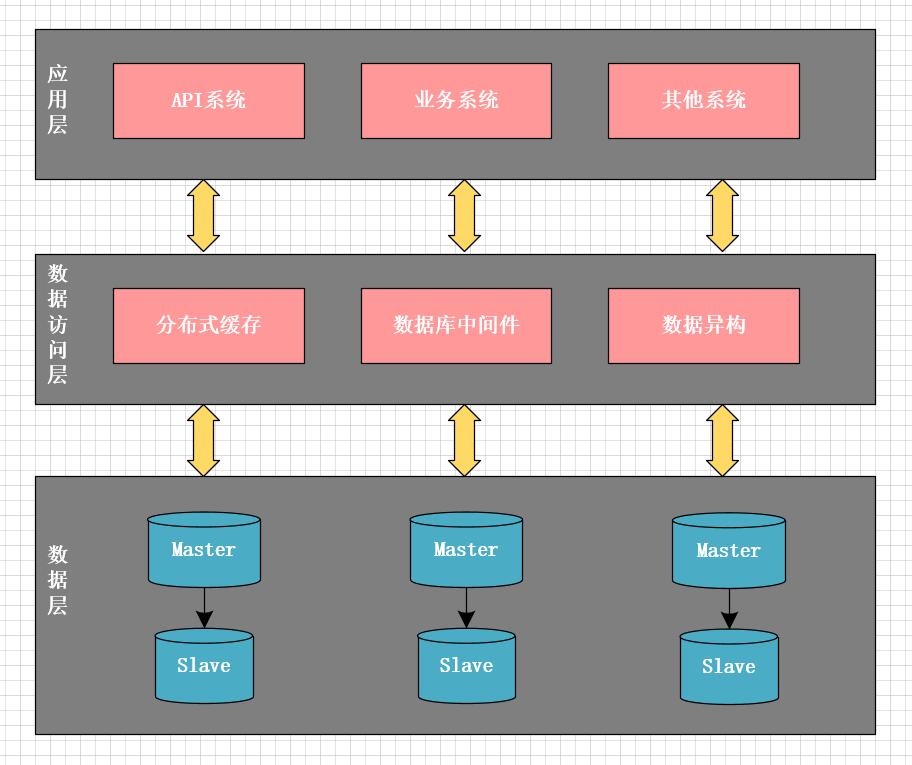
水平分庫面臨的第一個問題是,按什麼邏輯進行拆分。一種方案是按城市拆分,一個城市的所有數據在一個資料庫中;另一種方案是按訂單ID平均拆分數據。按城市拆分的優點是數據聚合度比較高,做聚合查詢比較簡單,實現也相對簡單,缺點是數據分布不均勻,某些城市的數據量極大,產生熱點,而這些熱點以後可能還要被迫再次拆分。按訂單ID拆分則正相反,優點是數據分布均勻,不會出現一個資料庫數據極大或極小的情況,缺點是數據太分散,不利於做聚合查詢。比如,按訂單ID拆分後,一個商家的訂單可能分布在不同的資料庫中,查詢一個商家的所有訂單,可能需要查詢多個資料庫。針對這種情況,一種解決方案是將需要聚合查詢的數據做冗餘表,冗餘的表不做拆分,同時在業務開發過程中,減少聚合查詢。
經過反覆思考,我們最後決定按訂單ID做水平分庫。從架構上,將系統分為三層:
- 應用層:即各類業務應用系統
- 數據訪問層:統一的數據訪問介面,對上層應用層屏蔽讀寫分庫、分表、快取等技術細節。
- 數據層:對DB數據進行分片,並可動態的添加shard分片。
水平分庫的技術關鍵點在於數據訪問層的設計,數據訪問層主要包含三部分:
- 分散式快取
- 資料庫中間件
- 數據異構中間件
而資料庫中間件需要包含如下重要的功能:
- ID生成器:生成每張表的主鍵
- 數據源路由:將每次DB操作路由到不同的分片數據源上
ID生成器
ID生成器是整個水平分庫的核心,它決定了如何拆分數據,以及查詢存儲-檢索數據。ID需要跨庫全局唯一,否則會引發業務層的衝突。此外,ID必須是數字且升序,這主要是考慮到升序的ID能保證MySQL的性能(若是UUID等隨機字元串,在高並發和大數據量情況下,性能極差)。同時,ID生成器必須非常穩定,因為任何故障都會影響所有的資料庫操作。
我們系統中ID生成器的設計如下所示。

- 整個ID的二進位長度為64位
- 前36位使用時間戳,以保證ID是升序增加
- 中間13位是分庫標識,用來標識當前這個ID對應的記錄在哪個資料庫中
- 後15位為自增序列,以保證在同一秒內並發時,ID不會重複。每個分片庫都有一個自增序列表,生成自增序列時,從自增序列表中獲取當前自增序列值,並加1,做為當前ID的後15位
- 下一秒時,後15位的自增序列再次從1開始。
水平分庫是一個極具挑戰的項目,我們整個團隊也在不斷的迎接挑戰中快速成長。
為了適應公司業務的不斷發展,除了在MySQL資料庫上進行相應的架構升級外,我們還搭建了一套完整的大數據實時分析統計平台,在系統中對用戶的行為進行實時分析。
關於如何搭建大數據實時分析統計平台,對用戶的行為進行實時分析,我們後面再詳細介紹。
好了,今天就到這兒吧,我是冰河,我們下期見!!
重磅福利
微信搜一搜【冰河技術】微信公眾號,關注這個有深度的程式設計師,每天閱讀超硬核技術乾貨,公眾號內回復【PDF】有我準備的一線大廠面試資料和我原創的超硬核PDF技術文檔,以及我為大家精心準備的多套簡歷模板(不斷更新中),希望大家都能找到心儀的工作,學習是一條時而鬱鬱寡歡,時而開懷大笑的路,加油。如果你通過努力成功進入到了心儀的公司,一定不要懈怠放鬆,職場成長和新技術學習一樣,不進則退。如果有幸我們江湖再見!
另外,我開源的各個PDF,後續我都會持續更新和維護,感謝大家長期以來對冰河的支援!!


