Efficient Estimation of Word Representations in Vector Space 論文筆記
Mikolov T , Chen K , Corrado G , et al. Efficient Estimation of Word Representations in Vector Space[J]. Computer ence, 2013.
源碼://github.com/danielfrg/word2vec
文章目的
本文的目的是提出學習高品質的詞向量(word2vec)的方法,這些方法主要利用在十億或者百萬辭彙的數據集上。因此作者提出了兩個新穎的模型(CBOW,Skip-gram)來計算連續向量表示,表示的品質用詞的相似度來衡量,將結果與之前表現最好的神經網路網路模型進行比較。
作者試圖用新的模型結構來最大化向量操作,並且保留單詞之間的線性規律。同時討論了訓練時間和準確率如何依賴於單詞向量的維度及訓練數據量。
結論
- 新的模型降低了計算複雜度,提高了準確率(從160億單詞的數據集中學習高品質的單詞向量)
- 這些向量在測試集上為度量語法和語義提供了最先進的性能。
背景
一些NLP系統和任務把詞作為原子單元,詞與詞之間沒有相似度,是作為詞典的下標表示的,這種方法有幾個好處:簡單,魯棒,在大數據集上訓練的簡單模型比小數據集上訓練的複雜模型好。最廣為流傳的是用於統計語言模型的N元模型,今天,它可以訓練幾乎所有數據的n元模型。
這些簡單的技術在很多任務上有限制。因此簡單的改進這些基本的技術並不能帶來顯著的效果提升,必須關注更先進的技術。
Model Architectures
之前許多研究人員提出了許多不同類型的模型,例如LSA和LDA。在本文中,作者主要研究了神經網路學習的單詞分散式表示。
為了比較不同模型的計算複雜度,提出了如下的模型訓練複雜度:
\]
- E:訓練迭代次數
- T:訓練集中的單詞數量
- Q:Q被每一個模型進一步定義,具體如下。
Feedforward Neural Net Language Model(NNLM)
結構:
- Input Layer:使用one-hot編碼的N個之前的單詞,V是辭彙表的大小
- Projection Layer:維度是\(N×D\),使用了一個共享的投影矩陣
- Hidden Layer:H表示隱藏層節點的個數
- Output Layer:V表示輸出節點的個數
每個樣本的計算複雜度公式如下所示:
\]
- \(N×D\):輸入層到投影的權重個數,N是上下文的長度,D是每個詞的實數表示維度
- \(N×D×H\):投影層到隱藏層的權重個數
- \(H×V\):隱含層到輸出層的權重個數
原本最重要的一項是\(H×V\),但是作者提出利用 hierarchical softmax 或者避免使用規則化模型來處理它。其中利用Huffman binary樹來表示單詞,需要評估的輸出單元的個數下降了\(log_2(V)\)。因此,大多的計算複雜度來源於 \(N×D×H\) 項。
Recurrent Neural Net Language Model (RNNLM)
基於語言模型的循環神經網路主要克服前饋NNLM的缺點,比如需要確定文本的長度。RNN可以表示更複雜的模型。
結構:
- Input Layer:單詞表示D和隱藏層H有相同的維度
- Hidden Layer:H表示隱藏層節點的個數
- Output Layer:V表示輸出節點的個數
這種模型的特點是有循環矩陣連接隱藏層,具有時間延遲連接,這允許形成長短期記憶,過去的資訊可以由隱藏狀態表示,隱藏狀態的更新由當前輸入和前一個輸入的隱藏層的狀態決定
每個樣本的計算複雜度公式如下所示:
\]
- \(H×H\):輸入層到隱藏層的權重個數
- \(H×V\):隱藏層到輸出層的個數
同樣,使用 hierarchical softmax 可以把\(H×V\)項有效地下降為\(H×log_2(V)\)項。因此大多數地複雜度來源於\(H×H\)項。
Parallel Training of Neural Networks
作者在Google的大型分散式框架DistBelief上實現了幾個模型,這個框架允許我們並行地運行同一個模型的不同副本,每個副本通過一個保存所有參數的中央伺服器進行參數更新。對於這種並行訓練,作者使用mini-batch非同步梯度下降和一個叫做Adagrad的自適應的學習率。在這個框架下,通常使用一百或者更多的副本,每一個副本在一個的數據中心的一個機器上的使用多個CPU核心。
提出的模型
作者提出了兩個新的模型(New Log-linear Models)來學習單詞的表示,新模型的優勢主要在於減小了計算複雜度。作者發現大量的計算複雜度主要來源於模型中的非線性隱藏層。
兩個新的模型採用相似的模型結構,都有 Input層、Projection層和Output層。
Continuous Bag-of-Words Model
輸入是某一個特徵詞的上下文相關的詞對應的詞向量,而輸出就是這特定的一個詞的詞向量。
和NNLM相比去掉了非線性隱藏層,並且投射層共享給所有的單詞(不單單是投射矩陣的共享)。因此,所有單詞都會投影到一個D維的向量上(加和平均)。
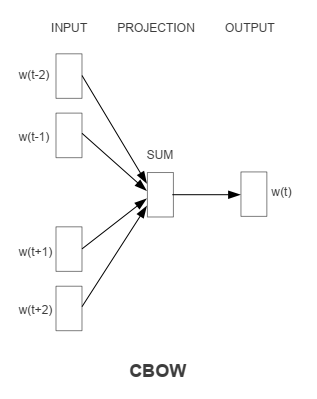
計算複雜度是:
\]
Continuous Skip-gram Model
輸入是特定的一個詞的詞向量,而輸出是特定詞對應的上下文詞向量。
使用當前的單詞作為輸入,輸入到一個投影層,然後會預測當前單詞的上下文。
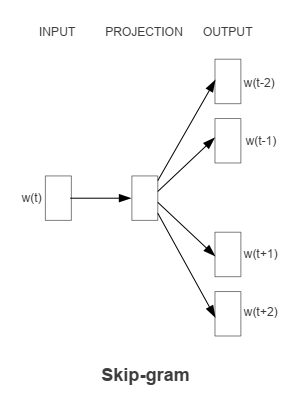
計算複雜度是:
\]
- C:單詞之間的最大距離
Comments
關於這兩個模型的具體分析可以參考這篇論文:Rong X . word2vec Parameter Learning Explained[J]. Computer ence, 2014.


