深度優先搜索和廣度優先搜索
當我們在學習和臨摹垃圾回收(Garbage Collection, 縮寫為 GC)相關演算法和源碼時候, 內在細節離不開
這兩大類搜索演算法支撐. 這就是構建的背景❉, 文章定位是科普掃盲❤.
0. 引述與目錄
[0] 知乎 – 節點 or 結點 ? [走進科學]
[1] 維基百科 – 廣度優先搜索 [概念參照]
[2] 維基百科 – 深度優先搜索 [概念參照]
[3] 維基百科 – 樹的遍歷 [概念參照]
[4] CSDN – 二叉樹的深度優先遍歷與廣度優先遍歷 [盜圖]
[5] 部落格園 – 數據結構之圖的基本概念 [遞歸抄襲]
[6] 部落格園 – 圖的遍歷之 深度優先搜索和廣度優先搜索 [深度抄襲]
[7] github – 深度搜索和廣度搜索 [演示素材]
目錄
1. 概念介紹
2. 樹的例子
2.1 前序遍歷
2.2 中序遍歷
2.3 後序遍歷
2.4 層次遍歷
2.5 搜索演算法源碼
3. 圖的例子
3.0 圖的基本概念
3.0.1 圖的定義
3.0.2 圖的基本概念
3.0.3 圖最基礎的兩類存儲結構
3.0.3.1 鄰接矩陣表示法
3.0.3.2 鄰接表表示法
3.1 深度優先搜索圖文介紹
3.1.1 深度優先搜索介紹
3.1.2 深度優先搜索圖解
3.1.2.1 無向圖的深度優先搜索
3.1.2.2 有向圖的深度優先搜索
3.2 廣度優先搜索圖文介紹
3.2.1 廣度優先搜索介紹
3.2.2 廣度優先搜索圖解
3.2.2.1 無向圖的廣度優先搜索
3.2.2.2 有向圖的廣度優先搜索
3.3 搜索演算法源碼
3.3.1 鄰接矩陣圖表示的無向圖 (Matrix Undirected Graph)
3.3.2 鄰接矩陣圖表示的有向圖 (Matrix Directed Graph)
3.3.3 鄰接鏈表圖表示的無向圖 (List Undirected Graph)
3.3.4 鄰接鏈表圖表示的有向圖 (List Directed Graph)
1. 概念介紹
關於遍歷演算法種類有很多很多, 這裡選了最通用, 深度優先遍歷和廣度優先遍歷兩類搜索演算法進行淺顯
講解(作者能力有限). 基礎有時候很有趣, 真的! ok, 那我們 go on.
深度優先搜索演算法(Depth-First-Search, 縮寫為 DFS), 是一種用於遍歷或搜索樹或圖的演算法. 這個演算法
會儘可能深的搜索樹的分支. 當結點 v 的所在邊都己被探尋過, 搜索將回溯到發現結點 v 的那條邊的起始結
點. 這一過程一直進行到已發現從源結點可達的所有結點為止. 如果還存在未被發現的結點, 則選擇其中一
個作為源結點並重複以上過程, 整個進程反覆進行直到所有結點都被訪問為止.
廣度優先搜索演算法(Breadth-First Search, 縮寫為 BFS), 又譯作寬度優先搜索, 或橫向優先搜索, 是一種
圖形搜索演算法. 簡單的說, BFS 是從根結點開始, 沿著樹的寬度遍歷樹的結點. 如果所有結點均被訪問, 則演算法
中止.
在電腦科學裡, 樹的遍歷(也稱為樹的搜索)是圖的遍歷的一種, 指的是按照某種規則, 不重複地訪問某
種樹的所有結點的過程. 具體的訪問操作可能是檢查結點的值, 更新結點的值等. 不同的遍歷方式, 其訪問結
點的順序是不一樣的. 以下我們將二叉樹的廣度優先和深度優先遍歷演算法歸類,但它們也適用於其它樹形結
構.
深度優先遍歷(搜索)
前序遍歷(Pre-Order Traversal)

深度優先搜索 – 前序遍歷: F -> B -> A -> D -> C -> E -> G -> I ->H
中序遍歷(In-Order Traversal)

深度優先搜索 – 中序遍歷: A -> B -> C -> D -> E -> F -> G -> H -> I
後序遍歷(Post-Order Traversal)

深度優先搜索 – 後序遍歷: A -> C -> E -> D -> B -> H -> I -> G -> F
廣度優先遍歷(搜索)
層次遍歷(Level Order Traversal)

廣度優先搜索 – 層次遍歷:F -> B -> G -> A -> D -> I -> C -> E -> H
種樹的所有結點的過程. 具體的訪問操作可能是檢查結點的值, 更新結點的值等. 不同的遍歷方式, 其訪問結
通過閱讀和思考以上維基百科中提供的摘錄, 我們大致對兩類遍歷演算法有了點直觀的認知. 不知道有沒
有人有這樣的疑惑, 為什麼寬度優先搜索叫法沒有廣度優先搜索這個叫法流傳廣, 明明在樹結構中要好理解
多了呢? 乍看確實這樣, 但不要忘了樹結構是一種特殊圖結構, 而複雜圖結構可能沒有直觀從上到下, 從左到
右這種直觀的觀感了. 因而寬度優先搜索名詞在一般化中顯得不夠準確了. 哈哈哈. 另外一個認知是關於必要
條件的. 例如深度和廣度優先搜索包含很多不同遍歷相關相關演算法, 不僅僅只有文章中介紹那幾個, 這點大家
要充分認識.
2. 樹的例子

觀察圖片, 提示中可以發現前中後序遍歷定義是圍繞根結點訪問時機定義的(還存在潛規則, 默認先左子
樹後右子樹). 下面我們通過具體的程式碼來表達遍歷思路. 首先我們構造樹結構
/** * 方便測試和描述演算法, 用 int node 構建 */ typedef int node_t; static void node_printf(node_t value) { printf(" %2d", value); } struct tree { struct tree * left; struct tree * right; node_t node; }; static inline struct tree * tree_new(node_t value) { struct tree * node = malloc(sizeof (struct tree)); node->left = node->right = NULL; node->node = value; return node; } static void tree_delete_partial(struct tree * node) { if (node->left) tree_delete_partial(node->left); if (node->right) tree_delete_partial(node->right); free(node); } void tree_delete(struct tree * root) { if (root) tree_delete_partial(root); }
2.1 前序遍歷
static void tree_preorder_partial(struct stack * s) { struct tree * top; // 2.1 訪問棧頂結點, 並將其出棧 while ((top = stack_pop_top(s))) { // 2.2 做業務處理 node_printf(top->node); // 3. 如果根結點存在右孩子, 則將右孩子入棧 if (top->right) stack_push(s, top->right); // 4. 如果根結點存在左孩子, 則將左孩子入棧 if (top->left) stack_push(s, top->left); } } /* * 前序遍歷: * 根結點 -> 左子樹 -> 右子樹 * * 遍歷演算法: * 1. 先將根結點入棧 2. 訪問棧頂結點, 做業務處理, 並將其出棧 3. 如果根結點存在右孩子, 則將右孩子入棧 4. 如果根結點存在左孩子, 則將左孩子入棧 重複 2 - 4 直到棧空 */ void tree_preorder(struct tree * root) { if (!root) return; struct stack s[1]; stack_init(s); // 1. 先將根結點入棧 stack_push(s, root); // 重複 2 - 4 直到棧空 tree_preorder_partial(s); stack_free(s); }
2.2 中序遍歷
/* * 中序遍歷: * 左子樹 -> 根結點 -> 右子樹 * * 遍歷演算法: * 1. 先將根結點入棧 2. 將當前結點的所有左孩子入棧, 直到左孩子為空 3. 彈出並訪問棧頂元素, 做業務處理. 4. 如果棧頂元素存在右孩子, 重複第 2 - 3步, 直到棧空並且不存在待訪問結點 */ void tree_inorder(struct tree * root) { if (!root) return; struct stack s[1]; stack_init(s); tree_inorder_partial(root, s); stack_free(s); } static void tree_postorder_partial(struct stack * s) { struct tree * top; // 記錄前一次出棧結點 struct tree * last = NULL; // 重複 1-2 直到棧空 while ((top = stack_top(s))) { // 2.2 如果我們發現它左右子結點都為空, 則可以做業務處理; // 2.3 或者,如果發現前一個出棧的結點是它的左結點或者右子結點,則可以做業務處理; if ((!top->left && !top->right) || (last && (last == top->left || last == top->right))) { // 做業務處理 node_printf(top->node); // 出棧 stack_pop(s); // 記錄此次出棧結點 last = top; } else { // 2.4. 否則,表示這個結點是一個新的結點,需要嘗試將其右左子結點依次入棧. if (top->right) stack_push(s, top->right); if (top->left) stack_push(s, top->left); } } }
2.3 後序遍歷
static void tree_postorder_partial(struct stack * s) { struct tree * top; // 記錄前一次出棧結點 struct tree * last = NULL; // 重複 1-2 直到棧空 while ((top = stack_top(s))) { // 2.2 如果我們發現它左右子結點都為空, 則可以做業務處理; // 2.3 或者,如果發現前一個出棧的結點是它的左結點或者右子結點,則可以做業務處理; if ((!top->left && !top->right) || (last && (last == top->left || last == top->right))) { // 做業務處理 node_printf(top->node); // 出棧 stack_pop(s); // 記錄此次出棧結點 last = top; } else { // 2.4. 否則,表示這個結點是一個新的結點,需要嘗試將其右左子結點依次入棧. if (top->right) stack_push(s, top->right); if (top->left) stack_push(s, top->left); } } } /* * 後序遍歷: * 左子樹 -> 右子樹 -> 根結點 * * 遍歷演算法: * 1. 拿到一個結點, 先將其入棧, 則它一定在比較靠棧底的地方, 比較晚出棧 2. 在出棧時候判斷到底是只有左結點還是只有右結點或者是兩者都有或者是都沒有. 如果我們發現它左右子結點都為空, 則可以做業務處理; 或者,如果發現前一個出棧的結點是它的左結點或者右子結點,則可以做業務處理; 否則,表示這個結點是一個新的結點,需要嘗試將其右左子結點依次入棧. 重複 1-2 直到棧空 */ void tree_postorder(struct tree * root) { if (!root) return; struct stack s[1]; stack_init(s); // 1. 先將根結點入棧 stack_push(s, root); // 重複 1 - 4 直到棧空 tree_postorder_partial(s); stack_free(s); }
思考上面深度優先搜索三種方式, 大致會感覺佔用棧空間多少映象是 前序遍歷 < 中序遍歷 < 後序遍歷 (存在特
例). 可能, 這也是前序遍歷是樹深度優先搜索演算法中流傳最廣的原因. 對於樹的後序遍歷程式碼實現, 版本也有好
幾個. 有的很容易手寫, 很花哨偷巧, 這裡推薦的是正規工程版本.
2.4 層次遍歷
/* * 層次遍歷: * 根結點 -> 下一層 | 左結點 -> 右結點 * * 遍歷演算法: * 1. 對於不為空的結點, 先把該結點加入到隊列中 * 2. 從隊中彈出結點, 並做業務處理, 嘗試將左結點右結點依次壓入隊列中 * 重複 1 - 2 指導隊列為空 */ void tree_level(struct tree * root) { if (!root) return; q_t q; q_init(q); // 1. 對於不為空的結點, 先把該結點加入到隊列中 q_push(q, root); do { // 2.1 從隊中彈出結點, 並做業務處理 struct tree * node = q_pop(q); node_printf(node->node); // 2.2 嘗試將左結點右結點依次壓入隊列中 if (node->left) q_push(q, node->left); if (node->right) q_push(q, node->right); // 重複 1 - 2 指導隊列為空 } while (q_exist(q)); q_free(q); }
2.5 搜索演算法源碼
3. 圖的例子
本章會先對圖的深度優先搜索和廣度優先搜索進行簡單介紹, 然後再給出 C 的源碼實現.
3.0 圖的基本概念
3.0.1 圖的定義
定義: 圖(Graph)是由頂點的有窮非空集合和頂點之間邊的集合組成, 通常表示為: G(V, E), 其中, G 表示一個圖,
V 是 圖 G 中頂點的集合, E 是 圖 G 中邊的集合.
在圖中需要注意的是:
(1) 線性表中我們把數據元素叫元素, 樹中將數據元素叫結點, 在圖中數據元素, 我們則稱之為頂點(Vertex).
(2) 線性表可以沒有元素, 稱為空表; 樹中可以沒有結點, 稱為空樹; 但是, 在圖中不允許沒有頂點(有窮非空性).
(3) 線性表中的各元素是線性關係, 樹中的各元素是層次關係, 而, 圖中各頂點的關係是用邊來表示(邊集可以為
空).
3.0.2 圖的基本概念
(1) 無向圖

如果圖中任意兩個頂點之間的邊都是無向邊(簡而言之就是沒有方向的邊), 則稱該圖為無向圖(Undirected
graphs).
(2) 有向圖

如果圖中任意兩個頂點之間的邊都是有向邊(簡而言之就是有方向的邊), 則稱該圖為有向圖(Directed graphs).
(3) 完全圖
① 無向完全圖: 在無向圖中, 如果任意兩個頂點之間都存在邊, 則稱該圖為無向完全圖. (含有 n 個頂點的無向完
全圖有 (n×(n-1))/2 條邊) 如下圖所示:

② 有向完全圖: 在有向圖中, 如果任意兩個頂點之間都存在方向互為相反的兩條弧, 則稱該圖為有向完全圖. (含
有 n 個頂點的有向完全圖有 n×(n-1) 條邊) 如下圖所示:

PS: 當一個圖接近完全圖時, 則稱它為稠密圖(Dense Graph), 而當一個圖含有較少的邊時, 則稱它為稀疏圖(
Spare Graph).
(4) 頂點的度
頂點 V 的度(Degree) 是指在圖中與 V 相關聯的邊的條數. 對於有向圖來說, 有入度(In-degree)和出度
(Out-degree) 之分, 有向圖頂點的度等於該頂點的入度和出度之和.
(5) 鄰接
① 若無向圖中的兩個頂點 V 和 W 存在一條邊(V, W), 則稱頂點 V 和 W 鄰接(Adjacent);
② 若有向圖中存在一條邊<V, W>,則稱 頂點 V 鄰接到 頂點 W ,活 頂點 W 鄰接自 頂點 V;
以 (2) 有向圖 舉例, 有 <A, D> <B, A> <B, C> <C, A> 鄰接關係.
(6) 弧頭和弧尾
有向圖中, 無箭頭一端的頂點通常被稱為”初始點”或”弧尾“, 箭頭直線的頂點被稱為”終端點”或”弧頭“. <A, D>
鄰接關係中, 頂點 A 就是弧尾, 頂點 D 就是弧頭.
PS: 無向圖中的邊使用小括弧”()”表示, 而有向圖中的邊使用尖括弧”<>” 表示.
(7) 路徑
在無向圖中, 若從頂點 V 出發有一組邊可到達頂點 W, 則稱頂點 V 到頂點 W 的頂點序列, 為從頂點 V 到頂點 W的
路徑(Path).
(8) 連通
若從 V 到 W 有路徑可通, 則稱頂點 V 和頂點 W 是連通(Connected)的.
(9) 權

有些圖的邊或弧具有與它相關的數字, 這種與圖的邊或弧相關的數叫做權(Weight).
有些圖的邊或弧具有與它相關的數字, 這種與圖的邊或弧相關的數叫做權(Weight).
3.0.3 圖最基礎的兩類存儲結構
圖的存儲結構除了要存儲圖中的各個頂點本身的資訊之外, 還要存儲頂點與頂點之間的關係, 因此, 圖的結
構也比較複雜. 常用最基礎的兩類圖的存儲結構有鄰接矩陣和鄰接表.
3.0.3.1 鄰接矩陣表示法
圖的鄰接矩陣(Adjacency Matrix)存儲方式是用兩個數組來表示圖. 一個一維數組存儲圖中頂點資訊, 一個
二維數組(稱為鄰接矩陣)存儲圖中的邊或弧的資訊.
(1) 無向圖
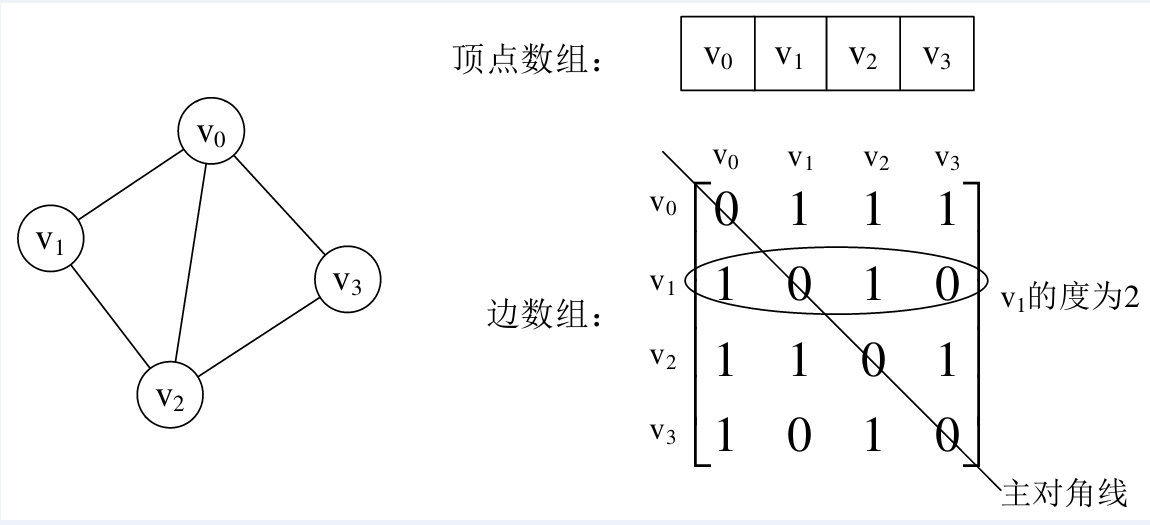
我們可以設置兩個數組, 頂點數組為 vertex[4] = {V0, V1, V2, V3}, 邊數組 edges[4][4] 為上圖右邊這樣的一個矩
陣. 對於矩陣的主對角線的值, 即 edges[0][0], edges[1][1], edges[2][2], edges[3][3], 全為 0, 因為不存在頂點
自己到自己的邊.
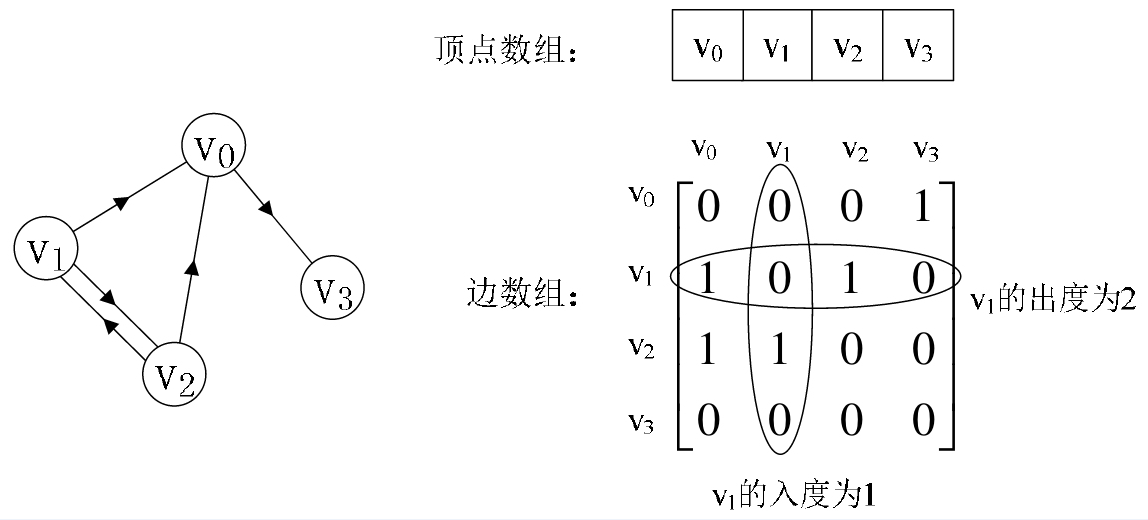
(2) 有向圖
我們再來看一個有向圖樣例, 如下圖所示的左邊. 頂點數組為 vertex[4] = {V0, V1, V2, V3}, 弧數組 edges[4][4]
為下圖右邊這樣的一個矩陣. 主對角線上數值依然為 0. 但因為是有向圖, 所以此矩陣並不對稱, 比如由 V1 到 V0
有弧, 得到 edges[1][0] = 1, 而 V0 到 V1 沒有弧, 因此 edges[0][1] = 0.
不足: 由於存在 n 個頂點的圖需要 n*n 個數組元素進行存儲, 當圖為稀疏圖時, 使用鄰接矩陣存儲方法將會出
現大量 0 元素, 這會造成極大的空間浪費. 這時, 可以考慮使用鄰接表表示法來存儲圖中的數據.
3.0.3.2 鄰接表表示法
首先, 回憶我們烙印在身體里的線性表存儲結構, 順序存儲結構因為存在預先分配記憶體可能造成存儲空間
浪費的問題, 於是想到了鏈式存儲的結構. 同樣的, 我們也可以嘗試對邊或弧使用鏈式存儲的方式來避免空間浪
費的問題.
鄰接表由表頭結點和表結點兩部分組成, 圖中每個頂點均對應一個存儲在數組中的表頭結點. 如果這個表
頭結點所對應的頂點存在鄰接結點, 則把鄰接結點依次存放於表頭結點所指向的單向鏈表中.
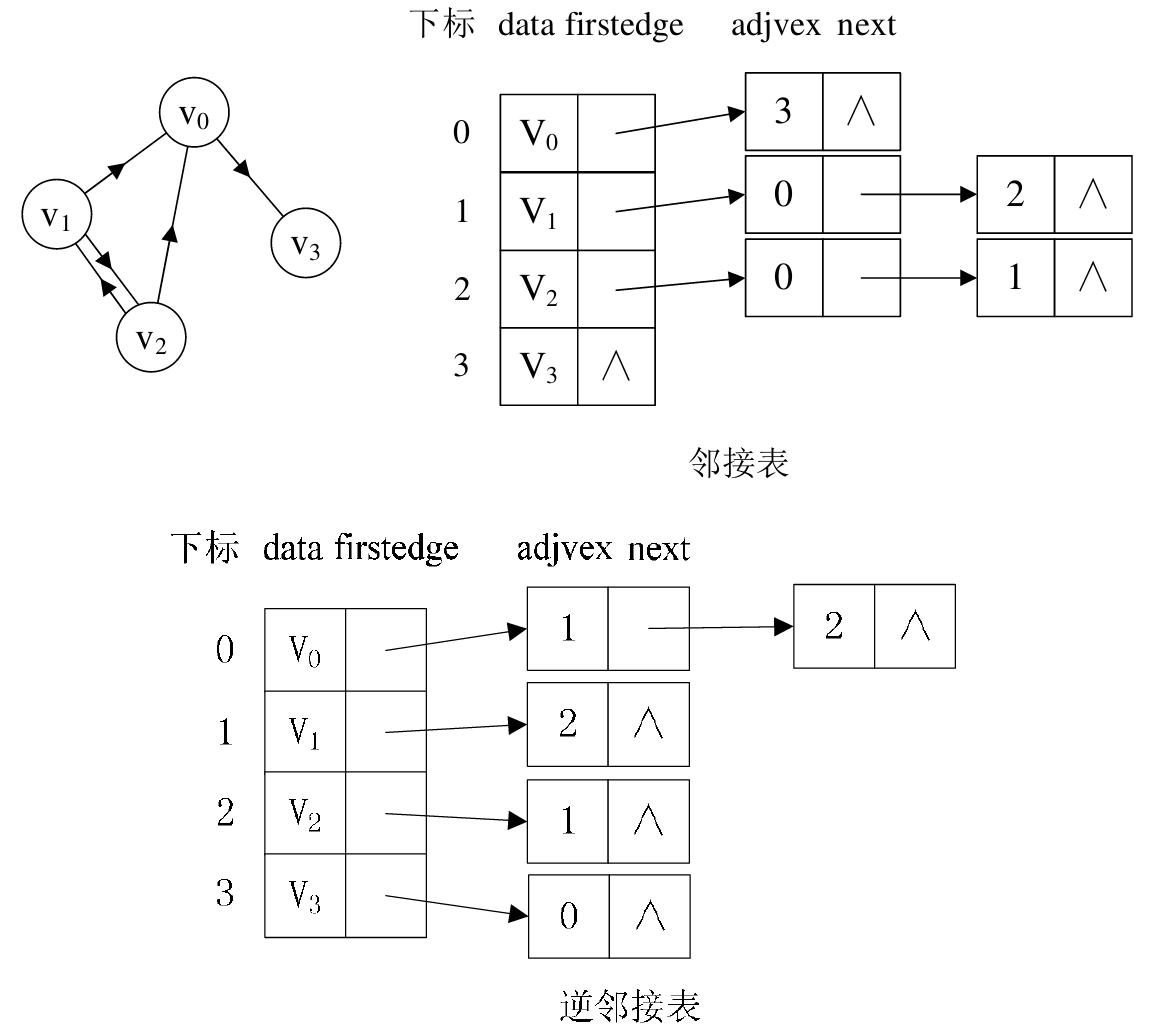
(1) 無向圖: 下圖所示的就是一個無向圖的鄰接表結構.
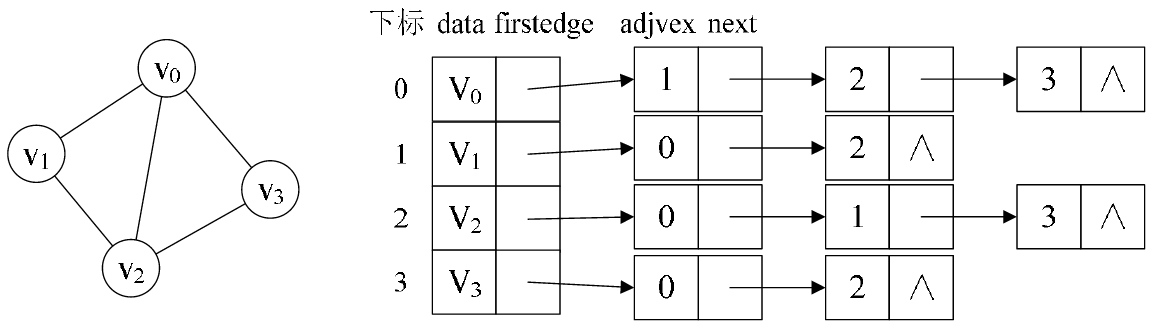
從上圖中我們知道, 頂點表的各個結點由 data 和 firstedge 兩個域表示, data 是數據域, 存儲頂點的資訊,
firstedge 是指針域, 指向邊表的第一個結點, 即此頂點的第一個鄰接點. 邊表結點由 adjvex 和 next 兩個域組成.
adjvex 是鄰接點域, 存儲某頂點的鄰接點在頂點表中的下標, next 則存儲指向邊表中下一個結點的指針. 例如:
V1 頂點與 V0, V2 互為鄰接點, 則在 V1 的邊表中,adjvex 分別為 V0 的 0 和 V2 的 2.
PS: 對於無向圖來說, 使用鄰接表進行存儲也會出現數據冗餘的現象. 例如上圖中, 頂點 V0 所指向的鏈表中存
在一個指向頂點 V3 的同時,頂點 V3 所指向的鏈表中也會存在一個指向 V0 的頂點。
(2) 有向圖: 若是有向圖, 鄰接表結構是類似的,但要注意的是有向圖由於有方向的. 因此, 有向圖的鄰接表分為
出邊表和入邊表(又稱逆鄰接表), 出邊表的表結點存放的是從表頭結點出發的有向邊所指的尾結點; 入邊表的表
結點存放的則是指向表頭結點的某個頂點, 如下圖所示.
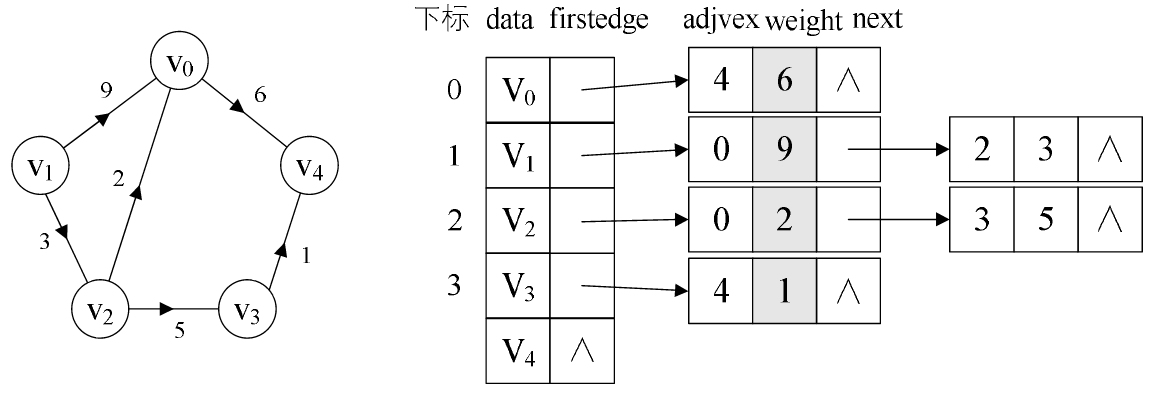
(3) 帶權圖: 對於帶權值的網圖, 可以在邊表結點定義中再增加一個 weight 的數據域, 存儲權值資訊即可, 如下
圖所示.
3.1 深度優先搜索圖文介紹
3.1.1 深度優先搜索介紹
圖的深度優先搜索(Depth First Search),我們再重複重複加深理解. 我們介紹下它的搜索步驟: 假設初始
狀態是圖中所有頂點均未被訪問, 則從某個 頂點(結點) v 出發, 首先訪問該頂點, 然後依次從它的各個未被訪問
的鄰接點出發深度優先搜索遍歷圖, 直至圖中所有和 頂點 v 有路徑相通的頂點都被訪問到. 若此時, 尚有其他頂
點未被訪問到, 則另選一個未被訪問的頂點作起始點, 重複上述過程, 直至圖中所有頂點都被訪問到為止. 顯然,
深度優先搜索對於圖這類結構很容易被遞歸過程所構造.
3.1.2 深度優先搜索圖解
3.1.2.1 無向圖的深度優先搜索
下面以”無向圖”為例, 來對深度優先搜索進行演示.
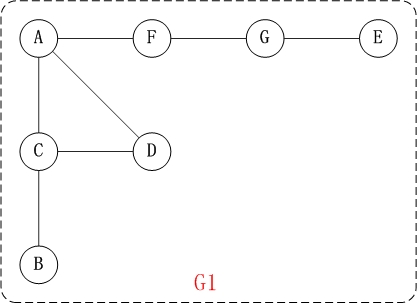
對上面的 圖 G1 進行深度優先遍歷,從 頂點 A 開始.
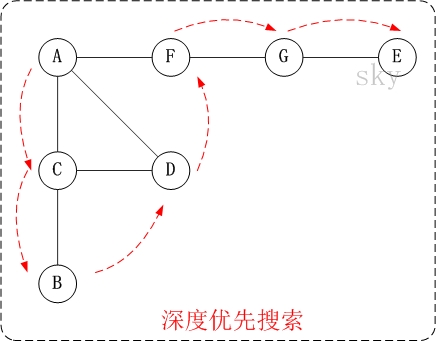
第1步: 訪問 A.
第2步: 訪問(A 的鄰接點) C.
在 第1步 訪問 A 之後, 接下來應該訪問的是 A 的鄰接點, 即 “C, D, F” 中的一個. 但在本文的實現中,
頂點 ABCDEFG 是按照順序存儲,C在”D和F”的前面,因此,先訪問C.
第3步: 訪問(C 的鄰接點) B.
在 第2步 訪問 C 之後, 接下來應該訪問 C 的鄰接點, 即 “B和D” 中一個(A已經被訪問過,就不算在內)
. 而由於 B 在 D 之前, 先訪問 B.
第4步: 訪問(C 的鄰接點) D.
在 第3步 訪問了 C 的鄰接點 B 之後, B 沒有未被訪問的鄰接點; 因此, 返回訪問 C 的另一個鄰接點 D.
第5步: 訪問(A 的鄰接點) F.
前面已經訪問了 A, 並且訪問完了 “A 的鄰接點 B 的所有鄰接點(包括遞歸的鄰接點在內)”; 因此, 此時
返回到訪問A的另一個鄰接點F。
第6步: 訪問(F 的鄰接點) G.
第7步: 訪問(G 的鄰接點) E.
因此訪問順序是: A -> C -> B -> D -> F -> G -> E
3.1.2.2 有向圖的深度優先搜索
下面以”有向圖”為例, 來對深度優先搜索進行演示.
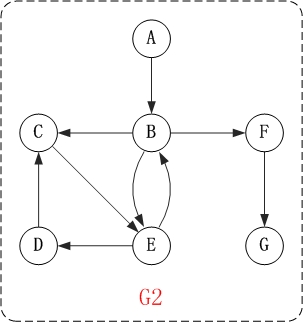
對上面的 圖 G2 進行深度優先遍歷, 從 頂點 A 開始.
第1步: 訪問 A.
第2步: 訪問 B.
在訪問了 A 之後, 接下來應該訪問的是 A 的出邊的另一個頂點, 即頂點 B.
第3步: 訪問 C.
在訪問了 B 之後, 接下來應該訪問的是 B 的出邊的另一個頂點, 即 頂點 C, E, F. 在本文實現的圖中, 頂
點 ABCDEFG 按照順序存儲, 因此先訪問 C.
第4步: 訪問 E.
接下來訪問 C 的出邊的另一個頂點, 即頂點 E.
第5步: 訪問 D.
接下來訪問 E 的出邊的另一個頂點, 即 頂點 B, D. 頂點 B 已經被訪問過, 因此訪問 頂點 D.
第6步: 訪問 F.
接下應該回溯”訪問 A 的出邊的另一個頂點 F”.
第7步: 訪問 G.
因此訪問順序是: A -> B -> C -> E -> D -> F -> G
3.2 廣度優先搜索圖文介紹
3.2.1 廣度優先搜索介紹
廣度優先搜索演算法(Breadth First Search), 又稱為”寬度優先搜索”或”橫向優先搜索”, 簡稱BFS. 它的遍歷
常規思路是: 從圖中某頂點(結點) v 出發, 在訪問了 v 之後依次訪問 v 的各個未曾訪問過的鄰接點, 然後分別從
這些鄰接點出發依次訪問它們的鄰接點, 並使得”先被訪問的頂點的鄰接點先於後被訪問的頂點的鄰接點被訪問
, 直至圖中所有已被訪問的頂點的鄰接點都被訪問到. 如果此時圖中尚有頂點未被訪問, 則需要另選一個未曾被
訪問過的頂點作為新的起始點, 重複上述過程, 直至圖中所有頂點都被訪問到為止. 換句話說, 廣度優先搜索遍歷
圖的過程是以 v 為起點, 由近至遠, 依次訪問和 v 有路徑相通且’路徑長度’為 1, 2 … 的頂點.
3.2.2 廣度優先搜索圖解
3.2.2.1 無向圖的廣度優先搜索
下面以”無向圖”為例, 來對廣度優先搜索進行演示. 還是以上面的 圖 G1 為例進行說明.
第1步: 訪問 A.
第2步: 依次訪問 C, D, F.
在訪問了 A 之後,接下來訪問 A 的鄰接點. 前面已經說過, 在本文實現中, 頂點 ABCDEFG 按照順序存儲
的, C 在 “D 和 F” 的前面, 因此, 先訪問 C. 再訪問完 C 之後, 再依次訪問 D, F.
第3步: 依次訪問 B, G.
在 第2步 訪問完 C, D, F 之後, 再依次訪問它們的鄰接點. 首先訪問 C 的鄰接點 B, 再訪問 F 的鄰接點 G.
第4步: 訪問 E.
在 第3步 訪問完 B, G 之後, 再依次訪問它們的鄰接點. 只有 G 有鄰接點 E, 因此訪問 G 的鄰接點 E.
因此訪問順序是: A -> C -> D -> F -> B -> G -> E
3.2.2.2 有向圖的廣度優先搜索
下面以”有向圖”為例, 來對廣度優先搜索進行演示. 還是以上面的 圖 G2 為例進行說明.
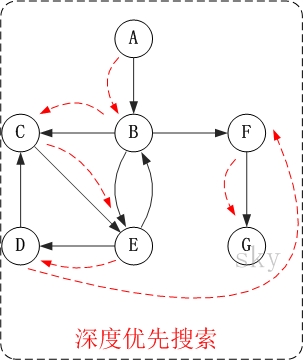
第1步: 訪問 A.
第2步: 訪問 B.
第3步: 依次訪問 C, E, F.
在訪問了 B 之後, 接下來訪問 B 的出邊的另一個頂點, 即 C, E, F. 前面已經說過, 在本文實現中,頂點
ABCDEFG 按照順序存儲的, 因此會先訪問 C, 再依次訪問 E, F.
第4步: 依次訪問 D, G.
在訪問完 C, E, F 之後, 再依次訪問它們的出邊的另一個頂點. 還是按照 C, E, F 的順序訪問, C 的已經全部
訪問過了, 那麼就只剩下 E, F; 先訪問 E 的鄰接點 D, 再訪問 F 的鄰接點 G.
因此訪問順序是:A -> B -> C -> E -> F -> D -> G