MySQL 學習筆記
MySQL學習筆記
MySQL簡介
MySQL 是由瑞典的 MySQL AB 公司開發的,目前是 Oracle(甲骨文)公司的一個關係型資料庫產品(2008年 MySQL AB 被 Sun 公司收購、2009年 Sun 公司又被 Oracle 收購 )。MySQL 是世界上最流行的開源資料庫系統,功能足夠強大,足以應付普通的web應用。百度,淘寶,校內網,騰訊,維基百科等都在使用MySQL資料庫。
MySQL的版本分為社區版(免費)和企業版,支援多個作業系統平台,內部支援多種存儲引擎,可以根據具體需求給每個表設置不同的存儲引擎以達到最高的效率。建議使用MySQL 5.7版本的。
因為商業資料庫的老大有可能將MySQL閉源,為了避免Oracle將MySQL閉源,而無開源的類MySQL資料庫可用,MySQL社區採用了分支的方式——MariaDB資料庫就這樣誕生了,MariaDB是一個向後兼容的資料庫產品,可能會在以後替代MySQL
什麼是資料庫
嚴格來講資料庫是一個存放數據的容器(倉庫),可以是文件或是記憶體空間等。當我們需要訪問資料庫中數據時,我們需要使用到資料庫管理系統(DBMS)。我們平時說的資料庫是指:資料庫管理系統(DBMS)+資料庫(DB)
資料庫概念的正規定義:對大量數據進行管理的高效的解決方案。
常見的資料庫有:
- Mysql
- SQLServer
- Oracle
- PGSQL
- DB2(IBM)
什麼是資料庫管理系統
資料庫管理系統(DBMS)是指訪問操作資料庫的軟體。
關係型資料庫和非關係型資料庫
關係型數據(RDBS,RELATIONAL DBS)是建立在關係模型上的資料庫系統。關係模型就是指二維表格模型,因而一個關係型資料庫就是由二維表及其之間的聯繫組成的一個資料庫系統 ,結構和實體關係。
非關係型資料庫(NoSQL): redis面向鍵值對, MongoDB面向文檔,HBase面向列存儲,NEO4J圖形資料庫。
MySQL的體系架構
MySQL採用C/S架構。啟動MySQL服務可以採用mysqld命令
# 啟動mysql服務
mysqld start
mysqld stop
# 鏈接伺服器
mysql -hlocalhost -P3306 -uroot -p
# 退出mysql服務
quit
上面的mysqld是啟動MySQL服務的命令,MySQL還提供了很多其他的工具命令。
MySQL伺服器端實用工具程式如下:
● mysqld:SQL後台程式(即MySQL伺服器進程)。該程式必須運行之後,客戶端才能通過連接伺服器來訪問資料庫。
● mysqld_safe:伺服器啟動腳本。在UNIX和NewWare中推薦使用mysqld_safe來啟動mysqld伺服器。mysqld_safe增加了一些安全性,例如,當出現錯誤時,重啟伺服器並向錯誤日誌文件中寫入運行時間資訊。
● mysql.server:伺服器啟動腳本。該腳本用於使用包含為特定級別的、運行啟動伺服器腳本的、運行目錄的系統。它調用mysqld_safe來啟動MySQL伺服器。
● mysqld_multi:伺服器啟動腳本,可以啟動或停止系統上安裝的多個伺服器。
● mysamchk:用來描述、檢查、優化和維護MyISAM表的實用工具。
● mysql.server:伺服器啟動腳本。在UNIX中的MySQL分發版包括mysql.server腳本。
● mysqlbug:MySQL缺陷報告腳本。它可以用來向MySQL郵件系統發送缺陷報告。
● mysql_install_db:該腳本用默認許可權創建MySQL授予權表。通常只是在系統上首次安裝MySQL時執行一次。MySQL客戶端實用工具程式如下:
● myisampack:壓縮MyISAM表以產生更小的只讀表的一個工具。
● mysql:互動式輸入SQL語句或從文件經批處理模式執行它們的命令行工具。
● mysqlacceess:檢查訪問主機名、用戶名和資料庫組合的許可權的腳本。
● mysqladmin:執行管理操作的客戶程式,例如創建或刪除資料庫、重載授權表、將表刷新到硬碟上以及重新打開日誌文件。Mysqladmin還可以用來檢索版本、進程以及伺服器的狀態資訊。
● mysqlbinlog:從二進位日誌讀取語句的工具。在二進位日誌文件中包含執行過的語句,可用來幫助系統從崩潰中恢復。
● mysqlcheck:檢查、修復、分析以及優化表的表維護客戶程式。
● mysqldump:將MySQL資料庫轉儲到一個文件(例如SQL語句或Tab分隔符文本文件)的客戶程式。
● mysqlhotcopy:當伺服器在運行時,快速備份MyISAM或ISAM表的工具。
● mysql import:使用LOAD DATA INFILE將文本文件導入相應的客戶程式。
● mysqlshow:顯示資料庫、表、列以及索引相關資訊的客戶程式。
● perror:顯示系統或MySQL錯誤程式碼含義的工具。
SQL語言簡介
有了資料庫之後,我們需要一個語言來和數據進行交互。SQL(結構化查詢語言)就是專門用來和資料庫交互的的一種語言。
SQL有許多不同的類型,有3個主要的標準:ANSI(美國國家標準機構)SQL;對ANSI SQL修改後在1992年採納的標準,稱為SQL-92或SQL2;最近的SQL-99標準,從SQL2擴充而來並增加了對象關係特徵和許多其他新功能。其次,各大資料庫廠商提供不同版本的SQL(比如PLSQL),這些版本的SQL不但能包括原始的ANSI標準,而且在很大程度上支援SQL-92標準。
SQL語言大致可以分為以下幾類類:
- 數據操作語言(DML,Data Manipulation Language )(DQL+DML):由select、insert、update和delete關鍵字完成,用來對資料庫表內容的增刪改查操作;
- 結構操作語言(數據定義語言,DDL,Data Definition Language ):create、drop、truncate和alter完成,用來對資料庫和資料庫對象的增刪改操作(drop會同時刪除表結構和表數據,truncate會只是刪除數據不刪除表結構,其原理是先drop然後再創建表結構);
- 資料庫管理語言(資料庫控制語言,DCL,DataBase Control Language):grant、revoke完成;
- 事物控制語言:主要有commit、rollback、savepoint完成。
有上面的介紹可知,大多數與資料庫的操作可以總結為對資料庫對象(資料庫、表、視圖、存儲過程等)的增刪改查操作,所以下面會從各個資料庫對象的增刪改查來介紹。在MySQL中主要的資料庫對象有:
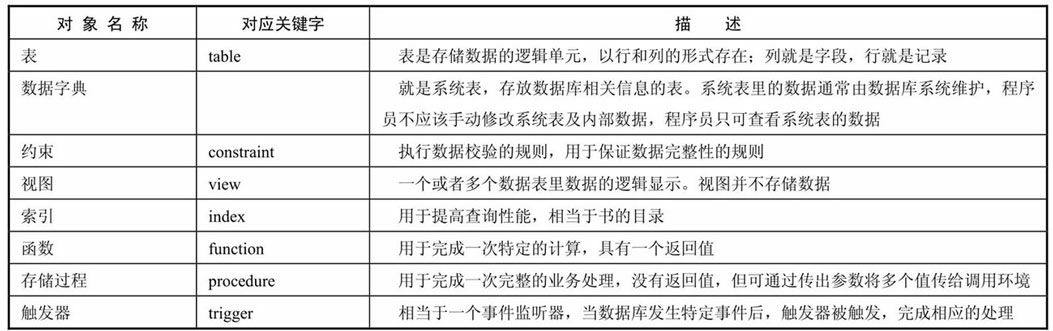
MySQL基礎知識
在講 MySQL 中數據表的增刪改查之前,我們先需要創建表。創建表的過程中需要制定表欄位的類型,欄位的約束以及表的存儲引擎等。所以非常有必要先介紹些MySQL的基礎語法知識。
字符集和校驗規則
字符集:字元的集合,常見的字符集有ASCLL、GBK和Unicode等;
校驗規則:當前字符集內,字元之間大小的比較規則。
數據類型
MySQL中三大數據類型是:數值、日期和字元串。
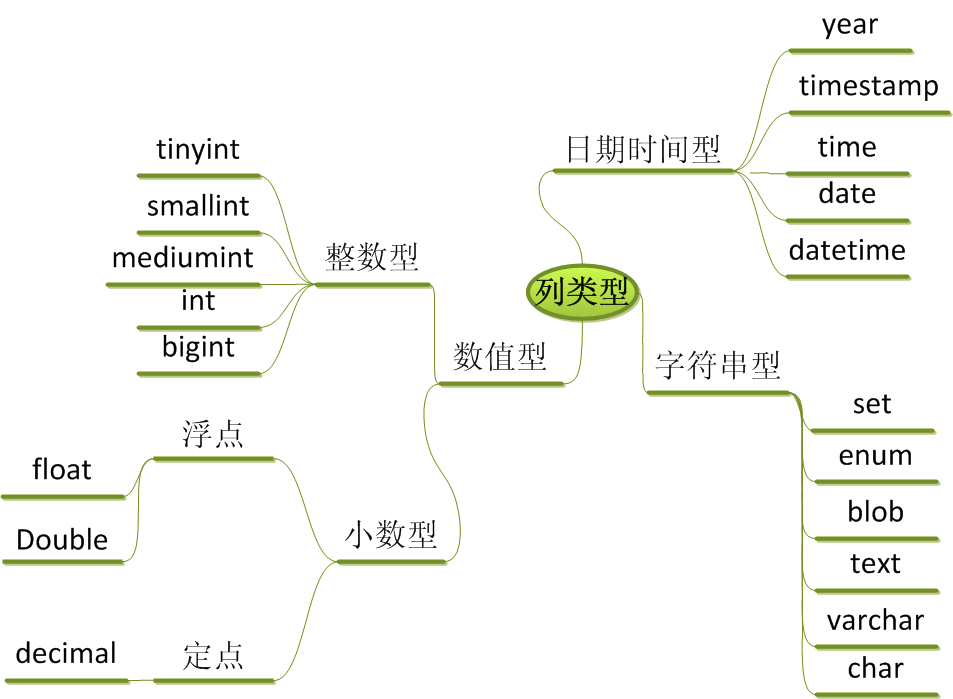
數值型
1. 數值類型
| 類型 | 位元組 | 最小值 | 最大值 |
|---|---|---|---|
| TYNYINT | 1 | -128/0 | 127/255 |
| SMALLINT | 2 | -32768/0 | 32767/65535 |
| MEDIUMINT | 3 | -8388608/0 | 8388607/16777215 |
| INT | 4 | -2147483648/0 | 2147483647/4294967295 |
| BIGINT | 8 | 很大… | 很大… |
INT(M) UNSIGNED ZEROFILL
可以這樣定義數值類型。其中M,表示顯示寬度,顯示寬度不限制數值的範圍。配合zerofill來使用,可以在小於顯示寬度的位數前增加0。ZEROFILL 自動為unsigned。Unsigned 表示無符號,只表示正數。
2. 小數類型
單精度(不推薦使用)
FLOAT(M,D) UNSIGNED ZEROFILL
雙精度
DOUBLE(M,D) UNSIGNED ZEROFILL
其中M表示總的位數(包括小數位數),D表示小數位數。M,D可以控制保存的範圍。比如DOUBLE(10,2)可以表示 -99999999.99 到 99999999.99。
定點數(金額,科學數據推薦使用這個類型)
DECIMAL(M,D) UNSIGNED ZEROFILL
其中M表示總的位數,D表示小數位數。此M,D可以控制保存的範圍。M,D省略,默認為10,0;
日期型
可以考慮使用long類型來存儲,也就是時間戳。
或者使用datetime(或timestamp)類型來存儲。但是這兩個類型有個問題:datetime不包含時區的概念,也就是你傳’2019-09-08 12:56:34’,它存儲的就是這個值。timestamp雖然包含時區的概念,但是它的取值範圍比較小(1970-01-01 00:00:01 — 2038-01-19 03:14:07),有些情況不夠用。
所以會有上面的建議,使用long類型存時間戳。
字元串型和二進位
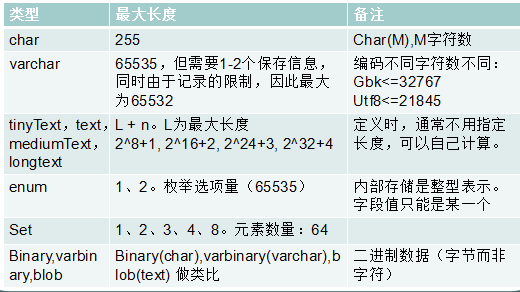
選擇數據類型的建議
當選擇欄位類型時,應該遵循下面幾個原則:
- 應該使用最精確的類型,佔用的空間少,已經事先估計欄位可能的長度;
- 還應該考慮到相關應用語言的處理,例如常常將時間日期保存成一個整型,便於計算;
- 考慮移植的兼容性。
約束
MySQL中列約束一般用來保證資料庫表數據的正確性和完整性。
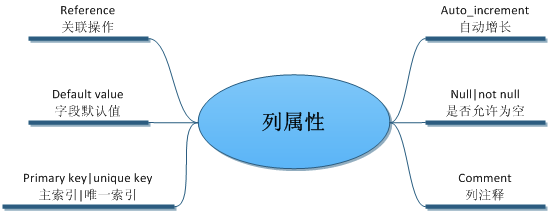
主鍵約束
主鍵:可以唯一標識一條記錄的一列或者多列的組合。主鍵具有以下特點:
-
每個表只能定義一個主鍵;
-
任意兩行都不具有相同的主鍵值;
-
每一行都必須具有一個主鍵值(主鍵列不允許NULL值);
-
主鍵列中的值不允許修改或更新;
-
主鍵值不能重用(如果某行從表中刪除,它的主鍵不能賦給以後的新行)。
-- 添加主鍵
create table tbl_user
(
user_id int primary key,
user_name varchar(20)
);
create table tbl_user
(
user_id int,
user_name varchar(20),
primary key(user_id)
);
alter table tbl_user add primary key(user_id,user_name);
ALTER TABLE tbl_test1 ADD CONSTRAINT pk_tbl_test1 PRIMARY KEY(id);
-- 刪除主鍵(假如主鍵列具有auto_increment屬性,需要先刪除自增長屬性,再刪除主鍵)
ALTER TABLE TABLE_NAME DROP PRIMARY KEY;
外鍵約束
外鍵(FK,foreign key):如果一個A表的欄位指向另一個B表的主鍵,則此欄位就為A表的外鍵。用於表示表之間的關係。存在外鍵的表,稱之為從表(子表),外鍵指向的表,稱之為主表(父表)。外鍵只被innodb存儲引擎所支援。其他引擎是不支援的。一個表可以存在一個或者多個外鍵。
外鍵的默認作用有兩點:
- 對子表(外鍵所在的表)的作用:子表在進行寫操作的時候,如果外鍵欄位在父表中找不到對應的匹配,操作就會失敗;
- 對父表的作用:對父表的主鍵欄位進行刪和改時,如果對應的主鍵在子表中被引用,操作就會失敗。
外鍵的訂製有三種約束模式:
- district:嚴格模式(默認), 父表不能刪除或更新一個被子表引用的記錄的主鍵值;
- cascade:級聯模式, 父表的主鍵值操作後,子表關聯的數據也跟著一起操作;
- set null:置空模式,前提外鍵欄位允許為NLL, 父表的主鍵值操作後,子表對應的欄位被置空。
-- 添加外鍵
create table tbl_user
(
user_id int primary key,
user_name varchar(20),
class_id int,
CONSTRAINT fk_tbl_user foreign key(class_id) references tbl_class(class_id)
)
alter table tbl_user add CONSTRAINT fk_tbl_user foreign key(class_id) references tbl_class(class_id);
-- 刪除外鍵
alter table tbl_user drop foreign key fk_tbl_user;
唯一性約束
唯一性約束可以確保一列或者多列不出現重複值。
Unique和Primary Key的區別:
- 一個表可以有多個欄位聲明為 Unique,但是只能有一個Primary Key生命;
- Primary Key的列不能為空值,但是Unique的列可以為空值。
-- 創建唯一性約束
CREATE TABLE tbl_test2
(
id INT,
name1 VARCHAR(20),
nick_name VARCHAR(20),
age INT,
CONSTRAINT unique_tbl_test2_name UNIQUE(name1,nick_name)
)
alter table tbl_test2 add constraint unique_tbl_test2_name UNIQUE(name1,nick_name);
-- 刪除唯一性約束(從下面的語法我們可以看出唯一性約束其實是個索引)
alter table tbl_test2 drop index unique_tbl_test2_name
檢查約束
檢查約束用於檢查資料庫表中某些欄位時候符合條件。
-- 創建檢查約束
CREATE TABLE tbl_test3
(
id INT,
name1 VARCHAR(20),
nick_name VARCHAR(20),
age INT,
CONSTRAINT check_tbl_test3 CHECK(age>20 AND age<40)
)
alter table table_test3 add constraint check_tbl_test3 check(age>20 and age<40);
-- 刪除檢查約束
alter table tbl_test3 drop constraint check_tbl_test3
默認值約束
插入一條記錄時沒有給這個欄位賦值,如果建表時設置了默認值,系統就會給這個欄位賦默認值。
-- 添加默認值
CREATE TABLE tbl_test4
(
id INT PRIMARY KEY AUTO_INCREMENT,
`name` VARCHAR(20) DEFAULT 'wuming',
age INT
)
ALTER TABLE tbl_test4 MODIFY COLUMN age INT DEFAULT 20;
-- 刪除默認值(刪除age欄位的默認值)
ALTER TABLE tbl_test4 CHANGE COLUMN age age INT DEFAULT NULL;
非空約束
-- 添加非空約束
CREATE TABLE tbl_test5
(
id INT PRIMARY KEY AUTO_INCREMENT,
`name` VARCHAR(20) NOT NULL,
age INT
)
ALTER TABLE tbl_test5 MODIFY COLUMN age INT NOT NULL;
-- 刪除非空約束
ALTER TABLE tbl_test5 MODIFY COLUMN age INT NULL;
自動增長約束
該列上必須有索引,not null,只能存在一個自動增長的列。通常定義在主索引(主鍵)欄位上。
通常 自動增長是從1開始遞增,但是可以通過修改表屬性,更改初始值。表屬性 auto_increment=x;(如果比已存在的小,則會從已有的最大值新記錄)
存儲引擎
存儲引擎可以理解為表的存儲結構,每種存儲引擎都支援不同的特性。MySQL支援插件式的存儲引擎,可以為每張數據表指定不同的存儲引擎。常用的存儲引擎有以下幾種:
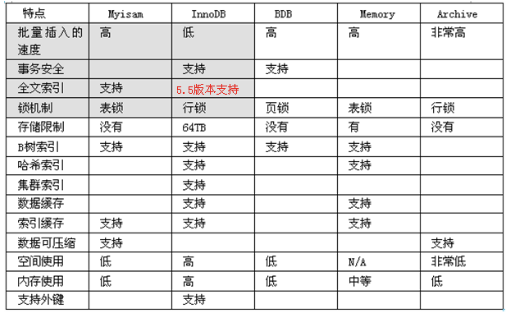
我們也可以使用下面命令查看當前資料庫支援哪些存儲引擎:
-- 查看支援的存儲引擎
show engines;
下面對最常用的三種存儲引擎做下簡單介紹:
- InnoDB:MySQL默認的存儲引擎,支援事務、支援行級鎖和表級鎖、支援各類索引、支援外鍵,高版本的MySQL還支援全文索引,但是批量數據插入的效率較低;
- MyISAM:具有較高的數據插入效率和數據查詢速度,支援全文索引,但是不支援資料庫事務,不支援行級鎖,只支援表級鎖;
- MEMORY:使用這個存儲引擎時,會將表中的數據載入到記憶體中,查詢很快,但是對記憶體要求較高。
所以我們應該根據應用的具體需求選擇合適的存儲引擎,而不是不加思考的都選擇默認存儲引擎(INNODB)。
如果要提供提交、回滾和恢復的事務安全(ACID兼容)能力,並要求實現並發控制,InnoDB是一個很好的選擇。如果數據表主要用來插入和查詢記錄,則MyISAM引擎提供較高的處理效率。如果只是臨時存放數據,數據量不大,並且不需要較高的數據安全性,可以選擇將數據保存在記憶體的MEMORY引擎中,MySQL中使用該引擎作為臨時表,存放查詢的中間結果。如果只有INSERT和SELECT操作,可以選擇Archive引擎,Archive存儲引擎支援高並發的插入操作,但是本身並不是事務安全的。Archive存儲引擎非常適合存儲歸檔數據,如記錄日誌資訊可以使用Archive引擎。
實體關係和表設計
- 1對1,兩個表保存的實體之間數據是對等的,比如一個學生有基本資訊和詳細資訊;
- 1對N,A實體對應多個B實體 ,比如一個班級內有很多學生,而且一個學生只屬於一個班級;
- M對N,A實體對應多個B實體,同時一個B實體也對應多個A實體,比如一個講師可以給多個班級授課。同時一個班級可以由多個來授課;
表設計原則:
- 1對1:兩個表具有相同的主鍵即可;
- 1對N:在多的實體端使用一個欄位存儲1端實體的主鍵資訊;
- M對N:增加一個存儲實體之間對應關係的表,保存A實體主鍵和B實體主鍵。每一個記錄,對應一個對應關係。
資料庫範式
範式是指資料庫設計規範。一共存在6個級別的範式,1NF,2NF,3NF,4NF,5NF,6NF。要求是從低到高逐漸遞增。關係型資料庫必須滿足1NF,通常滿足到3NF就可以了。
- 1NF:是指資料庫表的每一列都是不可分割的基本數據項,同一列中不能有多個值,即實體中的某個屬性不能有多個值或者不能有重複的屬性。第一範式是對關係模式的最起碼的要求。不滿足第一範式的資料庫模式不能稱為關係資料庫。比如地址這個欄位不能存成:江蘇省-南通市-啟東縣,而應該存成三個欄位:省、市和縣。
- 2NF:在滿足1NF的基礎上,要求表中的每條記錄必須被唯一的區分。通常的做法是為每條記錄添加主鍵。
- 3NF:滿足第二範式的基礎上,要求不能出現傳遞依賴,也就是不能出現屬性依賴於非主屬性的.
MySQL資料庫增刪改查
資料庫是所有其他資料庫對象的載體,在創建資料庫表之前必有先創建一個資料庫。
資料庫的創建
-- 建資料庫語句模板
Create database [if not exists] 資料庫名 [資料庫選項]
-- 建資料庫例子,在建資料庫時一般只要指定charset就可以了(有時你還可以設置校驗規則 )
CREATE DATABASE if not exists my_database charset utf8;
-- 選擇資料庫
use my_database;
資料庫的刪除
-- 刪除資料庫語句模板
drop database [if exists] 資料庫名 [資料庫選項]
-- 刪除資料庫例子,在建資料庫時一般只要指定charset就可以了
drop DATABASE if exists my_database;
資料庫的修改
-- 一般只要修改資料庫的字符集就可以了,校驗規則會默認選和字符集匹配的
ALTER DATABASE my_database CHARACTER SET gbk;
MySQL中一般不能直接對資料庫重命名,如果想重命名資料庫一般的做法有:
- 創建新資料庫,將原資料庫內的表重命名到新資料庫內,刪除原資料庫。
- 將原資料庫的數據和結構導出,然後在導入到新資料庫內,刪除原資料庫。
資料庫的查詢
-- 查詢資料庫名字以my打頭的資料庫
SHOW DATABASES LIKE 'my%';
-- 顯示所有的資料庫
SHOW DATABASES;
-- 顯示資料庫的創建結構
SHOW CREATE DATABASE my_database;
MySQL數據表的增刪改查
數據表是資料庫中最基礎的對象,平時大多數操作都是圍繞著資料庫表進行。在MySQL中,數據表是一個二維表,一般是一個實體的映射(當然也有很多表示關係的映射)。
表的創建
MySQL中表的創建有下面幾種模式:
Create table [if not exists] tbl_name (列定義) [表選項]
-- 只會創建表結構
Create table [if not exists] tbl_name like old_tbl_name;
-- 創建表結構和內容
Create table [if not exists] tbl_name as select 語句; //創建表結構和內容
-- 列定義部分
列名 類型 [是否為空] [Default 默認值] [是否為自動增長] [是否為主索引或唯一索引] [comment 注釋] [引用定義]
-- 常見的表選項有ENGINE、字符集和注釋等
-- 建表語句例子
CREATE TABLE `sys_user` (
`user_id` bigint NOT NULL AUTO_INCREMENT,
`username` varchar(50) NOT NULL COMMENT '用戶名',
`password` varchar(100) COMMENT '密碼',
`salt` varchar(20) COMMENT '鹽',
`email` varchar(100) COMMENT '郵箱',
`mobile` varchar(100) COMMENT '手機號',
`status` tinyint COMMENT '狀態 0:禁用 1:正常',
`create_user_id` bigint(20) COMMENT '創建者ID',
`create_time` datetime COMMENT '創建時間',
PRIMARY KEY (`user_id`),
UNIQUE INDEX (`username`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='系統用戶'
-- 使用上面語句創建完表之後,可以使用下面語句查看錶結構
show create table sys_user;
desc sys_user;
表的刪除
Drop table [if exists] tbl_name1,tbl_name2;
-- 刪除內容,但是保留表結構
TRUNCATE tbl_name1;
一次性可以刪除多了表。
表的修改
-- 修改表名字
RENAME TABLE tbl_name1 TO tbl_name2;
-- 跨資料庫
RENAME TABLE database1.tbl_name1 TO database.tbl_name2;
RENAME TABLE tb_user TO tbl_user;
-- 表結構修改
-- 添加欄位,First選項用於指定新加的欄位是否在第一位,AFTER選項指定新加的欄位在哪個欄位後面
ALTER TABLE <表名> ADD <新欄位名> <數據類型> [約束條件] [FIRST|AFTER已存在的欄位名];
ALTER TABLE sys_user ADD COLUMN `address` VARCHAR(50) NOT NULL COMMENT '用戶地址' AFTER mobile;
ALTER TABLE sys_user ADD COLUMN `job` VARCHAR(50) NOT NULL COMMENT '工作' AFTER address;
-- 刪除表欄位
ALTER TABLE sys_user DROP COLUMN `address`;
ALTER TABLE sys_user DROP COLUMN `job`;
-- 修改表欄位類型
ALTER TABLE sys_user MODIFY COLUMN job VARCHAR(100) NOT NULL DEFAULT '無業' COMMENT '工作';
-- 修改表欄位名稱,將欄位job改成job_type
ALTER TABLE sys_user CHANGE COLUMN job job_type VARCHAR(100) NOT NULL DEFAULT '無業' COMMENT '工作類型';
表的查詢
-- 查看某個資料庫下面的所有表
show tables from database;
-- 查看錶結構
show create tbl_name;
desc tbl_name;
MySQL表數據的增刪改查
數據的增加
--MySQL特殊語法,可以一次插入多列,Oracle不支援
INSERT INTO `tb_user` (`username`, `mobile`, `password`, `create_time`) VALUES
('mark4', '13612345678', '8c6976e5b5410415bde908bd4d', '2017-03-23 22:37:41'),
('mark5', '13612345678', '8c6976e5b5410415bde908bd4d', '2017-03-23 22:37:41'),
('mark3', '13612345678', '8c6976e5b5410415bde908bd4d', '2017-03-23 22:37:41');
--蠕蟲複製
INSERT INTO tbl_user_bak (password,create_time)
SELECT password,create_time FROM tbl_user_bak;
數據的刪除
--刪,支援刪除指定條數的數據
delete from tbl_name where 條件
DELETE FROM tbl_name [WHERE where_definition] [ORDER BY ...] [LIMIT row_count]
按照條件刪除(delete可以指定一次刪除幾條記錄,delete還支援多表刪除,類似join語法)
數據的更新
--改,支援排序,支援只更新指定條數
update tbl_name set col1=value1,col2=value2 where 條件 [order by] [limit]
update支援多表聯合更新,類似join語法。
數據的查詢
Select 主要用於數據。查詢可以配合其5個字句獲得,獲得相應功能。
Select [distinct] select_expr [from tbl_name] [where] [group by] [having] [order by] [limit]
上面的select_expr可以是表達式、函數表達式、純列名或者是用as指定別名。表名可以是一個表,可以是多個表,也可以用as給表指定別名。另外表名可以是虛擬表dual。(純粹是為了滿足select * from dual這種形式)
Where子句
在select查詢語句中where條件運算用於初步刪選條件,滿足這個條件的記錄將被進一步刪選。常用的運算符有下面這些。除了這些,正則運算符 也是常用的。Mysql本身也提供了很多內置函數幫我們解決問題,我們要善於利用這些函數解決問題。
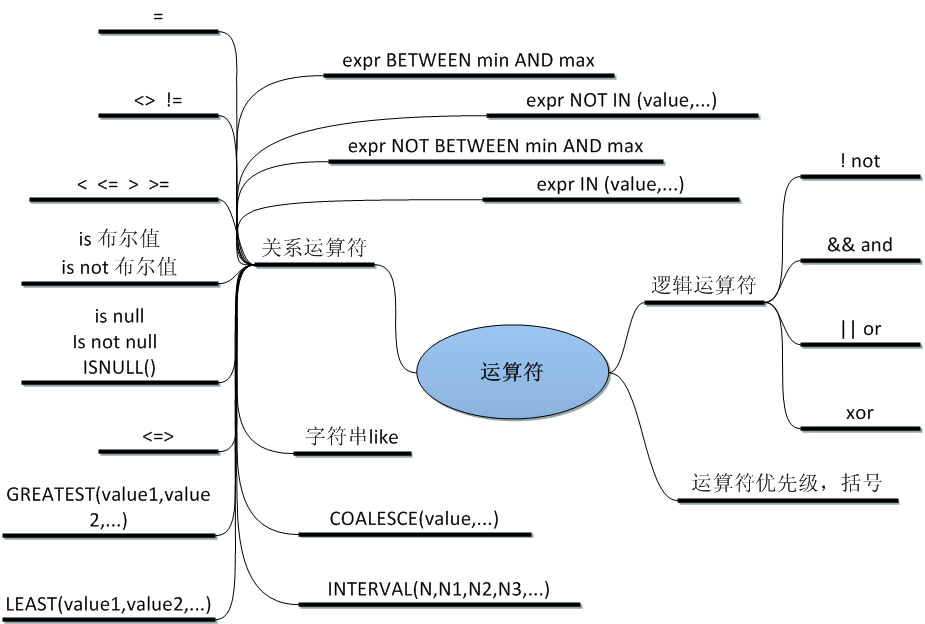
where子句表達式的判定結果有3種情況,分別是:true、flase和unknown。
在比較表達式exp1=exp2中有一個表達式的值是null時,整個表達式返回null,where對於null的處理就是false。對於安全等與運算符<=>需要強調下和=號的區別。<=>對於null值不會返回unknown。
對於上面的coalesce函數說明下,coalesce(exp1,exp2 …,expn,’defaultValue’),這個函數返回第一個不是null的值,如果都是null就返回默認值。
-- 返回第一個參數,在有序數組中的位置
mysql>SELECT INTERVAL(6,1,2,3,4,5,6,7,8,9,10);
+---------------------------------------------------------+
| INTERVAL(6,1,2,3,4,5,6,7,8,9,10) |
+---------------------------------------------------------+
| 6 |
+---------------------------------------------------------+
1 row in set (0.00 sec)
---------------------
和like關鍵字類似,Mysql中還提供了基於正則表達式的查詢,基本語法如下:
-- 正則表達式查詢
select exp1,exp2 from tbl_name where col1 REGEXP 'reg_exp_str';
在like子句中使用通配符
- %:匹配:0個或多個字元
- _:匹配1個字元
- []:匹配一個字符集
Group By子句
Group by 根據一個或多個列對結果集進行分組,語法為:
[GROUP BY {col_name | expr | position} [ASC | DESC], ... [WITH ROLLUP]]
分組後,每組內顯示一條記錄。原則上,分組後,查詢欄位應該只有分組欄位,但是也可以有其他欄位。此時其他欄位就只是組內第一條記錄的資訊,不能準確表示組內所有數據資訊,因此通常不查詢其他欄位。分組欄位必須出現在查詢欄位中,不然會報錯。
注意:group by後面可以跟多列,此時會根據多列的組合來分組。比如說幾個列的組合不同,mysql就認為這是一個不同的分組,會將它顯示出來。null會被單獨作為一個分組,若該列中存在多個null值,他們會被分為一組。
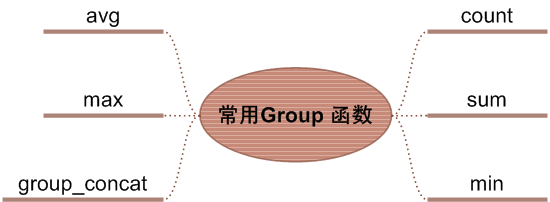
group by經常和聚合函數一起使用,用來統計分組後組內的資訊。但是可以單獨使用,相當於將所有行看成一組。通常合計函數是不統計null值的。
Having子句
having子句用來對group by之後的結果進行進一步刪選。舉個栗子:
select teacher, sum(days) as sum_days from lesson where 1 group by teache having sum_days > 44;
- <條件>:指定過濾條件。
HAVING子句和WHERE子句非常相似,HAVING子句支援WHERE子句中所有的操作符和語法,但是兩者存在幾點差異: - WHERE子句主要用於過濾數據行,而HAVING子句主要用於過濾分組,即HAVING子句基於分組的聚合值而不是特定行的值來過濾數據,主要用來過濾分組。
- WHERE子句不可以包含聚合函數,HAVING子句中的條件可以包含聚合函數。
- HAVING子句是在數據分組後進行過濾,WHERE子句會在數據分組前進行過濾。WHERE子句排除的行不包含在分組中,可能會影響HAVING子句基於這些值過濾掉的分組。
Order By子句
基本語法如下:
-- 下面的位置是指select後面欄位的位置
ORDER BY {<列名>|<表達式>|<位置>} [AESC|DESC]
Order by,可以使用一列或者多個列對結果進行排序。如果存在多個排序欄位,在前一個不能比較出結果後,後邊的才起作用。可以分別指明是升序還是降序:asc(ascending) desc(descending)。Order by會把null值當做最小值來處理。如果不使用Order By排序的話,默認使用插入順序來顯示。 order by的欄位可以不出現在查詢的欄位中,比如:
SELECT vend_id, prod_name FROM products ORDER BY prod_price;
limit子句
用於限制select語句最後選中的記錄的個數。limit offset,rowcount,如果省略offset則默認從0開始(第一條數據的偏移量是0)。
子查詢
子查詢是指嵌套在其他查詢語句內部的查詢。
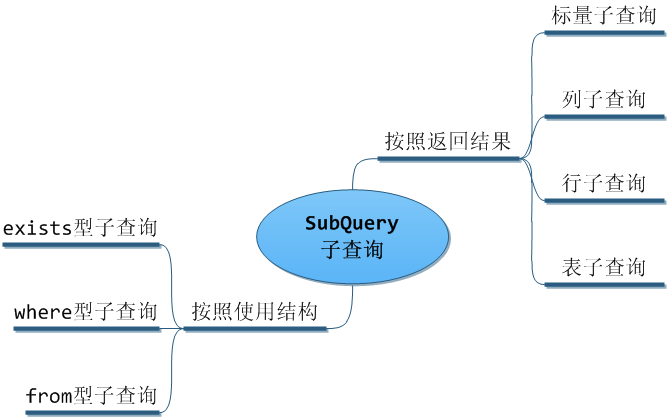
1. 根據子查詢返回的結果
一個子查詢會返回一個標量(單一值)、一個行、一個列或一個表(一行或多行及一列或多列)。這些子查詢被稱為標量、列、行和表子查詢。
2. 根據子查詢的位置
根據子查詢select 出現的的位置不同分為Where型子查詢,from型子查詢和exists子查詢
- Where型子查詢出現在where子句,通過比較運算符進行操作的。
- Exists(subquery)如果子查詢返回記錄,則exists返回1;
- From (subquery) as tmp_table; [AS] name子句是強制性的,因為FROM子句中的每個表必須有一個名稱。
在子查詢中會經常用到ANY(SOME)、ALL、IN和EXISTS這些操作符。
連接查詢
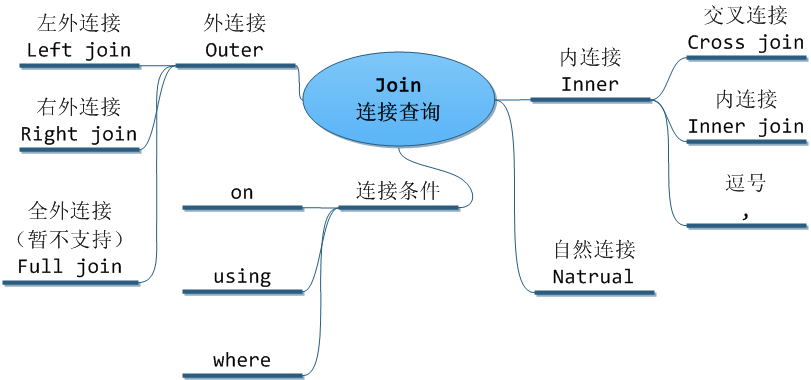
1. 內連接
內連接是把兩個表先做笛卡爾積,然後再根據連接條件刪選出相應的記錄。
SELECT A.*, B.* FROM
student_info A inner join student_score B
ON A.student_id = B.student_id
內連接中還存在一個cross join,一般用來做笛卡爾積,就是沒有條件的inner join。但是需要注意的是在mysql資料庫中corss join的行為和inner join一致,也是可以添加on條件的。建議平時使用inner join。
2. 外連接
mysql中外連接分為左外連接和右外連接(不支援全外連接)。如果是左外連接的話,除了滿足連接條件的記錄,左表中不滿足連接條件記錄也會被返回,右表中不滿足連接條件的欄位以null填充。右連接則相反。
Where和on可以使用條件表達式。Using (公共欄位),需要使用公共欄位。
內聯可以使用where on 和 條件,外聯 只可以使用using和on作為條件。
通常 where還有篩選 含義,而on和using只有連接條件的意思。因此通常連接條件使用on或using。而篩選條件使用where加以區分。推薦使用on關鍵字來表示連接條件。
3. 自連接
將同一張表自己和自己進行Inner join。暫時沒看到有太大的用處。
4. 各種連接查詢的區別
- 內連接和外連接區別
- 左外連接和右外連接的區別
聯合查詢
聯合查詢,使用union關鍵字,用於把來自許多SELECT語句的結果組合到一個結果集合中。相當於將兩個多個select語句的結果垂直的合併在一起。使用語法如下:
select column1,column2 from tbl_name1
union
select column1,column2 from tbl_name2;
在第一個SELECT語句中被使用的列名稱被用於結果的列名稱 .默認情況下,會去除重複的數據行,可以使用union all保留重複的數據行。如要對union的結果作為整體進行排序或limit,(最好對單個地SELECT語句加圓括弧),在後邊增加order by 或limit。order by引用的數據列來自第一個select。分別排序,再聯合,則需要用括弧將各select語句括起來,且order by只能在limit 出現時才有效。
函數
數值型函數
- ABS函數:絕對值
- MOD函數:取余函數
- SQRT函數:平方根函數
- SIGN函數:判斷參數是整數、負數或者是0;
- CEIL和CEILING函數:返回CEIL(x),返回不小於x的最小整數;
字元串型函數
- LENGTH函數:返回字元串的長度
- UPPER和LOWER函數
- LEFT(s,n):返回字元串最左邊的n個字元
- CONCAT(s1,s2,s3,…):字元串拼接函數,有一個參數是null就返回null
- TRIM函數
- SUBSTRING函數
- REVERSE函數:字元串逆序
- REPLACE:替換函數
日期函數
- CURDATE和CURRENT_DATE:返回當前日期;
- NOW和SYSDATE;
- CURTIME和CURRENT_TIME;
- DAYOFWEEK和WEEKDAY:返回某天是一個星期的第幾天;
- DAYOFMONTH;
- DAYOFYEAR;
- MONTH;
- MONTHNAME;
- DATEDIFF;
- ADDDATE;
- DATE_FORMAT。
聚合函數
- MAX:max不僅可以計算數值,還可以計算字元串
- MIN
- COUNT:統計記錄數,count(col_name)會忽略null值,count(*)統計所有行;
- SUM:對某一列求和,忽略值為null的行;
- AVG:忽略null行
自定義函數(見存儲過程)
視圖
在資料庫中,視圖是一張虛擬的表,視圖和普通的表沒有明顯的區別。視圖的結構和內容來自定義視圖的查詢語句。使用視圖有如下優勢:
- 視圖可以簡化查詢,可以把複雜的查詢結果放到視圖中,當我們再需要進行相同的查詢時,可以直接從視圖進行查詢,簡化查詢。
- 增加數據的安全性:表的有些敏感數據可能不許讓用戶查詢,這時可以將允許查詢的數據放入視圖中,讓用戶直接查詢視圖即可。
關於在查詢視圖時使用Order By做下說明:
ORDER BY子句可以用在視圖中,但若該視圖檢索數據的SELECT語句中也含有ORDER BY子句,則該視圖中的ORDER BY子句將被覆蓋。
視圖管理
--創建視圖:
CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}] VIEW view_name [(column_list)] AS select_statement
視圖名必須唯一,同時不能與表重名。視圖可以使用select語句查詢到的列名,也可以自己指定相應的列名。可以指定視圖執行的演算法,通過algorithm指定。
--查看結構
SHOW CREATE VIEW view_name
--刪除視圖
DROP VIEW [IF EXISTS] view_name [, view_name];
--修改視圖結構
ALTER VIEW view_name [(column_list)] AS select_statement
存儲過程(自定義函數)
自定義函數是一種與存儲過程十分相似的過程式資料庫對象。它與存儲過程一樣,都是由SQL語句和過程式語句組成的程式碼片段,並且可以被應用程式和其他SQL語句調用。但是,自定義函數與存儲過程之間仍存在幾點區別:
- 自定義函數不能擁有輸出參數,這是因為自定義函數自身就是輸出參數;而存儲過程可以擁有輸出參數。
- 自定義函數中必須包含一條RETURN語句,而這條特殊的SQL語句不允許包含於存儲過程中。
- 可以直接對自定義函數進行調用而不需要使用CALL語句,而對存儲過程的調用需要使用CALL語句。
自定義函數
CREATE FUNCTION <函數名> ( [ <參數1> <類型1> [ , <參數2> <類型2>] ] … )
RETURNS <類型>
<函數主體>
在RETURN VALUE語句中包含SELECT語句時,SELECT語句的返回結果只能是一行且只能有一列值。
自定義函數的管理
-- 刪除函數
drop function 函數名;
-- 修改函數
alter function ...;
-- 查看函數
show create function name;
存儲過程
存儲過程是一組為了完成特定功能的SQL語句表,經編譯後存儲在資料庫中,用戶通過指定存儲過程的名字並給定參數(如果該存儲過程帶有參數)來調用執行。具有如下優點:
- 不必要每次都編譯SQL語句;
- 可以增強SQL的靈活性,可以使用流程式控制制語句,完成複雜的判斷和較複雜的運算;
- 可以減少網路流量,因為存儲過程是保存在資料庫端的,不需要客戶端傳複雜的SQL語句到數據進行執行。
流程式控制制相關語法
DELIMITER $$
CREATE FUNCTION getProdName(X INT) RETURNS VARCHAR(50)
BEGIN
-- 定義一個局部變數i,默認值是1
-- 局部變數只能在Begin和end之間定義,作用域也只在begin和end之間,且必須在開頭定義
-- 全局變數使用@定義
DECLARE i INT DEFAULT 1;
DECLARE res VARCHAR(50);
-- set用來賦值
SET i = 2;
IF(X=i) THEN
-- 使用select into 語句對一個變數賦值
SELECT prod_name FROM products WHERE prod_INTO res;
RETURN res;
END IF;
SELECT prod_name FROM products WHERE prod_INTO res;
RETURN res;
END
$$
DELIMITER ;
條件控制語句
if(條件判斷) then
語句1;
else if(判斷)
語句2;
else
語句3;
end if
case
when(判斷1) then
語句1;
when(判斷2)
語句2;
default
語句3;
end case
循環控制語句
-- 除非使用leave語句離開循環,不然的話循環會一直執行
<標籤>loop
語句;
end loop [標籤]
<標籤> while <條件判斷> do
語句;
end while <標籤>
<標籤> repeat
語句;
until<條件>
end repeat <標籤>
存儲過程的詳細定義請參考這篇教程
觸發器
觸發器是關聯到某張表的一個資料庫對象。當表的一個特定事件(增刪改事件)發生時將會觸發這個觸發器。
MySQL中有Insert、Update和delete事件,每種事件又分為前後兩種事件,所以一共有6種觸發器類型。
需要使用時可以學習相關知識(主要注意的是觸發器不能控制在事務中)
索引
索引就是根據表中的一列或若干列按照一定順序建立的列值與記錄行之間的對應關係表,實質上是一張描述索引列的列值與原表中記錄行之間一一對應關係的有序表。
索引分類
根據索引的底層實現方式分,MySQL中的索引可以分為:
- B+樹索引
- Hash索引:只支援等值比較,比如「=」 「IN()」等
- R樹索引
按使用邏輯分,可以分為:
- 普通索引是最基本的索引類型,唯一任務是加快對數據的訪問速度,沒有任何限制。創建普通索引時,通常使用的關鍵字是INDEX或KEY。
- 唯一性索引是不允許索引列具有相同索引值的索引。如果能確定某個數據列只包含彼此各不相同的值,在為這個數據列創建索引的時候就應該用關鍵字UNIQUE把它定義為一個唯一性索引。創建唯一性索引的目的往往不是為了提高訪問速度,而是為了避免數據出現重複。
- 主鍵索引是一種唯一性索引,即不允許值重複或者值為空,並且每個表只能有一個主鍵。主鍵可以在創建表的時候指定,也可以通過修改表的方式添加,必須指定關鍵字PRIMARY KEY。
- 空間索引主要用於地理空間數據類型GEOMETRY。
- 全文索引只能在VARCHAR或TEXT類型的列上創建,並且只能在MyISAM存儲引擎上創建。
索引也可以被分成單列索引和組合索引。
- 單列索引就是索引只包含原表的一個列。
- 組合索引也稱為複合索引或多列索引,相對於單列索引來說,組合索引是將原表的多個列共同組成一個索引。
一個表可以有多個單列索引,但這些索引不是組合索引。一個組合索引實質上為表的查詢提供了多個索引,以此來加快查詢速度。比如,在一個表中創建了一個組合索引(c1, c2, c3),在實際查詢中,系統用來實際加速的索引有三個:單個索引(c1)、雙列索引(c1, c2)和多列索引(c1, c2, c3)。
使用原則和注意事項
雖然索引可以加快查詢速度,提高MySQL的處理性能,但是過多地使用索引也會造成以下弊端。
● 創建索引和維護索引要耗費時間,這種時間隨著數據量的增加而增加。
● 除了數據表占數據空間之外,每一個索引還要佔一定的物理空間。如果要建立聚簇索引,那麼需要的空間就會更大。
● 當對表中的數據進行增加、刪除和修改的時候,索引也要動態地維護,
創建索引可以遵循下列原則:
● 在經常需要搜索的列上建立索引,可以加快搜索的速度。
● 在作為主鍵的列上創建索引,強制該列的唯一性,並組織表中數據的排列結構。
● 在經常使用表連接的列上創建索引,這些列主要是一些外鍵,可以加快表連接的速度。
● 在經常需要根據範圍進行搜索的列上創建索引,因為索引已經排序,所以其指定的範圍是連續的。
● 在經常需要排序的列上創建索引,因為索引已經排序,所以查詢時可以利用索引的排序,加快排序查詢。
● 在經常使用WHERE子句的列上創建索引,加快條件的判斷速度。
對於那些很少使用的列,切忌建立索引;對於那些只有很少幾個值的列(比如性別)也不要建立索引;對於那些text IMG和Bit類型的欄位不要建立索引。
索引新增
創建索引的三種方式
- create index語法
create <index_name> on <tbl_name> ( <列名> [<長度>] )
比如
create index index_cust_address on test.customers(cust_address);
語法說明如下。
- <索引名>:指定索引名。一個表可以創建多個索引,但每個索引在該表中的名稱是唯一的。
- <表名>:指定要創建索引的表名。
- <列名>:指定要創建索引的列名,包含下列三個要素。
- <列名>:指定要創建索引的列名。通常可以考慮將查詢語句中在JOIN子句和WHERE子句里經常出現的列作為索引列。
- <長度>:可選項。指定使用列前的length個字元來創建索引。使用列的一部分創建索引有利於減小索引文件的大小,節省索引列所佔的空間。在某些情況下,只能對列的前綴進行索引。索引列的長度有一個最大上限255個位元組(MyISAM和InnoDB表的最大上限為1000個位元組),如果索引列的長度超過了這個上限,就只能用列的前綴進行索引。另外,BLOB或TEXT類型的列也必須使用前綴索引。
- ASC | DESC:可選項。ASC指定索引按照升序來排列,DESC指定索引按照降序來排列,默認為ASC。
查看索引
show index from tbl_name
返回欄位說明如下。
- Table:表的名稱。
- Non_unique:用於顯示該索引是否是唯一索引。若不是唯一索引,則該列的值顯示為1;若是唯一索引,則該列的值顯示為0。
- Key_name:索引的名稱。
- Seq_in_index:索引中的列序列號,從1開始計數。
- Column_name:列名稱。
- Collation:顯示列以何種順序存儲在索引中。在MySQL中,升序顯示值「A」(升序),若顯示為NULL,則表示無分類。
- Cardinality:顯示索引中唯一值數目的估計值。基數根據被存儲為整數的統計數據計數,所以即使對於小型表,該值也沒有必要是精確的。基數越大,當進行聯合時,MySQL使用該索引的機會就越大。
- Sub_part:若列只是被部分編入索引,則為被編入索引的字元的數目。若整列被編入索引,則為NULL。
- Packed:指示關鍵字如何被壓縮。若沒有被壓縮,則為NULL。
- Null:用於顯示索引列中是否包含NULL。若列含有NULL,則顯示為YES。若沒有,則該列顯示為NO。
- Index_type:顯示索引使用的類型和方法(BTREE、FULLTEXT、HASH、RTREE)。
- Comment:顯示評註。
索引刪除
drop index index_name on tbl_name
用戶和許可權
MySQL中用戶資訊都存儲在mysql這個庫的user表中。root用戶具有超級許可權,應盡量少用這個用戶,避免誤操作。
用戶創建
-- 創建一個用戶chen,密碼也是chen,只能在本地登錄
create user 'chen'@'localhost' identified by 'chen'
-- 創建一個用戶zhao,密碼也是zhao,不指定host的話在哪個網斷都能登陸
create user 'zhao' identified by 'zhao';
-- 修改用戶名,但是密碼不變
-- 查看原來用戶資訊
select * from mysql.user;
RENAME USER 'chen'@'localhost' TO 'chen_new'@'localhost';
-- 修改密碼
SET PASSWORD FOR 'chen_new'@'localhost' = PASSWORD('chen_new');
-- 使用mysqladmin將root的密碼改成root
mysqladmin -u root password 『root』
-- 刪除用戶
drop user 'chen_new'@'localhost';
許可權管理
-- 查看許可權
-- 如果查出來是USAGE ON *.* 表示這個用戶沒有任何許可權
SHOW GRANTS FOR 'root'@'localhost'
-- 用戶授權
-- 取消用戶許可權
事務和數據備份
事務
事務是資料庫中的一個操作單元,這些操作要麼全部成功要麼全部失敗,是一個不可分割的單位。
事務具有4個特性:原子性(Atomicity)、一致性(Consistency)、隔離性(Isolation)和持續性(Durability)。這4個特性簡稱為ACID特性。
- 原子性:事務必須是原子工作單元,事務中的操作要麼全部執行,要麼全都不執行,不能只完成部分操作。原子性在資料庫系統中,由恢復機制來實現。
- 一致性:事務開始之前,資料庫處於一致性的狀態;事務結束後,資料庫必須仍處於一致性狀態。資料庫一致性的定義是由用戶負責的。例如,在銀行轉賬中,用戶可以定義轉賬前後兩個賬戶金額之和保持不變。
- 隔離性:系統必須保證事務不受其他並發執行事務的影響,即當多個事務同時運行時,各事務之間相互隔離,不可互相干擾。事務查看數據時所處的狀態,要麼是另一個並發事務修改它之前的狀態,要麼是另一個並發事務修改它之後的狀態,事務不會查看中間狀態的數據。隔離性通過系統的並發控制機制實現。
- 持久性:一個已完成的事務對數據所做的任何變動在系統中是永久有效的,即使該事務產生的修改不正確,錯誤也將一直保持。持久性通過恢復機制實現,發生故障時,可以通過日誌等手段恢復資料庫資訊。
數據備份恢復
- 備份
-- 這種方式只能備份表的內容,但是不能備份表結構
select into file
-- 列子
select * from tbl_name into outfile 'D://file.txt';
- 數據恢復
-- 導入數據前需要先創建表結構
load data infile into tbl_name;
一些優化建議
- MySQL是用一系列的默認設置預先配置的,這些設置開始通常是很好的。但過一段時間後你可能需要調整記憶體分配、緩衝區大小等。(為查看當前設置,可使用SHOW VARIABLES;和SHOW STATUS)
- MySQL是一個多用戶多執行緒的DBMS,換言之,它經常同時執行多個任務。如果這些任務中的某一個執行緩慢,則所有請求都會執行緩慢。如果你遇到顯著的性能不良,可使用SHOW PROCESSLIST顯示所有活動進程(以及它們的執行緒ID和執行時間)。你還可以用KILL命令終結某個特定的進程(使用這個命令需要作為管理員登錄)。
- 總是有不止一種方法編寫同一條SELECT語句。應該試驗聯結、並、子查詢等,找出最佳的方法。
- 使用EXPLAIN語句讓MySQL解釋它將如何執行一條SELECT語句。
- 一般來說,存儲過程執行得比一條一條地執行其中的各條MySQL語句快。
- 應該總是使用正確的數據類型。
- 決不要檢索比需求還要多的數據。換言之,不要用SELECT 所有列(除非你真正需要每個列)。
- 有的操作(包括INSERT)支援一個可選的DELAYED關鍵字,如果使用它,將把控制立即返回給調用程式,並且一旦有可能就實際執行該操作。
- 在導入數據時,應該關閉自動提交。你可能還想刪除索引(包括FULLTEXT索引),然後在導入完成後再重建它們。
- 必須索引資料庫表以改善數據檢索的性能。確定索引什麼不是一件微不足道的任務,需要分析使用的SELECT語句以找出重複的WHERE和ORDER BY子句。如果一個簡單的WHERE子句返回結果所花的時間太長,則可以斷定其中使用的列(或幾個列)就是需要索引的對象。
- 你的SELECT語句中有一系列複雜的OR條件嗎?通過使用多條SELECT語句和連接它們的UNION語句,你能看到極大的性能改進。
- 索引改善數據檢索的性能,但損害數據插入、刪除和更新的性能。如果你有一些表,它們收集數據且不經常被搜索,則在有必要之前不要索引它們。(索引可根據需要添加和刪除。)
- LIKE很慢。一般來說,最好是使用FULLTEXT而不是LIKE。
- 資料庫是不斷變化的實體。一組優化良好的表一會兒後可能就面目全非了。由於表的使用和內容的更改,理想的優化和配置也會改變。
- 最重要的規則就是,每條規則在某些條件下都會被打破。

