【原創】ARM平台記憶體和cache對xenomai實時性的影響
1. 問題概述
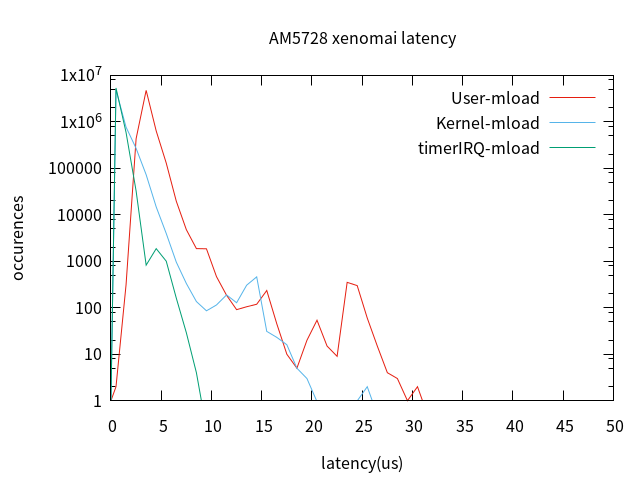
對ti am5728 xenomai系統latency測試時,在測試過程中發現,記憶體壓力對latency影響極大,未添加記憶體壓力下數據如下(註:文中所有測試使用默認gravity,對實時任務cpu已使用isolcpus=1隔離,另外文中的結論可能只對ARM平台有效):
stress -c 16 -i 4 -d 2 --hdd-bytes 256M
| user-task ltaency | kernel-task ltaency | TimerIRQ | |
|---|---|---|---|
| 最小值 | 0.621 | -0.795 | -1.623 |
| 平均值 | 3.072 | 0.970 | -0.017 |
| 最大值 | 16.133 | 12.966 | 7.736 |
添加參數--vm 2 --vm-bytes 128M模擬記憶體壓力。(創建2個進程模擬記憶體壓力,不斷重複:申請記憶體大小128MB,對申請的記憶體每隔4096位元組處寫入一個字元』Z『,然後讀取檢查是否還是』Z『,校查後釋放,回到申請操作)
stress -c 16 -i 4 -d 2 --hdd-bytes 256M --vm 2 --vm-bytes 128M
添加記憶體壓力後的latency,測試10分鐘(因時間原因未測1小時),測試數據如下:
| user-task ltaency | kernel-task ltaency | TimeIRQ | |
|---|---|---|---|
| 最小值 | 0.915 | -1.276 | -1.132 |
| 平均值 | 3.451 | 0.637 | 0.530 |
| 最大值 | 30.918 | 25.303 | 8.240 |
| 標準差 | 0.626 | 0.668 | 0.345 |
可以看到,添加記憶體壓力後,latency最大值是未加記憶體壓力最大值的2倍。
2. stress 記憶體壓力原理
stress工具對記憶體壓力相關參數有:
-m, –vm N fork N個進程對記憶體malloc()/free()
–vm-bytes B 每個進程操作的記憶體大小為B bytes (默認 256MB)
–vm-stride B 每隔B位元組訪問一個位元組 (默認4096)
–vm-hang N malloc睡眠N秒後free (默認不睡眠)
–vm-keep 僅分配一次記憶體,直到進程結束時釋放
這參數可用來模擬不同的壓力,--vm-bytes表示每次分配的記憶體大小。--vm-stride每隔B位元組訪問一個位元組,主要模擬cache miss的情況。--vm-hang指定對記憶體持有的時間,分配頻率。
對於上面參數--vm 2 --vm-bytes 128M ,表示創建2個進程模擬記憶體壓力,不斷重複:申請記憶體大小128MB,對申請的記憶體每隔4096位元組處寫入一個字元』Z『,然後讀取檢查是否還是』Z『,校查後釋放,回到申請操作。回顧我們的問題,其中涉及影響實時性的變數有:
(1).記憶體分配大小
(2).latency測試過程中stress是否分配/釋放記憶體
(3).記憶體是否使用訪問
(4).每次記憶體訪問的步長大小
進一步總結記憶體實時性影響因素有:
-
cache 影響
- cache miss率高
- 記憶體速率(頻寬)
-
記憶體管理
- 記憶體分配/釋放操作
- 記憶體訪問缺頁(MMU擁塞)
下面針對這幾個影響設計測試參數,進行測試排查。
2. cache 因素
關閉cache 可用於模擬100%快取未命中,從而測量可能由如記憶體匯流排和片外存儲器的擁塞引起的快取未命中的最壞情況的影響。
2.1 未加壓
am5728 這裡不測試L1 Cache的影響,主要測試L2 cache,配置內核關閉L2 cache,重新編譯內核。
System Type --->
[ ] Enable the L2x0 outer cache controller
為確認L2 cahe已經關閉,使用下面的程式驗證,申請大小為SIZE個int的記憶體,對記憶體里的整數加3,第一個for步長為1,第二個for步長為16(每個整數4位元組,16個64位元組,cacheline的大小剛好為64)。因為後面的for循環步長為16 ,在沒有cache 時,第二個for循環的執行時間應為第一個for的1/16,以此來驗證L2 Cache 已經關閉。
打開 L2 cache情況下前後兩個for的執行時間為2000ms:153ms(13倍),關閉 L2 cache後前後兩個for的執行時間為2618ms:153ms(17倍,大於16倍的原因是這裡使用的是同一塊記憶體,記憶體申請後沒有還沒分配物理記憶體,第一個for循環的時候會執行一些缺頁異常處理,所以用時稍長)。
#include<stdlib.h>
#include<stdio.h>
#include<time.h>
#define SIZE 64*1024*1024
int main(void)
{
struct timespec time_start,time_end;
int i;
unsigned long time;
int *buff =malloc(SIZE * sizeof(int));
clock_gettime(CLOCK_MONOTONIC,&time_start);
for (i = 0; i< SIZE; i ++) buff[i] += 3;//
clock_gettime(CLOCK_MONOTONIC,&time_end);
time = (time_end.tv_sec * 1000000000 + time_end.tv_nsec) - (time_start.tv_sec * 1000000000 + time_start.tv_nsec);
printf("1:%ldms ",time/1000000);
clock_gettime(CLOCK_MONOTONIC,&time_start);
for (i = 0; i< SIZE; i += 16 ) buff[i] += 3;//
clock_gettime(CLOCK_MONOTONIC,&time_end);
time = (time_end.tv_sec * 1000000000 + time_end.tv_nsec) - (time_start.tv_sec * 1000000000 + time_start.tv_nsec);
printf("64:%ldms\n",time/1000000);
free(buff);
return 0;
}
沒有壓力條件下,測試關閉L2 Cache前後latency情況(測試時間為10min),數據如下:
| L2 Cache ON | L2 Cache OFF | |
|---|---|---|
| min | -0.879 | 2.363 |
| avg | 1.261 | 4.174 |
| max | 8.510 | 13.161 |
由數據可以看出:關閉 L2Cache後,latency整體升高。在沒有壓力下,L2 Cahe 命中率高,提高程式碼執行效率,能夠明顯提升系統實時性,即同樣的一段程式碼,執行時間變短。
2.2 加壓(cpu/io)
不對記憶體加壓,僅測試CPU運算密集型任務及IO壓力下, L2 Cache關閉與否對latency的影響。加壓參數如下:
stress -c 16 -i 4
同樣測試10分鐘,數據如下:
| L2 ON | L2 OFF | |
|---|---|---|
| min | 0.916 | 1.174 |
| avg | 4.134 | 4.002 |
| max | 10.463 | 11.414 |
結論:CPU、IO壓力下,L2 Cache關閉與否似乎不那麼重要了
分析:
-
沒有加壓條件下,L2 cache處於空閑狀態,實時任務cache命中率高,latency 平均值所以低。當關閉L2 cache後,100% cache未命中,平均值和最大值均有升高。
-
添加 CPU、IO壓力後,18個計算進程搶奪cpu資源,對實時任務來說,當實時任務搶佔運行時,L2 Cache已被壓力計算任務的數據填滿,對實時任務來說幾乎100%未命中。所以 CPU、IO壓力下,L2 Cache關閉與否 latency差不多。
3. 記憶體管理因素
經過第2節的測試,壓力條件下有無 cache的latency 幾乎相同,可以排除Cache。下面進行測試記憶體分配/釋放、記憶體訪問缺頁(MMU擁塞)對latency的影響。
3.1 記憶體分配/釋放
在2的基礎上添加記憶體分配釋放壓力,分別測試對大小為1M、2M、4M、8M、16M、32M、64M、128M、256M的記憶體分配釋放操作下latency的數據,每次測試3分鐘,為測試MMU擁塞,分別對分配的記憶體進行步長為’1′ ’16’ ’32’ ’64’ ‘128’ ‘256’ ‘512’ ‘1024’ ‘2048’ ‘4096’的記憶體訪問,測試腳本如下:
#!/bin/bash
test_time=300 #5min
base_stride=1
VM_MAXSIZE=1024
STRIDE_MAXSIZE=('1' '16' '32' '64' '128' '256' '512' '1024' '2048' '4096')
trap 'killall stress' SIGKILL
for((vm_size = 64;vm_size <= VM_MAXSIZE; vm_size = vm_size * 2));do
for stride in ${STRIDE_MAXSIZE[@]};do
stress -c 16 -i 4 -m 2 --vm-bytes ${vm_size}M --vm-stride $stride &
echo "--------${vm_size}-${stride}------------"
latency -p 100 -s -g ${vm_size}-${stride} -T $test_time -q
killall stress >/dev/null
sleep 1
stress -c 16 -i 4 -m 2 --vm-bytes ${vm_size}M --vm-stride $stride --vm-keep &
echo "--------${vm_size}-${stride}-keep----------------"
latency -p 100 -s -g ${vm_size}-${stride}-keep -T $test_time -q
killall stress >/dev/null
sleep 1
stress -c 16 -i 4 -m 2 --vm-bytes ${vm_size}M --vm-stride $stride --vm-hang 2 &
echo "--------${vm_size}-${stride}-hang----------------"
latency -p 100 -s -g ${vm_size}-${stride}-hang -T $test_time -q
killall stress >/dev/null
sleep 1
done
done
L2 Cache打開,對不同大小記憶體進行分配釋放時的latency數據繪圖,橫軸為記憶體壓力任務每次申請的記憶體大小,縱軸為該壓力下的latency最大值,如下:
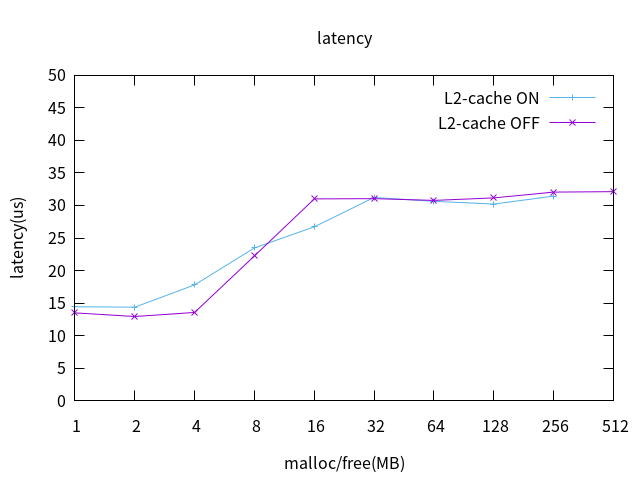
從上圖可以看到,兩個拐點分別為4MB,16MB ,分配/釋放的記憶體在4MB以內latency不受影響,保持正常水平,分配釋放的記憶體大於16MB時latency達到30us以上,與問題符合。由此可知:普通Linux任務的記憶體分配釋放會影響實時性。
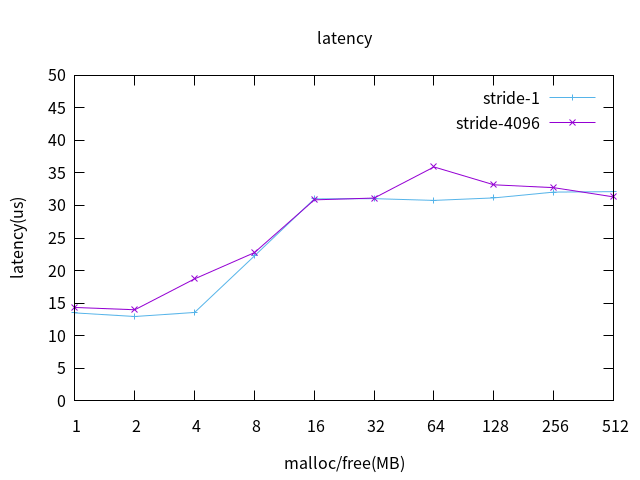
3.2 MMU擁塞
根據內核頁大小4K,在3.1的基礎 上添加參數–vm-stride 4096,來使stress每次訪問記憶體 都缺頁,來模擬MMU擁塞,L2 cache off 測試數據繪圖如下:
L2 cache on 測試數據繪圖如下:
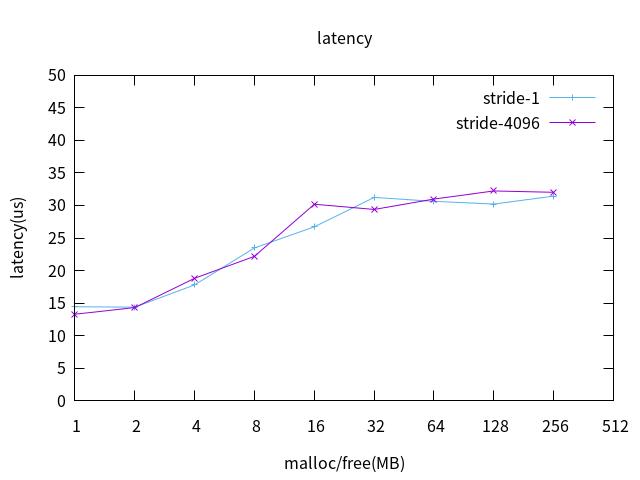
MMU擁塞對實時性幾乎沒有影響。
4 總結
通過分離各種影響因素後測試得出,施加記憶體壓力後,實時性變差是由於記憶體的分配釋放導致,說明該平台上運行在cpu0上的普通Linux任務對記憶體的申請釋放操作會影響運行在cpu1上的實時任務的實時性。
am5728隻有兩級cache, L2 Cache 在CPU空閑時能顯著提升實時性,但CPU負載過重時導致L2 Cache頻繁換入換出,不利於實時任務Cahe命中,幾乎對實時性沒有任何幫助。
更多資訊參考本部落格另一篇文章:有利於提高xenomai 實時性的一些配置建議


