MapReduce任務提交源碼分析
- 2019 年 11 月 13 日
- 筆記
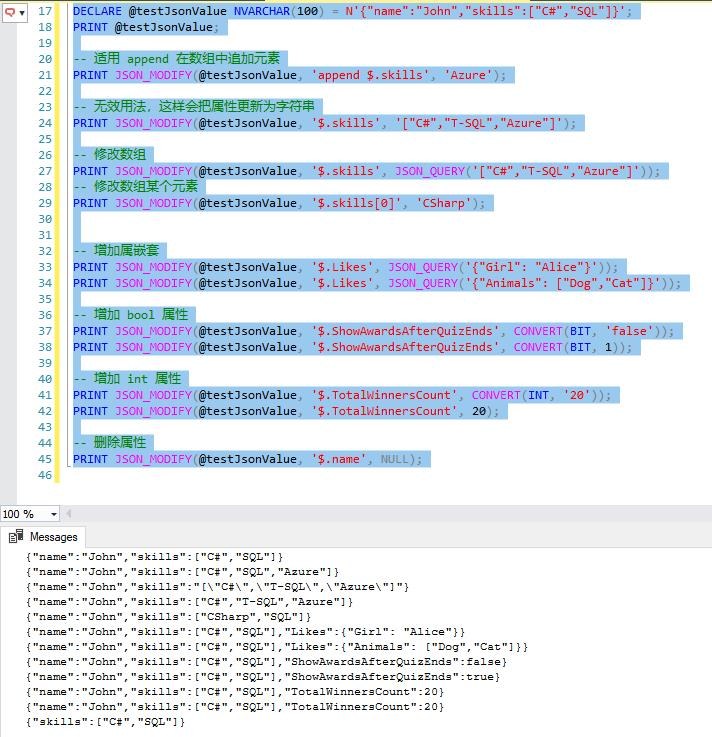
為了測試MapReduce提交的詳細流程。需要在提交這一步打上斷點:
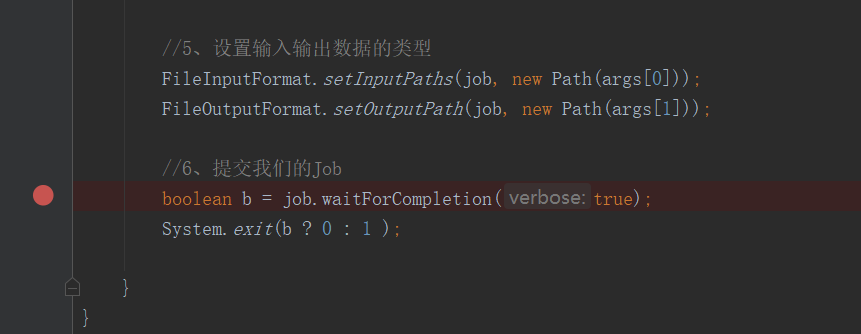
F7進入方法:
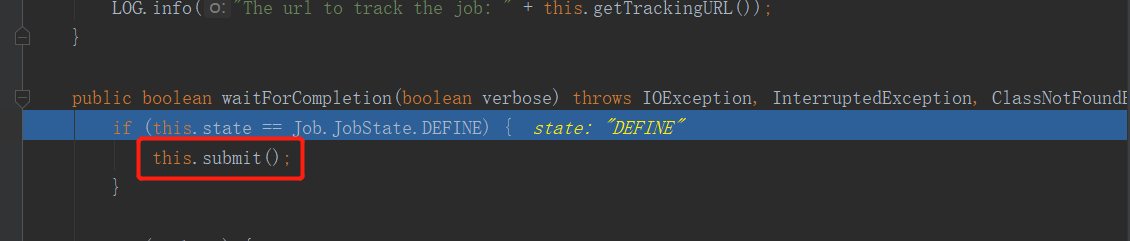
進入submit方法:
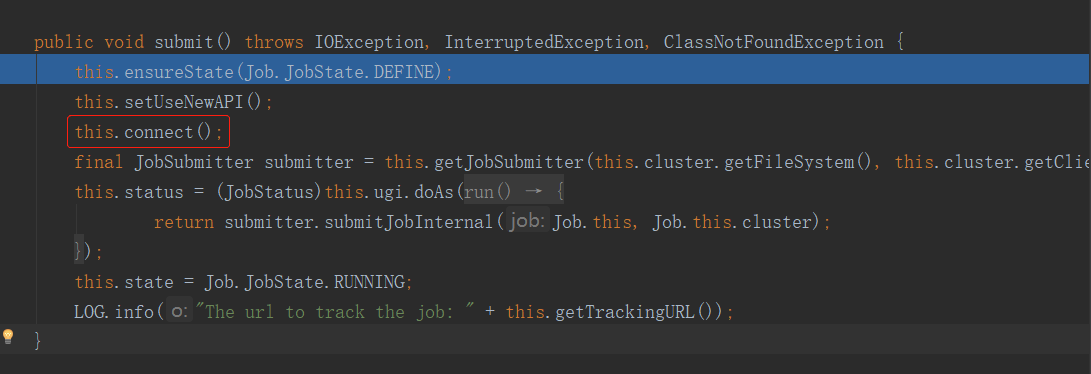
注意這個connect方法,它在連接誰呢?我們知道,Driver是作為客戶端存在的,那麼客戶端連接的應該就是Yarn集群,但是在這個簡單的WordCount案例中,並沒有將任務提交到Yarn集群,而是在本機中執行的。座椅這裡連接的自然就是本機。
進入這個connect方法,然後在裡面的Cluster方法上打上斷點:
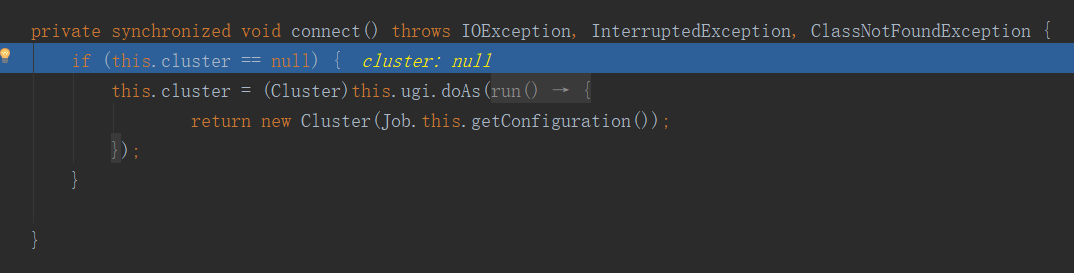
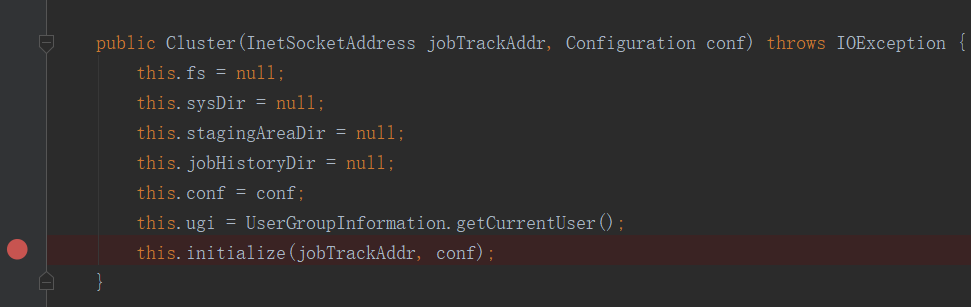
很明顯,這是一個構造器,他把集群抽象成了一個對象。進入此方法:
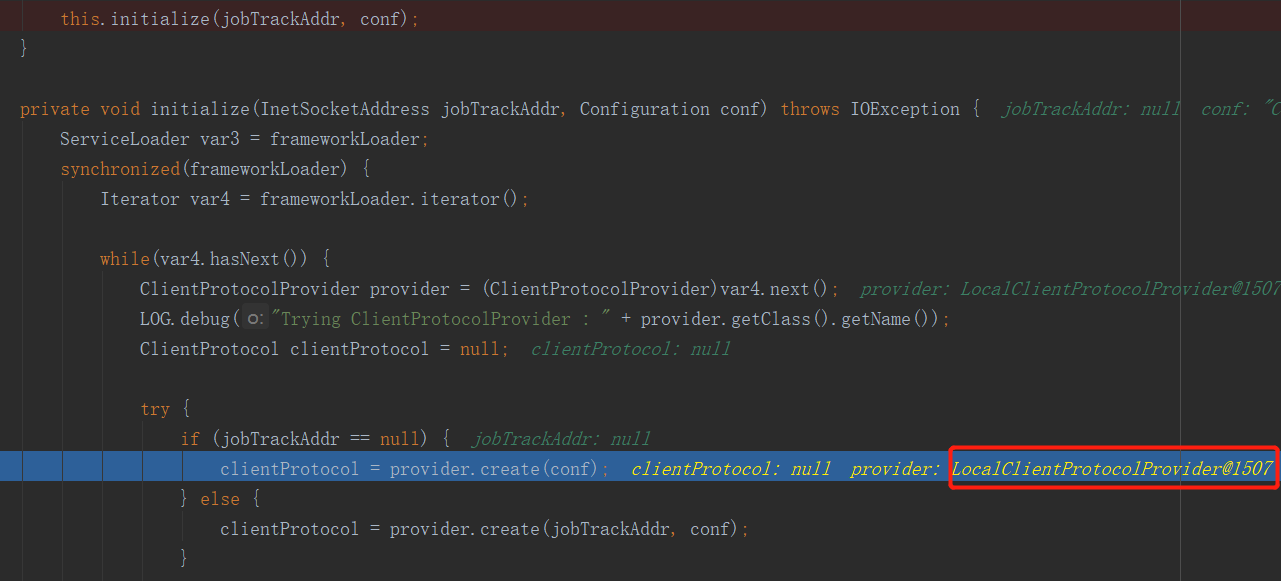
初始化了一個客戶端協議,進入這個create方法,看看他是如何初始化客戶端協議的:

注意這個mapreduce.framework.name,他就是mapred-site.xml文件中的mapreduce.framework.name項的值,由於我並沒有提交到集群上,而是在本機,所以他會載入本機的mapred-site.xml文件,但是我本機下的該文件並沒有像集群上那樣配置了mapred-site.xml文件,只有一份mapred-site.xml.template文件,更沒有mapreduce.framework.name這一項,所以上面程式碼中的值就默認為local了。
本機上的配置:
集群上的配置:

create方法最終反回了一個LocalJobRunner對象,如果上面的值是yarn,返回的則是YarnJobRunner。繼續往下:
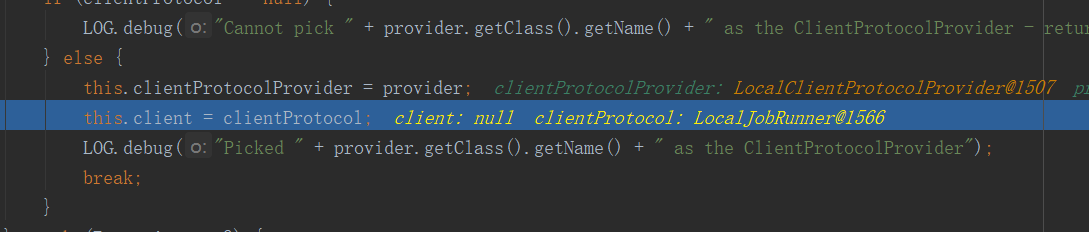
會發現這個LocalJobRunner就是客戶端。然後一直往下,直到完成connect方法,會發現整個過程中在connect方法中創建了一個Cluster對象,然後在Cluster對象裡面獲取到了客戶端。
緊接著,由於connect方法初始化了cluster對象,所以接下來創建了submitter對象,用於提交任務。進入submitJobInternal方法打上斷點

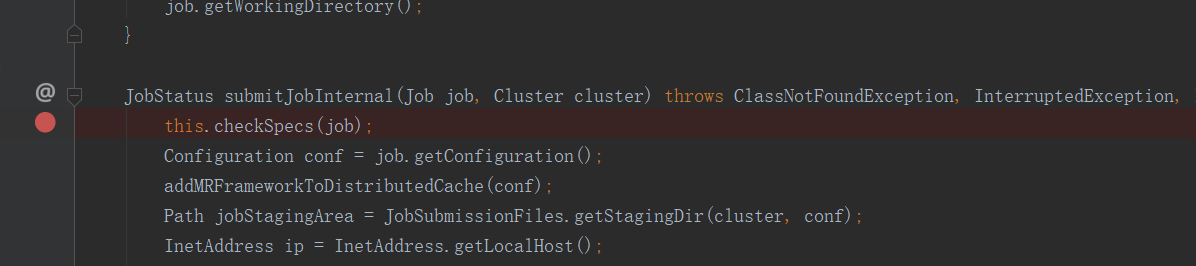
這個checkSpecs方法就是用來檢查路徑的,當輸入路徑不存在或輸出路徑已存在時會報錯。進入此方法後再進入內部方法就一目了然了:
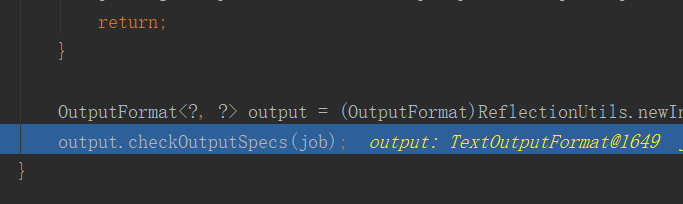
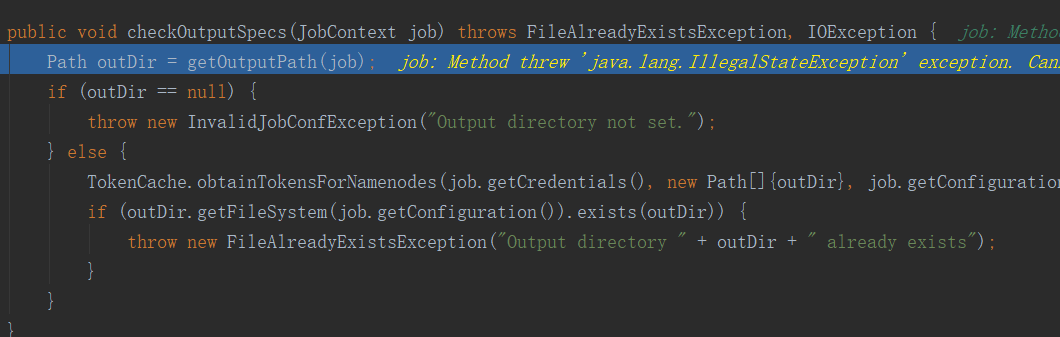
繼續往下執行,完成checkSpecs方法後完初始化一個路徑:

打開此路徑,此時還是空的文件夾:
繼續往下,隨後做了一些獲取IP和往配置文件中設置IP和hostname的操作:

繼續往下,隨後又在上面的路徑下隨機創建了一個目錄:

繼續往下,見到copyAndConfigureFiles時,進入此方法,然後在進入內部方法uploadFiles():

在uploadFiles方法中有,執行後的效果:
這個文件夾暫時不知道幹嘛的,只知道copyAndConfigureFiles方法創建了這個路徑。此方法執行完後,執行到writeSplits進入此方法:

這個方法是重點:切片是怎麼切的呢?
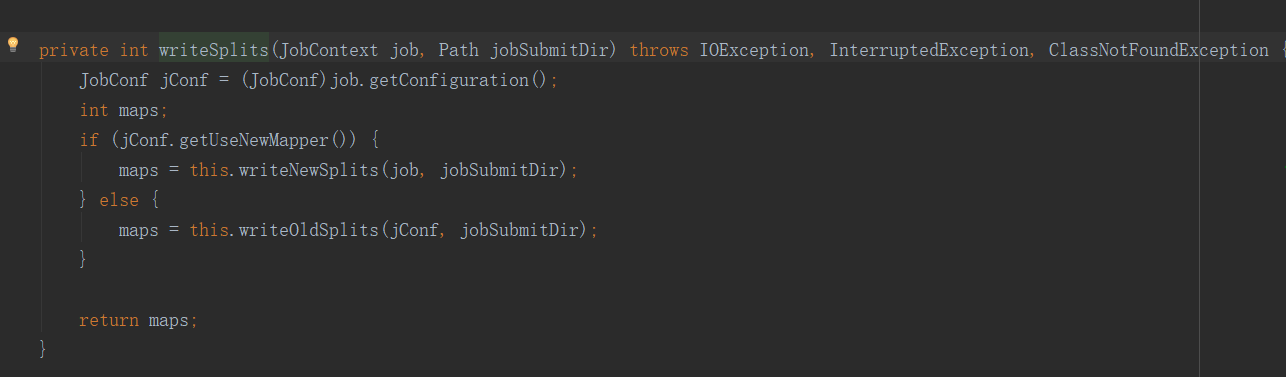
maps是int型,這表示這啟動的maptask的數量也該和切片的數量保持一致。而具體切成多少片呢?
上面的方法多態調用到子類的方法writeNewSplits,然後調用getSplits方法:

getSplits方法中有這樣一段:
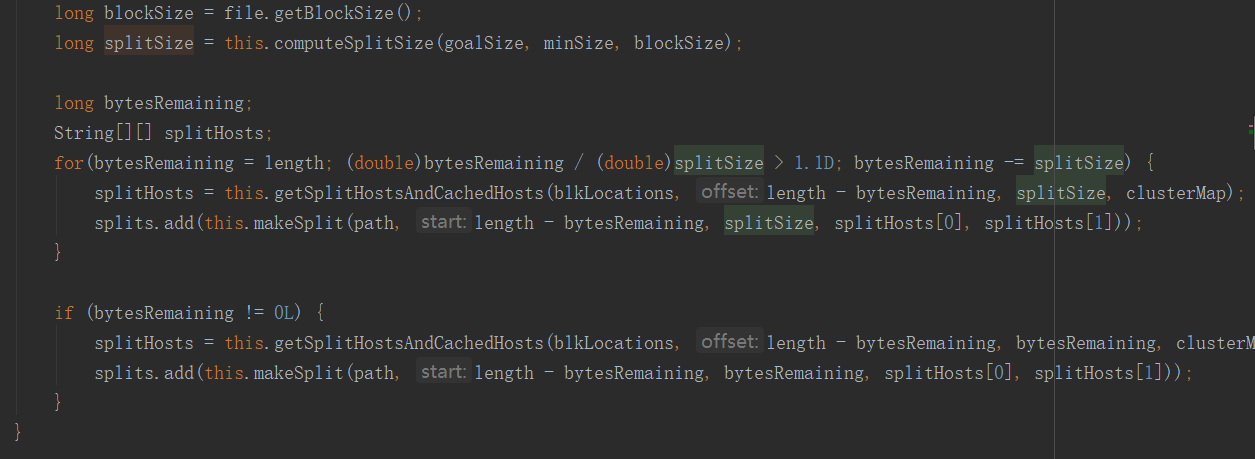
也就是說:當剩餘長度比切片尺寸大於1.1時,就會產生新的切片,比如說文件65m,splitSize為32m,第一片切到32m,剩餘33m,由於33/32<1.1,所以就不再切片,65m被切成兩片,0~32、32~65,而不是0~32 、 32~64 、 64~65三片。
當執行完writeSplits方法後,會在上面創建的目錄下生成幾個文件:
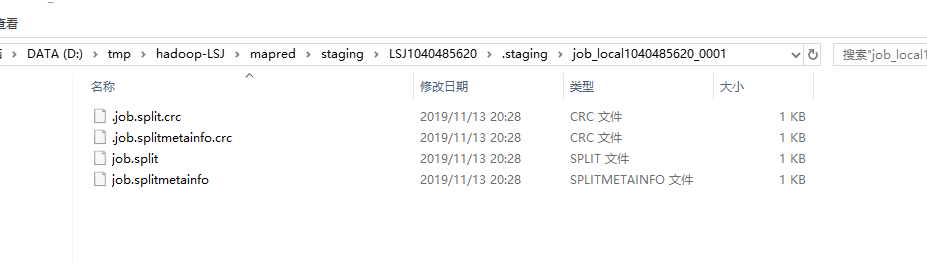
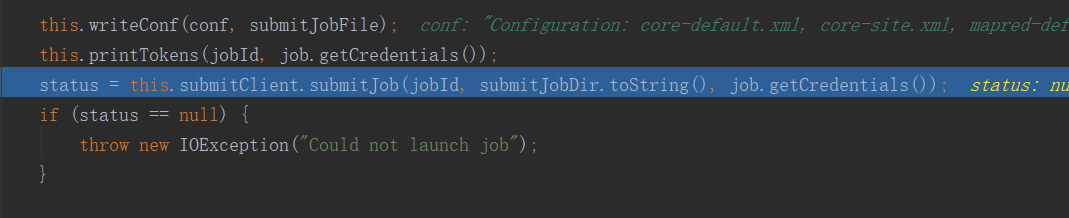
上面生成的文件中保存了“切片的規劃資訊”。繼續往下,當執行到writeConf方法後,會繼續在上面的目錄下生成與此Job相關的配置文件:
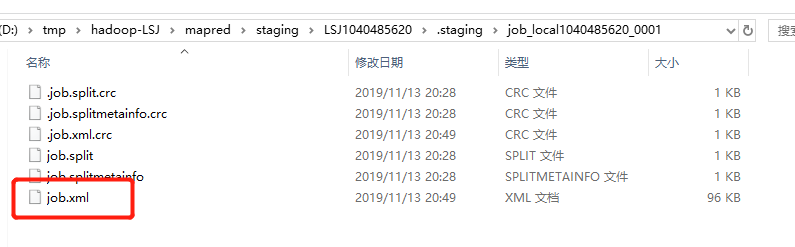
繼續執行,當執行完submitJob方法後,job本身(即WordCount程式本身會被打成jar包被提交)就被提交了:
但是由於我是直接在本地執行的,直接從main方法進來執行的,沒必要再打成jar包再從main方法進入,所以並不用提交,但是如果是是在yarn 上執行的時候,會把程式打成jar包放在上面的目錄下。
當任務執行完畢後,上面的目錄會被清空:
至此,整個任務的提交執行完成,試想一下,如果這個任務在Yarn上執行是什麼樣子呢?期待嗎邏輯不會變:
首先,還是執行connect方法,初始化到Cluster對象,然後創建JobRunner,不過在Yarn上執行的JobRunner就不是LocalJobRunner了,而是YarnJobRunner。執行完connect方法後會在HDFS文件系統創建一個路徑,其作用與上面創建的路徑相同,用於保存切片方案資訊和配置文件資訊,同時會將任務本身的jar包放入其中,最後任務執行完,這些內容又將被銷毀。