Python語言基礎04-函數和模組的使用
- 2019 年 11 月 13 日
- 筆記
本文收錄在Python從入門到精通系列文章系列
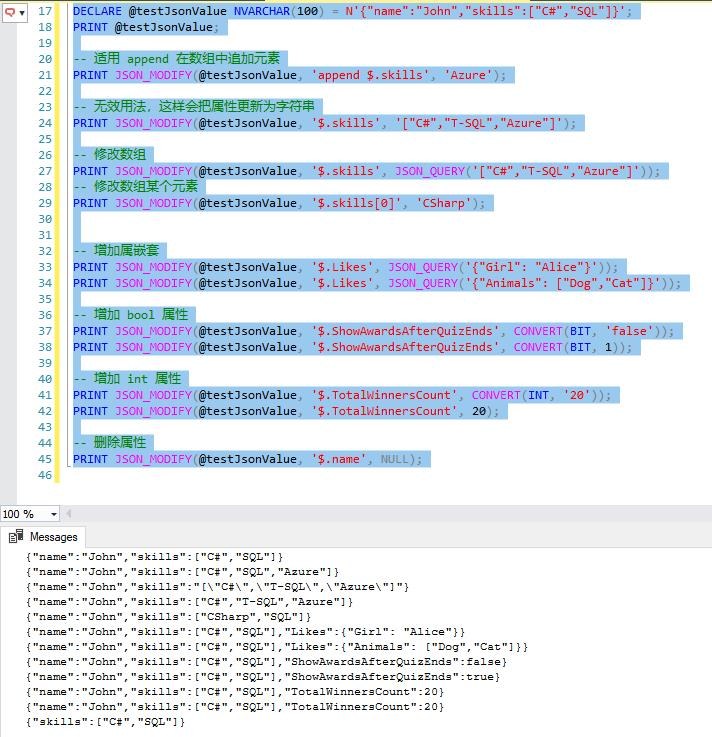
在分享本章節的內容之前,先來研究一道數學題,請說出下面的方程有多少組正整數解。
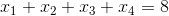
事實上,上面的問題等同於將8個蘋果分成四組每組至少一個蘋果有多少種方案。想到這一點問題的答案就呼之欲出了。
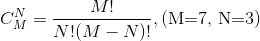
可以用Python的程式來計算出這個值,程式碼如下所示。
""" 輸入M和N計算C(M,N) Version: 0.1 Author: along """ m = int(input('m = ')) n = int(input('n = ')) fm = 1 for num in range(1, m + 1): fm *= num fn = 1 for num in range(1, n + 1): fn *= num fmn = 1 for num in range(1, m - n + 1): fmn *= num print(fm // fn // fmn)
輕鬆得出答案為:35
1. 函數的作用
不知道大家是否注意到,在上面的程式碼中,我們做了3次求階乘,這樣的程式碼實際上就是重複程式碼。編程大師Martin Fowler先生曾經說過:“程式碼有很多種壞味道,重複是最壞的一種!”,要寫出高品質的程式碼首先要解決的就是重複程式碼的問題。對於上面的程式碼來說,我們可以將計算階乘的功能封裝到一個稱之為“函數”的功能模組中,在需要計算階乘的地方,我們只需要“調用”這個“函數”就可以了。
1.1 定義函數
在Python中可以使用def關鍵字來定義函數,和變數一樣每個函數也有一個響亮的名字,而且命名規則跟變數的命名規則是一致的。在函數名後面的圓括弧中可以放置傳遞給函數的參數,這一點和數學上的函數非常相似,程式中函數的參數就相當於是數學上說的函數的自變數,而函數執行完成後我們可以通過return關鍵字來返回一個值,這相當於數學上說的函數的因變數。
在了解了如何定義函數後,我們可以對上面的程式碼進行重構,所謂重構就是在不影響程式碼執行結果的前提下對程式碼的結構進行調整,重構之後的程式碼如下所示。
def factorial(num): """求階乘""" result = 1 for i in range(1, num + 1): result *= i return result m = int(input('m = ')) n = int(input('n = ')) # 當需要計算階乘的時候不用再寫循環求階乘而是直接調用已經定義好的函數 print(factorial(m) // factorial(n) // factorial(m - n))
說明: Python的math模組中其實已經有一個factorial函數了,事實上要計算階乘可以直接使用這個現成的函數而不用自己定義。下面例子中的一些函數在Python中也都是現成的,我們這裡是為了講解函數的定義和使用才把它們又實現了一遍,實際開發中不建議做這種低級的重複性的工作。
2. 函數的參數
函數是絕大多數程式語言中都支援的一個程式碼的”構建塊”,但是Python中的函數與其他語言中的函數還是有很多不太相同的地方,其中一個顯著的區別就是Python對函數參數的處理。在Python中,函數的參數可以有默認值,也支援使用可變參數,所以Python並不需要像其他語言一樣支援函數的重載,因為我們在定義一個函數的時候可以讓它有多種不同的使用方式,下面是兩個小例子。
from random import randint def roll_dice(n=2): """搖色子""" total = 0 for _ in range(n): #print(_) total += randint(1, 6) #print(total) return total def add(a=0, b=0, c=0): """三個數相加""" return a + b + c # 如果沒有指定參數那麼使用默認值搖兩顆色子 print(roll_dice()) # 搖三顆色子 print(roll_dice(3)) print(add()) print(add(1)) print(add(1, 2)) print(add(1, 2, 3)) # 傳遞參數時可以不按照設定的順序進行傳遞 print(add(c=50, a=100, b=200))
我們給上面兩個函數的參數都設定了默認值,這也就意味著如果在調用函數的時候如果沒有傳入對應參數的值時將使用該參數的默認值,所以在上面的程式碼中我們可以用各種不同的方式去調用add函數,這跟其他很多語言中函數重載的效果是一致的。
2.1 函數的可變參數
其實上面的add函數還有更好的實現方案,因為我們可能會對0個或多個參數進行加法運算,而具體有多少個參數是由調用者來決定,我們作為函數的設計者對這一點是一無所知的,因此在不確定參數個數的時候,我們可以使用可變參數,程式碼如下所示。
# 在參數名前面的*表示args是一個可變參數 def add(*args): result = 0 for num in args: result += num return(result) # 在調用add函數時可以傳入0個或多個參數 print(add()) print(add(1)) print(add(1, 2)) print(add(1, 2, 3)) print(add(1, 3, 5, 7, 9))
3. 用模組管理函數
對於任何一種程式語言來說,給變數、函數這樣的標識符起名字都是一個讓人頭疼的問題,因為我們會遇到命名衝突這種尷尬的情況。最簡單的場景就是在同一個.py文件中定義了兩個同名函數,由於Python沒有函數重載的概念,那麼後面的定義會覆蓋之前的定義,也就意味著兩個函數同名函數實際上只有一個是存在的。
def foo(): print('hello, world!') def foo(): print('goodbye, world!') # 下面的程式碼會輸出什麼呢? foo()
當然上面的這種情況我們很容易就能避免,但是如果項目是由多人協作進行團隊開發的時候,團隊中可能有多個程式設計師都定義了名為foo的函數,那麼怎麼解決這種命名衝突呢?答案其實很簡單,Python中每個文件就代表了一個模組(module),我們在不同的模組中可以有同名的函數,在使用函數的時候我們通過import關鍵字導入指定的模組就可以區分到底要使用的是哪個模組中的foo函數,程式碼如下所示。
(1)先在同級目錄下,創建2個py文件
module1.py
def foo(): print('hello world')
module2.py
def foo(): print('goodbye world')
(2)直接使用模組使用函數
test.py
from module1 import foo foo() from module2 import foo foo()
(3)也可以按照如下所示的方式來區分到底要使用哪一個foo函數。
test.py
import module1 as m1 import module2 as m2 m1.foo() m2.foo()
(4)但是如果將程式碼寫成了下面的樣子,那麼程式中調用的是最後導入的那個foo,因為後導入的foo覆蓋了之前導入的foo。
test.py
from module1 import foo from module2 import foo foo() from module2 import foo from module1 import foo # 輸出hello, world! foo()
需要說明的是,如果我們導入的模組除了定義函數之外還中有可以執行程式碼,那麼Python解釋器在導入這個模組時就會執行這些程式碼,事實上我們可能並不希望如此,因此如果我們在模組中編寫了執行程式碼,最好是將這些執行程式碼放入如下所示的條件中,這樣的話除非直接運行該模組,if條件下的這些程式碼是不會執行的,因為只有直接執行的模組的名字才是”__main__”。
module3.py
def foo(): pass def bar(): pass # __name__是Python中一個隱含的變數它代表了模組的名字 # 只有被Python解釋器直接執行的模組的名字才是__main__ if __name__ == '__main__': print('call foo()') foo() print('call bar()') bar()
test.py
import module3 # 導入module3時 不會執行模組中if條件成立時的程式碼 因為模組的名字是module3而不是__main__
4. 練習
練習1
實現計算求最大公約數和最小公倍數的函數。
參考答案:
def gcd(x, y): """求最大公約數""" #(x, y) = (y, x) if x > y else (x, y) if x > y: (x, y) = (y, x) else: (x, y) for factor in range(x, 0, -1): if x % factor == 0 and y % factor == 0: return factor def lcm(x, y): """求最小公倍數""" return x * y // gcd(x, y) print(gcd(9,12)) print(lcm(9,12))
練習2
實現判斷一個數是不是迴文數的函數。
參考答案:
def is_palindrome(num): """ 判斷一個數是不是迴文數 迴文數是指將一個正整數從左往右排列和從右往左排列值一樣的數 """ temp = num total = 0 while temp > 0: total = total * 10 + temp % 10 temp //= 10 return total == num
練習3
實現判斷一個數是不是素數的函數。
參考答案:
def is_prime(num): """判斷一個數是不是素數""" for factor in range(2, num): if num % factor == 0: return False return True if num != 1 else False print(is_prime(1))
練習4
寫一個程式判斷輸入的正整數是不是迴文素數。
參考答案:
if __name__ == '__main__': num = int(input('請輸入正整數: ')) if is_palindrome(num) and is_prime(num): print('%d是迴文素數' % num) else: print('%d不是迴文素數' % num)
注意:通過上面的程式可以看出,當我們將程式碼中重複出現的和相對獨立的功能抽取成函數後,我們可以組合使用這些函數來解決更為複雜的問題,這也是我們為什麼要定義和使用函數的一個非常重要的原因。
5. 變數作用域
(1)最後,我們來討論一下Python中有關變數作用域的問題
def foo(): b = 'hello' # Python中可以在函數內部再定義函數 def bar(): c = True print(a) print(b) print(c) bar() # print(c) # NameError: name 'c' is not defined if __name__ == '__main__': a = 100 # print(b) # NameError: name 'b' is not defined foo()
上面的程式碼能夠順利的執行並且列印出100、hello和True,但我們注意到了,在bar函數的內部並沒有定義a和b兩個變數,那麼a和b是從哪裡來的。
我們在上面程式碼的if分支中定義了一個變數a,這是一個全局變數(global variable),屬於全局作用域,因為它沒有定義在任何一個函數中。在上面的foo函數中我們定義了變數b,這是一個定義在函數中的局部變數(local variable),屬於局部作用域,在foo函數的外部並不能訪問到它;但對於foo函數內部的bar函數來說,變數b屬於嵌套作用域,在bar函數中我們是可以訪問到它的。bar函數中的變數c屬於局部作用域,在bar函數之外是無法訪問的。事實上,Python查找一個變數時會按照“局部作用域”、“嵌套作用域”、“全局作用域”和“內置作用域”的順序進行搜索(由小到大),前三者我們在上面的程式碼中已經看到了,所謂的“內置作用域”就是Python內置的那些標識符,我們之前用過的input、print、int等都屬於內置作用域。
其中,在foo函數中調用bar函數的變數c,會報錯;因為讀不到此變數。
(2)再看看下面這段程式碼,我們希望通過函數調用修改全局變數a的值,但實際上下面的程式碼是做不到的。
def foo(): a = 200 print(a) # 200 if __name__ == '__main__': a = 100 foo() print(a) # 100
在調用foo函數後,我們發現a的值仍然是100,這是因為當我們在函數foo中寫a = 200的時候,是重新定義了一個名字為a的局部變數,它跟全局作用域的a並不是同一個變數,因為局部作用域中有了自己的變數a,因此foo函數不再搜索全局作用域中的a。
(3)如果我們希望在foo函數中修改全局作用域中的a,程式碼如下所示。
def foo(): global a a = 200 print(a) # 200 if __name__ == '__main__': a = 100 foo() print(a) # 200
我們可以使用global關鍵字來指示foo函數中的變數a來自於全局作用域,如果全局作用域中沒有a,那麼下面一行的程式碼就會定義變數a並將其置於全局作用域。
同理,如果我們希望函數內部的函數能夠修改嵌套作用域中的變數,可以使用nonlocal關鍵字來指示變數來自於嵌套作用域,請大家自行試驗。
在實際開發中,我們應該盡量減少對全局變數的使用,因為全局變數的作用域和影響過於廣泛,可能會發生意料之外的修改和使用,除此之外全局變數比局部變數擁有更長的生命周期,可能導致對象佔用的記憶體長時間無法被垃圾回收。事實上,減少對全局變數的使用,也是降低程式碼之間耦合度的一個重要舉措,同時也是對迪米特法則的踐行。減少全局變數的使用就意味著我們應該盡量讓變數的作用域在函數的內部,但是如果我們希望將一個局部變數的生命周期延長,使其在定義它的函數調用結束後依然可以使用它的值,這時候就需要使用閉包,這個我們在後續的內容中進行講解。
說明: 很多人經常會將“閉包”和“匿名函數”混為一談,但實際上它們並不是一回事,如果想了解這個概念,可以看看維基百科的解釋。
說了那麼多,其實結論很簡單,從現在開始我們可以將Python程式碼按照下面的格式進行書寫,這一點點的改進其實就是在我們理解了函數和作用域的基礎上跨出的巨大的一步。
def main(): # Todo: Add your code here pass if __name__ == '__main__': main()