Java並發學習筆記
日常學習筆記
會的越多,不會的越多
戒浮戒躁,腳踏實地
記錄和東哥、小海海、小燦燦一起奮鬥的日子
java並發編程實踐
01 | 可見性、原子性和有序性問題:並發編程Bug的源頭
筆記
- 並發編程的三個問題
- 原子性 -> 一個操作是不可中斷的,要麼全部執行成功要麼全部執行失敗。
- 指令級別語義:CPU單個指令一定是原子性的。
- java語言語義:java中一個指令不代表是具備原子性的。java指令是對CPU指令的封裝。(1 – n)
- 有序性 -> 程式按照程式碼順序有序執行
- 編譯期優化:在java編譯期,JVM認為改變指令順序不會影響結果的場景中(不違反happens-before),會進行編譯期的指令重排
- CPU指令重排:為了解決MESI協議導致的CPU空閑,引入了指令重排機制。大大提高了CPU的利用率
- 可見性 -> 當前執行緒對共享變數的修改,對其它執行緒立即可見
- JMM語義:在JMM中執行緒對共享變數的修改對其它執行緒立即可見。
- CPU語義:一個內核對L1/l2快取的M(modify)操作對其它S(share)該變數的內核可見。
- 可見性問題的根本來源:指令重排導致的CPU指令亂序執行。最終根源
- Store Buffere
- Invalidte Queue
- 可見性問題的根本來源:指令重排導致的CPU指令亂序執行。最終根源
- 原子性 -> 一個操作是不可中斷的,要麼全部執行成功要麼全部執行失敗。
金句
在採用一項技術的同時,一定要清楚它帶來的問題是什麼,以及如何規避
舉個例子,我們為了對系統實施監控,會引入例如pinpoint之類的AMP組件,解決了監控問題
的同時也帶來了性能問題,比如對頻寬的佔用,增加了介面響應的延時等;再比如,微服務
架構是為了解決單體應用靈活性差等問題而出現,同時也帶了了架構的複雜度,增加了服務
之間通訊,數據隔離等問題。所以,一個技術在解決某個問題的同時可能帶來新的問題,這樣
我們可能又會為新的問題引入別的技術來處理,這是個不斷循環的過程。因此,我們在評估
一項技術的時候,需要充分考慮其負面影響,怎麼權衡利弊,實現利益最大化。
CPU –> 三級快取 –> MESI協議 –> 指令重排
02 | Java記憶體模型:看Java如何解決可見性和有序性問題
筆記
- java記憶體模型
- JMM是JVM兼容不同的CPU架構的基礎。為了屏蔽底層硬體的差異,向開發者提供統一的介面,故誕生了JMM
- JMM只是規範,JMM只是規範,JMM只是規範
- JVM對JMM的實現,才是常見的堆、棧、方法區等一些耳熟能詳的名詞
- 可見性、有序性的根本解決方案
- 程式設計師:對CPU快取、編譯器等按需禁用快取以及編譯優化
- 方法:volatile/synchronized/final
- 以上三種方法是java提供給程式設計師「按需」禁止快取及編譯優化的手段。
- 方法:volatile/synchronized/final
- JVM:happens-before原則
在JVM可預見的場景中禁止CPU快取、編譯器優化- 程式次序規則
- 在一個執行緒中,前面的操作總是對後面操作可見
- 鎖定規則
- 一個unlock操作先行發生於後面對這個鎖的lock操作(先釋放,才能加鎖)
- 傳遞性規則
- A happens-before B B happens-before C 則 A happens-before C (以前理解不到位)
class VolatileExample { int x = 0; volatile boolean v = false; public void writer() { x = 42; v = true; } public void reader() { if (v == true) { // 這裡x會是多少呢? } } } - 執行緒start規則
- start前的操作,總是對被start的操作可見。它是指主執行緒 A 啟動子執行緒 B 後,子執行緒 B 能夠看到主執行緒在啟動子執行緒 B 前的操作。
Thread B = new Thread(()->{ // 主執行緒調用B.start()之前 // 所有對共享變數的修改,此處皆可見 // 此例中,var==77 }); // 此處對共享變數var修改 var = 77; // 主執行緒啟動子執行緒 B.start(); - 執行緒 join() 規則
- 這條是關於執行緒等待的。它是指主執行緒 A 等待子執行緒 B 完成(主執行緒 A 通過調用子執行緒 B 的 join() 方法實現),
當子執行緒 B 完成後(主執行緒 A 中 join() 方法返回),主執行緒能夠看到子執行緒的操作。當然所謂的「看到」,指的是對共享變數的操作。
Thread B = new Thread(()->{ // 此處對共享變數var修改 var = 66; }); // 例如此處對共享變數修改, // 則這個修改結果對執行緒B可見 // 主執行緒啟動子執行緒 B.start(); B.join() // 子執行緒所有對共享變數的修改 // 在主執行緒調用B.join()之後皆可見 // 此例中,var==66 - 這條是關於執行緒等待的。它是指主執行緒 A 等待子執行緒 B 完成(主執行緒 A 通過調用子執行緒 B 的 join() 方法實現),
- 程式次序規則
- 程式設計師:對CPU快取、編譯器等按需禁用快取以及編譯優化
理解
- 文中的禁用CPU快取,更深層次的理解見
- store buffer
- Invalidate Queue
- volatile/synchronized/final等是java提供給程式設計師禁止指令重排和禁用快取的工具
- CPU為了提高利用率需要指令重排,但是在一些場景中指令重排會導致一些意想不到的錯誤。這時候需要程式設計師來發現問題並給出了解決問題的手段
- 重點理解JMM是一種規範、不能混淆JVM對JMM的實現
03 | 互斥鎖(上):解決原子性問題
筆記
- 原子性問題到底該如何解決呢
- 原子性問題的源頭是執行緒切換,如果能夠禁用執行緒切換那不就能解決這個問題了嗎?而作業系統做執行緒切換是依賴 CPU 中斷的,所以禁止 CPU 發生中斷就能夠禁止執行緒切換。
- 同一時刻只有一個執行緒執行」這個條件非常重要,我們稱之為互斥。如果我們能夠保證對共享變數的修改是互斥的,那麼,無論是單核 CPU 還是多核 CPU,就都能保證原子性了。
- synchronized
- synchronized屬於重量級鎖,性能不高,在鎖競爭激烈的場所不建議使用
- synchronized好處在於簡單易用,絕對不會unlock
- 鎖和受保護資源的關係
- 受保護資源和鎖之間的關聯關係是 N:1 的關係
重點
- synchronized鎖膨脹過程
- synchronized 對象頭 monitor
- long類型的並發讀寫問題(long64位 — 32位作業系統)
金句
單核時代通過控制執行緒的切花就可以保證原子性,但是在多核時代,單純的控制執行緒切換是無法保證原子性的,需要通過鎖的互斥來
保證高並發場景下的原子性。
04 | 互斥鎖(下):如何用一把鎖保護多個資源
筆記
- 保護沒有關聯關係的多個資源
- 用不同的鎖對受保護資源進行精細化管理,能夠提升性能。這種鎖還有個名字,叫細粒度鎖
- 保護有關聯關係的多個資源
- 鎖能覆蓋所有受保護資源
- 對象鎖無法解決這個問題,因為會產生,我家的鎖鎖住別人家的資源的情況
- 正確姿勢是採用類鎖(性能有待優化)
理解
- 以前沒考慮過也沒遇到過 同一把鎖管理多個資源的情況,以後在用鎖的場景需要注意。
05 | 一不小心就死鎖了,怎麼辦
筆記
- 死鎖的專業定義
一組執行緒因為競爭共享資源而陷入互相等待,導致「永久」阻塞的現象。class Account { private int balance; // 轉賬 void transfer(Account target, int amt){ // 鎖定轉出賬戶 synchronized(this){ //① // 鎖定轉入賬戶 synchronized(target){ //② if (this.balance > amt) { this.balance -= amt; target.balance += amt; } } } } } - 在現實中尋找答案
我們試想在古代,沒有資訊化,賬戶的存在形式真的就是一個賬本,而且每個賬戶都有一個賬本,這些賬本都統一存放在文件架上。銀行櫃員在給我們做轉賬時,要去文件架上把轉出賬本和轉入賬本都拿到手,然後做轉賬- 文件架上恰好有轉出賬本和轉入賬本,那就同時拿走;
- 如果文件架上只有轉出賬本和轉入賬本之一,那這個櫃員就先把文件架上有的賬本拿到手,同時等著其他櫃員把另外一個賬本送回來;
- 轉出賬本和轉入賬本都沒有,那這個櫃員就等著兩個賬本都被送回來。
死鎖產生
同一時刻A櫃員拿到了入賬賬本,B櫃員拿到了出賬賬本,A等待出賬賬本,B等待入賬賬本。AB櫃員就會陷入「永久」等待。這就是死鎖。
- 粗粒度鎖
解決上述問題,可以採用粗粒度鎖,也就是類鎖,但是類鎖帶來的是性能問題。 - 細粒度鎖
- 優點:使用細粒度鎖可以提高並行度,是性能優化的有效手段。
- 風險:機會和風險是並存的。細粒度鎖可能導致死鎖。
- 如何預防死鎖
解決死鎖最好的辦法是預防死鎖,將其扼殺在搖籃里。- 產生死鎖的四個條件
- 互斥,共享資源X和Y只能被一個執行緒佔用
- 佔有且等待,執行緒T1佔有X資源,在等待資源Y的同時,不釋放資源X。
- 不可搶佔,其他執行緒不能強行搶佔執行緒T1佔有的資源
- 循環等待,執行緒T1等待執行緒T2佔有的資源,執行緒T2等待執行緒T1佔有的資源,就是循環等待
- 解決死鎖的思路就很簡單了,就是破壞以上一個條件就不會造成死鎖
- 破壞佔用且等待條件:一次性申請所有的資源
- example:不允許櫃員直接在文件架上拿賬本,而是增加管理員,櫃員拿賬本需要通過管理員來審核。比如,A櫃員需要拿進賬
管理員發現文件架上沒有出賬賬本,所以不允許櫃員只拿進賬賬本。這樣就解決了佔用且等待問題。
- example:不允許櫃員直接在文件架上拿賬本,而是增加管理員,櫃員拿賬本需要通過管理員來審核。比如,A櫃員需要拿進賬
- 破壞不可搶佔條件:核心是要能夠主動釋放它佔有的資源
- 這一點 synchronized 是做不到的。因為synchronized一旦申請不到資源就會進入阻塞狀態
進入阻塞態就以為什麼也幹不了,也釋放不了執行緒佔用的資源。 - ReetrentLock 可以解決這個問題
- 這一點 synchronized 是做不到的。因為synchronized一旦申請不到資源就會進入阻塞狀態
- 破壞循環等待條件:對資源排序,然後按序申請資源
- 我們假設每個賬戶都有不同的屬性 id,這個 id 可以作為排序欄位,申請的時候,我們可以按照從小到大的順序來申請
class Account { private int id; private int balance; // 轉賬 void transfer(Account target, int amt){ Account left = this; //① Account right = target; //② if (this.id > target.id) { //③ left = target; //④ right = this; //⑤ } //⑥ // 鎖定序號小的賬戶 synchronized(left){ // 鎖定序號大的賬戶 synchronized(right){ if (this.balance > amt){ this.balance -= amt; target.balance += amt; } } } } }
- 破壞佔用且等待條件:一次性申請所有的資源
- 產生死鎖的四個條件
金句
當我們在編程世界裡遇到問題時,應不局限於當下,可以換個思路,向現實世界要答案,利用現實世界的模型來構思解決方案,
這樣往往能夠讓我們的方案更容易理解,也更能夠看清楚問題的本質。
用細粒度鎖來鎖定多個資源時,要注意死鎖的問題。這個就需要你能把它強化為一個思維定勢,遇到這種場景,
馬上想到可能存在死鎖問題。當你知道風險之後,才有機會談如何預防和避免,因此,識別出風險很重要
我們在選擇具體方案的時候,還需要評估一下操作成本,從中選擇一個成本最低的方案。
收穫
while(true)循環是不是應該有個timeout,避免一直阻塞下去?
加超時在項目中非常實用。
06 | 用「等待-通知」機制優化循環等待
筆記
- 問題:05中破壞佔用且等待條件,while循環會浪費CPU資源
// 一次性申請轉出賬戶和轉入賬戶,直到成功 while(!actr.apply(this, target)){...};當並發衝突增加,可能上述while循環會循環上萬次,浪費CPU資源
- 方案:等待-通知機制
- 05中解決佔用且等待條件,其實根本原因在於所有執行緒都在盲目申請,而不是等到「機會」合適的時候再申請。所謂來得早不如來得巧
- 使用 synchronized, wait(), notify(), notifyAll()實現等待-通知機制
- 這個等待隊列和互斥鎖是一對一的關係,每個互斥鎖都有自己獨立的等待隊列
- notify() 只能保證在通知時間點,條件是滿足的。而被通知執行緒的執行時間點和通知的時間點基本上不會重合,所以當執行緒執行的時候,很可能條件已經不滿足了(保不齊有其他執行緒插隊)
//單例
class Allocator {
private List<Object> als;
// 一次性申請所有資源
synchronized void apply(
Object from, Object to){
// 經典寫法 範式
while(als.contains(from) ||
als.contains(to)){
try{
wait();
}catch(Exception e){
}
}
als.add(from);
als.add(to);
}
// 歸還資源
synchronized void free(
Object from, Object to){
als.remove(from);
als.remove(to);
notifyAll();
}
}
//測試方法
public class Test{
public void test(){
//加鎖
allocator.apply(from, to);
//TODO ...
//釋放鎖
allocator.free();
}
}
收穫
- 盡量使用notifyAll
- notify() 是會隨機地通知等待隊列中的一個執行緒,而 notifyAll() 會通知等待隊列中的所有執行緒。從感覺上來講,應該是 notify() 更好一些,因為即便通知所有執行緒,也只有一個執行緒能夠進入臨界區。但那所謂的感覺往往都蘊藏著風險,實際上使用 notify() 也很有風險,它的風險在於可能導致某些執行緒永遠不會被通知到。
假設我們有資源 A、B、C、D,執行緒 1 申請到了 AB,執行緒 2 申請到了 CD,此時執行緒 3 申請 AB,會進入等待隊列(AB 分配給執行緒 1,執行緒 3 要求的條件不滿足),執行緒 4 申請 CD 也會進入等待隊列。我們再假設之後執行緒 1 歸還了資源 AB,如果使用 notify() 來通知等待隊列中的執行緒,有可能被通知的是執行緒 4,但執行緒 4 申請的是 CD,所以此時執行緒 4 還是會繼續等待,而真正該喚醒的執行緒 3 就再也沒有機會被喚醒了。所以除非經過深思熟慮,否則盡量使用 notifyAll()。
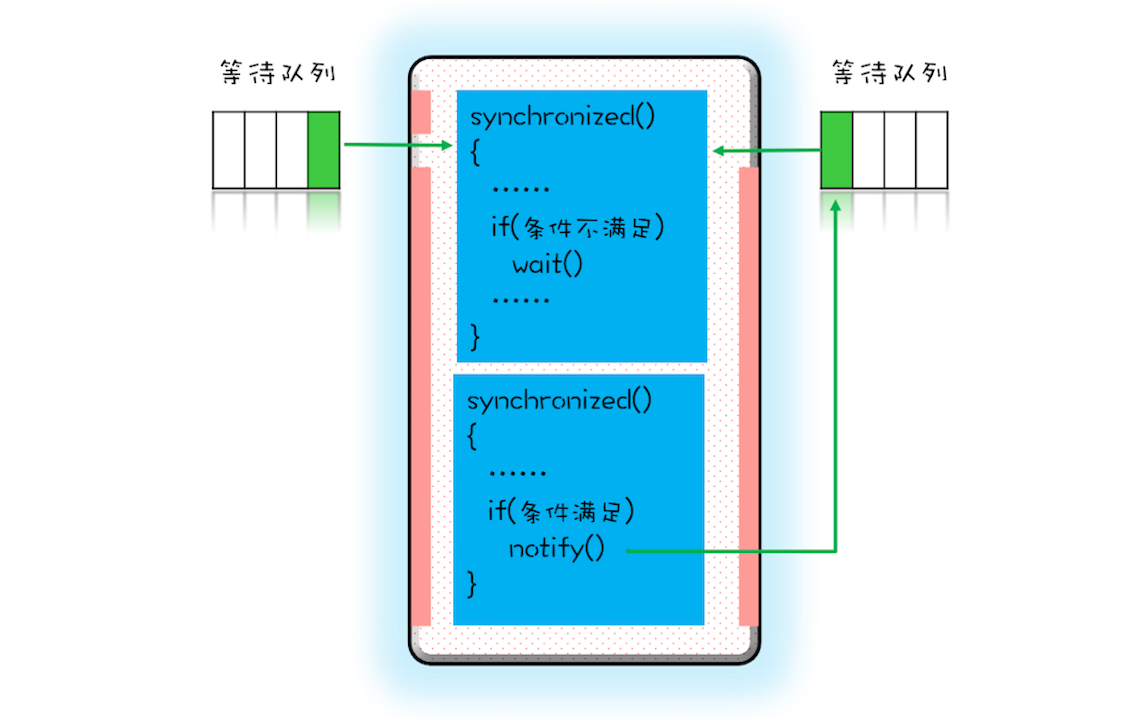
notify工作原理圖
- notify() 是會隨機地通知等待隊列中的一個執行緒,而 notifyAll() 會通知等待隊列中的所有執行緒。從感覺上來講,應該是 notify() 更好一些,因為即便通知所有執行緒,也只有一個執行緒能夠進入臨界區。但那所謂的感覺往往都蘊藏著風險,實際上使用 notify() 也很有風險,它的風險在於可能導致某些執行緒永遠不會被通知到。
- 每個互斥鎖都有各自獨立的等待池
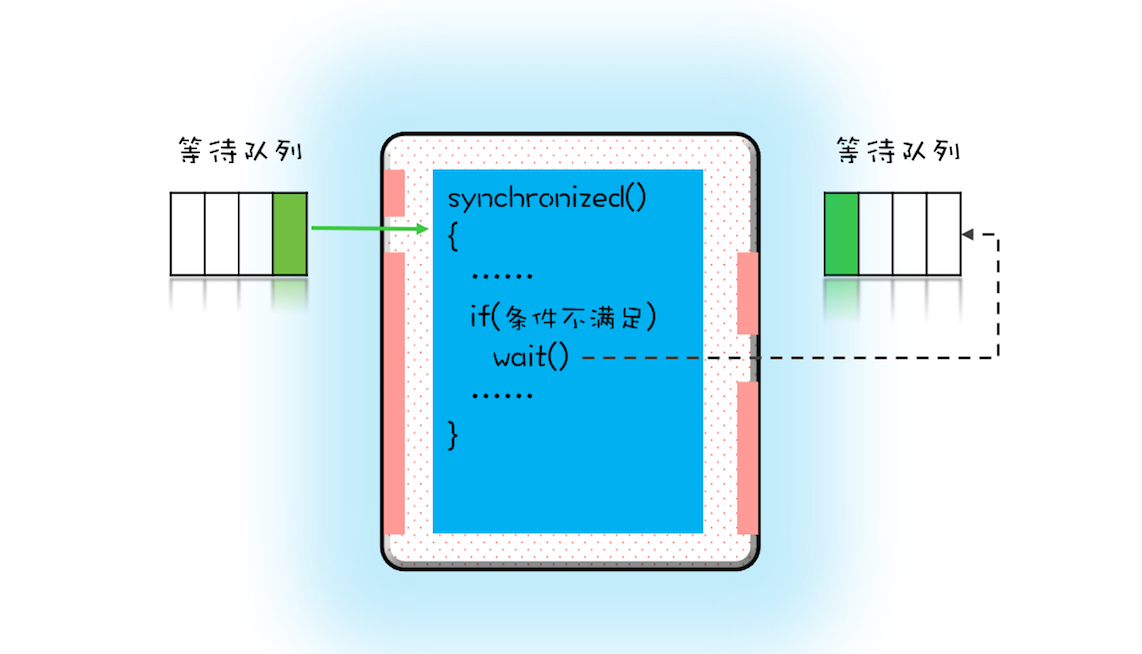
- wait和sleep的區別
wait()方法與sleep()方法的不同之處在於,wait()方法會釋放對象的「鎖標誌」。當調用某一對象的wait()方法後,會使當前執行緒暫停執行,並將當前執行緒放入對象等待池中,直到調用了notify()方法後,將從對象等待池中移出任意一個執行緒並放入鎖標誌等待池中,只有鎖標誌等待池中的執行緒可以獲取鎖標誌,它們隨時準備爭奪鎖的擁有權。當調用了某個對象的notifyAll()方法,會將對象等待池中的所有執行緒都移動到該對象的鎖標誌等待池。
sleep()方法需要指定等待的時間,它可以讓當前正在執行的執行緒在指定的時間內暫停執行,進入阻塞狀態,該方法既可以讓其他同優先順序或者高優先順序的執行緒得到執行的機會,也可以讓低優先順序的執行緒得到執行機會。但是sleep()方法不會釋放「鎖標誌」,也就是說如果有synchronized同步塊,其他執行緒仍然不能訪問共享數據。- wait釋放鎖
- sleep不釋放鎖


07 | 安全性、活躍性以及性能問題
筆記
- 並發編程的問題
- 微觀上:原子性、可見性、有序性
- 宏觀上:安全性、活躍性、性能
- 安全性問題
- 理論知識
- 什麼是執行緒安全?本質上就是正確性:程式按照我們的期望執行
- 理論上執行緒安全的程式就是要避免原子性、可見性、有序性問題
- 需要著重的關注執行緒安全性的場景:存在共享數據並且該數據會發生變化,通俗的講就是多個執行緒同時讀寫同一個數據
- 數據競爭:當多個執行緒同時修改一個共享數據時,導致的並發bug(其實就是執行緒安全性)
public class Test { private long count = 0; void add10K() { int idx = 0; while(idx++ < 10000) { count += 1; } } }- 競態條件:指的是執行緒執行的結果依賴執行緒執行的順序
public class Test { private long count = 0; synchronized long get(){ return count; } synchronized void set(long v){ count = v; } void add10K() { int idx = 0; while(idx++ < 10000) { set(get()+1) //當兩個執行緒同時運行到get()方法時,get()方法先後(有sync鎖)0,count結果為1。當先後執行時,count結果為2 } } }- 解決方案 — 互斥(鎖)
CPU 提供了相關的互斥指令,作業系統、程式語言也會提供相關的 API。從邏輯上來看,我們可以統一歸為:鎖
- 理論知識
- 活躍性問題
所謂活躍性問題,指的是某個操作無法執行下去。我們常見的「死鎖」就是一種典型的活躍性問題,當然除了死鎖外,還有兩種情況,分別是「活鎖」和「飢餓」- 活鎖:互相「謙讓」的例子。執行緒因為總是同時的進行競爭而導致的互相等待的現象。
- 解決方案:讓執行緒等待一個隨機的時間。避免「同時」即可
- 死鎖:一組執行緒執行緒因為競爭共享數據而陷入永久性等待,導致執行緒「永久」的阻塞。
- 解決方案:破壞四個條件即可:互斥、佔用且等待、不可搶佔、循環等待
- 飢餓:所謂「飢餓」指的是執行緒因為無法訪問所需資源而無法執行下去的情況
- 解決方案
- 公平的分配資源
- 保證資源充足
- 避免執行緒長時間持有鎖
- 公平鎖,先來先得
- 解決方案
- 活鎖:互相「謙讓」的例子。執行緒因為總是同時的進行競爭而導致的互相等待的現象。
- 性能問題
- 盡量採用無鎖方式 樂觀鎖(CAS) 本地化存儲(ThreadLocal) copy-on-write
- 盡量減少執行緒持有鎖的時間
- 優化鎖粒度 聯想1.8前後ConcurrentHashMap的鎖設計
總結
- 安全性方面注意數據競爭 競態條件問題
- 活躍性方面注意死鎖 活鎖 飢餓等問題
- 性能方面盡量採用無鎖CAS,優化鎖粒度,減少鎖持有時間
08 | 管程:並發編程的萬能鑰匙
筆記
- 管程和訊號量
- 管程和訊號量是同步的,所謂同步也就是管程能實現訊號量,訊號量也能實現管程
- 什麼是管程
- 管程是一個概念
- 在java中每一個對象都綁定著一個管程(訊號量)
- 執行緒訪問加鎖對象其實就是去擁有一個監視器的過程。
- 執行緒訪問共享變數的過程其實就是申請擁有監視器的過程。
- 監視器至少有兩個等待隊列。
總結起來就是,管程就是一個對象監視器。任何執行緒想要訪問該資源,就要排隊進入監控範圍。進入之後,接受檢查,不符合條件,則要繼續等待,直到被通知,然後繼續進入監視器。
- java中的管程
- 1.5之前:①synchronized + wait、notify、notifyAll
- 1.5之後:②lock + condition
- 區別
- ①只支援一種一個條件變數,即wait,調用wait時將會將其加入到等待隊列。被notify時會隨機通知一個執行緒加入到鎖的等待池
- ②相對①condition支援中斷和增加了等待時間
- 三種實現管程的模型
- HASEN:執行完,再去喚醒另外一個執行緒。能夠保證執行緒的執行
- HOARE:是中斷當前執行緒,喚醒另外一個執行緒,執行玩再去喚醒,也能夠保證完成。
- MESA:是進入等待隊列,不一定有機會能夠執行(公平競爭公平 == 容易飢餓)
09 | Java執行緒(上):Java執行緒的生命周期
筆記
- 通用的五種執行緒狀態
- 初始狀態
- 可運行狀態
- 運行狀態
- 休眠狀態
- 終止狀態
- java執行緒的五種狀態
- new(初始化)
- runnable(可運行/運行狀態)
- blocked(阻塞狀態)
- waiting(無限時等待)
- timed_waiting(有時限等待)
- terminated(終止)
- RUNNABLE 與 BLOCKED 的狀態轉換
- 只有一種場景會觸發這種轉換,就是執行緒等待 synchronized 的隱式鎖。synchronized 修飾的方法、程式碼塊同一時刻只允許一個執行緒執行,其他執行緒只能等待,這種情況下,等待的執行緒就會從 RUNNABLE 轉換到 BLOCKED 狀態。而當等待的執行緒獲得 synchronized 隱式鎖時,就又會從 BLOCKED 轉換到 RUNNABLE 狀態
- RUNNABLE 與 WAITING 的狀態轉換
- 第一種場景,獲得 synchronized 隱式鎖的執行緒,調用無參數的 Object.wait() 方法
- 第二種場景,調用無參數的 Thread.join() 方法
- 第三種場景,調用 LockSupport.park() 方法。其中的 LockSupport 對象,也許你有點陌生,其實 Java 並發包中的鎖,都是基於它實現的
- RUNNABLE 與 TIMED_WAITING 的狀態轉換
- 調用帶超時參數的 Thread.sleep(long millis) 方法
- 獲得 synchronized 隱式鎖的執行緒,調用帶超時參數的 Object.wait(long timeout) 方法
- 調用帶超時參數的 Thread.join(long millis) 方法
- 調用帶超時參數的 LockSupport.parkNanos(Object blocker, long deadline) 方法
- 調用帶超時參數的 LockSupport.parkUntil(long deadline) 方法
- 從 NEW 到 RUNNABLE 狀態
- Java 剛創建出來的 Thread 對象就是 NEW 狀態,而創建 Thread 對象主要有兩種方法
- RUNNABLE 到 TERMINATED 狀態
- 正常結束
- interrupt()
10 | Java執行緒(中):創建多少執行緒才是合適的?
筆記
-
為什麼要使用多執行緒?
- 使用多執行緒,本質上就是提升程式性能。
- 兩個指標
- 延遲指的是發出請求到收到響應這個過程的時間;延遲越短,意味著程式執行得越快,性能也就越好。
- 吞吐量指的是在單位時間內能處理請求的數量;吞吐量越大,意味著程式能處理的請求越多,性能也就越好
- 本質上就是將硬體的性能發揮到極致
-
多執行緒的應用場景
- I/O密集型
- CPU密集型
-
評論區
- 個人覺得公式話性能問題有些不妥,定性的io密集或者cpu密集很難在定量的維度上反應出性能瓶頸,而且公式上忽略了執行緒數增加帶來的cpu消耗,性能優化還是要定量比較好,這樣不會盲目,比如io已經成為了瓶頸,增加執行緒或許帶來不了性能提升,這個時候是不是可以考慮用cpu換取頻寬,壓縮數據,或者邏輯上少發送一些。最後一個問題,我的答案是大部分應用環境是合理的,老師也說了是積累了一些調優經驗後給出的方案,沒有特殊需求,初始值我會選大家都在用偽標準
11 | Java執行緒(下):為什麼局部變數是執行緒安全的?
筆記
- 為什麼局部變數不存在執行緒安全問題
- 從執行緒棧解釋:局部變數在執行緒的獨享棧中
- 沒有共享就沒有傷害
- 執行緒安全問題的解決方案之一
- 執行緒封閉
- ThreadLocal
- 注意ThreadLocal的記憶體泄漏問題
總結
- new出來的對象都在堆中的合理解釋
- 對象在堆中,但是對象的句柄(引用或者指針)在棧中
- 沒有共享就沒有傷害
- 遞歸注意深度,容易導致棧記憶體溢出
- ThreadLocal的記憶體泄漏問題
- Spring對數據源連接池的抽象 ThreadLocal實現的
12 | 如何用面向對象思想寫好並發程式?
筆記
- 三個思路
- 封裝共享變數
- 將共享變數作為對象屬性封裝在內部,對所有公共方法制定並發訪問策略
- 識別共享變數間的約束條件
public class SafeWM { // 庫存上限 private final AtomicLong upper = new AtomicLong(0); // 庫存下限 private final AtomicLong lower = new AtomicLong(0); // 設置庫存上限 void setUpper(long v){ upper.set(v); } // 設置庫存下限 void setLower(long v){ lower.set(v); } // 省略其他業務程式碼 }* 約束條件,決定了並發訪問策略 * 忽略了一個約束條件:下限 < 上限 * 不安全的一個例子public class SafeWM { // 庫存上限 private final AtomicLong upper = new AtomicLong(0); // 庫存下限 private final AtomicLong lower = new AtomicLong(0); // 設置庫存上限 void setUpper(long v){ // 檢查參數合法性 if (v < lower.get()) { throw new IllegalArgumentException(); } upper.set(v); } // 設置庫存下限 void setLower(long v){ // 檢查參數合法性 if (v > upper.get()) { throw new IllegalArgumentException(); } lower.set(v); } // 省略其他業務程式碼 }當setUpper(5) 和 setLower(7)同時發生時,會發生upper = 5 lower = 7 * 著重注意if else語句造成的競態條件 - 封裝共享變數
- 制定並發訪問策略
- 避免共享
- 不變模式(不可變對象/變數)
- 管程/並發工具(JUC)
- 優先考慮java的並發包,一般能解決絕大多數並發問題
- 迫不得已時再考慮「低級」原語:synchronized、Lock、Semaphore,使用時千萬小心
- 避免過早優化,首先保證安全,等到確實遇到性能瓶頸的時候,再考慮優化
14 | Lock和Condition(上):隱藏在並發包中的管程
筆記
- 並發編程的兩個核心問題
- 互斥-同一個時刻只能有一個執行緒可以訪問共享資源
- 同步-執行緒之間如何通訊、協作
- Java中管程的兩個實現–java執行緒的兩種協作方式
- synchronized + wait + notify
- synchronized實現互斥
- wait + notify實現同步
- lock + Condition
- lock實現互斥
- condition實現同步
- synchronized + wait + notify
- 再造管程的理由
- synchronized存在的問題
- 1.5之前性能不夠好 + 容易膨脹為重量級鎖
- 死鎖問題無法破壞不可搶佔條件
- synchronized存在的問題
- 設計一個鎖能解決不可搶佔條件
- 能夠響應中斷
- 支援超時
- 非阻塞的獲取鎖
// 支援中斷的API void lockInterruptibly() throws InterruptedException; // 支援超時的API boolean tryLock(long time, TimeUnit unit) throws InterruptedException; // 支援非阻塞獲取鎖的API boolean tryLock(); - 如何保證可見性
- synchronized
- happens-before中有一個鎖規則,保證了synchronized的可見性
- Lock
- 利用了 volatile 相關的 Happens-Before 規則
ReentrantLock 內部持有一個volatile的變數
class SampleLock { volatile int state; // 加鎖 lock() { // 省略程式碼無數 state = 1; } // 解鎖 unlock() { // 省略程式碼無數 state = 0; } } - 利用了 volatile 相關的 Happens-Before 規則
- synchronized
- 可重入鎖
- 執行緒可以重複獲取同一把鎖
- ReentrantLock漢語意思就是可重入鎖的含義
- 公平鎖與非公平鎖
- 公平鎖:按照先來先得的原則,完全公平。其實就是排隊等待
- 非公平鎖:公平競爭鎖,每次競爭所有執行緒獲取鎖的機會是均等待。(為什麼叫非公平鎖呢?因為運氣不好的可能造成執行緒飢餓)
15 | Lock和Condition(下):Dubbo如何用管程實現非同步轉同步?
筆記
- 相對synchronized + wait + notify/ReentrantLock + Condition的優勢
- Lock&Condition 實現的管程是支援多個條件變數的,這是二者的一個重要區別。
- sync + wait只能支援一個條件,因為條件都是綁定到monitor上的,每一個鎖只有一個monitor
- 如何實現一個阻塞隊列
- 阻塞隊列需要兩個條件:滿阻塞/空阻塞
- sync管程只能實現一個阻塞,因為其只能支援一個條件變數
- lock + Condition 可以支援多個條件變數
- 複習
- sync + wait + notify + notifyAll
- lock + Condition + await + signal + signalAll
public class BlockedQueue<T>{ final Lock lock = new ReentrantLock(); // 條件變數:隊列不滿 final Condition notFull = lock.newCondition(); // 條件變數:隊列不空 final Condition notEmpty = lock.newCondition(); // 入隊 void enq(T x) { lock.lock(); try { while (隊列已滿){ // 等待隊列不滿 notFull.await(); } // 省略入隊操作... //入隊後,通知可出隊 notEmpty.signal(); }finally { lock.unlock(); } } // 出隊 void deq(){ lock.lock(); try { while (隊列已空){ // 等待隊列不空 notEmpty.await(); } // 省略出隊操作... //出隊後,通知可入隊 notFull.signal(); }finally { lock.unlock(); } } }
- 阻塞隊列需要兩個條件:滿阻塞/空阻塞
- Dubbo如何實現非同步的RPC實現同步的等待結果
// 創建鎖與條件變數 private final Lock lock = new ReentrantLock(); private final Condition done = lock.newCondition(); // 調用方通過該方法等待結果 Object get(int timeout){ long start = System.nanoTime(); lock.lock(); try { while (!isDone()) { done.await(timeout); long cur=System.nanoTime(); if (isDone() || cur-start > timeout){ break; } } } finally { lock.unlock(); } if (!isDone()) { throw new TimeoutException(); } return returnFromResponse(); } // RPC結果是否已經返回 boolean isDone() { return response != null; } // RPC結果返回時調用該方法 private void doReceived(Response res) { lock.lock(); try { response = res; if (done != null) { done.signal(); } } finally { lock.unlock(); } }
猜想
- Future應該也是通過 Lock + Condition實現的
- 明天看源碼ArrayListBlockQueue/LinkedListBlockQueue,看二者如何實現的阻塞
16 | Semaphore:如何快速實現一個限流器?
筆記
- 訊號量
- 互斥性
- Semaphore如何實現互斥。指定Semaphore的計數器為1,也就意味著同一個時刻只能有一個執行緒可以訪問臨界區資源
- 執行緒並行控制
- Semaphore如何控制並發。Semaphore通過計數器,控制訪問臨界區的執行緒不能超過計數器值。
- 互斥性
- 作業系統中也存在訊號量–作用和java中的訊號量也是相同的
- 作業系統利用訊號量控制進程的並行
- Semaphore 的公平性
- 默認Semaphore是非公平的,同 ReentrantLock
- Semaphore提供了兩個構造方法,如下所示,兩個參數的構造方法,第二個參數可以指定公平性
- false:非公平,也就是公平競爭,容易飢餓
- true:公平,先來後到
public Semaphore(int permits) { sync = new NonfairSync(permits); } public Semaphore(int permits, boolean fair) { sync = fair ? new FairSync(permits) : new NonfairSync(permits); }
總結
- 訊號量在 Java 語言裡面名氣並不算大,但是在其他語言里卻是很有知名度的。Java 在並發編程領域走的很快,
重點支援的還是管程模型。 管程模型理論上解決了訊號量模型的一些不足,主要體現在易用性和工程化方面,
例如用訊號量解決我們曾經提到過的阻塞隊列問題,就比管程模型麻煩很多。
17 | ReadWriteLock:如何快速實現一個完備的快取?
筆記
- 管程和訊號量都能解決所有並發問題了,JUC中還存在那麼多並發工具?
- 分場景優化,提升易用性
- 什麼是讀寫鎖
- 讀寫鎖普遍存在於各種語言,三條基本原則
- 允許多個執行緒同時讀共享變數
- 統一時刻只允許一個執行緒寫共享變數
- 如果一個寫執行緒正在執行寫操作,此時禁止讀執行緒讀共享變數(讀鎖和寫鎖是互斥的)
- 對比mysql(以下兩條結論都建立在兩個獨立的事務中)
- 在read-uncommitted、read-committed、repeatable-read級別下,對同一行數據的寫不會阻塞讀。原因在於在以上三個隔離級別中,是通過MVCC控制的。當然如果採用當前讀(lock in share mode讀讀不互斥,讀寫互斥。ps:for update讀讀互斥、讀寫互斥)則可以產生阻塞
- 在serializable隔離級別下,同讀寫鎖的第三條讀寫互斥規則。原因是在serializable級別下所有的讀都是當前讀(互斥讀)。
- mysql 演示
-- session1 -- 查詢事務級別 select @@tx_isolation; -- 設置事務級別 set session transaction isolation level read committed; -- 開啟事務 start transaction; select * from sys_test where id = 2 ; -- 加上lock in share mode同讀寫鎖的讀寫互斥; -- 提交事務 commit; -- session2 set session transaction isolation level read committed; start transaction; update sys_test set name = '55' where id = 2; select * from sys_test where id = 2; commit;
- 對比mysql(以下兩條結論都建立在兩個獨立的事務中)
- 讀寫鎖普遍存在於各種語言,三條基本原則
- ReadWriteLock讀寫鎖
- 讀多寫少的場景
- 快取
- 讀寫鎖的升級與降級
- ReadWriteLock不支援鎖升級(會飢餓),但是支援鎖降級。
理解
- ReadWriteLock讀寫鎖如果不互斥,也就沒必要存在讀鎖了。
- 類似mysql,如果讀寫不互斥,則沒必要加讀鎖。
- 讀鎖存在的意義在於第三條規則。寫同時阻塞讀,可以保證讀到的一定是最新的。
- mysql在前三個隔離級別下默認讀是快照讀(無鎖讀),所以才存在了臟讀、不可重複度、幻讀。所以解決以上三個問題的終極方法就是所有讀都採用當前讀(鎖讀)、當然這會影響性能,不建議使用。
18 | StampedLock:有沒有比讀寫鎖更快的鎖?
筆記
- StampedLock 和 ReadWriteLock的區別
- ReadWriteLock 支援兩種模式(讀讀不互斥,寫寫互斥,讀寫互斥)
- 讀鎖
- 寫鎖
- StampedLock 支援三種模式
- 寫鎖 語義同ReadWriteLock的寫鎖
- 悲觀讀鎖 語義同ReadWriteLock的讀鎖
- 樂觀讀鎖 樂觀鎖-無鎖,性能更好
- ReadWriteLock 支援兩種模式(讀讀不互斥,寫寫互斥,讀寫互斥)
- StampedLock 鎖升級 (不是內部實現)
- 當 StampedLock 樂觀讀期間遇到寫操作(validate(stamp)方法可判斷)
- 注意事項
- StampedLock 是不可重入的
- 使用 StampedLock 一定不要調用中斷操作,如果需要支援中斷功能,一定使用可中斷的悲觀讀鎖 readLockInterruptibly() 和寫鎖 writeLockInterruptibly()。這個規則一定要記清楚。
範式
- 讀範式
final StampedLock sl = new StampedLock(); // 樂觀讀 long stamp = sl.tryOptimisticRead(); // 讀入方法局部變數 ...... // 校驗stamp if (!sl.validate(stamp)){ // 升級為悲觀讀鎖 stamp = sl.readLock(); try { // 讀入方法局部變數 ..... } finally { //釋放悲觀讀鎖 sl.unlockRead(stamp); } } //使用方法局部變數執行業務操作 ...... - 寫範式
long stamp = sl.writeLock(); try { // 寫共享變數 ...... } finally { sl.unlockWrite(stamp); }
19 | CountDownLatch和CyclicBarrier:如何讓多執行緒步調一致?
筆記
- CountDownLatch
- 主要用來解決一個執行緒等待多個執行緒的場景。可以類比旅遊團團長要等待所有的遊客到齊才能去下一個景點;
- 一旦計數器到0,再有執行緒調用await(),會直接通過。
- CyclicBarrier
- 一組執行緒之間互相等待。
- 具備自動重置功能。CyclicBarrier 的計數器是可以循環利用的。一旦計數器減到 0 會自動重置到你設置的初始值。
- CyclicBarrier 還可以設置回調函數
TODO
- CyclicBarrier實操
20 | 並發容器:都有哪些「坑」需要我們填?
筆記
- List
- LinkedList
- ArrayList
- 同步容器
- Vector
- 並發容器
- CopyOnWriteArrayList
- Set
- HashSet
- TreeSet
- LinkedSet
- 並發容器
- CopyOnWriteArraySet
- CopyOnWriteSkipListSet
- Map
- LinkedHashMap
- HashMap
- TreeMap
- 同步容器
- HashTable
- 並發容器
- ConcurrentHashMap
- ConcurrentSkipListMap
- Queue
- 非阻塞
- 執行緒不安全
- PriorityQueue
- LinkedList
- 執行緒安全
- 單端
- ConcurrentLinkedQueue
- 雙端
- ConcurrentLinkedDeque
- 單端
- 執行緒不安全
- 阻塞
- ArrayBlockingQueue
- 出隊入隊同一把鎖
- 底層數據結構:數組
- 有界
- 默認不保證執行緒安全性
- LinkedBlockingQueue
- 底層鏈表
- 「有界」阻塞隊列(長度為int長度)
- SynchronousQueue
- 無空間(不存儲元素)
- LinkedTransferQueue
- 無界:由鏈表組成的無界TransferQueue
- PriorityBlockingQueue
- 支援優先順序
- 無界
- DelayQueue
- 延時阻塞隊列
- 無界
- ArrayBlockingQueue
- 非阻塞
- 對於Collections.synchronizedXXX()的方法要著重注意競態條件問題
- 使用無界隊列時要著重注意oom問題。例如:執行緒池的阻塞隊列
21 | 原子類:無鎖工具類的典範
筆記
-
CAS全程
- Compare And Swap
-
無鎖方案的優點
- 無鎖方案相對於互斥鎖方案,最大的好處就是性能
- 互斥鎖方案為了保證互斥性,需要執行加鎖、解鎖操作,而加鎖、解鎖操作本身就消耗性能;
同時拿不到鎖的執行緒還會進入阻塞狀態,進而觸發執行緒切換,執行緒切換對性能的消耗也很大。
相比之下,無鎖方案則完全沒有加鎖、解鎖的性能消耗,同時還能保證互斥性,既解決了問題,又沒有帶來新的問題,可謂絕佳方案。
- 互斥鎖方案為了保證互斥性,需要執行加鎖、解鎖操作,而加鎖、解鎖操作本身就消耗性能;
- 不會出現死鎖
- 注意活鎖和飢餓問題
- 無鎖方案相對於互斥鎖方案,最大的好處就是性能
-
無鎖方案的實現原理
- 硬體支援-CPU為了解決並發問題,提供了CAS指令。作為一條 CPU 指令,CAS 指令本身是能夠保證原子性的。
- CAS的使用一般都伴隨著自旋
-
ABA問題
- 解決方案
- 理論上增加時間戳或者版本號都可以實現,JDK採用的是使用版本號。
- 解決方案
-
單純的累加操作,使用累加器相對原子化的基本類型,性能更高
-
TODO實操
22 | Executor與執行緒池:如何創建正確的執行緒池?
- 執行緒池是一種生產者 – 消費者模式
- 執行緒池的使用方式 是 生產者
- 執行緒池本身是消費者
- ThreadPoolExecutor
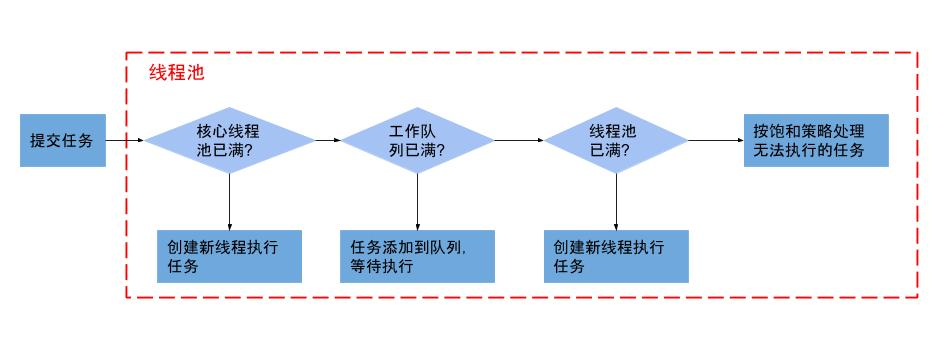
ThreadPoolExecutor( int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)- corePoolSize 核心池大小
表示執行緒池保有的最小執行緒數。有些項目很閑,但是也不能把人都撤了,至少要留 corePoolSize 個人堅守陣地。- 當執行緒數小於核心執行緒數時,即使有執行緒空閑,執行緒池也會優先創建新執行緒處理
- 核心執行緒會一直存活,即使沒有任務需要執行
- 設置allowCoreThreadTimeout=true(默認false)時,核心執行緒會超時關閉
- maximumPoolSize 最大池
表示執行緒池創建的最大執行緒數。當項目很忙時,就需要加人,但是也不能無限制地加,最多就加到 maximumPoolSize 個人。當項目閑下來時,就要撤人了,最多能撤到 corePoolSize 個人。 - keepAliveTime & unit 空閑執行緒存活的時間
上面提到項目根據忙閑來增減人員,那在編程世界裡,如何定義忙和閑呢?很簡單,一個執行緒如果在一段時間內,都沒有執行任務,說明很閑,keepAliveTime 和 unit 就是用來定義這個「一段時間」的參數。也就是說,如果一個執行緒空閑了keepAliveTime & unit這麼久,而且執行緒池的執行緒數大於 corePoolSize ,那麼這個空閑的執行緒就要被回收了。 - workQueue 工作隊列
工作隊列,當執行緒核心池已滿,接下來來的任務就會被放到工作隊列(阻塞隊列)- 最好不要用無界隊列,一旦業務量增加很容易OOM
- threadFactory
通過這個參數你可以自定義如何創建執行緒,例如你可以給執行緒指定一個有意義的名字。(PS:一般給執行緒池名字加前綴用這個方法) - handler 拒絕策略
當工作隊列和執行緒池都滿了,那麼此時提交任務,執行緒池就會拒絕接收- CallerRunsPolicy:提交任務的執行緒自己去執行該任務。
- AbortPolicy:默認的拒絕策略,會 throws RejectedExecutionException
- DiscardPolicy:直接丟棄任務,沒有任何異常拋出
- DiscardOldestPolicy:丟棄最老的任務,其實就是把最早進入工作隊列的任務丟棄,然後把新任務加入到工作隊列。
- 實現 RejectedExecutionHandler 介面 自定義拒絕策略,如果處理的任務不允許丟失,則可以和降級策略配合使用。
可以放資料庫,放mq,redis,本地文件都可以,具體要看實際需求。
- corePoolSize 核心池大小
重點
- 注意事項
- 不要使用無界工作隊列 最好不要使用 無界隊列 因為業務量的突然增加很容易導致OOM
- 默認拒絕策略要慎重使用 實際開發任務中可以配合MQ和服務降級處理
- 執行緒池的異常處理 execute() 方法提交任務時,如果任務在執行的過程中出現運行時異常,會導致執行任務的執行緒終止;不過,最致命的是任務雖然異常了,但是你卻獲取不到任何通知,這會讓你誤以為任務都執行得很正常。
最好的辦法還是捕獲所有異常,按需處理 - 執行緒池的使用建議
- 業務隔離
- 壓測確定隊列長度或執行緒數
- 核心池大小
- 經驗值
- IO密集型
- 2 * CPU + 1
- CPU密集型
- CPU + 1
- IO密集型
- 實踐值
- 最佳執行緒數目 = (執行緒等待時間與執行緒CPU時間之比 + 1)* CPU數目
- 最佳值
- 壓測
- 經驗值
- 執行緒池流程

23 | Future:如何用多執行緒實現最優的「燒水泡茶」程式?
筆記
- 如何獲取非同步執行結果
- Future
- CountdownLatch
- join方法
- Future介面是一個獲取非同步結果的通用介面
- FutureTask是如何獲取結果的
- FutureTask源碼中狀態標識 state
- NEW = 0;初始狀態
- COMPLETING = 1;正在執行
- NORMAL = 2;
- EXCEPTIONAL = 3;
- CANCELLED = 4;
- INTERRUPTING = 5;
- INTERRUPTED = 6;
- 狀態轉換 TODO詳細閱讀源碼理解
- NEW -> COMPLETING -> NORMAL
- NEW -> COMPLETING -> EXCEPTIONAL
- NEW -> CANCELLED
- NEW -> INTERRUPTING -> INTERRUPTED
- FutureTask源碼中狀態標識 state
- FutureTask的阻塞方法不像有些部落格說的 Object#wait而是 LockSupport.park(this);對應的喚醒執行緒的方法 LockSupport.unpark(this);
TODO
- 總結java中實現獲取非同步結果的方式和工具
- 總結 非同步轉同步的方式
24 | CompletableFuture:非同步編程沒那麼難
筆記
- CompletableFuture 的核心優勢
- 無需手工維護執行緒,沒有繁瑣的手工維護執行緒的工作,給任務分配執行緒的工作也不需要我們關注;(對比FutureTask的實現)
- 語義更清晰,例如 f3 = f1.thenCombine(f2, ()->{}) 能夠清晰地表述「任務 3 要等待任務 1 和任務 2 都完成後才能開始」;
- 程式碼更簡練並且專註於業務邏輯,幾乎所有程式碼都是業務邏輯相關的。
- 創建CompletableFuture對象
- runAsync(Runnable runnable) 不獲取返回值的靜態方法
- supplyAsync(Supplier supplier) 可獲取返回值的方法 (ps:作用同Future),Supplier相對於Runnable,get方法可以獲取返回值
- 以上兩個方法可以指定執行緒池 (PS:CompletableFuture默認使用ForkJoinPool執行緒池)
//使用默認執行緒池 static CompletableFuture<Void> runAsync(Runnable runnable) static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier) //可以指定執行緒池 static CompletableFuture<Void> runAsync(Runnable runnable, Executor executor) static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier, Executor executor) - CompletableFuture實現的CompletionStage介面的作用
任務的時序關係管理- 串列關係

CompletionStage<R> thenApply(fn); CompletionStage<R> thenApplyAsync(fn); CompletionStage<Void> thenAccept(consumer); CompletionStage<Void> thenAcceptAsync(consumer); CompletionStage<Void> thenRun(action); CompletionStage<Void> thenRunAsync(action); CompletionStage<R> thenCompose(fn); CompletionStage<R> thenComposeAsync(fn); - 並行關係
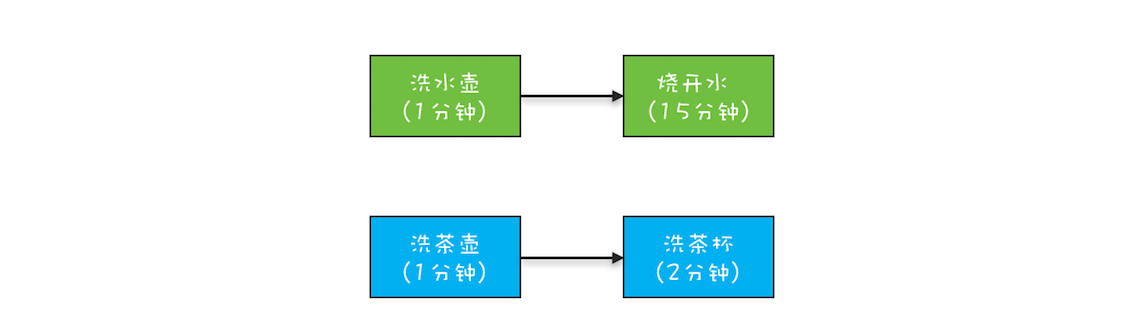
- 匯聚關係
- AND匯聚關係
CompletionStage<R> thenCombine(other, fn); CompletionStage<R> thenCombineAsync(other, fn); CompletionStage<Void> thenAcceptBoth(other, consumer); CompletionStage<Void> thenAcceptBothAsync(other, consumer); CompletionStage<Void> runAfterBoth(other, action); CompletionStage<Void> runAfterBothAsync(other, action); - OR 匯聚關係
CompletionStage applyToEither(other, fn); CompletionStage applyToEitherAsync(other, fn); CompletionStage acceptEither(other, consumer); CompletionStage acceptEitherAsync(other, consumer); CompletionStage runAfterEither(other, action); CompletionStage runAfterEitherAsync(other, action); - AND匯聚關係
- 串列關係
- 異常處理
CompletionStage exceptionally(fn); CompletionStage<R> whenComplete(consumer); CompletionStage<R> whenCompleteAsync(consumer); CompletionStage<R> handle(fn); CompletionStage<R> handleAsync(fn);



課後思考
- 創建採購訂單的時候,需要校驗一些規則,例如最大金額是和採購員級別相關的。有同學利用 CompletableFuture 實現了這個校驗的功能,邏輯很簡單,首先是從資料庫中把相關規則查出來,然後執行規則校驗。你覺得他的實現是否有問題呢?
//採購訂單
PurchersOrder po;
CompletableFuture<Boolean> cf =
CompletableFuture.supplyAsync(()->{
//在資料庫中查詢規則
return findRuleByJdbc();
}).thenApply(r -> {
//規則校驗
return check(po, r);
});
Boolean isOk = cf.join();
- 解答
- 沒有進行異常處理,
- 要指定專門的執行緒池做資料庫查詢(讀資料庫屬於io操作,應該放在單獨執行緒池,避免執行緒飢餓)
- 如果檢查和查詢都比較耗時,那麼應該像之前的對賬系統一樣,採用生產者和消費者模式,讓上一次的檢查和下一次的查詢並行起來。
25 | CompletionService:如何批量執行非同步任務?
- CompletionService 批量提交非同步任務
// 創建執行緒池
ExecutorService executor =
Executors.newFixedThreadPool(3);
// 非同步向電商S1詢價
Future<Integer> f1 =
executor.submit(
()->getPriceByS1());
// 非同步向電商S2詢價
Future<Integer> f2 =
executor.submit(
()->getPriceByS2());
// 非同步向電商S3詢價
Future<Integer> f3 =
executor.submit(
()->getPriceByS3());
// 獲取電商S1報價並保存
r=f1.get();
executor.execute(()->save(r));
// 獲取電商S2報價並保存
r=f2.get();
executor.execute(()->save(r));
// 獲取電商S3報價並保存
r=f3.get();
executor.execute(()->save(r));
- Future 實現「詢價」程式
- 如上所示,需要一個個的get然後執行下一步操作,f1, f2, f3需要一次等待
// 創建阻塞隊列
BlockingQueue<Integer> bq =
new LinkedBlockingQueue<>();
//電商S1報價非同步進入阻塞隊列
executor.execute(()->
bq.put(f1.get()));
//電商S2報價非同步進入阻塞隊列
executor.execute(()->
bq.put(f2.get()));
//電商S3報價非同步進入阻塞隊列
executor.execute(()->
bq.put(f3.get()));
//非同步保存所有報價
for (int i=0; i<3; i++) {
Integer r = bq.take();
executor.execute(()->save(r));
}
- 阻塞隊列的優化方案
- 如上所示 阻塞隊列也能解決這種互相等待操作造成的資源浪費
- 利用 CompletionService 實現詢價系統
- CompletionService 內部實現了一個阻塞隊列,默認 LinkedListBlockingQueue(建議覆蓋,因為默認的是無界的)
- CompletionService 會把Future對象放到阻塞隊列中。
程式碼實現如下所示
// 創建執行緒池
ExecutorService executor =
Executors.newFixedThreadPool(3);
// 創建CompletionService
CompletionService<Integer> cs = new
ExecutorCompletionService<>(executor);
// 非同步向電商S1詢價
cs.submit(()->getPriceByS1());
// 非同步向電商S2詢價
cs.submit(()->getPriceByS2());
// 非同步向電商S3詢價
cs.submit(()->getPriceByS3());
// 將詢價結果非同步保存到資料庫
for (int i=0; i<3; i++) {
Integer r = cs.take().get();// **TODO 驗證是否是先執行完的,先入隊**
executor.execute(()->save(r));
}
TODO 驗證是否是先執行完的,先入隊
- 利用 CompletionService 實現 Dubbo 中的 Forking Cluster
- Dubbo 中有一種叫做 Forking 的集群模式,這種集群模式下,支援並行地調用多個查詢服務,只要有一個成功返回結果,整個服務就可以返回了。
// 創建執行緒池
ExecutorService executor =
Executors.newFixedThreadPool(3);
// 創建CompletionService
CompletionService<Integer> cs =
new ExecutorCompletionService<>(executor);
// 用於保存Future對象
List<Future<Integer>> futures =
new ArrayList<>(3);
//提交非同步任務,並保存future到futures
futures.add(
cs.submit(()->geocoderByS1()));
futures.add(
cs.submit(()->geocoderByS2()));
futures.add(
cs.submit(()->geocoderByS3()));
// 獲取最快返回的任務執行結果
Integer r = 0;
try {
// 只要有一個成功返回,則break
for (int i = 0; i < 3; ++i) {
r = cs.take().get();
//簡單地通過判空來檢查是否成功返回
if (r != null) {
break;
}
}
} finally {
//取消所有任務
for(Future<Integer> f : futures)
f.cancel(true);
}
// 返回結果
return r;
總結
- 當需要批量提交非同步任務的時候建議你使用 CompletionService。CompletionService 將執行緒池 Executor 和阻塞隊列 BlockingQueue 的功能融合在了一起,能夠讓批量非同步任務的管理更簡單。除此之外,CompletionService 能夠讓非同步任務的執行結果有序化,先執行完的先進入阻塞隊列,利用這個特性,你可以輕鬆實現後續處理的有序性,避免無謂的等待,同時還可以快速實現諸如 Forking Cluster 這樣的需求。
- CompletionService 的實現類 ExecutorCompletionService,需要你自己創建執行緒池,雖看上去有些啰嗦,但好處是你可以讓多個 ExecutorCompletionService 的執行緒池隔離,這種隔離性能避免幾個特別耗時的任務拖垮整個應用的風險。
課後思考
- 本章使用 CompletionService 實現了一個詢價應用的核心功能,後來又有了新的需求,需要計算出最低報價並返回,下面的示例程式碼嘗試實現這個需求,你看看是否存在問題呢?
// 創建執行緒池
ExecutorService executor =
Executors.newFixedThreadPool(3);
// 創建CompletionService
CompletionService<Integer> cs = new
ExecutorCompletionService<>(executor);
// 非同步向電商S1詢價
cs.submit(()->getPriceByS1());
// 非同步向電商S2詢價
cs.submit(()->getPriceByS2());
// 非同步向電商S3詢價
cs.submit(()->getPriceByS3());
// 將詢價結果非同步保存到資料庫
// 並計算最低報價
AtomicReference<Integer> m =
new AtomicReference<>(Integer.MAX_VALUE);
for (int i=0; i<3; i++) {
executor.execute(()->{
Integer r = null;
try {
r = cs.take().get();
} catch (Exception e) {}
save(r);
m.set(Integer.min(m.get(), r));
});
}
return m;
Copy
解答
- 以上程式碼無法保證三個執行緒 和 主執行緒 return m的順序。可以加個CountDownLatch 來保證執行緒執行完成 再讓主執行緒return。
26 | Fork/Join:單機版的MapReduce
筆記
- 從任務的角度看待並發編程
- 不難發現執行緒池、Future、CompletableFuture、CompletionService都是站在任務的角度看待並發編程,將視野擴大,不再將精力都浪費在執行緒的協作上
- 對於簡單的並行任務,可以通過執行緒池+Future
- 如果任務之間有耦合關係,不管是AND或者OR,都可以CompletableFuture來解決
- 如果是批量任務,可以通過CompletionService來解決
- 並發編程關注的三個問題
- 互斥、
- 實現互斥的方案:鎖:Synchronized、ReentrantLock、ReadWriteLock、StampedLock、、、
- 分工、
- 實現分工的方案:執行緒池、CompletionService、CompletableFuture
- 協作
- 執行緒協作的方案:管程:synchronized+wait+notify、Lock+Condition、CountDownLatch、CyclicBarrier
- 互斥、
- 從更高的視野看待並發編程
- 任務
- 執行緒任務調度方式:執行緒池+Future、CompletionService、CompletableFuture
- 任務
- 任務類型
- 並行任務:執行緒池 + Future + 阻塞隊列、CompletableFuture
- 批量任務:CompletionService
- 聚合任務:CompletableFuture
- 分治任務:Fork/Join
- Fork/Join
- 理解
- Fork對應任務分解
- join對應任務聚合
- 工具
- ForkJoinPool
- 生產者-消費者模型
- 任務竊取當pool中的呃執行緒空閑了,會去竊取其他工作隊列中的任務。TODO 確認是一個等待池還是每個執行緒有一個等待池
- ForkJoinTask
- 抽象實現類:RecursiveAction(compute()無返回值)
- 抽象實現類:RecursiveTask(compute()有返回值)
以上兩者的關係類似 ThreadPoolExecutor 和 Runnable的關係
- ForkJoinPool
- 理解
總結
- Fork/Join 並行計算框架的核心組件是 ForkJoinPool。ForkJoinPool 支援任務竊取機制,能夠讓所有執行緒的工作量基本均衡,
不會出現有的執行緒很忙,而有的執行緒很閑的狀況,所以性能很好。Java 1.8 提供的 Stream API 裡面並行流也是以 ForkJoinPool
為基礎的。不過需要你注意的是,默認情況下所有的並行流計算都共享一個 ForkJoinPool,
這個共享的 ForkJoinPool 默認的執行緒數是 CPU 的核數;如果所有的並行流計算都是 CPU 密集型計算的話,完全沒有問題,
但是如果存在 I/O 密集型的並行流計算,那麼很可能會因為一個很慢的 I/O 計算而拖慢整個系統的性能。
所以建議用不同的 ForkJoinPool 執行不同類型的計算任務。
27 | 並發工具類模組熱點問題答疑
筆記
- 注意while(true)的問題
- 一般while(true)需要break條件,一般是超時時間,不然容易導致死循環
- while(true) & Lock和Condition裡面的活鎖問題
- notifyAll和signalAll
- 一般使用All比notify和signal更安全
- Semaphore 需要鎖中鎖
- Semaphore 允許多個執行緒訪問一個臨界區,這也是一把雙刃劍,當多個執行緒進入臨界區時,如果需要訪問共享變數就會存在並發問題,所以必須加鎖,也就是說 Semaphore 需要鎖中鎖。
- 個人理解,Semaphore不是一個鎖,只是一個並發工具,所以遇到共享變數問題,依然是需要鎖的
- 鎖的申請和釋放要成對出現
- 回調總要關心執行執行緒是誰
- 當看到回調函數的時候,一定問一問執行回調函數的執行緒是誰
- 共享執行緒池:有福同享就要有難同當
- 對於I/O密集型和CPU密集型的執行緒池要做業務隔離
- 線上問題定位的利器:執行緒棧 dump
- 善於利用JSP和jstack命令
28 | Immutability模式:如何利用不變性解決並發問題?
- 快速實現具備不可變性的類
- 將一個類所有的屬性都設置成 final 的,並且只允許存在只讀方法,那麼這個類基本上就具備不可變性了
- 將類也設置成 final 保證不能通過繼承修改該類的final屬性
- String
- String 類是final的,就是為了保證執行緒安全的
- String 類的字元串替換操作 String#replace方法如何保證的執行緒安全?
- replace 是通過將替換後的值返回的形式”修改”的字元串,嚴格來說不能說是修改,而是生成了一個新的字元串。也就是生成了一個新的不可變String對象
- TODO,思考 String 類型為什麼是存在常量池的
- 享元模式
享元模式本質上其實就是一個對象池,利用享元模式創建對象的邏輯也很簡單:創建之前,首先去對象池裡看看是不是存在;如果已經存在,就利用對象池裡的對象;
如果不存在,就會新創建一個對象,並且把這個新創建出來的對象放進對象池裡。- Long & Integer
- Long 這個類並沒有照搬享元模式,Long 內部維護了一個靜態的對象池,僅快取了[-128,127]之間的數字,這個對象池在 JVM 啟動的時候就創建好了,
而且這個對象池一直都不會變化,也就是說它是靜態的。
- Long 這個類並沒有照搬享元模式,Long 內部維護了一個靜態的對象池,僅快取了[-128,127]之間的數字,這個對象池在 JVM 啟動的時候就創建好了,
- Long & Integer
- 使用 Immutability 模式的注意事項
- 對象的所有屬性都是 final 的,並不能保證不可變性;
- 不可變對象也需要正確發布。
- 注意不可變的邊界,如下所示,雖然Bar對象中Foo屬性是final的,但是不能保證foo的屬性不能被修改。
class Foo{
int age=0;
int name="abc";
}
final class Bar {
final Foo foo;
void setAge(int a){
foo.age=a;
}
}
總結
- 利用 Immutability 模式解決並發問題,也許你覺得有點陌生,其實你天天都在享受它的戰果。Java 語言裡面的 String 和 Long、Integer、Double
等基礎類型的包裝類都具備不可變性,這些對象的執行緒安全性都是靠不可變性來保證的。
Immutability 模式是最簡單的解決並發問題的方法,建議當你試圖解決一個並發問題時,可以首先嘗試一下 Immutability 模式,看是否能夠快速解決。 - 無狀態
具備不變性的對象,只有一種狀態,這個狀態由對象內部所有的不變屬性共同決定。其實還有一種更簡單的不變性對象,那就是無狀態。
無狀態對象內部沒有屬性,只有方法。除了無狀態的對象,你可能還聽說過無狀態的服務、無狀態的協議等等。無狀態有很多好處,最核心的一點就是性能。
在多執行緒領域,無狀態對象沒有執行緒安全問題,無需同步處理,自然性能很好;在分散式領域,無狀態意味著可以無限地水平擴展,所以分散式領域裡面性能的瓶頸一定不是出在無狀態的服務節點上。 - 其實spring的 單例Bean 也是一種無狀態的Bean ,也就是在單例Bean中最好不要定義共享變數,因為如果不加入執行緒安全的控制的話,讀寫一定能引起並發問題。
29 | Copy-on-Write模式:不是延時策略的COW
筆記
- Copy-on-Write 寫時複製
- 基本思想-懶惰策略
- Copy-On-Write簡稱COW,是一種用於程式設計中的優化策略。其基本思路是,從一開始大家都在共享同一個內容,當某個人想要修改這個內容的時候,
才會真正把內容Copy出去形成一個新的內容然後再改,這是一種延時懶惰策略。
- Copy-On-Write簡稱COW,是一種用於程式設計中的優化策略。其基本思路是,從一開始大家都在共享同一個內容,當某個人想要修改這個內容的時候,
- 基本思想-讀寫分離
- 當修改容器時,不首先修改原容器,而是將原容器copy一份,然後修改copy的容器,之後再將修改後的容器替換原容器。這樣讀和寫操作的永遠都是兩個容器。
也就實現了讀寫分離。
- 當修改容器時,不首先修改原容器,而是將原容器copy一份,然後修改copy的容器,之後再將修改後的容器替換原容器。這樣讀和寫操作的永遠都是兩個容器。
- 基本思想-懶惰策略
- Copy-on-Write 在作業系統中的應用
- 類 Unix 的作業系統中創建進程的 API 是 fork(),傳統的 fork() 函數會創建父進程的一個完整副本,例如父進程的地址空間現在用到了 1G 的記憶體,那麼 fork() 子進程的時候要複製父進程整個進程的地址空間(佔有 1G 記憶體)給子進程,這個過程是很耗時的。而 Linux 中的 fork() 函數就聰明得多了,fork() 子進程的時候,並不複製整個進程的地址空間,而是讓父子進程共享同一個地址空間;只用在父進程或者子進程需要寫入的時候才會複製地址空間,從而使父子進程擁有各自的地址空間。
- java中的 CopyOnWriteArrayList 和 CopyOnWriteArraySet是一種典型的空間換時間的做法
- java中的CopyOnWriteXXX容器採用的都是當元素髮生變化,就進行copy操作。
- 存在的問題:當容器非常大,這樣就會浪費很多的空間。
- java中的CopyOnWriteXXX容器採用的都是當元素髮生變化,就進行copy操作。
總結
- 目前 Copy-on-Write 在 Java 並發編程領域知名度不是很高,很多人都在無意中把它忽視了,但其實 Copy-on-Write 才是最簡單的並發解決方案。
它是如此簡單,以至於 Java 中的基本數據類型 String、Integer、Long 等都是基於 Copy-on-Write 方案實現的。Copy-on-Write 是一項非常通用的技術方案,
在很多領域都有著廣泛的應用。不過,它也有缺點的,那就是消耗記憶體,每次修改都需要複製一個新的對象出來,好在隨著自動垃圾回收(GC)
演算法的成熟以及硬體的發展,這種記憶體消耗已經漸漸可以接受了。所以在實際工作中,如果寫操作非常少,那你就可以嘗試用一下 Copy-on-Write,效果還是不錯的。
思考題
- 為什麼java中沒有 CopyOnWriteLinkedList
- 知識點:鏈表是分散的存儲空間,通過 指針串聯起來的
- 知識點:數組是連續的存儲空間
- 當需要複製數組,只需要複製數組所在的連續空間即可,是一個時間複雜度為O(1)的操作。
而鏈表是不連續的存儲空間,所以複製鏈表意味著需要 按照鏈表的指針,遍歷整個鏈表。這將是一個時間複雜度為O(n)的操作。
30 | 執行緒本地存儲模式:沒有共享,就沒有傷害
筆記
- 執行緒封閉
- 局部變數
- ThreadLocal
- ThreadLocal源碼
- 切記 ThreadLocalMap是Thread持有的
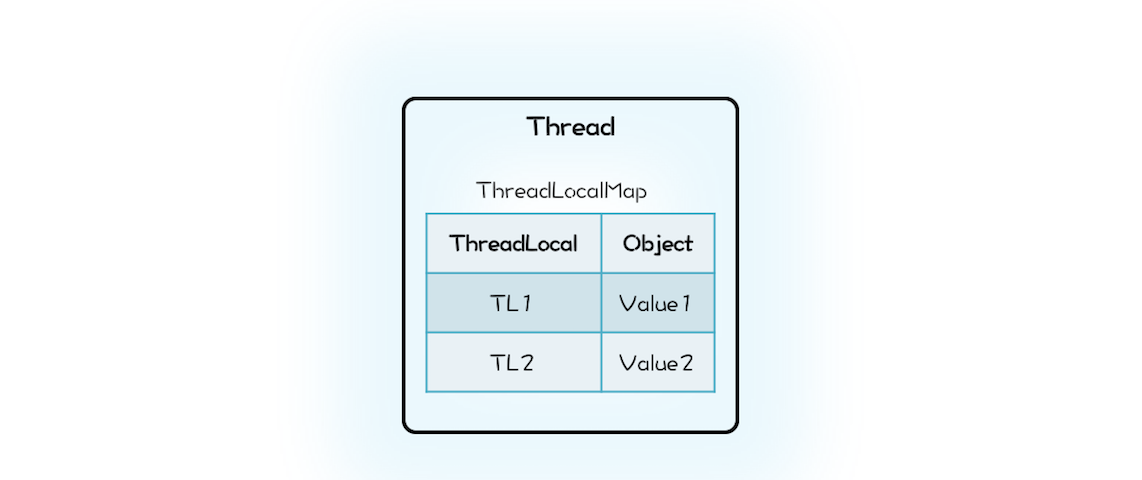
- 切記 ThreadLocalMap是Thread持有的

class Thread {
//內部持有ThreadLocalMap
ThreadLocal.ThreadLocalMap
threadLocals;
}
class ThreadLocal<T>{
public T get() {
//首先獲取執行緒持有的
//ThreadLocalMap
ThreadLocalMap map = Thread.currentThread().threadLocals;
//在ThreadLocalMap中
//查找變數
Entry e = map.getEntry(this);
return e.value;
}
static class ThreadLocalMap{
//內部是數組而不是Map
Entry[] table;
//根據ThreadLocal查找Entry
Entry getEntry(ThreadLocal key){
//省略查找邏輯
}
//Entry定義
static class Entry extends
WeakReference<ThreadLocal>{
Object value;
}
}
}
- ThreadLocal 的記憶體泄漏問題
- 一個誤區、不是說ThreadLocal一定存在記憶體泄漏,在一般場景中,Thread持有ThreadLocalMap,ThreadLocalMap以弱引用的方式持有ThreadLocal,當執行緒Thread被回收,意味著ThreadLocal一定會被回收。
- ThreadLocal的記憶體泄漏發生在配合執行緒池使用的場景中
- 在執行緒池中 執行緒存活時間很長,往往同應用程式是同生共死的,這就意味著 Thread 持有的 ThreadLocalMap 一直都不會被回收,再加上 ThreadLocalMap 的 Entry對 ThreadLocal的引用是弱引用(WeakReference)
- 所以 只要 ThreadLocal 結束了自己的生命周期 是可以被回收掉的。但是 Entry 中的value 卻是被Entry強引用。所以即便 Value的生命周期結束了,value 也是無法被回收的(可達性分析演算法),從而導致記憶體泄漏
- 解決方案-一般ThreadLocal配合執行緒池使用,需要使用try{}finally{}手動釋放資源
ExecutorService es;
ThreadLocal tl;
es.execute(()->{
//ThreadLocal增加變數
tl.set(obj);
try {
// 省略業務邏輯程式碼
}finally {
//手動清理ThreadLocal
tl.remove();
}
});
總結
- Spring的 執行緒池管理 採用的就是 ThreadLocal ,每個執行緒可以針對性的修改自己的執行緒池。通過這個,可以寫一個切面來切換數據源。
- 執行緒本地存儲模式本質上是一種避免共享的方案,由於沒有共享,所以自然也就沒有並發問題。
31 | Guarded Suspension模式:等待喚醒機制的規範實現
筆記
- 等待喚醒機制

- 場景:
- 服務調用方(生產者) 將消息 發動到 MQ。
- 服務提供方(消費者) 將消息 消費。
現在需要消費者消費完消息後,通知 生產者,然後生產者再響應其客戶端。
- 分析
- 生產者需要等待
- 消費者消費完需要通知生產者
- 方案
- 分析場景,其實就是一個非同步轉同步的過程
- 生產者等待 消費者通知 可以使用 管程實現
- 管程採用Lock + Condition 實現等待 和 通知的關鍵 需要找到一個將 生產者發送消息 和 消費者響應消息,將兩個消息對應到一個Condition
- 方案就是將消息對應的Condition快取起來 這樣的話就可以採用 **Key(msg.id) –> value(Condition)
- 當 上下游 生產者和消費者都是集群化部署,如何解決?
- 設計 MQ的topic = msg + ip 這樣就能保證 同一個節點消費的通知消息一定是 本節點生產的消息
- 場景:

32 | Balking模式:再談執行緒安全的單例模式
筆記
- 多執行緒版本的if
- 場景:
- 類似語雀,編輯完了需要保存。
- 首先需要維護一個變數「changed」標識當前文檔有沒有被修改
- 然後一個定時任務 定時執行自動保存任務。
偽程式碼如下所示
- 類似語雀,編輯完了需要保存。
- 場景:
//自動存檔操作
void autoSave(){
synchronized(this){//同步程式碼塊保證 對changed的讀和下面的寫互斥
if (!changed) {
return;
}
changed = false;
}
//執行存檔操作
//省略且實現
this.execSave();
}
//編輯操作
void edit(){
//省略編輯邏輯
......
synchronized(this){
changed = true;
}
}
- 針對上面的場景,總結成為一個並發設計模式 – Balking模式
- Balking 本質上是一種規範化的解決「多執行緒版本if」的方案
- Balking 模式範式 — 使用管程實現
boolean changed=false;
//自動存檔操作
void autoSave(){
synchronized(this){
if (!changed) {
return;
}
changed = false;
}
//執行存檔操作
//省略且實現
this.execSave();
}
//編輯操作
void edit(){
//省略編輯邏輯
......
change();
}
//改變狀態
void change(){
synchronized(this){
changed = true;
}
}
- volatile 實現Balking模式
- 對於上面使用 管程 實現的balking模式,是針對多執行緒版本的互斥方案。如果,在場景中不需要保證變數 changed 的互斥,可以採用volatile來實現
- 切記 使用 volatile 的前提是對原子性沒有要求。
仍然是上面的場景,如果對互斥要求不嚴格,表現在業務上,也就是如果多保存幾次也無所謂,那麼就可以去掉 管程 使用volatile來修飾_changed_變數。 - 重點 volatile實現Balking 的場景十分有限。只需要記住使用 volatile 的前提是對原子性沒有要求。 即可
課後思考
以下程式碼是為了保證 count只被計算一次。
class Test{
volatile boolean inited = false;
int count = 0;
void init(){
if(inited){//1
return;
}
inited = true;//2
//計算count的值
count = calc();//3
}
}
- 以上程式碼是否存在執行緒安全性問題?
- 當多個執行緒同時進入1處程式碼,也就意味著,這幾個想成都能完整執行2,3處的程式碼。所以count就有可能被計算多次。
總結
- 只執行一次的場景
- 場景:
SpringBoot 啟動流程的源碼中,refresh 方法只能被執行一次。 - 方案:保證程式碼絕對只執行一次最好的解決方案就是使用原子類AtomicBoolean。
AtomicBoolean.compareAndSet(false, true)。
- 場景:
- Balking 模式的啟發
- 之前實現的離線 license 可以通過 Balking 模式優化一般

