熔斷原理與實現Golang版
- 2020 年 10 月 28 日
- 筆記
在微服務中服務間依賴非常常見,比如評論服務依賴審核服務而審核服務又依賴反垃圾服務,當評論服務調用審核服務時,審核服務又調用反垃圾服務,而這時反垃圾服務超時了,由於審核服務依賴反垃圾服務,反垃圾服務超時導致審核服務邏輯一直等待,而這個時候評論服務又在一直調用審核服務,審核服務就有可能因為堆積了大量請求而導致服務宕機
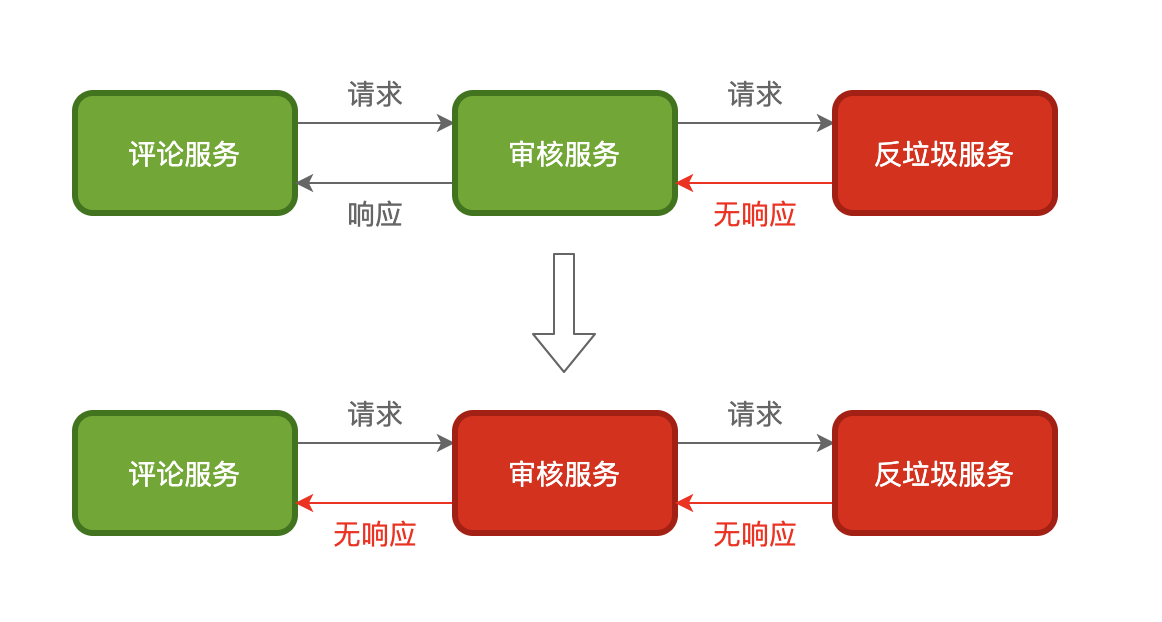
由此可見,在整個調用鏈中,中間的某一個環節出現異常就會引起上游調用服務出現一些列的問題,甚至導致整個調用鏈的服務都宕機,這是非常可怕的。因此一個服務作為調用方調用另一個服務時,為了防止被調用服務出現問題進而導致調用服務出現問題,所以調用服務需要進行自我保護,而保護的常用手段就是熔斷
熔斷器原理
熔斷機制其實是參考了我們日常生活中的保險絲的保護機制,當電路超負荷運行時,保險絲會自動的斷開,從而保證電路中的電器不受損害。而服務治理中的熔斷機制,指的是在發起服務調用的時候,如果被調用方返回的錯誤率超過一定的閾值,那麼後續的請求將不會真正發起請求,而是在調用方直接返回錯誤
在這種模式下,服務調用方為每一個調用服務(調用路徑)維護一個狀態機,在這個狀態機中有三個狀態:
- 關閉(Closed):在這種狀態下,我們需要一個計數器來記錄調用失敗的次數和總的請求次數,如果在某個時間窗口內,失敗的失敗率達到預設的閾值,則切換到斷開狀態,此時開啟一個超時時間,當到達該時間則切換到半關閉狀態,該超時時間是給了系統一次機會來修正導致調用失敗的錯誤,以回到正常的工作狀態。在關閉狀態下,調用錯誤是基於時間的,在特定的時間間隔內會重置,這能夠防止偶然錯誤導致熔斷器進去斷開狀態
- 打開(Open):在該狀態下,發起請求時會立即返回錯誤,一般會啟動一個超時計時器,當計時器超時後,狀態切換到半打開狀態,也可以設置一個定時器,定期的探測服務是否恢復
- 半打開(Half-Open):在該狀態下,允許應用程式一定數量的請求發往被調用服務,如果這些調用正常,那麼可以認為被調用服務已經恢復正常,此時熔斷器切換到關閉狀態,同時需要重置計數。如果這部分仍有調用失敗的情況,則認為被調用方仍然沒有恢復,熔斷器會切換到關閉狀態,然後重置計數器,半打開狀態能夠有效防止正在恢復中的服務被突然大量請求再次打垮
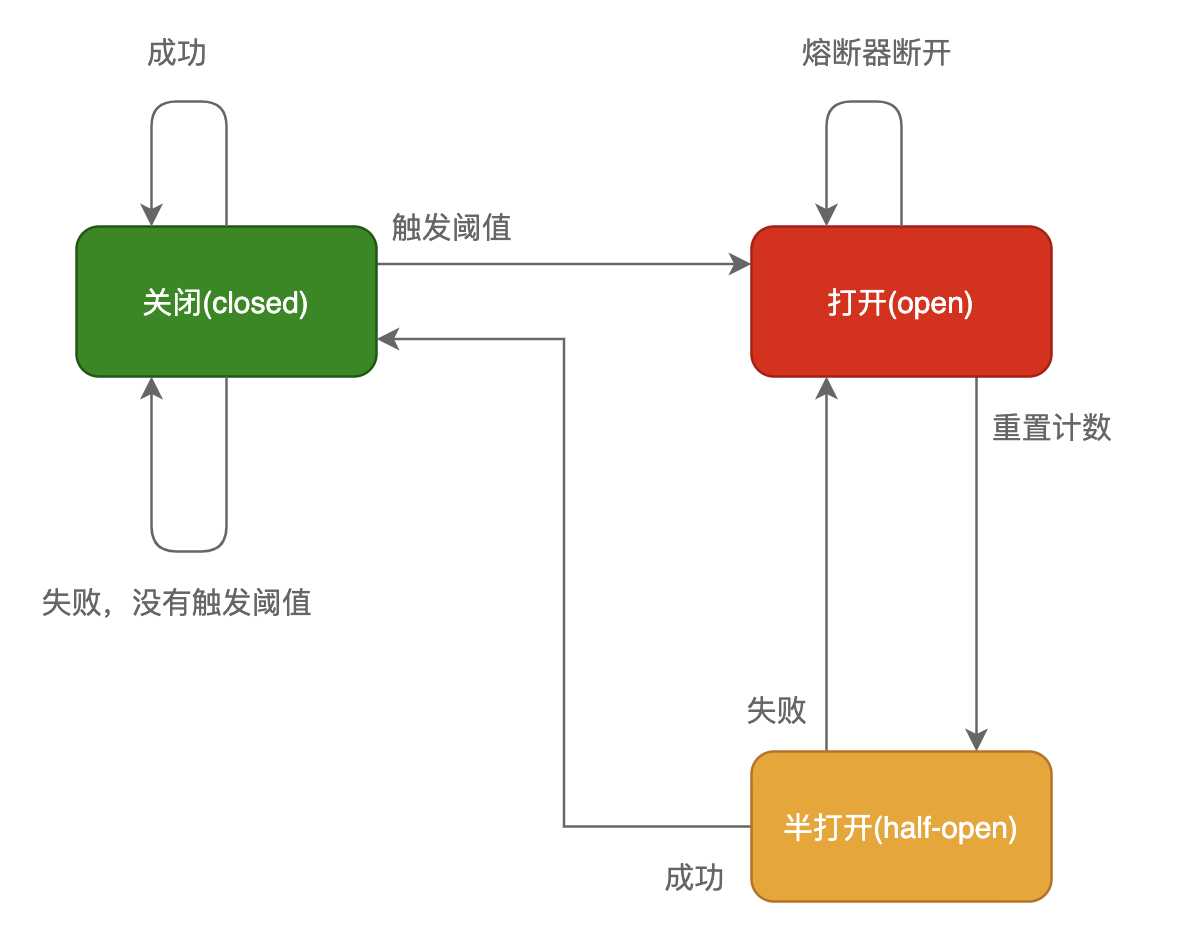
服務治理中引入熔斷機制,使得系統更加穩定和有彈性,在系統從錯誤中恢復的時候提供穩定性,並且減少了錯誤對系統性能的影響,可以快速拒絕可能導致錯誤的服務調用,而不需要等待真正的錯誤返回
熔斷器引入
上面介紹了熔斷器的原理,在了解完原理後,你是否有思考我們如何引入熔斷器呢?一種方案是在業務邏輯中可以加入熔斷器,但顯然是不夠優雅也不夠通用的,因此我們需要把熔斷器集成在框架內,在zRPC框架內就內置了熔斷器
我們知道,熔斷器主要是用來保護調用端,調用端在發起請求的時候需要先經過熔斷器,而客戶端攔截器正好兼具了這個這個功能,所以在zRPC框架內熔斷器是實現在客戶端攔截器內,攔截器的原理如下圖:
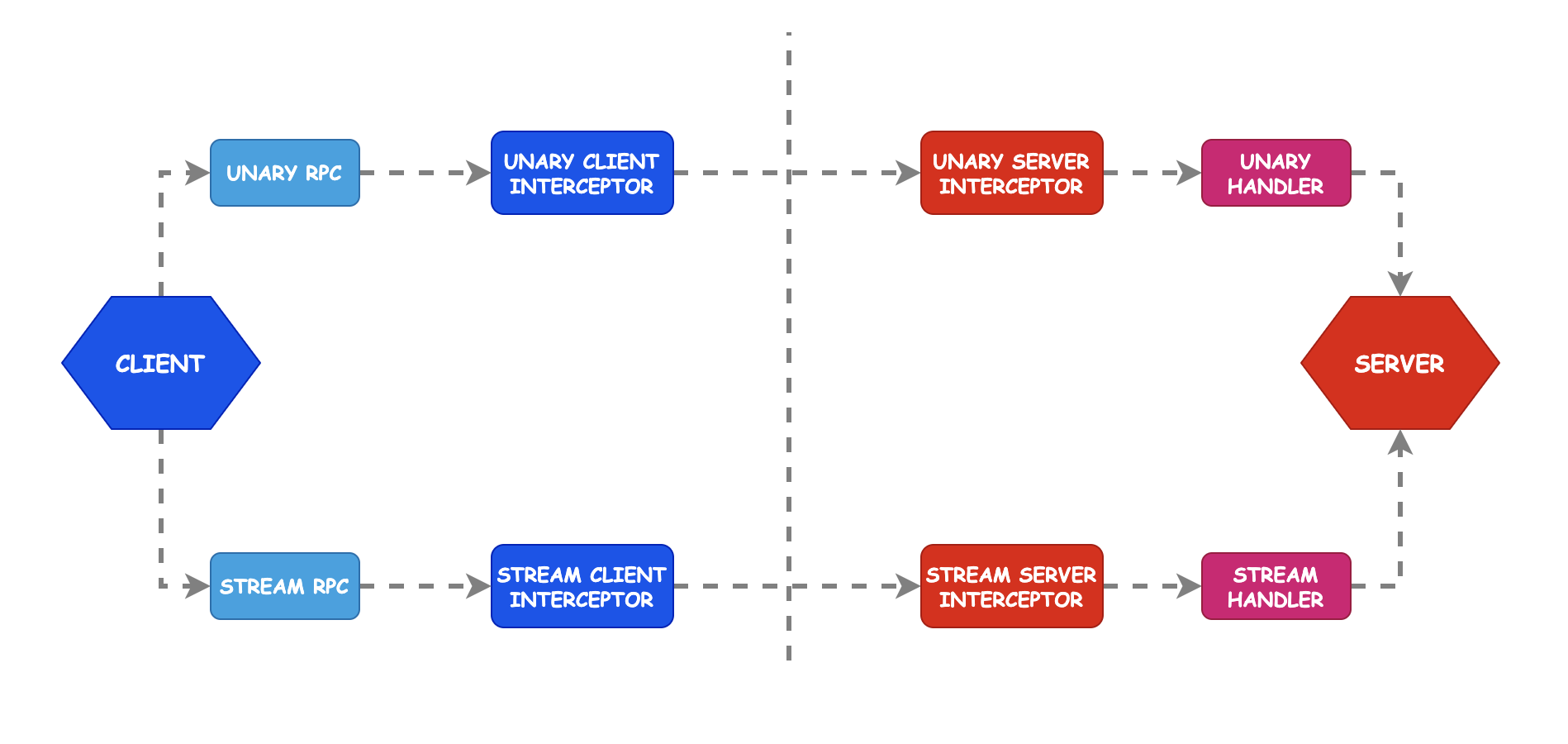
對應的程式碼為:
func BreakerInterceptor(ctx context.Context, method string, req, reply interface{},
cc *grpc.ClientConn, invoker grpc.UnaryInvoker, opts ...grpc.CallOption) error {
// 基於請求方法進行熔斷
breakerName := path.Join(cc.Target(), method)
return breaker.DoWithAcceptable(breakerName, func() error {
// 真正發起調用
return invoker(ctx, method, req, reply, cc, opts...)
// codes.Acceptable判斷哪種錯誤需要加入熔斷錯誤計數
}, codes.Acceptable)
}
熔斷器實現
zRPC中熔斷器的實現參考了Google Sre過載保護演算法,該演算法的原理如下:
- 請求數量(requests):調用方發起請求的數量總和
- 請求接受數量(accepts):被調用方正常處理的請求數量
在正常情況下,這兩個值是相等的,隨著被調用方服務出現異常開始拒絕請求,請求接受數量(accepts)的值開始逐漸小於請求數量(requests),這個時候調用方可以繼續發送請求,直到requests = K * accepts,一旦超過這個限制,熔斷器就回打開,新的請求會在本地以一定的概率被拋棄直接返回錯誤,概率的計算公式如下:
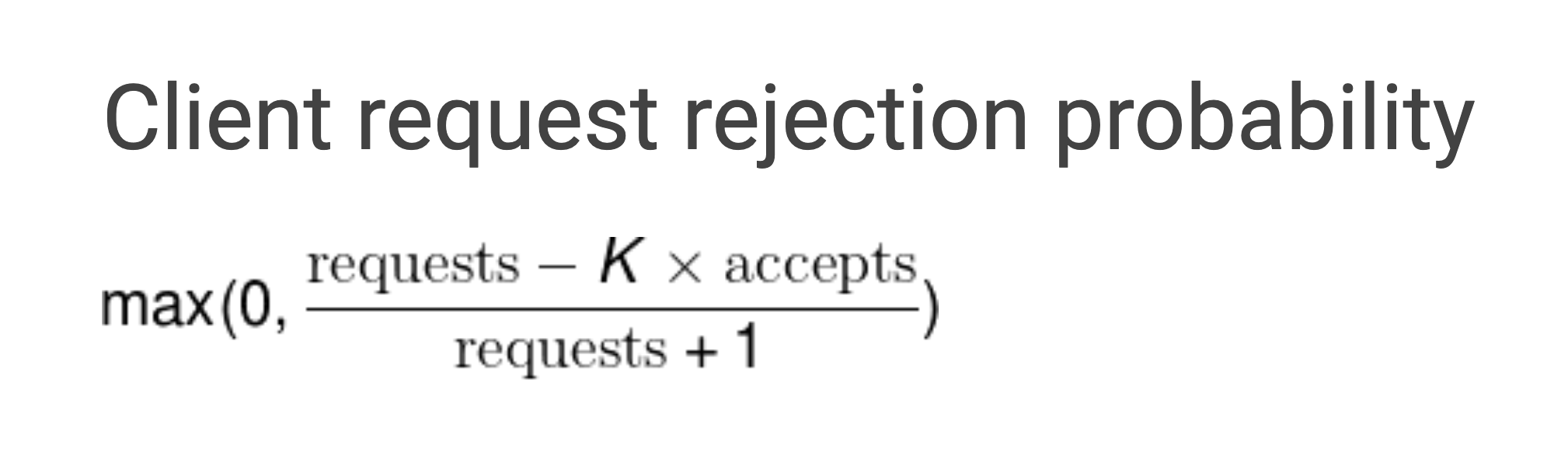
通過修改演算法中的K(倍值),可以調節熔斷器的敏感度,當降低該倍值會使自適應熔斷演算法更敏感,當增加該倍值會使得自適應熔斷演算法降低敏感度,舉例來說,假設將調用方的請求上限從 requests = 2 * acceptst 調整為 requests = 1.1 * accepts 那麼就意味著調用方每十個請求之中就有一個請求會觸發熔斷
程式碼路徑為go-zero/core/breaker
type googleBreaker struct {
k float64 // 倍值 默認1.5
stat *collection.RollingWindow // 滑動時間窗口,用來對請求失敗和成功計數
proba *mathx.Proba // 動態概率
}
自適應熔斷演算法實現
func (b *googleBreaker) accept() error {
accepts, total := b.history() // 請求接受數量和請求總量
weightedAccepts := b.k * float64(accepts)
// 計算丟棄請求概率
dropRatio := math.Max(0, (float64(total-protection)-weightedAccepts)/float64(total+1))
if dropRatio <= 0 {
return nil
}
// 動態判斷是否觸發熔斷
if b.proba.TrueOnProba(dropRatio) {
return ErrServiceUnavailable
}
return nil
}
每次發起請求會調用doReq方法,在這個方法中首先通過accept效驗是否觸發熔斷,acceptable用來判斷哪些error會計入失敗計數,定義如下:
func Acceptable(err error) bool {
switch status.Code(err) {
case codes.DeadlineExceeded, codes.Internal, codes.Unavailable, codes.DataLoss: // 異常請求錯誤
return false
default:
return true
}
}
如果請求正常則通過markSuccess把請求數量和請求接受數量都加一,如果請求不正常則只有請求數量會加一
func (b *googleBreaker) doReq(req func() error, fallback func(err error) error, acceptable Acceptable) error {
// 判斷是否觸發熔斷
if err := b.accept(); err != nil {
if fallback != nil {
return fallback(err)
} else {
return err
}
}
defer func() {
if e := recover(); e != nil {
b.markFailure()
panic(e)
}
}()
// 執行真正的調用
err := req()
// 正常請求計數
if acceptable(err) {
b.markSuccess()
} else {
// 異常請求計數
b.markFailure()
}
return err
}
總結
調用端可以通過熔斷機制進行自我保護,防止調用下游服務出現異常,或者耗時過長影響調用端的業務邏輯,很多功能完整的微服務框架都會內置熔斷器。其實,不僅微服務調用之間需要熔斷器,在調用依賴資源的時候,比如mysql、redis等也可以引入熔斷器的機制。


