Abductive Commonsense Reasoning —— 溯因推理
Abductive Commonsense Reasoning(溯因推理)
介紹
溯因推理是對不完全觀察情境的最合理解釋或假設的推論。
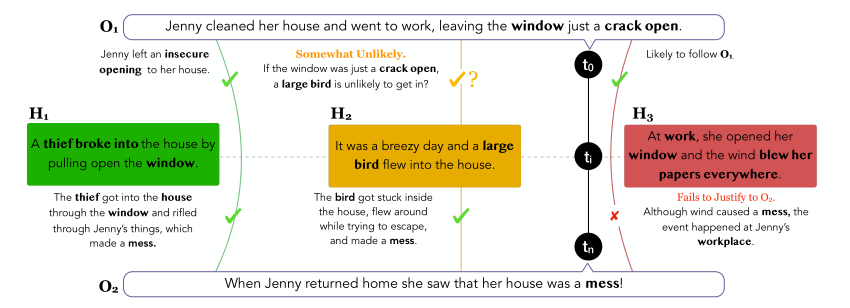
上圖給出的是一個簡明扼要的例子:
給定不同時間節點上的情境觀測值 \(O_{1}\) 和 \(O_{2}\) ,溯因推理的任務是從給出的一眾解釋性假設 \(H_{1}, \space H_{2}, \space \cdots ,H_{n}\) 中選出最合理的。例如,上圖在 \(t_{0}\) 時刻觀測到的情境 \(O_{1}\) 是:Jenny打掃好了房間並給窗戶留了條縫隙之後去工作了。而在 \(t_{n}\) 時刻,情境變成了:當Jenny回到家,發現房間里一片狼藉。針對這兩個觀測到的不同時間節點上情境,有若干個解釋性假設 \(H_{1}, \space H_{2}, \space H_{3}\)。
- 對於假設 \(H_{1}\) ,小偷的入室盜竊(broke into)很好的承接了 \(O_{1}\) 中」未關緊窗戶(a crack open)「帶來的安全隱患,並很好地解釋了情境 \(O_{2}\) 中房間為什麼一團亂(小偷翻東西),因此看上去假設 \(H_{1}\) 非常合理的解釋了情境 \(O_{1}\) 到情境 \(O_{2}\) 的轉換。
- 對於假設 \(H_{2}\) ,假設中提到的大隻的鳥(large bird)似乎不太可能從窗戶縫隙飛進房間,但是如果不考慮情境 \(O_{1}\),該假設可以很好地解釋房間亂的現象(鳥兒被困房間,為了逃離,弄得房間很亂)
- 對於假設 \(H_{3}\),前半部分(At work)可以很好地承接情境 \(O_{1}\)(Jenny去工作了,因此Jenny在工作中),但是該假設後半部分(blew her papers everywhere)完全沒法解釋情境 \(O_{2}\), 因為該假設完全指的是發生在辦公處的事情,而情境 \(O_{2}\) 則是Jenny家中的場景。
綜合以上對三個假設的考量,我們很容易得出,第一個假設是最符合情境 \(O_{1}\) 和 \(O_{2}\) 的。然而這看似簡單的推理過程,對於現有的模型來說,卻不是那麼容易的。
雖然長期以來」溯因「這種行為被認為是人們解讀、理解自然語言的核心,但受限於數據集的缺乏和模型的性能,支撐溯因自然語言推理和生成的研究卻相對較少。
ART數據集
ART(敘事文本中的溯因推理——ABDUCTIVE REASONING IN NARRATIVE TEXT)是第一個用於研究敘事文本中溯因推理的大規模基準數據集。其組成如下:
- 20K左右的敘述背景 ——成對的觀察結果<\(O
_{1}\space,O_{2}\)>- 這些觀察情境是根據ROCStories數據集進行編寫的。ROCStories是一個由五句話組成的手動精選短篇故事的大集合。它被設計為每個故事都有一個清晰的開始和結束,這自然對應到ART數據集中的 \(O_{1},O_{2}\) 。
- 超過200K的解釋性假設
- 按可能的解釋性假設 \(h^{+}\) 和不太可能的解釋性假設 \(h^{-}\) 進行眾包。對於 \(h^{-}\) 的眾包 ,要求眾包工人在 \(h^{+}\) 的基礎上,進行最小限度的編輯(最多改動5個單詞),為每個 \(h^{+}\) 創造不可信的假設變數 \(h^{-}\)。
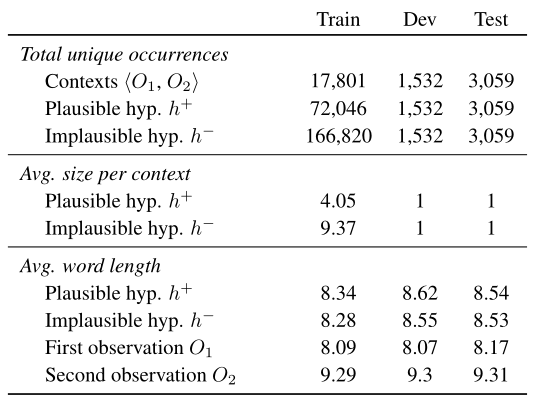
- 數據集分析
- 下面分別分析了訓練集、開發集、測試集上對應每個觀測的平均對應的正反解釋性假設的個數和假設及觀測文本句的平均詞長。
任務
論文中提出的兩個溯因推理任務分別是αNLI(溯因自然語言推理——Abductive Natural Language Inference)和αNLG(溯因自然語言生成 —— Abductive Natural Language Generation)。
ART數據集中每個例子按如下格式定義:
- \(O_{1}\) —— \(t_{1}\)時刻的觀察
- \(O_{2}\) —— \(t_{2}\)時刻的觀察
- \(h^{+}\) —— 對觀察 \(O_{1}\) 和觀察 \(O_{2}\) 的更合理的解釋
- \(h^{-}\) —— 對觀察 \(O_{1}\) 和觀察 \(O_{2}\) 來說不太合理的解釋
αNLI
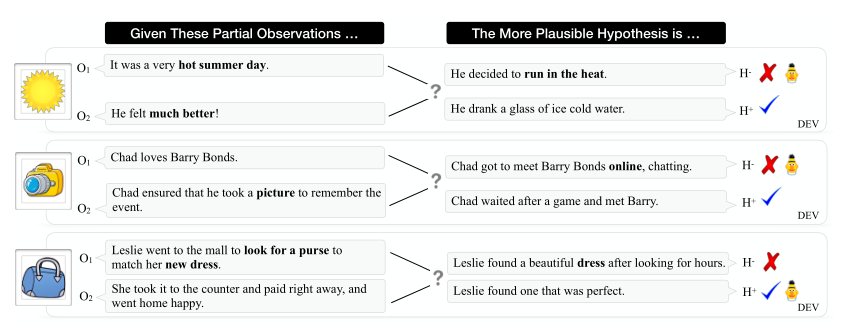
給定一對觀測和一對解釋性假設,αNLI的任務是選出兩個假設中更有可能的那個。
在概率框架下模型的目標函數為:
\]
根據貝葉斯法則,以觀測 \(O_{1}\) 為先驗條件,可以重寫上述公式:
\begin{aligned}
P\left(h^{i} \mid O_{1}, O_{2}\right) = \frac{P\left(O_{2}, O_{1}, h^{i}\right)}{P\left(O_{1} , O_{2}\right)} \\
=\frac{P\left(O_{2}\mid h^{i}, O_{1}\right)P\left(h^{i},O_{1}\right)}{P\left(O_{2}, O_{1}\right)} \\
=\frac{P\left(O_{2}\mid h^{i}, O_{1}\right)P\left(h^{i} \mid O_{1}\right)}{P\left(O_{2}\mid O_{1}\right)}
\end{aligned}
\end{equation}
\]
因為 \(P\left(O_{2}\mid O_{1}\right)\) 是定值,所求又是優化問題,所以可以僅考慮左側的目標函數與右側乘式的相關關係即可:
\]
根據上式,建立如下若干獨立性假設,為αNLI任務構建一套概率模型:

- \(H_{i}\) 與 \(O_{1},O_{2}\)都無關時(模型沒用到觀測值)
\]
-
\(H_{i}\) 僅與 \(O_{1},O_{2}\)其中一個有關(模型用到了一個觀測值)
-
線性鏈模型 —— \(H_{i}\) 與 \(O_{1},O_{2}\)都直接相關,但 \(O_{1} \perp O_{2}\) (模型使用兩個觀測值,但獨立地考慮了每個觀測值對假設的影響),
\]
- 全連接(模型使用兩個觀測值,結合兩個觀測值的資訊選擇合理的假設),目標函數為:
\]
在論文的實驗中,將不同的獨立性假設文本輸入BERT進行編碼。對於前兩個概率模型,可以通過簡單地將模型的輸入限制為相關變數來加強獨立性。另一方面,相關線性鏈模型將所有三個變數 \(O_{1},O_{2},H\) 都作為輸入,通過限制模型的形式以加強條件獨立性。具體來說,學習一個具有二分類功能的分類器:
\]
其中,\(\phi\) 和 \(\phi^{\prime}\) 為產生標量值的神經網路模型。
αNLG
給定 \(O_{1},O_{2},h^{+}\) 為一組的的訓練數據,αNLG的任務就是最大化 \(O_{1},O_{2},h^{+}\) 對應的文本句在生成模型中的生成概率。同時,還可以在給定兩個觀測的基礎上再添加背景知識 \(\text{K}\) 作為條件,模型的損失函數構造如下:
\]
其中,\(O_{1}=\left\{w_{1}^{o 1} \ldots w_{m}^{o 1}\right\}\) ,\(O_{2}=\left\{w_{1}^{o 2} \ldots w_{n}^{o 2}\right\}\),\(h^{+}=\left\{w_{1}^{h} \ldots w_{l}^{h}\right\}\),它們都由其自然語言文本對應的token組成。 \(w_{<i}^{h}\) 代表當前位置的前 \(i\) 個token,\(w_{i}^{h}\) 為當前位置 \(i\) 處的token。模型的訓練目標就是最大化句子的生成概率 \(P\),也即最小化上述公式的損失 \(L\)。
實驗結果
αNLI
αNLI任務被構造成了一個二分類問題。
Baseline
- SVM —— 利用Glove詞嵌入,考慮詞長度、詞的重疊和情感特徵等對兩個假設選項進行選擇。(50.6%)
- BOW —— 將兩個觀察和一個解釋性假設文本串接在一起,利用Glove為串接起來的文本構建句子嵌入,再通過一個全連接網路為包含每個不同的解釋性假設選項的句子的嵌入打分。(50.5%)
- Bi-LSTM + max-pooling —— 用Bi-LSTM編碼句子,使用經過最大池化後的句子嵌入進行打分。(50.8%)
可以看到,傳統分類器 + 上下文無關的單詞嵌入的方式對解決這個二分類問題看上去幾乎毫無作用(因為隨機二選一都有一般的概率選對)。
實驗模型
採用預訓練模型GPT和BERT編碼觀測和解釋性假設。
- 對於GPT,將觀測 \(O_{1}\) 和解釋性假設 \(H\) 串接在一起,然後使用 [SEP] 將其與觀測 \(O_{2}\) 分隔開,以[START] 和 [SEP] 結尾。
- 對於BERT,根據不同獨立性假設。有如下五種輸入的構造方式:

評估
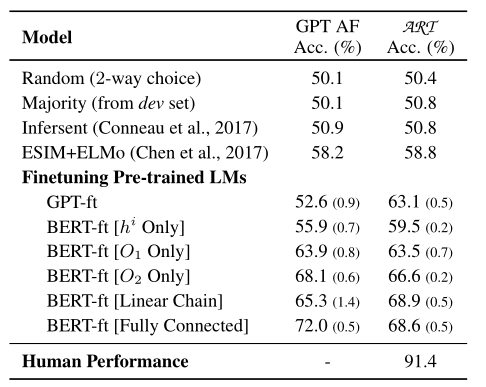
最後一列代表模型在論文提出的 \(\text{ART}\) 數據集上的表現,和前四個baseline相比,基於GPT和BERT構造的分類模型在數據集上的表現明顯提高了很多,最好的BERT-ft[Linear Chain]比最佳baseline提升了10.1個百分點,達到了68.9。但是和人類的表現相比,這樣的結果還是非常差的。因此,在溯因推理方面的研究還有很多工作要做。
αNLG
實驗模型
-
\(O_{1}-O_{2}-\text{Only}\) —— 以組成兩個觀測值 \(O_{1}\) 和 \(O_{2}\) 的token為起始訓練GPT2。
-
使用COMET生成ATOMIC格式(如果-那麼)的知識 —— 包含常識知識的圖,是一個以推理「如果-那麼」的知識為主的知識庫,它以事件作為節點,下列九大關係作為邊:
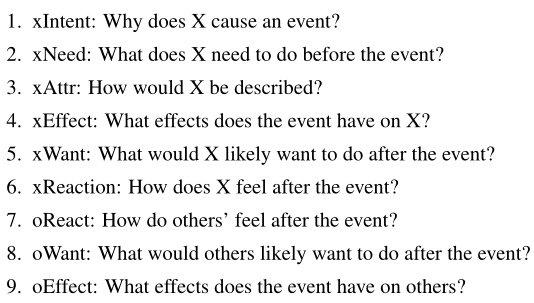
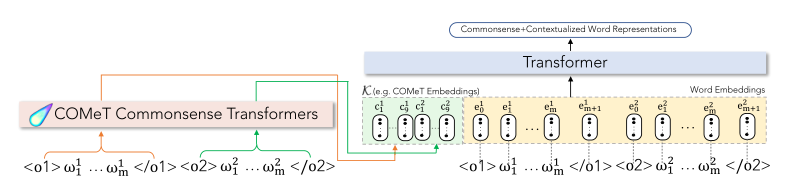
ATOMIC是對\(\text{ART}\) 數據集中的敘事上下文進行推理所需的背景常識的來源。COMET是基於ATOMIC訓練的專門實現常識知識圖自動構建的Transformer,這裡藉助COMET生成基於事件的常識推理知識,然後再GPT2中集成了COMET生成的資訊用於αNLG任務。集成方式分兩種:

- COMeT-Txt+GPT-2(作為文本短語的方式集成)
在單詞嵌入層嵌入輸入標記之後,我們在通過Transformer架構的層之前,向串接的觀察序列添加18個(對應於每個觀察的九個關係)自然語言文本,由GPT2進行編碼。
- COMeT-Emb+GPT2(作為嵌入的方式集成)
和上面那種方式一樣,不過在觀察序列前添加的是18個COMeT Embedding,這允許模型在處理COMeT嵌入時學習每個token的表示——有效地將背景常識知識集成到語言模型中。
評估
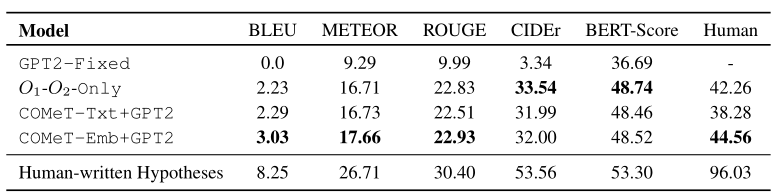
- 自動評估 —— BLEU、METEOR、ROUGE、CIDEr、BERT-Score
- 人工評估 —— 向眾包人員展示成對的觀察結果和一個生成的假設,要求他們標註該假設是否解釋了給定的觀察結果。最後一欄為對應的評估分數。人工編寫的假設在96%的情況下是正確的,而我們最好的生成模型,即使有背景常識知識的增強,也只能達到45%——這表明αNLG生成任務對當前最優越的文本生成器來說尤其具有挑戰性。
生成實例

結論
文章提出了第一項研究,調查基於語言的溯因推理的可行性。概念化並引入溯因自然語言推理(αNLI)——一個關注敘事語境中溯因推理的新任務。該任務被表述為一個選擇題回答問題。文章還介紹了溯因自然語言生成(αNLG)——一種新的任務,需要機器為給定的觀察結果生成可信的假設。為了支援這些任務,創建並引入了一個新的挑戰數據集ART,它由20k個常識性敘述和200k多個解釋性假設組成。在實驗中,基於最先進的NLI和語言模型建立了這一新任務的Baseline,其準確率為68.9%,與人類性能(91.4%)有相當大的差距。αNLG任務要困難得多——雖然人類可以寫出96%的有效解釋,但是當前表現最好模型只能達到45%。文章的分析讓我們對深度預訓練語言模型無法執行的推理類型有了新的見解——儘管預訓練模型在NLI蘊涵的密切相關但不同的任務中表現出色,但是在應對基於 \(\text{ART}\) 數據集提出的溯因推理和溯因生成任務時,表現卻差強人意,這為未來的研究指出了有趣的途徑。作者希望ART將成為未來基於語言的溯因推理研究的一個具有挑戰性的基準,並且αNLI和αNLG任務將鼓勵在人工智慧系統中實現複雜推理能力的表徵學習。


