EMNLP 2019 丨微軟亞洲研究院精選論文解讀
- 2019 年 11 月 13 日
- 筆記
閱讀大概需要18分鐘 跟隨小部落客,每天進步一丟丟
轉載:微軟研究院AI頭條
編者按:EMNLP 2019正於11月3日至11月7日在中國香港舉辦。本屆 EMNLP 大會中,微軟亞洲研究院共21篇論文入選,涵蓋預訓練、語義分析、機器翻譯等研究熱點。本文為大家介紹其中的7篇精選論文。
預訓練
可視化和理解 BERT 的有效性
Visualizing and Understanding the Effectiveness of BERT
論文鏈接:https://arxiv.org/abs/1908.05620
預訓練語言模型 BERT 等在很多 NLP 任務上取得了顯著提升,但大家對其有效性的原因尚未充分理解。本文通過可視化模型微調過程的損失表面和優化軌跡來嘗試理解 BERT 的有效性,發現預訓練過程可以使模型在下游任務上達到一個較好的初始點,並且微調 BERT 所得到的模型有更強的泛化能力。

圖1:微調 BERT 相對於從隨機初始化有著更廣闊且更平坦的優化區域
首先我們在不同任務上對比了微調 BERT 和從隨機初始化這兩種訓練方式,通過可視化它們的一維和二維訓練損失表面,可以看出微調 BERT 相對於從隨機初始化有著更廣闊且更平坦的優化區域。

圖2:微調 BERT 可以更直接地找到優化方向,並對過擬合更加魯棒
之後通過可視化微調 BERT 和從隨機初始化的優化軌跡,可以看出微調 BERT 可以更直接地找到優化方向,並且優化路徑更加平緩,這使其可以更快收斂。另外,我們發現即使在小數據(如 MRPC)上對模型微調更多的輪數,優化軌跡顯示其並未發生明顯的過擬合現象。

圖3:微調 BERT 在泛化誤差表面上有較大的局部最優區域,表明預訓練帶來更強的模型泛化能力
以往工作表明更廣闊、平坦的局部最優區域往往有更強的泛化能力。我們比較了微調 BERT 和隨機初始化,可以看出微調 BERT 在泛化誤差表面上依然有較大的局部最優區域,這與訓練損失表面一致,表明預訓練可以帶來更強的模型泛化能力。
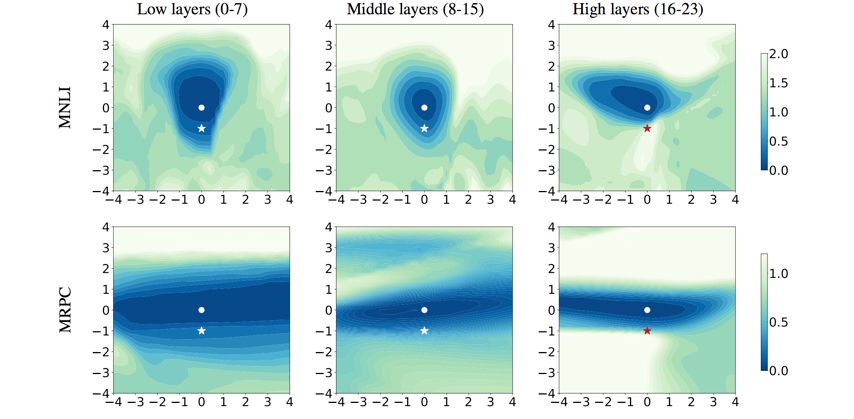
圖4:BERT 網路底層可遷移性更強,而高層則更多學習了和下游任務相關的知識
此外,本文還可視化了針對不同層的訓練損失表面,可以發現 BERT 較低層的損失表面有更廣闊的局部最優區域。說明了 BERT 網路底層可遷移性更強,而高層則更多學習了和下游任務相關的知識。
文本生成
利用規則和預訓練網路進行文本正式性風格遷移
Harnessing Pre-Trained Neural Networks with Rules for Formality Style Transfer
論文鏈接:https://aka.ms/AA6h0mm
文本正式性(Formality)的研究對於廣泛的自然語言處理應用都有著重要的作用,例如輔助非母語者的寫作助手和兒童教育等。隨著深度學習技術在自然語言領域的不斷發展,研究人員已經可以進行初步的非正式到正式文本的改寫。
本文從監督學習的角度對文本正式性改寫進行研究,主要關注由非正式文本到正式文本的改寫。傳統的基於監督學習的方法多從機器翻譯領域借鑒模型,例如直接使用 Seq2Seq 模型或 Transformer 模型基於平行語料進行訓練。研究人員的進一步研究表明使用經過規則處理的非正式文本與原始正式文本進行訓練可以得到更好的結果。我們發現引入規則的流水線式方法雖然有效降低了數據的複雜性,使模型能夠更容易地學習到一些複雜的模式,但由於規則自身的局限性,難免引入一些雜訊。如圖5所示,R & B 作為一個實體,應該保持大寫。

圖5:原始非正式文本與基於規則的方法的結果
我們希望能夠既引入規則的優點,也能剔除部分規則所帶來的雜訊。因此我們提出了三種利用原始非正式文本與基於規則的結果共同生成正式文本的方法,如圖6所示:Concatenate Fine-tuning 使用一個編碼器編碼拼接後的兩個輸入文本,並使用一個解碼器進行解碼;Decoder Ensemble 使用兩個編碼器和解碼器訓練兩個模型,並在推斷階段取兩個模型預測的概率分布的平均值;Separate Encoding with Hierarchical Attention 使用兩個編碼器對兩個輸入文本分別編碼,使用一個解碼器結合 Hierarchical Attention 進行解碼。

圖6:將規則融入生成模型的三種方式
本文採用了先進的預訓練語言模型——GPT2 來分別構建編碼器和解碼器。本文的編碼器-解碼器模型和 Transformer 的結構略有不同,如圖7所示,編碼器和解碼器都使用 GPT2 的 block 結構且不共享參數。

圖7:基於 GPT2 構建的編碼器-解碼器生成模型
本文在 GYAFC 數據集上進行了實驗,在 F&R 和 E&M 兩個 domain 上的結果如表1和表2所示:

表1:在 Family & Relationship 上的實驗結果

表2:在 Entertainment & Music 上的實驗結果
可以看到本文提出的 GPT-CAT(Concatenate Fine-tuning)方法在不同的場景下(domain 是否合併)都表現出了一致的最優結果,我們認為很可能是因為使用同一個編碼器進行編碼,使得兩個輸入文本在編碼階段得到了更多的交互,因此得到了更好的編碼表示。
開放域對話的無監督上下文改寫
Unsupervised Context Rewriting for Open Domain Conversation
論文鏈接:https://arxiv.org/abs/1910.08282
在聊天機器人中,多輪對話理解一直是一個非常困難的問題。目前,如果輸入是單輪對話,模型往往可以生成較好的回復,然而如果輸入是多輪對話,機器所給出的回復往往不盡如人意。為了解決這個問題,我們提出利用改寫的方法來幫助對上下文進行建模,將多輪對話輸入改寫為單輪對話輸入,如圖8所示。

圖8:將多輪對話輸入改寫為單輪輸入的示意圖
在這裡,我們使用多輪對話中的上下文資訊來改寫最後一輪的句子(query),在壓縮了上下文資訊的同時,也保留了對 query 最有用的資訊。利用改寫機制的好處在於:(1)改寫後的句子具有很好的可解釋性;(2)改寫後的 query 不依賴於下游任務,因此可以分別提升檢索式對話模型和生成式對話模型的效果;(3)改寫後的 query 可以使用單輪對話的模型,該類模型的效果相對於傳統的多輪對話模型較好,且計算量較小,適合線上系統。
利用改寫機制需要解決以下問題:(1)如何從上下文中抽取出有用的資訊;(2)如何將該部分資訊注入 query 中。為解決以上問題,我們採用無監督的方法來構造被改寫的語料,首先使用 Pointwise-Mutually-Information(PMI)演算法根據 query 和 response(回復的句子),抽取上下文中與其共現概率最大的若干詞作為關鍵資訊。再使用語言模型將這些資訊插入 query 中,計算不同插入位置的得分,進而得到被改寫的 query。但是在實際的應用場景中,我們無法得到 response 的資訊,所以我們採用一個基於複製網路(copy-net)的深度模型來學習這部分先驗知識,並使用這些構造好的數據作為訓練集,利用該訓練集進行多輪對話上下文改寫模型訓練(Context Rewriting Network)。

圖9:多輪對話上下文改寫模型
然而,基於無監督的改寫方式存在一定的噪音,我們無法保證抽取出來的關鍵詞是否有助於下游任務,尤其是存在檢索式和生成式對話模型這兩種不同任務。我們針對這兩種不同任務,分別採用不同的獎勵函數(Reward),採用強化學習方式對模型進行微調(fine-tune),最終使得我們的模型在生成式和檢索式任務上均超越 baseline。而且由於使用了不同的獎勵函數,我們經過強化學習後的微調模型也成功超越了原始模型。

表3:得到檢索候選後,將多輪對話改寫並進行匹配度計算結果

表4:端到端檢索結果人工評價

表5:端到端生成結果人工評價(其中3為最佳)
語義分析
利用多任務學習解決基於大規模知識圖譜的對話問答
Multi-Task Learning for Conversational Question Answering over a Large-Scale Knowledge Base
論文鏈接: https://arxiv.org/abs/1910.05069
基於大規模知識圖譜的對話問答在智慧私人助理系統(例如Cortana、Google Now、Siri、Alexa等)中起重要作用。近年來基於神經網路的語義解析(Semantic Parsing)方法在這個領域中取得了很大的進展。這種方法通過神經網路將自然語言轉化為機器可執行的邏輯表達式(Logical Form),然後通過在知識圖譜上執行邏輯表達式來獲得最終答案。
然而,大部分已有的工作主要採用一種分步的方法來解決這個問題。一種典型的方法是,首先進行實體識別並鏈接到知識圖譜中(Entity detection and linking),然後對謂詞進行分類(Predicate classification), 最後生成機器可執行的邏輯表達式(Logical form generation)。這種方法的缺陷是受 error propagation 影響較大,並且由於各個模組獨立進行訓練,不能充分利用監督資訊。
為了解決這些問題,本文提出一種基於多任務學習的方法。具體來說,我們將語義解析問題分解為兩個子問題:(1)實體識別;(2)帶實體位置的邏輯表達式生成。前者對帶有上下文的自然語言問句進行序列標註,每個 word 都被分類為{O, {B, I} X NT}, 其中 O 表示非 entity,B、I分別表示 entity 的開始和中間,NT 代表 entity 類型個數,通過這種帶有 entity 類型的實體識別,我們可以很好地解決實體鏈接(entity linking)過程中的歧義問題。後者通過 sequence to sequence with pointer network 來實現,將自然語言問句翻譯為帶實體位置的邏輯表達式,其中的實體由其在輸入中的位置來表示。最後通過多任務學習同時對兩個子問題進行學習。

圖10:多任務語義解析模型(MaSP)
這種方法具有以下優勢:(1)多任務學習有效地利用了所有的監督資訊;(2)由於上下文也同時輸入到模型中,可以有效地解決 coreference 和 ellipsis 問題;(3)在邏輯表達式生成過程中,通過預測實體位置而不是實體本身,可以有效地處理大規模知識圖譜中的大量實體;(4)實體識別中,通過預測實體的類型,可以有效地緩解實體鏈接過程中的歧義問題。在 CSQA 數據集上的實驗驗證了這個方法(MaSP)的有效性。

表6:基於 CSQA 數據集的實驗結果
機器翻譯
大規模利用單語數據進行神經機器翻譯
Exploiting Monolingual Data at Scale for Neural Machine Translation
論文鏈接:https://aka.ms/AA6i2nr
在機器翻譯中,目標語言端的無標數據被廣泛的利用,例如反向翻譯技術(back-translation)。相比之下,源語言端的無標數據並沒有被廣泛利用。本文系統地研究了如何同時利用源語言和目標語言端的無標數據,並提出了一種有效的數據使用流程。我們在 WMT 英德互譯和 WMT 德法互譯上驗證了演算法的有效性,並取得了非常優越的性能。
假設我們關注的是 X 和 Y 語言之間的互譯。我們要在給定的有標雙語數據集 B 上訓練 X->Y 和 Y->X 兩個翻譯模型,分別記做 f 和 g。同時,我們需要準備兩份無標數據 Mx 和 My,分別對應 X 和 Y 兩種語言。我們提出的演算法包括三步:
(1)無標註數據翻譯:我們將 Mx 中的每一個句子用 f 翻譯到 Y 語言,對 My 中的句子用 g 翻譯到 X 語言,得到兩個新的數據集合 Bs={(x, f(x))|x∈Mx}, Bt={(g(y),y)|y∈My}
(2)有雜訊訓練:我們給數據集 B、Bs 和 Bt 的源語言端都加上雜訊,包括隨機將單詞替換為<UNK>,隨機丟棄和隨機打亂單詞。在有雜訊的數據集上,我們訓練對應的模型 f1:X->Y 和 g1:Y->X。在此階段,我們建議使用大規模無標數據。
(3)微調:得到 f1 和 g1 之後,我們用在不同雙語數據上訓練得到的新的雙語模型f' 和 g' 來重新翻譯 Mx 和 My 無標數據得到 Bs' 和 Bt',在這份數據上再將 f1 和 g1 微調成最終的模型。
我們的實驗結果如表7所示。在第二階段,我們選用了120M(兩邊分別60M)無標數據。第三階段,使用40M(兩邊分別20M)無標數據。具體結果如下:

表7:實驗結果
可以看出每一個階段的結果都會有一定的提高,並且我們的方案取得了目前最好的結果。我們在德法互譯任務上也取得了類似的結果。
在文章中,我們對不同的數據使用方案也進行了詳細的討論和對比。簡單來說,我們驗證了:(1)源端和目標端的無標數據都是有用的;(2)有雜訊訓練這一階段對提升最終性能有幫助;(3)只使用源端或者目標端無標數據,效果不會隨著數據的增加而增加。如果同時使用上述兩種數據,在我們的實驗中,實驗效果會隨著數據的增多而得到提升。
利用訓練好的自回歸模型來優化非自回歸模型
Hint-Based Training for Non-Autoregressive Machine Translation
論文鏈接:https://arxiv.org/pdf/1909.06708.pdf
目前最先進的神經機器翻譯模型都採用自回歸概率分解,即在解碼過程中逐個生成目標詞語。這種計算模式在現有的並行硬體(如GPU)上受到限制,使得其具有較高的推理延遲。最近提出的非自回歸機器翻譯模型減少了模型所需要的時間,但只能達到較低的翻譯精度。為了提高非自回歸模型的翻譯精度,我們提出一種新的方法,利用訓練好的自回歸模型來幫助非自回歸模型的優化。

圖11:利用訓練好的自回歸模型來幫助非自回歸模型的優化流程
具體地,我們定義了兩種來源於自回歸模型的「提示」:來自隱狀態的提示與來自詞對齊與注意力機制的提示,並利用這些提示來正則化非自回歸模型的訓練。實驗結果顯示我們的新模型比之前的模型顯著提高了翻譯品質。具體地,針對 WMT14 英語-德語和德語-英語任務,我們分別得到了25.20和29.52 BLEU 值的結果,大幅超越之前的非自回歸翻譯基準線模型。
基於語言聚類的多語言機器翻譯
Multilingual Neural Machine Translation with Language Clustering
論文鏈接:https://arxiv.org/pdf/1908.09324.pdf
多語言機器翻譯通常使用一個模型支援多種語言的翻譯,對於簡化模型訓練過程、降低線上維護成本、提升低資源以及零資源翻譯有著極其重要的作用。然而,無論是用一個翻譯模型支援世界上數千種語言,還是每種語言都用各自的翻譯模型,代價都非常高。所以,比較實用的做法是用少數幾個模型支援所有的語言。在資源(比如模型的數量)給定的情況下,如何決定哪些語言可以同時被一個模型支援,對於多語言機器翻譯非常重要。在這個工作中,我們提出的方法將語言聚類到不同的類別中,每個類別分別用一個多語言翻譯模型來支援。我們研究了兩種聚類方法:(1)利用先驗知識來聚類;(2)利用語言向量來聚類。
在第一種基於先驗知識的聚類中,我們使用了語系(Language Family)的知識。一個語系代表一組有著共同祖先的相似語言組成的語言類別。我們選用了比較權威並且廣泛使用的 Ethnologue 語系分類法。在這個分類體系中,全球7472種語言被分類成152個語系。圖12展示了我們實驗中使用的23種語言所屬的語系分類。

圖12:語系分類
在第二種基於語言向量的聚類中,我們對所有語言訓練了一個多語言翻譯模型,並在模型中用語言向量來區分不同的語言,語言向量在多語言翻譯模型中一起被訓練,可以用來表示不同語言的特徵,如圖13所示。我們使用層次聚類法對得到的語言向量進行聚類。

圖13:在多語言機器翻譯模型中學習語言向量來進行聚類
下面是實驗評估,我們選用了 IWSLT 2011~2018年,英語和23種其它語言之間的翻譯對進行實驗。
首先看語言的聚類結果。基於先驗知識的聚類結果如上圖12所示。基於語言向量的聚類結果如圖14所示。我們有幾點發現:(1)語言向量能很好的捕獲語言的語系關係;(2)語言向量也能反映語言的形態學資訊;(3)語言向量還能捕獲語言的一些由於區域、文化以及歷史因素的影響形成的關係。具體分析可見論文。

圖14:基於語言向量的聚類結果
然後看語言聚類的翻譯精度,表8列出了英語到其它語言的實驗結果,最後一列為23個翻譯的 BLEU 平均值。可以看到基於語言向量(Embedding)的聚類方法得到的模型要好於基於語系(Family)的聚類,同時比一個模型支援所有語言(Universal)以及每個語言分別用各自的模型(Individual)要好。Universal 模型的翻譯精度較差,而 Individual 模型增加了離線訓練和在線維護成本,這也是本文工作要解決的問題。我們基於語言向量(Embedding)的聚類在只用5個模型的成本上,相比 Individual(成本為23個模型)在23個語言的平均 BLEU 高0.7,相比 Universal(成本為1個模型)的平均 BLEU 高2.08,顯示了我們的聚類方法對於降低模型訓練維護成本以及提升翻譯精度的有效性。更多實驗結果和分析參見論文。

表8:實驗結果