強化學習簡介及馬爾科夫決策過程
- 2019 年 11 月 13 日
- 筆記
1. 什麼是強化學習
強化學習(reinforcement learning, RL)是近年來大家提的非常多的一個概念,那麼,什麼叫強化學習?
強化學習是機器學習的一個分支,和監督學習,非監督學習並列。
參考文獻[1]中給出了定義:
Reinforcement learning is learning what to do —-how to map situations to actions —- so as to maximize a numerical reward signal.
即強化學習是通過學習將環境狀態轉化為動作的策略,從而獲得一個最大的回報。
舉個栗子[2],在flappy bird遊戲中,我們想設計一個獲得高分的策略,但是卻不清楚他的動力學模型等等。這是我們可以通過強化學習,讓智慧體自己進行遊戲,如果撞到柱子,則給負回報,否則給0回報。(也可以給不撞柱子持續給1點回報,撞柱子不給回報)。通過不斷的回饋,我們可以獲得一隻飛行技術高超的小鳥。
通過上面例子,我們可以看到強化學習的幾個特性[3]:
- 沒有label,只有獎勵(reward)
- 獎勵訊號不一定是實時的,很有可能延後的。
- 當前的行為影響後續接收到的數據
- 時間(序列)是一個重要因素
2. 強化學習的建模
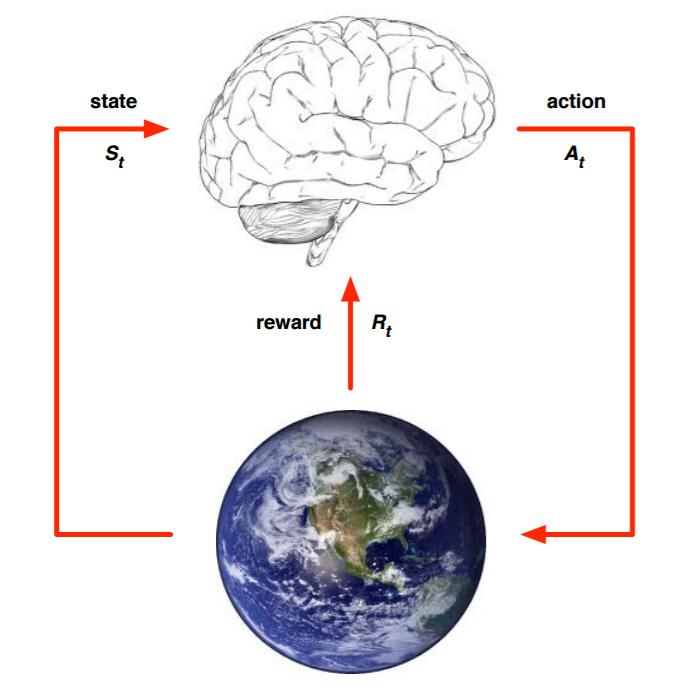
上面的大腦代表我們的智慧體,智慧體通過選擇合適的動作(Action)(A_t),地球代表我們要研究的環境,它擁有自己的狀態模型,智慧體選擇了合適的動作(A_t),環境的狀態(S_t)發生改變,變為(S_{t+1}),同時獲得我們採取動作(A_t)的延遲獎勵(R_t),然後選擇下一個合適的動作,環境狀態繼續改變……這就是強化學習的思路。
在這個強化學習的思路中,整理出如下要素[4]:
(1)環境的狀態(S),(t)時刻環境的狀態(S_t)是它的環境狀態集中的某一個狀態;
(2)智慧體的動作(A),(t)時刻智慧體採取的動作(A_t)是它的動作集中的某一個動作;
(3)環境的獎勵(R),(t)時刻智慧體在狀態(S_t)採取的動作(A_t)對應的獎勵(R_{t+1})會在(t+1)時刻得到;
除此之外,還有更多複雜的模型要素:
(4)智慧體的策略(pi),它代表了智慧體採取動作的依據,即智慧體會依據策略(pi)選擇動作。最常見的策略表達方式是一個條件概率分布(pi(a|s)),即在狀態(s)時採取動作(a)的概率。即(pi(a|s)=P(A_t=a|S_t=s)),概率越大,動作越可能被選擇;
(5)智慧體在策略(pi)和狀態(s)時,採取行動後的價值(v_pi(s))。價值一般是一個期望函數。雖然當前動作會對應一個延遲獎勵(R_{t+1}),但是光看這個延遲獎勵是不行的,因為當前的延遲獎勵高,不代表到(t+1,t+2,dots)時刻的後續獎勵也高, 比如下象棋,我們可以某個動作可以吃掉對方的車,這個延時獎勵是很高,但是接著後面我們輸棋了。此時吃車的動作獎勵值高但是價值並不高。因此我們的價值要綜合考慮當前的延時獎勵和後續的延時獎勵。 (v_pi(s))一般表達為:
[ v_pi(s)=E(R_{t+1}+gamma R_{t+2}+gamma^2R_{t+3}+dots|S_t=s) ]
(6)其中(gamma)作為獎勵衰減因子,在([0,1])之間,如果為0,則是貪婪法,即價值只有當前延遲獎勵決定。如果為1,則所有的後續狀態獎勵和當前獎勵一視同仁。大多數時間選擇一個0到1之間的數字
(7) 環境的狀態轉化模型,可以理解為一個狀態概率機,它可以表示為一個概率模型,即在狀態(s)下採取動作(a),轉到下一個狀態(s^{'})的概率,表示為(P_{ss{'}}^{a})
(8)探索率$epsilon (主要用在強化學習訓練迭代過程中,由於我們一般會選擇使當前輪迭代價值最大的動作,但是這會導致一些較好的但我們沒有執行過的動作被錯過。因此我們在訓練選擇最優動作時,會有一定的概率)epsilon $不選擇使當前輪迭代價值最大的動作,而選擇其他的動作。
3.馬爾科夫決策過程(Markov Decision Process ,MDP)
環境的狀態轉化模型,表示為一個概率模型(P_{ss{'}}^{a}),它可以表示為一個概率模型,即在狀態(s)下採取動作(a),轉到下一個狀態(s^{'})的概率。在真實的環境轉化中,轉化到下一個狀態(s{'})的概率既和上一個狀態(s)有關,還和上一個狀態,以及上上個狀態有關。這樣我們的環境轉化模型非常非常非常複雜,複雜到難以建模。
因此,我們需要對強化學習的環境轉化模型進行簡化。簡化的方法就是假設狀態轉化的馬爾科夫性:轉化到下一個狀態(s{'})的概率僅和當前狀態(s)有關,與之前狀態無關,用公式表示就是:
[ P_{ss'}^{a}=E(S_{t+1}=s'|S_t=s,A_t=a) ]
同時對於第四個要素策略(pi),我們也進行了馬爾科夫假設,即在狀態(s)下採取動作(a)的概率僅和當前狀態(s)有關,和其他要素無關:
[ pi(a|s)=P(A_t=a|S_t=s) ]
價值函數(v_pi(s))的馬爾科夫假設:
[ v_pi(s)=E(G_t|S_t=s)=E_pi(R_{t+1}+gamma R_{t+2}+gamma^2R_{t+3}+dots|S_t=s) ]
(G_t)表示收穫(return), 是一個MDP中從某一個狀態(S_t)開始取樣直到終止狀態時所有獎勵的有衰減的之和。
推導價值函數的遞推關係,很容易得到以下公式:
[ v_pi(s)=E_pi(R_{t+1}+gamma v_pi(S_{t+1})|S_t=s) ]
上式一般稱之為貝爾曼方程,它表示,一個狀態的價值由該狀態以及後續狀態價值按一定的衰減比例聯合組成。
4. 動作價值函數及貝爾曼方程
對於馬爾科夫決策過程,我們發現它的價值函數(v_pi(s))沒有考慮動作,僅僅代表了當前狀態採取某種策略到最終步驟的價值,現在考慮採取的動作帶來的影響:
[ q_pi{(s,a)}=E(G_t|S_t=s,A_t=a)=E_pi(R_{t+1}+gamma R_{t+2}+gamma^2R_{t+3}+dots|S_t=s,A_t=a) ]
動作價值函數(q_pi(s,a))的貝爾曼方程:
[ q_pi(s,a)=E_pi(R_{t+1}+gamma q_pi(S_{t+1},A_{t+1})|S_t=s,A_t=a) ]
按照定義,很容易得到動作價值函數(q_pi(s,a))和狀態價值函數(v_pi(s))的關係:
[ v_pi(s)=sum_{ain A}pi(a|s)q_pi(s,a) ]
也就是說,狀態價值函數是所有動作價值函數基於策略(pi)的期望。
同時,利用貝爾曼方程,我們利用狀態價值函數(v_pi(s))表示動作價值函數(q_pi(s,a)),即:
[ q_pi(s,a)=E_pi(R_{t+1}+gamma q_pi(S_{t+1},A_{t+1})|S_t=s,A_t=a) ]
[ =E_pi(R_{t+1}|S_t=s,A_t=a)+gamma E_pi(q_pi(S_{t+1},A_{t+1})|S_t=s,A_t=a) ]
[ =R_s^a+gamma sum_{s'}P_{ss'}^{a}sum_{a'}pi(a'|s')q_pi(s',a') ]
[ =R_s^a+gamma sum_{s'}P_{ss'}^av_pi(s') ]
公式5和公式12總結起來,我們可以得到下面兩式:
[ v_pi(s)=sum_{a in A}pi(a|s)(R_s^a+gamma sum_{s'}P_{ss'}^av_pi(s')) ]
[ q_pi(s,a)=R_s^a+gamma sum_{s'}P_{ss'}^av_pi(s') ]
5. 最優價值函數
解決強化學習問題意味著要尋找一個最優的策略讓個體在與環境交互過程中獲得始終比其它策略都要多的收穫,這個最優策略我們可以用 (pi^*)表示。一旦找到這個最優策略 (pi^*),那麼我們就解決了這個強化學習問題。一般來說,比較難去找到一個最優策略,但是可以通過比較若干不同策略的優劣來確定一個較好的策略,也就是局部最優解。
如何比較策略優劣?一般通過對應的價值函數進行比較:
[ v_{*}(s)=max _{pi} v_{pi}(s)=max_pi sum_api(a | s) q_{pi}(s, a)=max _{a} q_{*}(s, a) ]
或者最優化動作價值函數:
[ q_{*}(s, a)=max _{pi} q_{pi}(s, a) ]
[ =R_s^a+gamma max_pi v_pi(s') ]
狀態價值函數(v)描述了一個狀態的長期最優化價值,即在這個狀態下考慮到所有可能發生的後續動作,並且都挑選最優動作執行的情況下,這個狀態的價值。
動作價值函數(q)描述了處於一個狀態,並且執行了某個動作後,所帶來的長期最有價值。即在這個狀態下執行某一特定動作後,考慮再之後所有可能處於的狀態下總是選取最優動作來執行所帶來的長期價值。
對於最優的策略,基於動作價值函數我們可以定義為:
[ pi_{*}(a | s)=left{begin{array}{ll}{1} & {text { if } a=arg max _{a in A} q_{*}(s, a)} \ {0} & {text { else }}end{array}right. ]
只要我們找到了最大的狀態價值函數或者動作價值函數,那麼對應的策略(pi^*)就是我們強化學習問題的解。
6.強化學習的實例
關於強化學習的實例,具體可參見[4]和[5],很強,很棒。
7.思考
在很多人的文章中,將強化學習訓練的模型被稱之為「智慧體」,為什麼呢?因為它和我們人類學習的思路很相似:
模型在沒有樣本的情況下,主動去探索,然後從環境中獲取一個(延遲)回饋,然後通過回饋進行反思,優化策略/動作,最終學習成為一個強大的智慧體。
當然,強化學習還擁有一些缺點[6]:
-
樣本利用率低,需要用大量樣本進行訓練。並且有時訓練速度還很慢(遠遠低於人類)。
-
獎勵函數難以設計。大部分的獎勵函數都是0,過於稀疏。
-
容易陷入局部最優。文獻[6]中例子指出,一個以速度為獎勵函數的馬,可以四角朝天的「奔跑」。
-
對環境的過擬合。往往沒辦法一個模型用於多個環境。
-
不穩定性。 不穩定對於一個模型是災難性的。一個超參數的變化可能引起模型的崩潰。
當然,我們不能一味肯定,也不能一味否定,強化學習在AUTOML,AlphaGO的成功應用也說明了強化學習儘管會有很多困難,但是也是具有一個具有探索性、啟發性的方向。
[1] R.Sutton et al. Reinforcement learning: An introduction , 1998
[2] https://www.cnblogs.com/jinxulin/p/3511298.html
[3] https://zhuanlan.zhihu.com/p/28084904
[4] https://www.cnblogs.com/pinard/p/9385570.html
[5] https://www.cnblogs.com/pinard/p/9426283.html
[6] https://www.alexirpan.com/2018/02/14/rl-hard.html
本文由飛劍客原創,如需轉載,請聯繫私信聯繫知乎:@AndyChanCD


