梯度消失和梯度爆炸及解決方案
梯度在神經網路中的作用
在談梯度消失和梯度爆炸的問題之前,我們先來考慮一下為什麼我們要利用梯度,同時鋪墊一些公式,以便於後面的理解。
存在梯度消失和梯度爆炸問題的根本原因就是我們在深度神網路中利用反向傳播的思想來進行權重的更新。即根據損失函數計算出的誤差,然後通過梯度反向傳播來減小誤差、更新權重。
我們假設,存在一個如圖所示的簡單神經網路,我們可以得到相關的公式如右側所示:

其中函數 g 是激活函數,c 是偏置值,t 是目標值,E 是損失函數,這裡利用的是平方誤差損失函數。我們可以很清晰的看出,其實整個神經網路就是一個複合函數:
\]
帶入到損失函數中,公式如下:
\]
為了便於討論,我們對上面的神經網路進行簡化,簡化為每一層只有一個節點的網路,這樣我們的公式也可以相應的簡化:
\]
\]
這樣我們的目的就變得更加明確,整個函數中需要調整的就是 \(c\) 和 \(b_1\) 這兩個偏置值以及 \(v_1\) 和 \(w_{11}\) 這兩個權重。
我們假設權重空間如圖所示,其中 cost function 就是上面的 E, State Space 就是上面的 \(c\) 和 \(b_1\) 這兩個偏置值以及 \(v_1\) 和 \(w_{11}\) 這兩個權重:

因為我們知道我們的目的是找到最小的 E,所以需要通過調整 \(c\) 和 \(b_1\) 這兩個偏置值以及 \(v_1\) 和 \(w_{11}\) 這兩個權重的值,來找到圖中的 Global Minimum,即 E 最小的點。這一類尋找最小值的問題,在數學上利用梯度下降演算法可以有效的解決。
梯度消失的原因
我們利用上面提到的公式來說明梯度消失產生的原因,求代價函數對 \(w_{11}\) 的偏導數:
\]
假設,當我們的激活函數使用 Sigmoid 函數的時候,如果 Sigmoid 公式為:
\]
帶入替換 g() 後,公式變為:
\]
根據上述公式,我們可以得出,Sigmoid函數的導數影像如下所示:

而我們神經網路中的初始權值也一般是小於 1 的數,所以相當於公式中是多個小於 1 的數在不斷的相乘,導致乘積和還很小。這只是有兩層的時候,如果層數不斷增多,乘積和會越來越趨近於 0,以至於當層數過多的時候,最底層的梯度會趨近於 0,無法進行更新,並且 Sigmoid 函數也會因為初始權值過小而趨近於 0,導致斜率趨近於 0,也導致了無法更新。
除了這個情況以外,還有一個情況會產生梯度消失的問題,即當我們的權重設置的過大時候,較高的層的激活函數會產生飽和現象,如果利用 Sigmoid 函數可能會無限趨近於 1,這個時候斜率接近 0,最終計算的梯度一樣也會接近 0, 最終導致無法更新。
可以參考如下圖片,底層要比高層的學習速度低特別多。

梯度爆炸的原因
當我們取得的權重值為一個中間值的時候,如果這個中間值使 \(S'(s)w > 1\) ,那麼會導致網路的底層會比高層的梯度變化更快,則就會導致梯度爆炸(激增)的問題。
避免梯度消失和梯度爆炸的方案
-
使用新的激活函數
- Sigmoid 函數 和 雙曲正切函數都會導致梯度消失的問題。ReLU 函數當 x < 0,的時候一樣會導致無法學習。
- 利用一些改進的 ReLU 可以在一定程度上避免梯度消失的問題。例如,ELU 和 Leaky ReLU,這些都是 ReLU 的變體。
-
權重初始化
在初始化權重的時候,使權重滿足如下公式:
\]
其中 \(G_1\) 是估計的激活函數的平均值,\(n^{out}_i\) 是第 i 層神經網路上向外連接的平均值
-
批量規範化
我們要規範化一個特定層節點的激活,利用如下公式:
\[\hat{x}_k^{(i)} = \frac{x_k^{(i)} – Mean[x_k^{(i)}]}{\sqrt{Var[x_k^{(i)}]}}
\]然後我們利用自己的自定義平均值和方差來移動和調整它,並且用反向傳播進行訓練
\[y_k^{(i)} = \beta_k^{(i)} + \gamma_k^{(i)}\times \hat{x}_k^{(i)}
\] -
長短記憶網路(LSTM)
-
逐層無監督預訓練(layer-wise unsupervised pre-training)
-
殘差網路(Residual Network)
- 在傳統網路的基礎,在兩個連續的堆疊層上增加一個到輸出的直接連接,也叫跳過連接,使這些層分流。
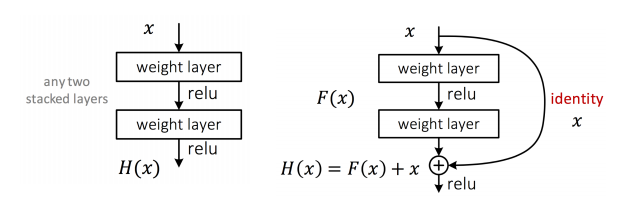
- \(F(x)\) 被稱為一個 residual component,主要是糾正以前層的錯誤或者提供前一層計算不出的額外的細節
- 如果超過了 100 層需要在添加殘差之前就使用 ReLU 而不是之後。這個過程被叫做 identity skip connection。
-
梯度截斷



