自動機器學習(AutoML)綜述
論文: AutoML: Survey of the State-of-the-Art
下面這個網站會不斷更新AutoML相關的論文,當然如果你的論文未被收錄,你也可以手動上傳你的論文讓更多人看到:
1、文章結構
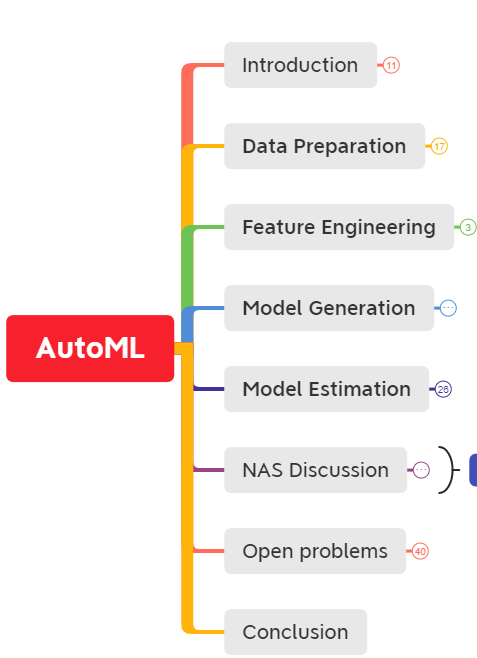
下面是整個AutoML的pipeline,全文也是圍繞這個pipeline對AutoML技術做了回顧和總結。
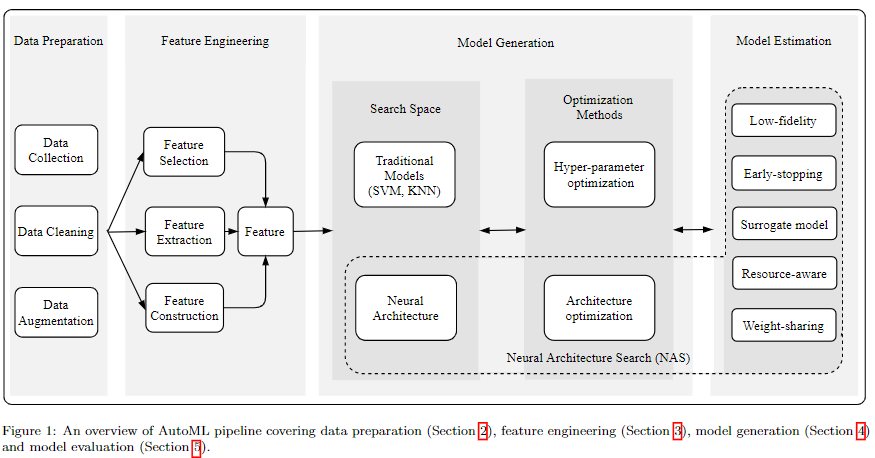
下表總結了目前現有的AutoML相關的綜述,我們的survey涵蓋了更廣的範圍,並且將2020年已發表在會議或期刊上的很多論文都整理在內。其他綜述寫的都很棒,都有很高的參考價值。
下面的內容會對論文做一個簡單的總結,不會涉及到太多的細節,感興趣的朋友可以移步最上面的鏈接閱讀原文。
2、Data preparation
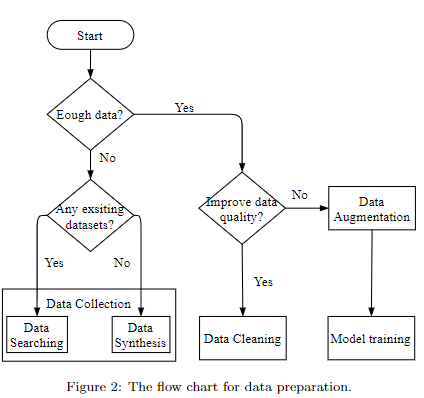
上圖是數據準備的流程圖,涉及到的技術有:
- data searching
- data synthesis
- data cleaning
- data augmentation
- 這裡介紹了一些自動數據增強的演算法,即不需要人工設計,而是通過演算法為特定任務設計一套數據增強操作。
具體細節可參閱原文。
3、Neural architecture search (NAS)
由前面的pipeline可以看到NAS技術主要有三個部分組成:
- search space:定義了網路結構的範式。我們論文主要關注神經網路架構,因此像SVM這種傳統機器學習模型的search space我們沒有做過多介紹。
- architecture optimization (AO): 定義了如何搜索網路結構。在一些論文里也稱作search strategy或search policy等,也有不少論文稱之為architecture optimization,本文選擇這個的原因也是為了和hyperparameter optimization (HPO) 統一起來,即二者都是優化演算法,只不過HPO一般是指優化像學習率或者batch size這樣的超參數,而AO則是優化網路結構。
- model estimation:找到一個模型後,我們需要評估它以此來判斷模型的好壞。
在之前版本里,我們將architecture也視為了超參數的一種,這個可能會引起歧義,而且目前NAS社區大多數論文都將architecture和hyperparameter區分開來的,所以為了方便理解,該版本也對architecture和hyperparameter做了區分。
3.1 Search space
主要有如下四種search space:
- entire-structured search space
直接設計出一個完整的網路結構,即每一層代表一個操作,該操作是從預設定的search space里選擇的;然後層與層之間可以跳躍連接。這樣設計的主要問題是設計出來的模型缺乏可遷移性,不太好擴展。
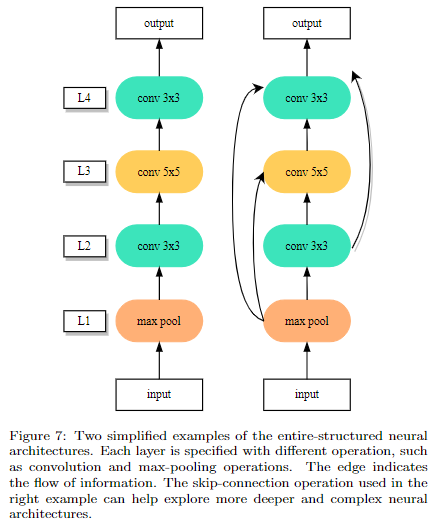
- Cell-based search space
為了解決上個方式的問題,Cell-based,顧名思義,就是先搜索出一個表現最好的cell結構,然後堆疊cell來得到最終的模型。
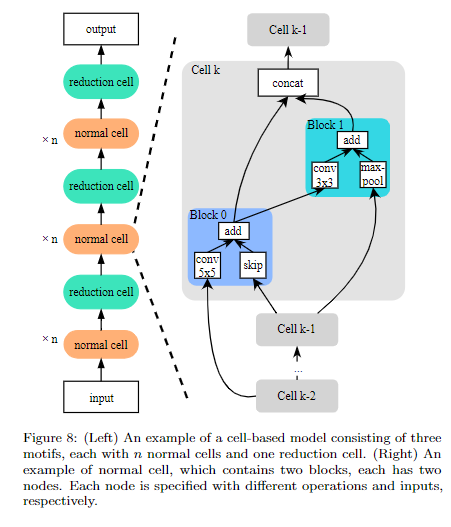
- Hierarchical search space
cell-based 有個缺點就是cell 結構其實是人為固定好的,比如你需要提前設置好一個cell是由幾個node組成的。而且最後只是簡單地堆疊重複的cell得到最終模型,這樣的設計範式也是存在局限性的。下面兩種搜索空間使得cell結構的可能性更多。
第一種是將cell分成若干個level,高level的cell由低level的cell組成
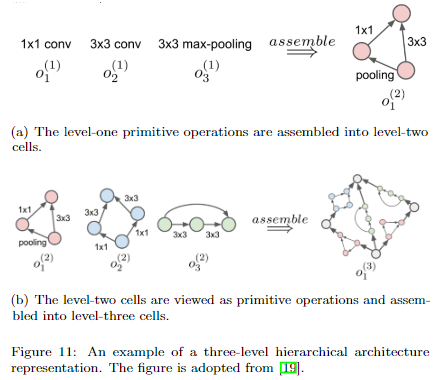
另一種是以MnasNet為代表的方法,即每一層是一個cell,每個cell由若干個block組成,block的數量是可以搜索的。另外每個cell內部的block結構是一樣的,但是不同的cell之間的block是不一樣的。
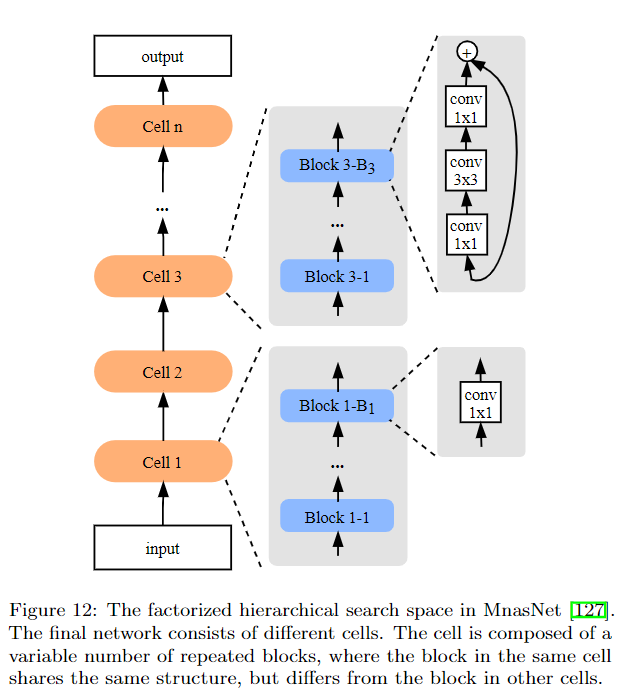
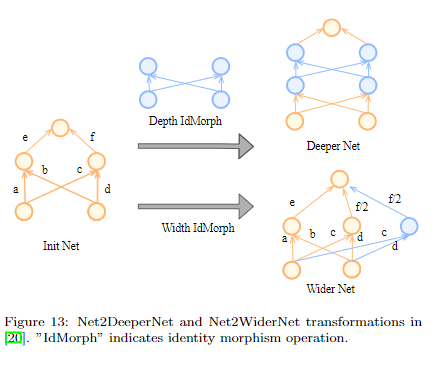
- Morphism-based search space
這種方式簡單理解就是可以基於現有的模型進行擴展,比如模型加寬、加深,或者把某一個操作替換成其他操作等。
3.2 Architecture Optimization
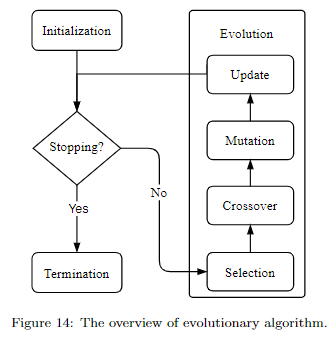
- Evolutionary Algorithm
進化演算法其實就是借鑒的生物進化,主要包括四步:
- selection:選擇父母網路,用於生成子網路
- crossover:可以簡單理解成子網路獲取父母網路的資訊
- mutation:子網路的部分資訊發生突變,這樣可以得到更多種類的網路結構
- update:更新網路數量,因為生成的網路越多,消耗的資源也越多。而資源是有限的,所以需要控制網路總數,一般可以通過淘汰表現差的或老的來控制模型的數量。
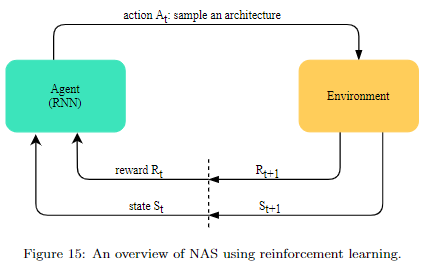
- Reinforcement Learning
如果對這類方法還不熟悉的,建議閱讀ENAS論文或之前的文章論文筆記系列-Efficient Neural Architecture Search via Parameter Sharing,這裡不做過多介紹。
- Surrogate model-based optimization (SMBO)
SMBO簡單理解就使用一個代理模型(比如Gaussian process)來預測生成的模型的性能,進而加快搜索效率。

- Random & Grid search
random search被好幾個論文證明了它也是非常有效的,有的時候甚至超過了一些「花里胡哨」的方法。
(真.玄.學)
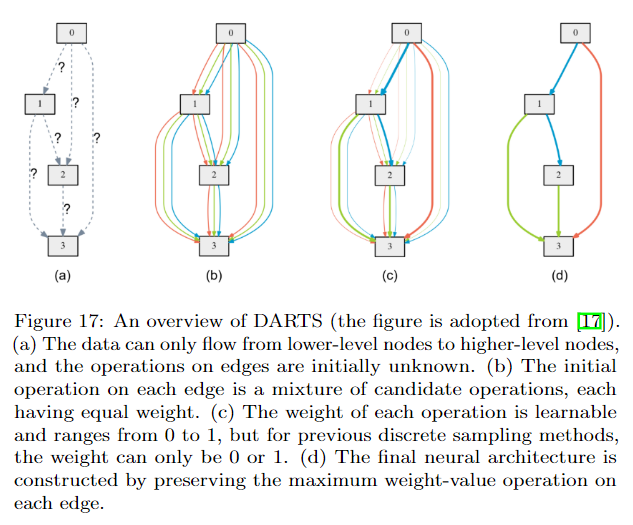
- Gradient descent-based method
DARTS應該是最早提出連續化搜索的方法之一,但是他有一個很大的問題就是記憶體消耗大,因為它構建了一個supernet,而且每次計算都需要更新這個supernet。因此後續有很多方法來改進。比如GDAS將Gumbel-softmax應用到DARTS上,每次只需要更新supernet的一個子網路即可,因此對記憶體消耗減少了很多。還有其他很多改進演算法詳見論文。
3.3 Model estimation
搜索到一個模型後,我們需要對一個模型做評估。最樸素的想法就是訓練這個模型直到收斂,然後在驗證集上看他的結果怎麼樣,但是這樣既耗時又耗資源。所以需要一些提高效率的方法,下面只是做簡單的總結,具體細節詳見論文。
1) 低保真度評估
- 使用解析度更小的圖片(比如ImageNet原圖一般是224*224,那我們可以用64*64的變體數據集)
- 使用訓練集的子集來訓練,減少訓練時間
- 使用多個低保真的評估,然後將這些評估結果做一個ensemble
2)weight sharing
ENAS 和DARTS都採用了類似的方式,即所有可能的模型都是一個supernet的子模型。這些子模型互相共享權重,因此就不需要每次都重新對子模型進行訓練了。
3)Surrogate
我不再去訓練模型了,相反我可以使用代理模型來預測模型的性能。但是如何確保代理模型能準確預測是一個需要解決的問題。
4)資源感知
早期NAS工作更多關注在最終的accuracy,而忽略了生成的模型的大小。比如有的模型雖然表現不錯,但是模型非常大,換言之這種模型的實用性是有局限的。所以很多論文開始探索如何找到參數不是太多而且表現還不錯的模型。
4、NAS討論
4.1 Performance Comparison
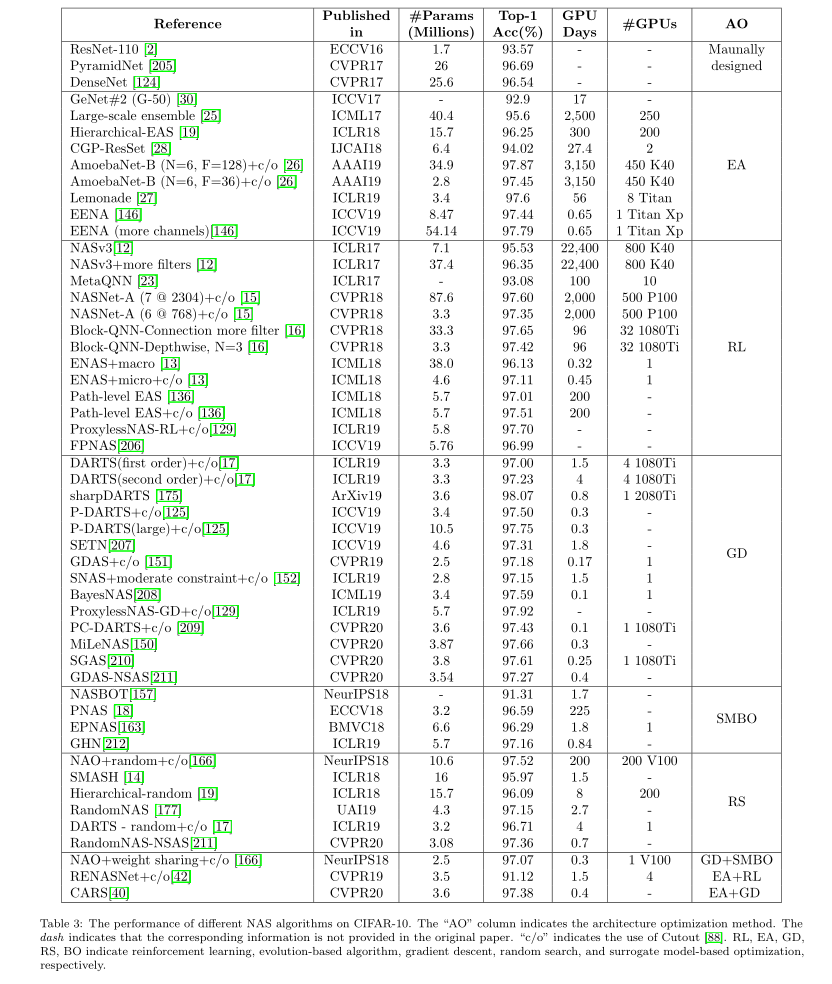
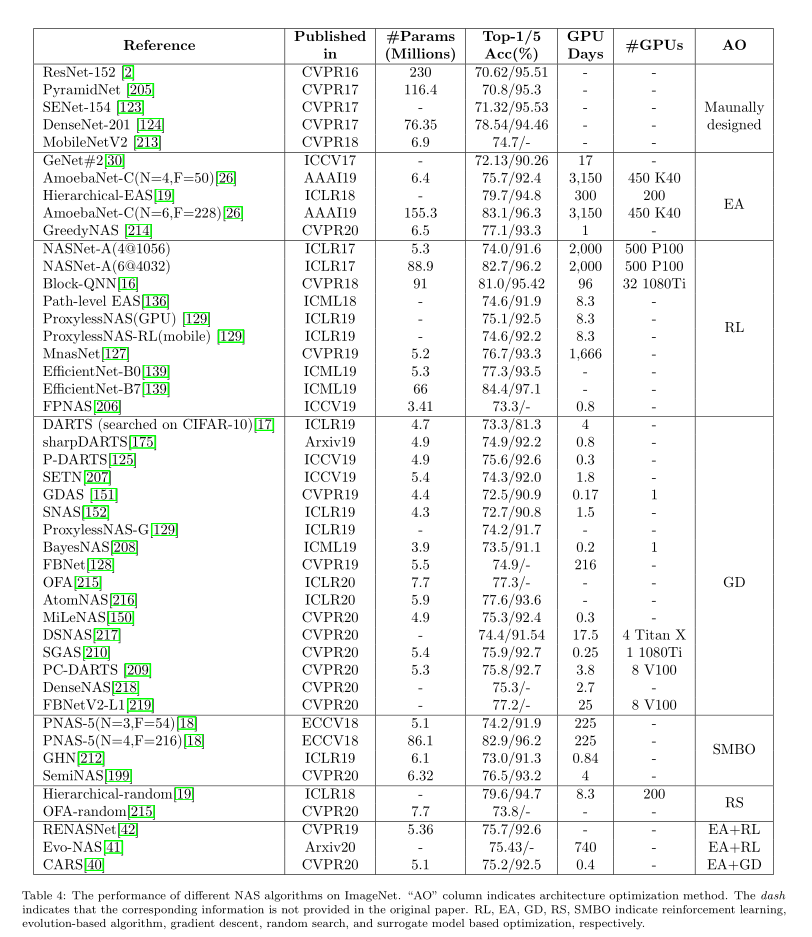
上面兩個表格總結了NAS演算法在CIFAR-10和ImageNet上的結果。雖然每個論文使用的硬體設備都不太一樣,但是大致上我們還是能看到Gradient descent-based methods是非常高效的,不僅使用的資源少,而且效果還很不錯,這也是為什麼很多後續NAS工作都是沿著這個思路做的。
但是我們也可以看到隨機搜索也是一個非常不錯的方法,不僅簡單,而且結果也可和其他方法相媲美。
1) Kendall Tau
但是上面的都是基於accuracy和搜索時間上做的對比。有不少方法開始尋找其他的NAS演算法評價指標,。我們知道大多數NAS其實分成兩個步驟,一是搜索最有潛力的模型(搜索階段);二是驗證該模型的表現(評估階段)。但是很多時候搜索階段表現最好的,在評估階段並不是最好的,甚至可能表現很差。 因此一種用的比較多的就是Kendall Tau metric,它會評估兩個階段模型性能的相關性,相關性越高則表示演算法越有效,它的計算公式如下:
\tau=\frac{N_{C}-N_{D}}{N_{C}+N_{D}}
其中N_C,N_D分別表示 concordant and discordant pairs。\tau的大小在-1到1之間:
- \tau=1:演算法能很好地找到表現好的模型,即搜索階段表現最好的模型在評估階段也是最好的。
- \tau=1: 演算法不能很好地找到表現好的模型,即搜索階段表現最好的模型在評估階段反而是最差的。
- \tau=0:搜索階段和評估階段之間完全沒有關係,基本上是隨機搜索。
2) NAS-Bench
最近有好幾個NAS相關的數據集,如NAS-Bench-101、NAS-Bench-201和NAS-Bench-NLP。簡單理解就是這些數據集的每個樣本的數據就是某種網路結構和模型大小等資訊,對應的標籤就是該網路結構的準確率。很多NAS演算法都基於這些數據集來驗證他們演算法的有效性,而且使用這些數據集不需要我們在訓練和評估搜索到的網路結構了,效率也更高了。
4.2 Two-stage vs. One-stage NAS
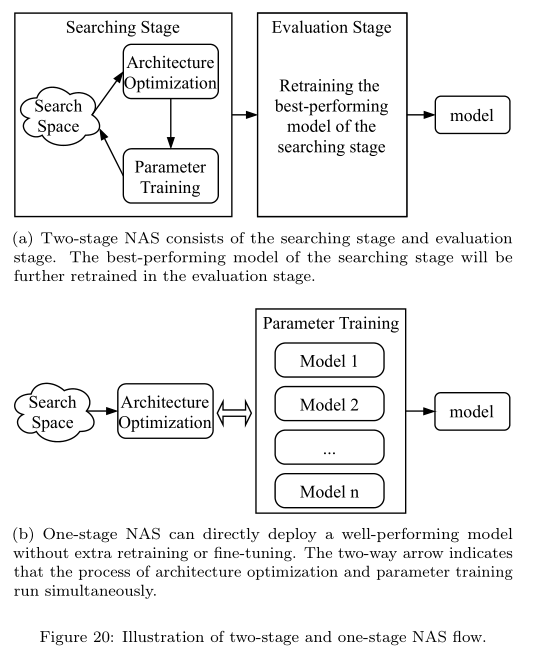
一般的NAS演算法都是Two-stage的,即先找到一個比較有潛力的模型,之後在deploy之前基本上還得retrain或者finetune一遍。而one-stage NAS則不需要,即找到模型後即可直接用這個模型來做預測了,這方面的方法有Once-for-all NAS, AutoHAS, FBNetv3等。
4.3 One-shot NAS
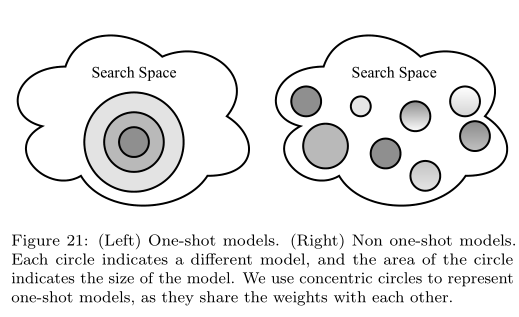
在介紹之前需要說明下:One-shot NAS和One-stage NAS是兩回事,二者可能會有重疊的地方,但是分類的方法是不一樣的。One-stage NAS強調的是一步到位,即搜索完之後模型可以直接使用,而不再需要retrain等操作;而One-shot NAS指的是那些將search space構造成一個supernet的方法,即對網路結構的搜索其實就是對supernet內部路徑的搜索。
我們把 One-shot NAS又進一步劃分成了兩類:coupled optimization(耦合優化)和decoupled optimization(解耦優化)。
1)耦合優化
耦合優化的包含兩個方面的耦合:
- 網路結構和權重的耦合。比如DARTS採用的是bilevel的方式來優化架構和對應權重
- 子網路之間權重耦合。由於子網路之間互相共享權重,更新某一個子網路的權重必然會影響其他子網路的性能
像DARTS、ENAS就是屬於耦合優化。
2)解耦優化
解耦優化,就是把架構優化和權重優化分開成兩個步驟,即先只訓練supernet,之後從supernet中按照設計的優化演算法選擇和評估。
Understanding and Simplifying One-Shot Architecture Search和Single Path One-Shot Neural Architecture Search with Uniform Sampling這兩篇論文是比較經典的解耦優化演算法。
4.4 Joint Hyperparameter and Architecture Optimization
文章最前面提到我們將hyperparameter和architecture做了區分,但是究其本質,其實二者是一樣的,而且使用的優化演算法也很多是通用的,比如隨機搜索,SMBO,基於梯度的優化演算法等都可以用來優化hyperparameters和architecture。因此為什麼不同時優化二者呢?像AutoHAS這些方法在這一方向上做了探索,也取得了不錯的效果(詳見原論文)。
5、Open problems and Future work
- Flexible search space
目前大多數NAS的search space基本上都是基於人類經驗設計的,比如使用卷積操作、假如skip-connection等,雖然效果不錯,但是或多或少都引入了人類偏見,或者說仍舊沒有跳脫出人類的設計範疇。所以如何設計出不受人類偏見影響的search space是一個值得探索的方向。Auto-Zero在這方向上做出了探索,它只使用一些非常基礎的數學計算式子,例如加、減sin,cos,高斯分布等從0開始成功地找到了2層的神經網路結構。
- 可解釋性
- 可復現性
- 魯棒性
目前NAS更多實應用在科研性質的數據集上,而我們都知道現實世界中的數據是有很多雜訊的,比如標籤錯誤或者資訊不完整等,甚至有的數據加入了人為製造的雜訊(如Adversarial data),這些都會影響模型的性能。雖然已經有不少方法可以提高模型的對抗雜訊魯棒性,但是他們都是算是一個後處理的方法,一個理想的方法是在搜索過程我就能搜索到魯棒性很強的模型,這樣就不用再做一些後處理操作了。目前將NAS和魯棒性結合的論文還不是很多(好像只有三四篇論文),因此還是一個初步探索階段。
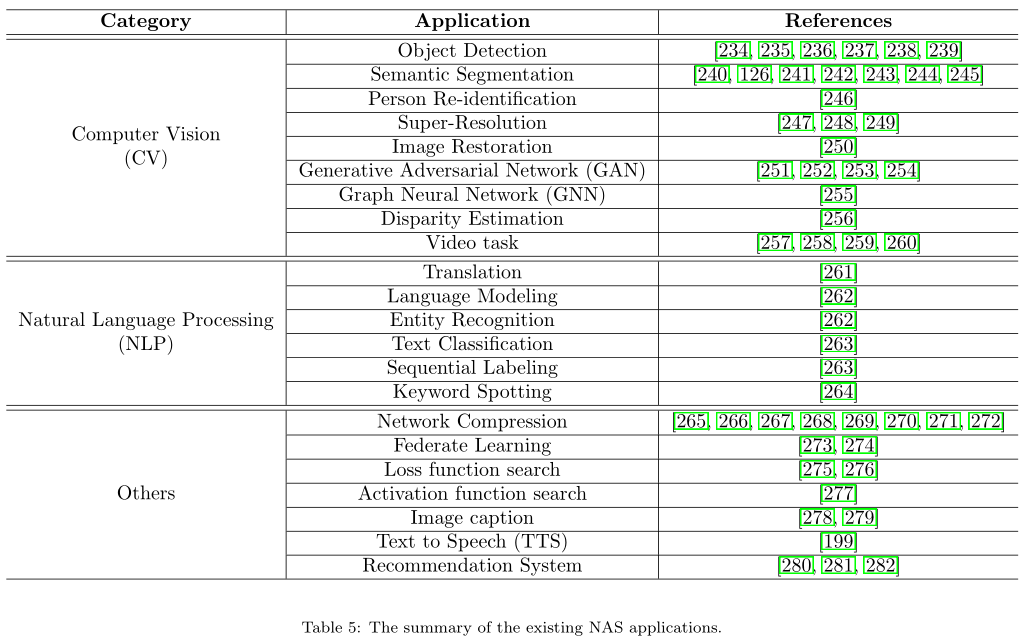
- 將NAS應用到更多領域
下表統計了除了影像分類外,目前NAS所應用的領域
- 完整的AutoML pipeline系統
目前有不少AutoML的開源庫了,但是大都只實現了pipeline的一部分。
比如TPOT,Auto-Weka,Auto-Sklearn都是基於傳統機器學習模型設計的。Auto-keras則主要側重NAS。不過微軟的NNI和華為最近開源的Vega都提供了非常強大的功能,例如NAS、模型壓縮、超參數搜索。NNI最近更新了對Sklearn的支援,Vega還提供了自動化data augmentation功能,很是強大了,因此完全傻瓜式的多模組AutoML系統指日可待了。
- lifelong learning
一個優秀的AutoML系統還應該能夠lifelong learning,因為在現實場景中會源源不斷的產生新數據,所以換句話說就是能不斷學習新數據,同時還能記住舊知識。
對於學習新數據,有兩個問題:一是新數據的數量可能會很少,這就涉及到meta-learning技術。最近有不少論文將NAS和meta-learning做了結合,也都取得了不錯的效果;二是新數據的標籤不完整,這就涉及非監督學習,何凱明團隊最新研究成果UnNAS發現非監督NAS也能取得不錯甚至比監督NAS更好的結果。
記住舊知識比較經典的演算法是 learning without forgetting (LwF) 和 iCaRL。
更多乾貨歡迎關注公眾號【AutoML機器學習】

