RocketMQ 主從同步若干問題答疑
- 2019 年 11 月 12 日
- 筆記
溫馨提示:建議參考程式碼RocketMQ4.4版本,4.5版本引入了多副本機制,實現了主從自動切換,本文並不關心主從切換功能。
@(本節目錄)
1、初識主從同步
主從同步基本實現過程如下圖所示:
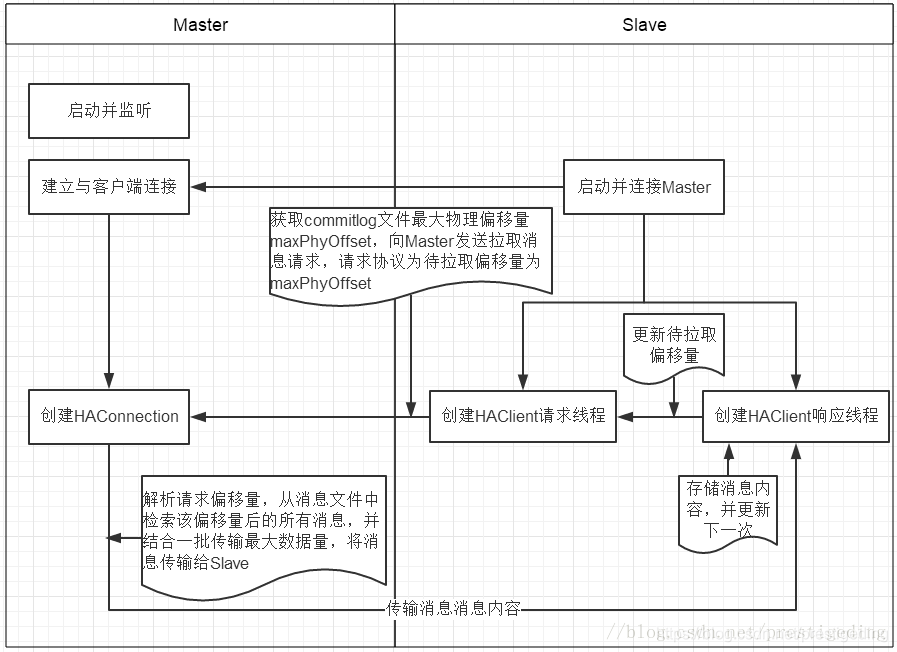
RocketMQ 的主從同步機制如下:
A. 首先啟動Master並在指定埠監聽;
B. 客戶端啟動,主動連接Master,建立TCP連接;
C. 客戶端以每隔5s的間隔時間向服務端拉取消息,如果是第一次拉取的話,先獲取本地commitlog文件中最大的偏移量,以該偏移量向服務端拉取消息;
D. 服務端解析請求,並返回一批數據給客戶端;
E. 客戶端收到一批消息後,將消息寫入本地commitlog文件中,然後向Master彙報拉取進度,並更新下一次待拉取偏移量;
F. 然後重複第3步;
RocketMQ主從同步一個重要的特徵:主從同步不具備主從切換功能,即當主節點宕機後,從不會接管消息發送,但可以提供消息讀取。
溫馨提示:本文並不會詳細分析RocketMQ主從同步的實現細節,如大家對其感興趣,可以查閱筆者所著的《RocketMQ技術內幕》或查看筆者博文:https://blog.csdn.net/prestigeding/article/details/79600792
2、提出問題
- 主,從伺服器都在運行過程中,消息消費者是從主拉取消息還是從從拉取?
- RocketMQ主從同步架構中,如果主伺服器宕機,從伺服器會接管消息消費,此時消息消費進度如何保持,當主伺服器恢復後,消息消費者是從主拉取消息還是從從伺服器拉取,主從伺服器之間的消息消費進度如何同步?
接下來帶著上述問題,一起來探究其實現原理。
3、原理探究
3.1 RocketMQ主從讀寫分離機制
RocketMQ的主從同步,在默認情況下RocketMQ會優先選擇從主伺服器進行拉取消息,並不是通常意義的上的讀寫分離,那什麼時候會從拉取呢?
溫馨提示:本節同樣不會詳細整個流程,只會點出其關鍵點,如果想詳細了解消息拉取、消息消費等核心流程,建議大家查閱筆者所著的《RocketMQ技術內幕》。
在RocketMQ中判斷是從主拉取,還是從從拉取的核心程式碼如下:
DefaultMessageStore#getMessage
long diff = maxOffsetPy - maxPhyOffsetPulling; // @1 long memory = (long) (StoreUtil.TOTAL_PHYSICAL_MEMORY_SIZE * (this.messageStoreConfig.getAccessMessageInMemoryMaxRatio() / 100.0)); // @2 getResult.setSuggestPullingFromSlave(diff > memory); // @3程式碼@1:首先介紹一下幾個局部變數的含義:
- maxOffsetPy
當前最大的物理偏移量。返回的偏移量為已存入到作業系統的PageCache中的內容。 - maxPhyOffsetPulling
本次消息拉取最大物理偏移量,按照消息順序拉取的基本原則,可以基本預測下次開始拉取的物理偏移量將大於該值,並且就在其附近。 - diff
maxOffsetPy與maxPhyOffsetPulling之間的間隔,getMessage通常用於消息消費時,即這個間隔可以理解為目前未處理的消息總大小。
程式碼@2:獲取RocketMQ消息存儲在PageCache中的總大小,如果當RocketMQ容量超過該闊值,將會將被置換出記憶體,如果要訪問不在PageCache中的消息,則需要從磁碟讀取。
- StoreUtil.TOTAL_PHYSICAL_MEMORY_SIZE
返回當前系統的總物理記憶體。參數 - accessMessageInMemoryMaxRatio
設置消息存儲在記憶體中的閥值,默認為40。
結合程式碼@2這兩個參數的含義,算出RocketMQ消息能映射到記憶體中最大值為40% * (機器物理記憶體)。
程式碼@3:設置下次拉起是否從從拉取標記,觸發下次從從伺服器拉取的條件為:當前所有可用消息數據(所有commitlog)文件的大小已經超過了其闊值,默認為物理記憶體的40%。
那GetResult的suggestPullingFromSlave屬性在哪裡使用呢?
PullMessageProcessor#processRequest
if (getMessageResult.isSuggestPullingFromSlave()) { // @1 responseHeader.setSuggestWhichBrokerId(subscriptionGroupConfig.getWhichBrokerWhenConsumeSlowly()); } else { responseHeader.setSuggestWhichBrokerId(MixAll.MASTER_ID); } switch (this.brokerController.getMessageStoreConfig().getBrokerRole()) { // @2 case ASYNC_MASTER: case SYNC_MASTER: break; case SLAVE: if (!this.brokerController.getBrokerConfig().isSlaveReadEnable()) { response.setCode(ResponseCode.PULL_RETRY_IMMEDIATELY); responseHeader.setSuggestWhichBrokerId(MixAll.MASTER_ID); } break; } if (this.brokerController.getBrokerConfig().isSlaveReadEnable()) { // @3 // consume too slow ,redirect to another machine if (getMessageResult.isSuggestPullingFromSlave()) { responseHeader.setSuggestWhichBrokerId(subscriptionGroupConfig.getWhichBrokerWhenConsumeSlowly()); } // consume ok else { responseHeader.setSuggestWhichBrokerId(subscriptionGroupConfig.getBrokerId()); } } else { responseHeader.setSuggestWhichBrokerId(MixAll.MASTER_ID); }程式碼@1:如果從commitlog文件查找消息時,發現消息堆積太多,默認超過物理記憶體的40%後,會建議從從伺服器讀取。
程式碼@2:如果當前伺服器的角色為從伺服器:並且slaveReadEnable=true,則忽略程式碼@1設置的值,下次拉取切換為從主拉取。
程式碼@3:如果slaveReadEnable=true(從允許讀),並且建議從從伺服器讀取,則從消息消費組建議當消息消費緩慢時建議的拉取brokerId,由訂閱組配置屬性whichBrokerWhenConsumeSlowly決定;如果消息消費速度正常,則使用訂閱組建議的brokerId拉取消息進行消費,默認為主伺服器。如果不允許從可讀,則固定使用從主拉取。
溫馨提示:請注意broker服務參數slaveReadEnable,與訂閱組配置資訊:whichBrokerWhenConsumeSlowly、brokerId的值,在生產環境中,可以通過updateSubGroup命令動態改變訂閱組的配置資訊。
如果訂閱組的配置保持默認值的話,拉取消息請求發送到從伺服器後,下一次消息拉取,無論是否開啟slaveReadEnable,下一次拉取,還是會發往主伺服器。
上面的步驟,在消息拉取命令的返回欄位中,會將下次建議拉取Broker返回給客戶端,根據其值從指定的broker拉取。
消息拉取實現PullAPIWrapper在處理拉取結果時會將服務端建議的brokerId更新到broker拉取快取表中。
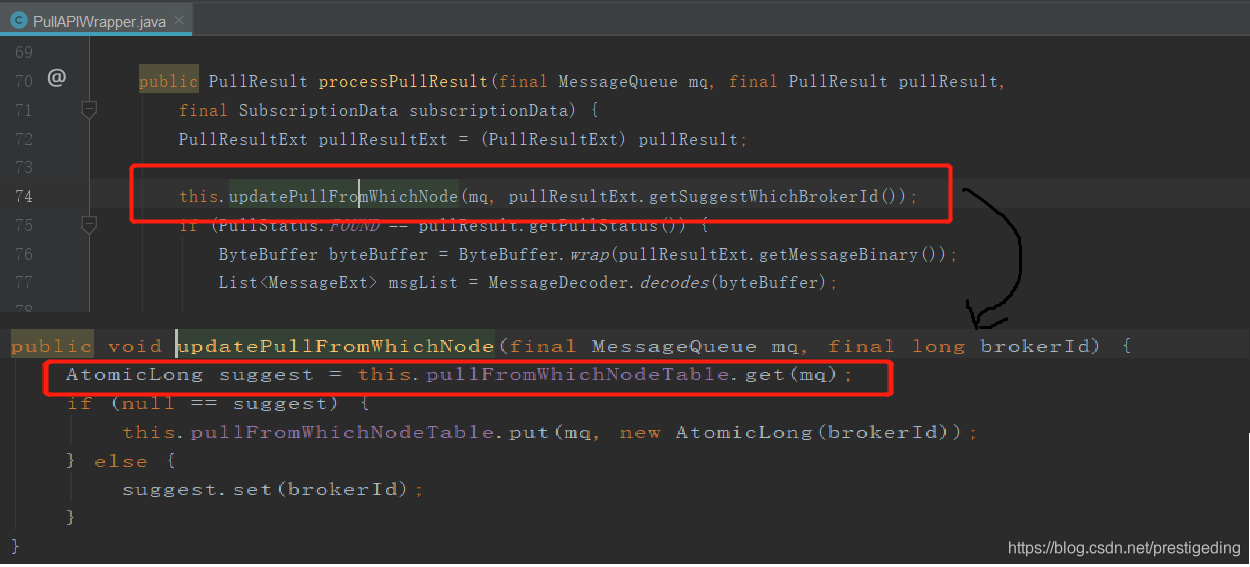
在發起拉取請求之前,首先根據如下程式碼,選擇待拉取消息的Broker。
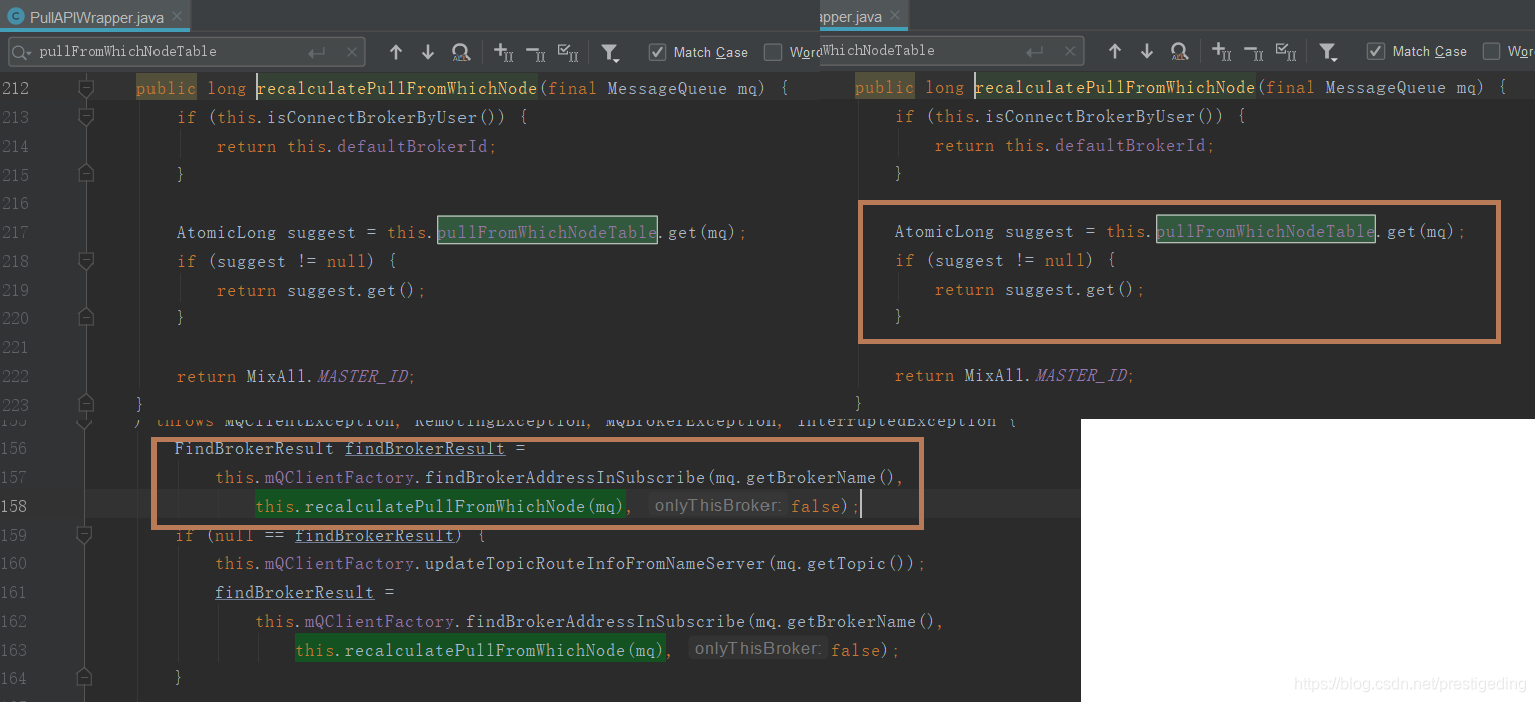
3.2 消息消費進度同步機制
從上面內容可知,主從同步引入的主要目的就是消息堆積的內容默認超過物理記憶體的40%,則消息讀取則由從伺服器來接管,實現消息的讀寫分離,避免主服務IO抖動嚴重。那問題來了,主伺服器宕機後,從伺服器接管消息消費後,那消息消費進度存儲在哪裡?當主伺服器恢復正常後,消息是從主伺服器拉取還是從從伺服器拉取?主伺服器如何得知最新的消息消費進度呢?
RocketMQ消息消費進度管理(集群模式):
集群模式下消息消費進度存儲文件位於服務端${ROCKETMQ_HOME}/store/config/consumerOffset.json。消息消費者從伺服器拉取一批消息後提交到消費組特定的執行緒池中處理消息,當消息消費成功後會向Broker發送ACK消息,告知消費端已成功消費到哪條消息,Broker收到消息消費進度回饋後,首先存儲在記憶體中,然後定時持久化到consumeOffset.json文件中。備註:關於消息消費進度管理更多的實現細節,建議查閱筆者所著的《RocketMQ技術內幕》。
我們先看一下客戶端向服務端回饋消息消費進度時如何選擇Broker。
因為主服務的brokerId為0,默認情況下當主伺服器存活的時候,優先會選擇主伺服器,只有當主伺服器宕機的情況下,才會選擇從伺服器。
既然集群模式下消息消費進度存儲在Broker端,當主伺服器正常時,消息消費進度文件存儲在主伺服器,那提出如下兩個問題:
1)消息消費端在主伺服器存活的情況下,會優先向主伺服器回饋消息消費進度,那從伺服器是如何同步消息消費進度的。
2)當主伺服器宕機後則消息消費端會向從伺服器回饋消息消費進度,此時消息消費進度如何存儲,當主伺服器恢復正常後,主伺服器如何得知最新的消息消費進度。
為了解開上述兩個疑問,我們優先來看一下Broker伺服器在收到提交消息消費進度回饋命令後的處理邏輯:
客戶端定時向Broker端發送更新消息消費進度的請求,其入口為:RemoteBrokerOffsetStore#updateConsumeOffsetToBroker,該方法中一個非常關鍵的點是:選擇broker的邏輯,如下所示:
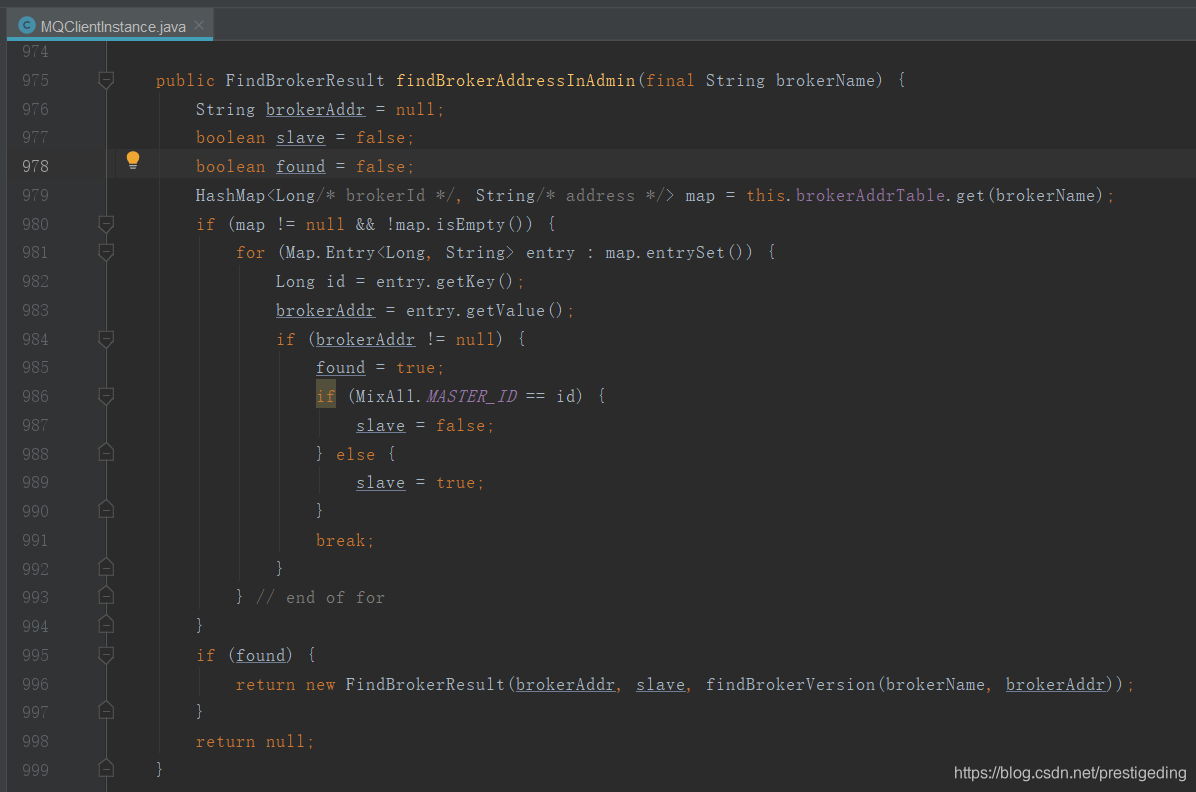
如果主伺服器存活,則選擇主伺服器,如果主伺服器宕機,則選擇從伺服器。也就是說,不管消息是從主伺服器拉取的還是從從伺服器拉取的,提交消息消費進度請求,優先選擇主伺服器。服務端就是接收其偏移量,更新到服務端的記憶體中,然後定時持久化到${ROCKETMQ_HOME}/store/config/consumerOffset.json。
經過上面的分析,我們來討論一下這個場景:
消息消費者首先從主伺服器拉取消息,並向其提交消息消費進度,如果當主伺服器宕機後,從伺服器會接管消息拉取服務,此時消息消費進度存儲在從伺服器,主從伺服器的消息消費進度會出現不一致?那當主伺服器恢復正常後,兩者之間的消息消費進度如何同步?
3.2.1 從服務定時同步主伺服器進度
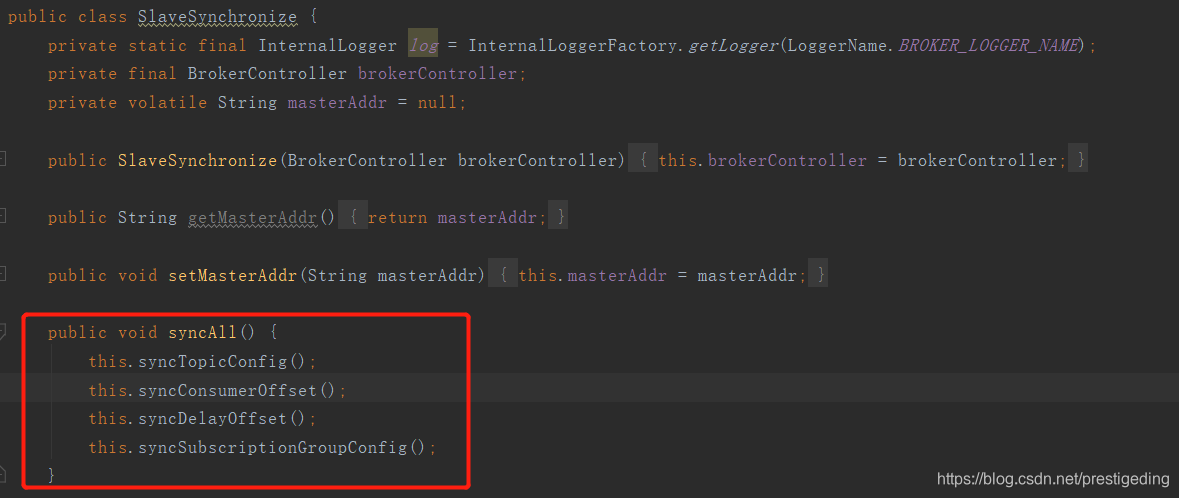
如果Broker角色為從伺服器,會通過定時任務調用syncAll,從主伺服器定時同步topic路由資訊、消息消費進度、延遲隊列處理進度、消費組訂閱資訊。
那問題來了,如果主伺服器啟動後,從伺服器馬上從主伺服器同步消息消息進度,那豈不是又要重新消費?
其實在絕大部分情況下,就算從服務從主伺服器同步了很久之前的消費進度,只要消息者沒有重新啟動,就不需要重新消費,在這種情況下,RocketMQ提供了兩種機制來確保不丟失消息消費進度。
第一種,消息消費者在記憶體中存在最新的消息消費進度,繼續以該進度去伺服器拉取消息後,消息處理完後,會定時向Broker伺服器回饋消息消費進度,在上面也提到過,在回饋消息消費進度時,會優先選擇主伺服器,此時主伺服器的消息消費進度就立馬更新了,從伺服器此時只需定時同步主伺服器的消息消費進度即可。
第二種是,消息消費者在向主伺服器拉取消息時,如果是是主伺服器,在處理消息拉取時,也會更新消息消費進度。
3.2.2 主伺服器消息拉取時更新消息消費進度
主伺服器在處理消息拉取命令時,會觸發消息消費進度的更新,其程式碼入口為:PullMessageProcessor#processRequest
boolean storeOffsetEnable = brokerAllowSuspend; // @1 storeOffsetEnable = storeOffsetEnable && hasCommitOffsetFlag; storeOffsetEnable = storeOffsetEnable && this.brokerController.getMessageStoreConfig().getBrokerRole() != BrokerRole.SLAVE; // @2 if (storeOffsetEnable) { this.brokerController.getConsumerOffsetManager().commitOffset(RemotingHelper.parseChannelRemoteAddr(channel), requestHeader.getConsumerGroup(), requestHeader.getTopic(), requestHeader.getQueueId(), requestHeader.getCommitOffset()); }程式碼@1:首先介紹幾個局部變數的含義:
- brokerAllowSuspend:broker是否允許掛起,在消息拉取時,該值默認為true。
- hasCommitOffsetFlag:消息消費者在記憶體中是否快取了消息消費進度,如果快取了,該標記設置為true。
如果Broker的角色為主伺服器,並且上面兩個變數都為true,則首先使用commitOffset更新消息消費進度。
看到這裡,主從同步消息消費進度的相關問題,應該就有了答案了。
4、總結
上述實現原理的講解有點枯燥無味,我們先來回答如下幾個問題:
1、主,從伺服器都在運行過程中,消息消費者是從主拉取消息還是從從拉取?
答:默認情況下,RocketMQ消息消費者從主伺服器拉取,當主伺服器積壓的消息超過了物理記憶體的40%,則建議從從伺服器拉取。但如果slaveReadEnable為false,表示從伺服器不可讀,從伺服器也不會接管消息拉取。
2、當消息消費者向從伺服器拉取消息後,會一直從從伺服器拉取?
答:不是的。分如下情況:
1)如果從伺服器的slaveReadEnable設置為false,則下次拉取,從主伺服器拉取。
2)如果從伺服器允許讀取並且從伺服器積壓的消息未超過其物理記憶體的40%,下次拉取使用的Broker為訂閱組的brokerId指定的Broker伺服器,該值默認為0,代表主伺服器。
3)如果從伺服器允許讀取並且從伺服器積壓的消息超過了其物理記憶體的40%,下次拉取使用的Broker為訂閱組的whichBrokerWhenConsumeSlowly指定的Broker伺服器,該值默認為1,代表從伺服器。
3、主從服務消息消費進是如何同步的?
答:消息消費進度的同步時單向的,從伺服器開啟一個定時任務,定時從主伺服器同步消息消費進度;無論消息消費者是從主伺服器拉的消息還是從從伺服器拉取的消息,在向Broker回饋消息消費進度時,優先向主伺服器彙報;消息消費者向主伺服器拉取消息時,如果消息消費者記憶體中存在消息消費進度時,主會嘗試跟新消息消費進度。
讀寫分離的正確使用姿勢:
1、主從Broker伺服器的slaveReadEnable設置為true。
2、通過updateSubGroup命令更新消息組whichBrokerWhenConsumeSlowly、brokerId,特別是其brokerId不要設置為0,不然從從伺服器拉取一次後,下一次拉取就會從主去拉取。
作者介紹:
丁威,《RocketMQ技術內幕》作者,RocketMQ 社區佈道師,公眾號:中間件興趣圈 維護者,目前已陸續發表源碼分析Java集合、Java 並發包(JUC)、Netty、Mycat、Dubbo、RocketMQ、Mybatis等源碼專欄。



