當 Redis 發生高延遲時,到底發生了什麼
- 2019 年 11 月 12 日
- 筆記
Redis 是一種記憶體資料庫,將數據保存在記憶體中,讀寫效率要比傳統的將數據保存在磁碟上的資料庫要快很多。但是 Redis 也會發生延遲時,這是就需要我們對其產生原因有深刻的了解,以便於快速排查問題,解決 Redis的延遲問題
一條命令執行過程
在本文場景下,延遲 (latency) 是指從客戶端發送命令到客戶端接收到命令返回值的時間間隔。所以我們先來看一下 Redis 一條命令執行的步驟,其中每個步驟出問題都可能導致高延遲。
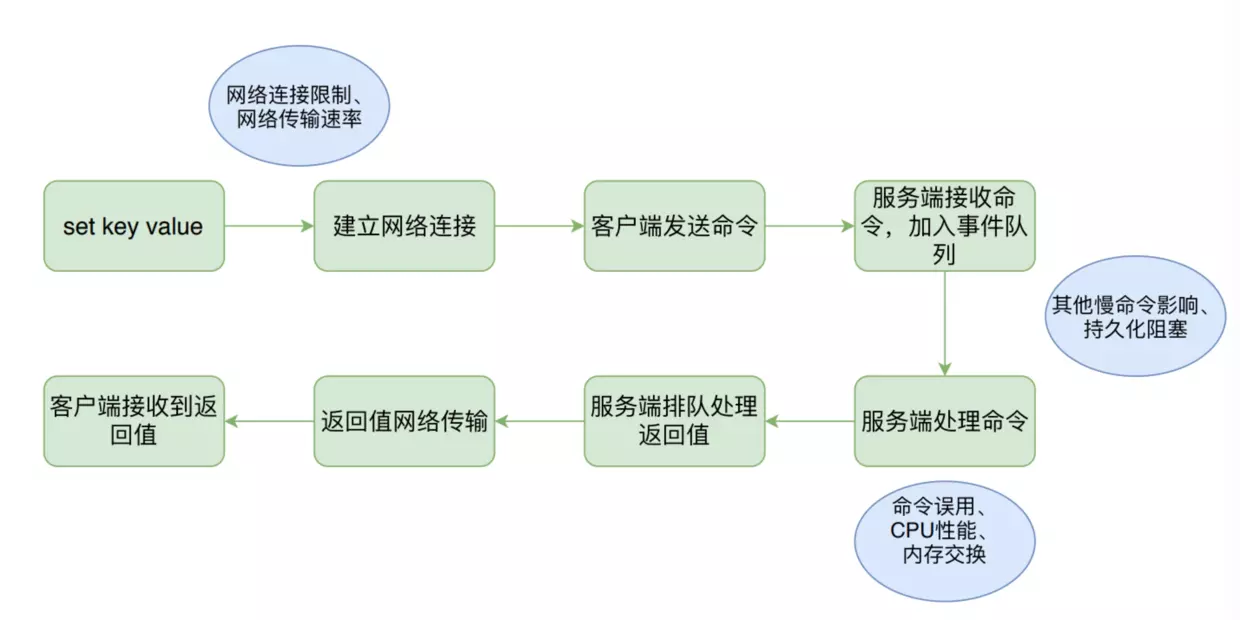
上圖是 Redis 客戶端發送一條命令的執行過程示意圖,綠色的是執行步驟,而藍色的則是可能出現的導致高延遲的原因。
網路連接限制、網路傳輸速率和CPU性能等是所有服務端都可能產生的性能問題。但是 Redis 有自己獨有的可能導致高延遲的問題:命令或者數據結構誤用、持久化阻塞和記憶體交換。
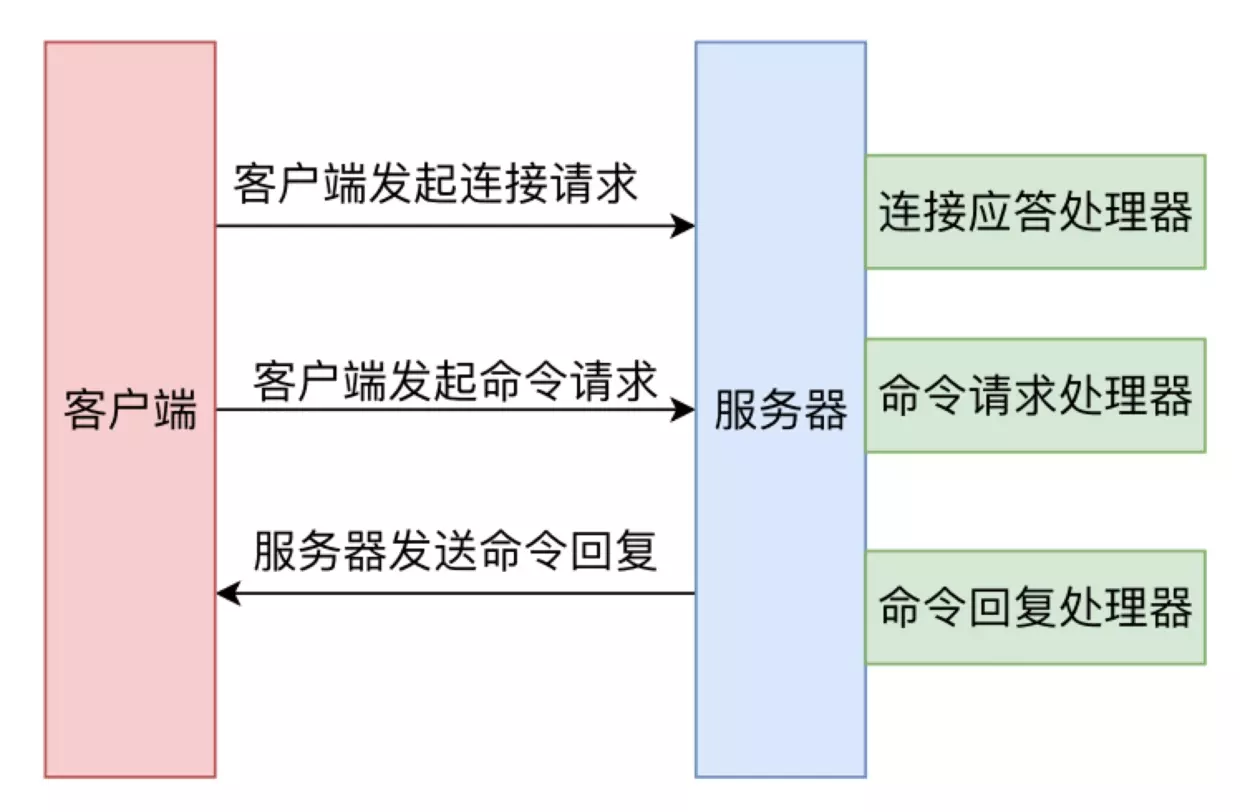
而且更為致命的是,Redis 採用單執行緒和事件驅動的機制來處理網路請求,分別有對應的連接應答處理器,命令請求處理器和命令回復處理器來處理客戶端的網路請求事件,處理完一個事件就繼續處理隊列中的下一個。一條命令處理出現了高延遲會影響接下來處於排隊狀態的其他命令。有關 Redis 事件處理機制的可以參考本篇文章。
對於高延遲,Redis 原生提供慢查詢統計功能,執行 slowlog get {n} 命令可以獲取最近的 n 條慢查詢命令,默認對於執行超過10毫秒(可配置)的命令都會記錄到一個定長隊列中,線上實例建議設置為1毫秒便於及時發現毫秒級以上的命令。
# 超過 slowlog-log-slower-than 閾值的命令都會被記錄到慢查詢隊列中# 隊列最大長度為 slowlog-max-lenslowlog-log-slower-than 10000slowlog-max-len 128
如果命令執行時間在毫秒級,則實例實際OPS只有1000左右。慢查詢隊列長度默認128,可適當調大。慢查詢本身只記錄了命令執行時間,不包括數據網路傳輸時間和命令排隊時間,因此客戶端發生阻塞異常 後,可能不是當前命令緩慢,而是在等待其他命令執行。需要重點比對異常和慢查詢發生的時間點,確認是否有慢查詢造成的命令阻塞排隊。
slowlog的輸出格式如下所示。第一個欄位表示該條記錄在所有慢日誌中的序號,最新的記錄被展示在最前面;第二個欄位是這條記錄被記錄時的系統時間,可以用 date 命令來將其轉換為友好的格式第三個欄位表示這條命令的響應時間,單位為 us (微秒);第四個欄位為對應的 Redis 操作。
> slowlog get1) 1) (integer) 262) (integer) 14502531333) (integer) 430974) 1) "flushdb"
下面我們就來依次看一下不合理地使用命令或者數據結構、持久化阻塞和記憶體交換所導致的高延遲問題。
不合理的命令或者數據結構
一般來說 Redis 執行命令速度都非常快,但是當數據量達到一定級別時,某些命令的執行就會花費大量時間,比如對一個包含上萬個元素的 hash 結構執行 hgetall 操作,由於數據量比較大且命令演算法複雜度是 O(n),這條命令執行速度必然很慢。
這個問題就是典型的不合理使用命令和數據結構。對於高並發的場景我們應該盡量避免在大對象上執行演算法複雜度超過 O(n) 的命令。對於鍵值較多的 hash 結構可以使用 scan 系列命令來逐步遍歷,而不是直接使用 hgetall 來全部獲取。
Redis 本身提供發現大對象的工具,對應命令:redis-cli-h {ip} -p {port} bigkeys。這條命令會使用 scan 從指定的 Redis DB 中持續取樣,實時輸出當時得到的 value 佔用空間最大的 key 值,並在最後給出各種數據結構的 biggest key 的總結報告。
> redis-cli -h host -p 12345 --bigkeys# Scanning the entire keyspace to find biggest keys as well as# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec# per 100 SCAN commands (not usually needed).[00.00%] Biggest hash found so far 'idx:user' with 1 fields[00.00%] Biggest hash found so far 'idx:product' with 3 fields[00.00%] Biggest hash found so far 'idx:order' with 14 fields[02.29%] Biggest hash found so far 'idx:fund' with 16 fields[02.29%] Biggest hash found so far 'idx:pay' with 69 fields[04.45%] Biggest set found so far 'indexed_word_set' with 1482 members[05.93%] Biggest hash found so far 'idx:address' with 159 fields[11.79%] Biggest hash found so far 'idx:reply' with 196 fields-------- summary -------Sampled 1484 keys in the keyspace!Total key length in bytes is 13488 (avg len 9.09)Biggest set found 'indexed_word_set' has 1482 membersBiggest hash found 'idx:的' has 196 fields0 strings with 0 bytes (00.00% of keys, avg size 0.00)0 lists with 0 items (00.00% of keys, avg size 0.00)2 sets with 1710 members (00.13% of keys, avg size 855.00)1482 hashs with 6731 fields (99.87% of keys, avg size 4.54)0 zsets with 0 members (00.00% of keys, avg size 0.00)
持久化阻塞
對於開啟了持久化功能的Redis節點,需要排查是否是持久化導致的阻 塞。持久化引起主執行緒阻塞的操作主要有:fork 阻塞、AOF刷盤阻塞。
fork 操作發生在 RDB 和 AOF 重寫時,Redis 主執行緒調用 fork 操作產生共享記憶體的子進程,由子進程完成對應的持久化工作。如果 fork 操作本身耗時過長,必然會導致主執行緒的阻塞。

Redis 執行 fork 操作產生的子進程記憶體佔用量表現為與父進程相同,理論上需要一倍的物理記憶體來完成相應的操作。但是 Linux 具有寫時複製技術 (copy-on-write),父子進程會共享相同的物理記憶體頁,當父進程處理寫請求時會對需要修改的頁複製出一份副本完成寫操作,而子進程依然讀取 fork 時整個父進程的記憶體快照。所以,一般來說,fork 不會消耗過多時間。
可以執行 info stats命令獲取到 latestforkusec 指標,表示 Redis 最近一次 fork 操作耗時,如果耗時很大,比如超過1秒,則需要做出優化調整。
> redis-cli -c -p 7000 info | grep -w latest_fork_useclatest_fork_usec:315
當我們開啟AOF持久化功能時,文件刷盤的方式一般採用每秒一次,後 台執行緒每秒對AOF文件做 fsync 操作。當硬碟壓力過大時,fsync 操作需要等待,直到寫入完成。如果主執行緒發現距離上一次的 fsync 成功超過2秒,為了數據安全性它會阻塞直到後台執行緒執行 fsync 操作完成。這種阻塞行為主要是硬碟壓力引起,可以查看 Redis日誌識別出這種情況,當發生這種阻塞行為時,會列印如下日誌:
Asynchronous AOF fsync is taking too long (disk is busy).Writing the AOF buffer without waiting for fsync to complete,this may slow down Redis.
也可以查看 info persistence 統計中的 aofdelayedfsync 指標,每次發生 fdatasync 阻塞主執行緒時會累加。
>info persistenceloading:0aof_pending_bio_fsync:0aof_delayed_fsync:0
記憶體交換
記憶體交換(swap)對於 Redis 來說是非常致命的,Redis 保證高性能的一個重要前提是所有的數據在記憶體中。如果作業系統把 Redis 使用的部分記憶體換出到硬碟,由於記憶體與硬碟讀寫速度差幾個數量級,會導致發生交換後的 Redis 性能急劇下降。識別 Redis 記憶體交換的檢查方法如下:
>redis-cli -p 6383 info server | grep process_id # 查詢 redis 進程號>cat /proc/4476/smaps | grep Swap # 查詢記憶體交換大小Swap: 0 kBSwap: 4 kBSwap: 0 kBSwap: 0 kB
如果交換量都是0KB或者個別的是4KB,則是正常現象,說明Redis進程記憶體沒有被交換。
有很多方法可以避免記憶體交換的發生。比如說:
- 保證機器充足的可用記憶體
- 確保所有Redis實例設置最大可用記憶體(maxmemory),防止極端情況下 Redis 記憶體不可控的增長。
- 降低系統使用swap優先順序,如
echo10>/proc/sys/vm/swappiness。
參考
- https://redis.io/topics/latency

