淺談 KMP 演算法
- 2019 年 11 月 12 日
- 筆記
最近在複習數據結構,學到了 KMP 演算法這一章,似乎又迷糊了,記得第一次學習這個演算法時,老師在課堂上講得唾沫橫飛,十分有激情,而我們在下面聽得一臉懵比,啥?這是個啥演算法?啥玩意?再去看看書,完全聽不懂呀?總之,覺得十分懵比,課後去看了一些影片和部落格,才慢慢有一點理解,學習不是一蹴而就的,需要腳踏實地的努力。過了三年,重新溫習這個演算法,似乎依舊不是很明白,理解得不夠透徹,重新拾起課本和影片,認真學習這個演算法。
1.KMP 演算法簡介
KMP 演算法是由三位老前輩(D.E.Knuth,J.H.Morris 和 V.R.Pratt )的研究結果,該演算法巧妙之處在於避免重複遍歷的情況,全稱叫做克努特-莫里斯-普拉特演算法,簡稱 KMP 演算法,D.E.Knuth,編寫了《電腦程式設計藝術》寫完了第四卷,這部著作被譽為電腦領域中的“相對論”。
2.子串 next 數組的計算
KMP 演算法關鍵點是先求出 next[] 數組,這個 next 數組只與模式匹配串有關,例如以 “abababca” 這個子串計算一下它的 next 數組
下標為 index = 0 開始 ,
index = 0 ,”a” 的前綴和後綴都為空集,value = 0;
index = 1,”ab” 的前綴和後綴分別為 “a” 和 “b”,不相等,value = 0;
index = 2, “aba” 的前綴是 “a”、 “ab”,後綴是 “ba”、”a”,有相同交集 “a”,長度為 1, value = 1;
index = 3, “abab” 的前綴是 “a”、”ab”、”aba”,後綴是 “bab”、”ab”、”b”,有最長相同交集 “ab”, 長度為 2,value = 2;
index = 4,”ababa” 的前綴是 “a”、”ab”、”aba”、”abab”,後綴是 “baba”、”aba”、”ba”、”a”,有最大相同交集 “aba”,長度為 3, value = 3;
index = 5,”ababab” 的前綴是 “a”、”ab”、”aba”、”abab”、”ababa”,後綴是 “babab”、”abab”、”bab”、”ab”、”b”,有最長相同交集 “abab”,長度為 4, value = 4;
index = 6,”abababc” 的前綴是 “a”、”ab”、”aba”、”abab”、”ababa”、”ababab”,後綴是 “bababc”、”ababc”、”babc”、”abc”、”bc”、”c”,沒有相同交集,value = 0;
index = 7,”abababca” 的前綴是 “a”、”ab”、”aba”、”abab”、”ababa”、”abababc”,後綴是 “bababca”、”ababca”、”babca”、”abca”、”bca”、”ca”、”a”,有相同交集 “a”,長度為1,value = 1;
最後結果如下:
char: | a | b | a | b | a | b | c | a |
index: | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
value: | 0 | 0 | 1 | 2 | 3 | 4 | 0 | 1 |
3、如何使用 next[] 數組
得到子串的 next 數組以後,在目標串中匹配使用 next 數組,通過使用 next 數組避免重複的匹配已經匹配過的元素,如果找到長度為 partial_match_length 的部分匹配,並且表 next [partial_match_length]> 1,我們可以提前跳過 partial_match_length – next[partial_match_length-1] 個字元
總結移動位數 = 已匹配的字元數 – 對應的部分匹配值
char: | a | b | a | b | a | b | c | a |
index: | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
value: | 0 | 0 | 1 | 2 | 3 | 4 | 0 | 1 |
以 “bacbababaabcbab” 為例說明它的匹配過程,第一次匹配, 調到 index = 1 位置,如下
bacbababaabcbab
|
abababca
不難看出, 部分匹配的長度為 partial_match_length = 1, 但是在 next [ partial_match_length – 1] = 0,也就是 next[0] = 0,這個元素,所以我們不需要跳過任何元素,接下來 cb 和 a 都不匹配直接向右匹配,到了下一個 a 匹配的地方
bacbababaabcbab
| | | | |
abababca
來到這個地方,你會發現此時部分匹配的長度為 5 , partial_match_length = 5, next[partial_match_length – 1] = next[4],查 next 數組,next[4] = 3,這就意味著在接下來的匹配中我們要跳過 partial_match_length – next[partial_match_length-1] ,即 5 – next[4] = 5 – 3 = 2,要跳過 2 個字元,所以接下來的匹配應該變成了如下所示:
bacbababaabcbab
xx | | |
abababca
xx 表示跳過了,部分匹配長度為 3, partial_match_length = 3,next[partial_match_length – 1] = next[2] = 1,接下來匹配中要跳過
partial_match_length – next[partial_match_length – 1], 即 3 – 1 = 2, 跳過 2 個字元後的匹配情況如下:
bacbababaabcbab
xx |
abababca
得到部分匹配長度為 1 , partial_match_length = 1, next[partial_match_length – 1] = 0,接下來匹配不用跳過字元,向右匹配,匹配串比剩餘的主串要長,所以沒有找到匹配的字元串。
4、KMP 演算法程式碼實現,使用 C 語言實現
#include <stdio.h> #include <stdlib.h> #include <string.h> void get_next(char T[],int next[])//next數組 { int i,j; i=0;//前 j=1;//後 next[1]=0; while(j<T[0]) { if(i==0 || T[i]==T[j]) { i++; j++; next[j]=i; /*if(T[i]!=T[j]) { next[j]=i; } else { next[j]=next[i]; }*/ } else { i=next[i]; } } } int Index_KMP(char S[],char T[]) { int next[1000]; int i=1; int j=1; get_next(T,next);//獲得next數組 /* for(i=1;i<=T[0];i++) { printf("%d ",next[i]); } */ while(i<=S[0] && j<=T[0]) { if(j==0||S[i]==T[j]) { i++; j++; } else { j=next[j]; } } if(j>T[0]) return i-T[0]; return 0; } int main (){ char T[1000],S[1000]; int i,k; while(scanf("%s %s",S,T)!=EOF) { k=strlen(T); for(i=strlen(T);i>0;i--)//向後移動 { T[i]=T[i-1]; } T[0]=k; k=strlen(S); for(i=strlen(S);i>0;i--)//向後移動 { S[i]=S[i-1]; } S[0]=k; printf("%dn",Index_KMP(S,T)); } return 0; }
運行結果如下:
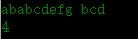
4 為第一個出現匹配字元串的數字下標從 1 開始
5、個人總結
經過這次對於 KMP 演算法的練習,使我重新練習了一遍,關於 KMP 中演算法實現的某些步驟依舊不是很清楚,有些地方想得還不是特別明白,也許這就是差距。今天出現了一些程式碼的 Bug,為了解決 Bug 查了一些網站的資料,重新溫習了 C語言的使用,今天過得很充實。
歡迎大家關注我的微信公眾號:
參考資料:
http://jakeboxer.com/blog/2009/12/13/the-knuth-morris-pratt-algorithm-in-my-own-words/
http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html
https://liam.page/2016/12/20/KMP-Algorithm/
https://blog.dotcpp.com/a/8986