Tensorflow學習筆記No.7
- 2020 年 10 月 17 日
- 筆記
- TensorFlow
tf.data與自定義訓練綜合實例
使用tf.data自定義貓狗數據集,並使用自定義訓練實現貓狗數據集的分類。
1.使用tf.data創建自定義數據集
我們使用kaggle上的貓狗數據以及tf.data來建立自己的貓狗數據集。
tf.data詳細的使用方法中在Tensorflow學習筆記No.5中以經介紹過,這裡只簡略講述。
打開kaggle中的notebook,點擊右側”+Add data”,搜索如下數據集,並點擊右側”Add”。
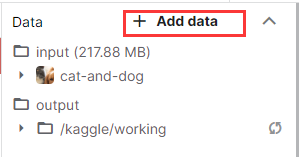

隨後Cat and Dog這個數據集就會被添加在input目錄下。
1.1獲取圖片路徑
首先,導入需要的模組~
1 import tensorflow as tf 2 from tensorflow import keras 3 import matplotlib.pyplot as plt 4 %matplotlib inline 5 import numpy as np 6 import glob 7 import os 8 import pathlib
使用pathlib.path()方法獲取文件目錄。
文件目錄如下:
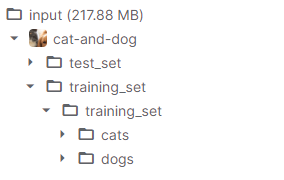
1 data_root = pathlib.Path('../input/cat-and-dog/training_set/training_set')
data_root記錄了貓狗數據集在kaggle中的儲存位置。
隨後我們使用.glob()方法獲取該路徑下的所有圖片路徑。
1 all_image_path = list(data_root.glob('*/*.jpg'))
使用random.shuffle()方法對路徑進行亂序(因為後續也會對數據進行亂序和數據增強處理,這一步可有可無),並記錄圖片總數。
1 import random 2 random.shuffle(all_image_path) 3 image_count = len(all_image_path)
2.2對圖片進行標記
獲取全部的圖片後,我們要對所有的圖片打上標籤,以便區分圖片是cat還是dog,用於後續對神經網路的訓練。
首先,獲取標籤的名稱,也就是存放圖片的文件夾的名字(cats/dogs)。
1 label_name = sorted([item.name for item in data_root.glob('training_set/*')])
獲取的標籤名如下:

然後我們建立字典,將標籤名映射為0,1。
1 name_to_indx = dict((name, indx) for indx, name in enumerate(label_name))

通過獲取的圖片路徑將所有的圖片打上標籤。
1 all_image_path = [str(path) for path in all_image_path] 2 all_image_label = [name_to_indx[pathlib.Path(p).parent.name] for p in all_image_path]
2.3影像處理與數據增強
由於數據增強只需要對train數據進行增強,所以我們定義兩個函數分別對train和test數據進行處理。
對讀入的圖片進行解碼,並將尺寸歸一化。
對訓練集數據進行隨機上下左右翻轉與裁剪,增強數據。
1 def load_preprosess_image(path, label): 2 img = tf.io.read_file(path) 3 img = tf.image.decode_jpeg(img, channels = 3) 4 img = tf.image.resize(img, [320, 320]) 5 #resize_with_crop_or_pad填充與裁剪 6 7 #數據增強 8 img = tf.image.random_crop(img, [256, 256, 3]) #隨機裁剪 9 img = tf.image.random_flip_left_right(img) #隨機左右翻轉 10 img = tf.image.random_flip_up_down(img) #隨機上下翻轉 11 #img = tf.image.random_brightness(img, 0.5) #隨機調整亮度 12 #img = tf.image.random_contrast(img, 0, 1) #隨機調整對比度 13 14 img = tf.cast(img, tf.float32) 15 img = img / 255 16 label = tf.reshape(label, [1]) 17 return img, label 18 #載入和預處理圖片 19 20 def load_preprosess_image_test(path, label): 21 img = tf.io.read_file(path) 22 img = tf.image.decode_jpeg(img, channels = 3) 23 img = tf.image.resize(img, [256, 256]) 24 #resize_with_crop_or_pad填充與裁剪 25 26 img = tf.cast(img, tf.float32) 27 img = img / 255 28 label = tf.reshape(label, [1]) 29 return img, label 30 #載入和預處理圖片
通過tf.data.Dataset.from_tensor_slices()方法建立數據集。
1 dataset = tf.data.Dataset.from_tensor_slices((all_image_path, all_image_label))
將數據集分割為訓練集與測試集,並分別使用預處理函數對圖片進行處理。
1 test_count = int(image_count * 0.2) 2 train_count = image_count - test_count 3 train_dataset = dataset.skip(test_count) 4 test_dataset = dataset.take(test_count) 5 6 train_dataset = train_dataset.map(load_preprosess_image) 7 test_dataset = test_dataset.map(load_preprosess_image_test)
對訓練集和測試集劃分BATCH_SIZE。
1 BATCH_SIZE = 16 2 train_dataset = train_dataset.shuffle(train_count).batch(BATCH_SIZE) 3 test_dataset = test_dataset.batch(BATCH_SIZE)
註:此時的train_dataset與test_dataset都是可迭代對象,我們可以使用迭代器查看數據。
1 img, label = next(iter(train_dataset)) 2 plt.imshow(img[0]) #由於這個東西運行的很慢,這裡就不展示運行結果了,這兩行程式碼同樣可有可無。
2.使用自定義訓練訓練神經網路
2.1建立神經網路模型
我們仿照VGG_16製作一個網路模型(不完全相同)。
1 model = keras.Sequential() 2 model.add(keras.layers.Conv2D(64, (3, 3), input_shape = (256, 256, 3),padding = 'same', activation = 'relu')) 3 model.add(keras.layers.BatchNormalization()) 4 model.add(keras.layers.Conv2D(64, (3, 3), activation = 'relu')) 5 model.add(keras.layers.BatchNormalization()) 6 model.add(keras.layers.MaxPooling2D()) 7 model.add(keras.layers.Conv2D(128, (3, 3), activation = 'relu')) 8 model.add(keras.layers.BatchNormalization()) 9 model.add(keras.layers.Conv2D(128, (3, 3), activation = 'relu')) 10 model.add(keras.layers.BatchNormalization()) 11 model.add(keras.layers.MaxPooling2D()) 12 model.add(keras.layers.Conv2D(256, (3, 3), activation = 'relu')) 13 model.add(keras.layers.BatchNormalization()) 14 model.add(keras.layers.Conv2D(256, (3, 3), activation = 'relu')) 15 model.add(keras.layers.BatchNormalization()) 16 model.add(keras.layers.Conv2D(256, (3, 3), activation = 'relu')) 17 model.add(keras.layers.BatchNormalization()) 18 model.add(keras.layers.MaxPooling2D()) 19 model.add(keras.layers.Conv2D(512, (3, 3), activation = 'relu')) 20 model.add(keras.layers.BatchNormalization()) 21 model.add(keras.layers.Conv2D(512, (3, 3), activation = 'relu')) 22 model.add(keras.layers.BatchNormalization()) 23 model.add(keras.layers.Conv2D(512, (3, 3), activation = 'relu')) 24 model.add(keras.layers.BatchNormalization()) 25 model.add(keras.layers.MaxPooling2D()) 26 model.add(keras.layers.Conv2D(512, (3, 3), activation = 'relu')) 27 model.add(keras.layers.BatchNormalization()) 28 model.add(keras.layers.Conv2D(512, (3, 3), activation = 'relu')) 29 model.add(keras.layers.BatchNormalization()) 30 model.add(keras.layers.Conv2D(512, (3, 3), activation = 'relu')) 31 model.add(keras.layers.BatchNormalization()) 32 model.add(keras.layers.MaxPooling2D()) 33 model.add(keras.layers.GlobalAveragePooling2D()) 34 model.add(keras.layers.Dense(1024, activation = 'relu')) 35 model.add(keras.layers.BatchNormalization()) 36 model.add(keras.layers.Dense(256, activation = 'relu')) 37 model.add(keras.layers.BatchNormalization()) 38 model.add(keras.layers.Dense(1))
注意!最後一層Dense層沒有使用sigmoid函數進行激活。
2.2自定義模型訓練策略
我們選用Adam作為優化器,並定義模型的正確率與平均損失的計算方式。
1 optimizer = tf.keras.optimizers.Adam(learning_rate = 0.001) 2 epoch_loss_avg = tf.keras.metrics.Mean('train_loss', dtype = tf.float32)#參數為name 3 train_accuracy = tf.keras.metrics.Accuracy() 4 5 epoch_loss_avg_test = tf.keras.metrics.Mean('train_loss', dtype = tf.float32)#參數為name 6 test_accuracy = tf.keras.metrics.Accuracy()
定義訓練集與測試集的的訓練函數。
1 def train_step(model, images, labels): 2 with tf.GradientTape() as GT: #記錄梯度 3 pred = model(images, training = True) 4 loss_step = tf.keras.losses.BinaryCrossentropy(from_logits = True)(labels, pred) 5 #from_logits 模型中輸出結果是否進行了激活,未激活則為True 6 grads = GT.gradient(loss_step, model.trainable_variables) 7 #計算梯度 8 optimizer.apply_gradients(zip(grads, model.trainable_variables)) 9 #利用梯度對模型參數進行優化 10 epoch_loss_avg(loss_step)#計算loss 11 train_accuracy(labels, tf.cast(pred > 0, tf.int32))#計算acc 12 13 def test_step(model, images, labels): 14 pred = model(images, training = False)#pred = model.predict(images)# 15 loss_step = loss_step = tf.keras.losses.BinaryCrossentropy(from_logits = True)(labels, pred) 16 17 epoch_loss_avg_test(loss_step)#計算loss 18 test_accuracy(labels, tf.cast(pred > 0, tf.int32))#計算acc
使用with tf.GradientTape()記錄訓練過程中的loss值。
使用model()對訓練集進行預測,在通過損失函數BinaryCrossentropy()計算loss值。
使用.gradient()方法來計算梯度,參數為,loss值與模型的可訓練參數。
計算好梯度之後,使用optimizer對模型的可訓練參數進行優化。
最後計算模型的平均loss與正確率。
對測試集僅進行預測計算loss與正確率即可,無需對模型參數進行更新。
2.3自定義訓練過程對模型進行訓練
首先,定義幾個列表記錄loss與acc,用來繪製訓練過程的影像。
1 train_loss_result = [] 2 train_acc_result = [] 3 4 test_loss_result = [] 5 test_acc_result = []
定義要訓練的epochs,這裡我們對模型訓練130個epoch。
1 num_epochs = 130
定義訓練函數:
1 for epoch in range(num_epochs): 2 indx = 1 3 for images, labels in train_dataset: 4 train_step(model, images, labels) 5 indx += 1 6 if(indx % 5 == 0): 7 print('.', end = '') 8 print() 9 #訓練過程 10 train_loss_result.append(epoch_loss_avg.result()) 11 train_acc_result.append(train_accuracy.result()) 12 #記錄loss與acc 13 14 for images, labels in test_dataset: 15 test_step(model, images, labels) 16 17 test_loss_result.append(epoch_loss_avg_test.result()) 18 test_acc_result.append(test_accuracy.result()) 19 20 print('Epoch:{}: loss:{:.3f}, acc:{:.3f}, val_loss:{:.3f}, val_acc:{:.3f}'.format( 21 epoch + 1, epoch_loss_avg.result(), train_accuracy.result(), 22 epoch_loss_avg_test.result(), test_accuracy.result() 23 )) 24 25 epoch_loss_avg.reset_states() 26 train_accuracy.reset_states() 27 #清空,統計下一個epoch的均值 28 29 epoch_loss_avg_test.reset_states() 30 test_accuracy.reset_states()
在每個epoch中,對train_dataset進行迭代,每次迭代處理的數據數量為一個BATCH_SIZE(),對每個BATCH_SIZE使用定義好的訓練函數對模型進行訓練,輸出訓練過程並使用之前定義好的列表記錄訓練過程。
一個epoch訓練完後,對loss均值與正確率計算函數進行清空處理,為下一個epoch的訓練做好準備。
2.3訓練結果
點擊kaggle右上角的”Save version”保存並將模型提交進行訓練。
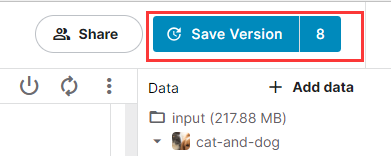
選擇提交(Commit),並點擊”Advanced Settings”。

選擇使用GPU進行訓練,否則會訓練的非常緩慢。
最後點擊Save即可。
由於使用的網路模型較深,且參數較多,所以訓練的速度很慢,大概訓練了3個半小時得到如下訓練結果:
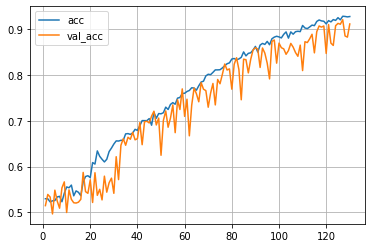
模型在訓練集上達到了92.8%的正確率,在測試集上達到了91.1%的正確率。
本次更新的較為匆忙,很多API的用法沒有很詳細的進行介紹,後面會再次更新進行補充。