深度CTR預估模型的演化之路2019最新進展
- 2019 年 11 月 12 日
- 筆記
來源 | 深度傳送門(ID: deep_deliver)
導讀:本文主要介紹深度CTR經典預估模型的演化之路以及在2019工業界的最新進展。
介紹
在計算廣告和推薦系統中,點擊率(Click Through Rate,以下簡稱CTR)預估是一個重要問題。在CTR預估任務中(以下簡稱CTR任務),我們通常利用user資訊、item資訊和context資訊來預測user對item的CTR。
傳統CTR預估任務採用的方法不外乎特徵工程+LR/FM的組合,這種通過大量特徵工程來提高預測效果的工作費時費力,且構造過程不具有通用性。此外,傳統的人工特徵工程處理開放式的特徵(如用戶ID)似乎難如登天,而這些特徵往往能夠為模型提供許多正向的收益。
隨著深度學習的發展,近年來越來越多的深度學習模型被應用到CTR任務中來。Wide&Deep、DeepFM等模型相信大家都耳熟能詳,DIN、DIEN等結合用戶歷史行為的模型最近更是被人津津樂道。
本文主要關注利用僅根據user資訊、item資訊、context資訊,不考慮用戶歷史資訊的「傳統」深度CTR模型的演化過程,希望通過梳理,大家能夠對近年來深度學習模型在CTR任務上的探索有一個大體的認知。
深度CTR模型的基本框架
典型的深度CTR模型可以分成以下四個部分:輸入、特徵嵌入(Embedding)、特徵交互(有時候也稱為特徵提取)和輸出。

輸入:輸入通常包含若干個<特徵ID, 特徵值>對,當然也可以One-Hot Encoding展開(如上圖所示)。
特徵嵌入(Embedding):在CTR任務中數據特徵呈現高維、稀疏的特點,假設特徵數為N,直接將這些特徵進行One-Hot Encoding會產生巨大的參數數量。以FM的二階項為例子,如一萬個特徵,兩兩構造二階特徵時將會產生一億規模的特徵權重參數。
Embedding可以減小模型複雜度,具體過程如下:
通過矩陣乘法將1*N的離散特徵向量通過維度為N*k的參數矩陣W壓縮成1*k的低維度稠密向量,通常k<<N,參數從N^2降到N*k。
此外,在CTR任務中特徵常以分組(group, 有時也稱領域field)的離散特徵資訊,如user gender、item category等,在從FM推演各深度學習CTR預估模型(附程式碼)[1]中提到「將特徵具有領域關係的特點作為先驗知識加入到神經網路的設計中去:同領域的特徵嵌入後直接求和作為一個整體嵌入向量」。沿用這樣的方法基於以下三個原因:
- 經分組特徵嵌入後送入後續模組得到的是定長向量,且特徵組個數<<特徵數,減少後續模組的參數量。
- 不同組的嵌入維度(即上文中的k)可以不同,可以根據特徵組內的特徵個數合理設計嵌入維度。
- 如果特徵組的嵌入維度相同,則不同特徵組間的嵌入向量可以兩兩組合得到大有裨益的二階特徵資訊。
特徵交互:經過特徵嵌入可以獲得稠密向量,在特徵交互模組中設計合理的模型結構將稠密向量變成標量,該模組直接決定模型的品質好壞。本文接下來的內容將重點介紹這個模組的設計過程。
輸出:將特徵交互模組輸出的標量用sigmoid函數映射到[0, 1],即表示CTR。
萬丈高樓平地起:LR、FM、Embedding+MLP
LR: Logistic Regression
不積跬步無以至千里,從最簡單的LR模型說起。一言以蔽之,LR將特徵加權求和並經sigmoid即得到CTR值,在深度CTR模型的基本框架下的LR表示如下圖:

其中嵌入部分的維度大小均為1;特徵交互中具體工作是將嵌入部分得到的值相加。模型的抽象化表示如下圖:

FM:Factorization Machines
與LR相比,FM增加了二階項的資訊,通過窮舉所有的二階特徵(一階特徵兩兩組合)並結合特徵的有效性(特徵權重)來預測點擊結果,FM的二階特徵組合過程可拆分成Embedding和內積兩個步驟。

Embedding+MLP
多層感知機MLP因具有學習高階特徵的能力常常被用在各種深度CTR模型中。MLP主要由若干個全連接層和激活層組成。

他山之石可以攻玉
基於FM中的Quadratic Layer的改進
- AFM: Attentional FM 【IJCAI'17】
兩個特徵內積的過程如下:兩個特徵向量做Hadamard Product得到1*k的二階組合特徵向量,再將這個向量沿嵌入維度求和(sum by dimension)得到一個實數值。
AFM[2]通過注意力網路學習二階組合特徵的重要性,將所有的二階組合特徵向量進行加權求和作為Attention Net部分的輸出。

- IAFM【AAAI'19】
IAFM(Interaction-aware FM)[3]從特徵層面和特徵組層面共同影響二階組合特徵的重要性。其中在特徵組層面,通過網路學習特徵所在特徵組之間的重要性向量。最後將二階特徵向量和特徵組向量做Hadamard Product再求和得到Attention Net部分的輸出。

基於Embedding+MLP的改進
- Wide&Deep【DLRS'16】
將LR和MLP並聯即可得到Wide&Deep模型[4],可同時學習一階特徵和高階特徵。

- FNN【ECIR'16】
FNN[5]本質上還是Embedding+MLP模型,只是利用FM模型預訓練Group Embedding。近年來一些研究表明通過預訓練FM初始化Embedding值的深度學習模型在一些任務上能夠達到快速收斂的效果。

- NFM【SIGIR'17】
將LR、MLP和Quadratic Layer串連可得到NFM[6],注意這裡的Quadratic Layer和原始FM模型里有些許不同。

- DeepFM 【IJCAI'17】
將LR、MLP和Quadratic Layer並聯可得到DeepFM[7],注意到MLP和Quadratic Layer共享Group Embedding。DeepFM是目前效率和效果上都表現不錯的一個模型。

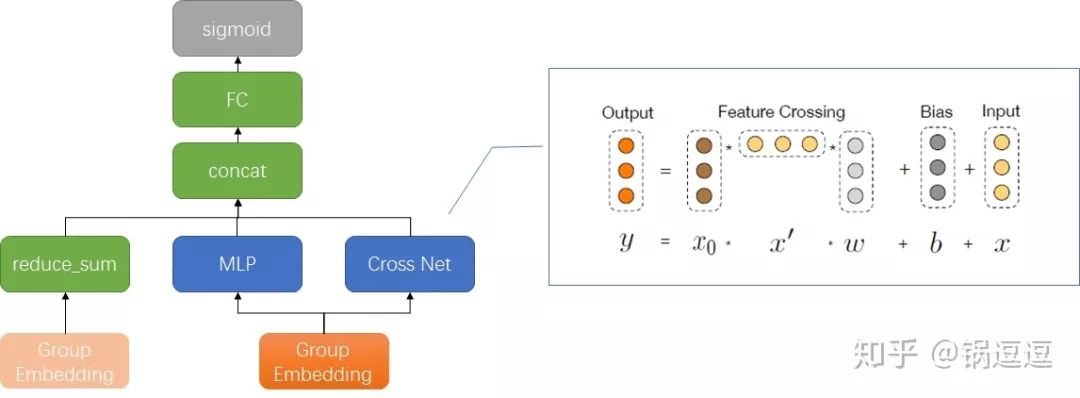
- DCN: 【ADKDD'17】
將LR、MLP和Cross Net並聯可得到DCN[8]。Cross Net是一個堆疊型網路,該部分的初始輸入是將f個(1,k)的特徵組向量concat成一個(1,f*k)的向量(不同特徵組的嵌入維度可以不同,反正拼起來就對了)。
每層計算過程如下:輸入向量和初始輸入向量做Cartesian product得到(f*k,f*k)的矩陣,再重新投影成(1,k)向量,每一層輸出都包含輸入向量。
- xDeepFM【KDD'18】
將LR、MLP和CIN並聯可得到xDeepFM[9]。

為了統一符號解釋一下,圖中的D=嵌入維度k。CIN也是一個堆疊型網路,該部分的初始輸入是一個(f,k)的矩陣。每層計算過程如下:輸入矩陣(Hi, k)和初始輸入矩陣沿嵌入維度方向做Cartesian product得到(Hi, f, k)的三維矩陣,再重新投影成(Hi+1,k)矩陣。
CIN的最後一層:將CIN中間層的輸出矩陣沿嵌入維度方向做sum pooling得到(H1,1),(H2,1)…(Hl,1)的向量,再將這些向量concat起來作為CIN網路的輸出。
在這裡可以將CrossNet和CIN做一個小小的對比:

- PNN【ICDM'16】
將Inner/Outer Product Layer和MLP串連可得到PNN模型[10]。其中Inner Product Layer和Quadratic Layer v2實際上是一個東西(權重在Product Layer層增加了可訓練的權重參數)。
後面提到OENN、OANN、FGCNN都是基於IPNN(使用Inner Product Layer)進行改進。

- OENN【SIGIR'19】
OENN(Order-aware Embedding Neural Network for CTR Prediction)[11]認為相同特徵在不同階交互時應當使用不同嵌入向量,對於大於3階的交互過程則使用CIN替代。

- OANN
OANN(Operation-aware Neural Networks for User Response Prediction)[12]認為相同特徵在交互過程中執行不同的操作應當使用不同嵌入向量,例如一共有f個特徵,每個特徵與其他特徵做Inner Product會執行(f-1)次操作,加上不交互的嵌入向量,即一個特徵需要有f個對應的嵌入向量。

- FGCNN【WWW'19】
FGCNN(Feature Generation by Convolutional Neural Network)[13]是在IPNN的基礎上串連了一個Feature Generation Layer。Feature Generation由Convolutional Layer+MaxPooling Layer+FC(原文中的recombination layer)組成,CNN提取useful neighbor feature patterns,將MaxPooling得到的特徵組資訊拍平了通過一個FC可提取global feature interactions.

- FiBiNET【RecSys'19】
FiBiNET[14]的創新點在於引入CV中的SENET和設計了Bilinear-Interaction。SENET是一個比較有效的特徵提取方法,共分為三個部分:Squeeze,Excitation和Re-Weight。
Binear-Interaction則是在特徵之間加入(k,k)的權重參數矩陣(文中的W)進行計算,論文中設置了三種模式:共享(Field-All)、特徵組共享(Field-Each)、特徵獨享(Field-Interaction),分別要訓練1個、f個、f*(f-1)/2個維度為(k,k)的權重參數矩陣。

- AutoInt【CIKM'19】
AutoInt[15]可以看做將MLP的FC部分替換成Multi-head Self-Attention。

總結
1. 深度CTR模型說白了就是一個「搭積木」的過程,然而不是每塊「積木」都是有效的,「積木」之間的拼接方式也會影響模型的好壞。
2. 甲之蜜糖乙之砒霜。不同模型適用的場景不同,這部分需要一定的實驗和經驗積累,我經驗尚淺,就不在此班門弄斧了。
3. 推薦一個大佬的開源實現,向厲害的人學習:https://github.com/shenweichen/DeepCTR。
參考文獻
1. https://blog.csdn.net/han_xiaoyang/article/details/81031961
2. Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Networks
3. Interaction-aware Factorization Machines for Recommender Systems
4. Wide & Deep Learning for Recommender Systems
5. Deep Learning over Multi-field Categorical Data – A Case Study on User Response Prediction
6. Neural Factorization Machines for Sparse Predictive Analytics
7. DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
8. Deep & Cross Network for Ad Click Predictions
9. xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems
10. Product-based Neural Networks for User Response Prediction
11. Order-aware Embedding Neural Network for CTR Prediction
12. Operation-aware Neural Networks for User Response Prediction
13. Feature Generation by Convolutional Neural Network for Click-Through Rate Prediction
14. FiBiNET: Combining Feature Importance and Bilinear feature Interaction for Click-Through Rate Prediction
15. AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks
原文鏈接:
https://zhuanlan.zhihu.com/p/86181485
(*本文為AI科技大本營轉載文章,轉載請聯繫原作者)


