行人被遮擋問題怎麼破?百度提出PGFA新方法,發布Occluded-DukeMTMC大型數據集 | ICCV 2019
- 2019 年 11 月 12 日
- 筆記
譯者 | 劉暢
編輯 | Jane
出品 | AI科技大本營(ID:rgznai100)
【導語】在以人搜人的場景中,行人會經常被各種物體遮擋。之前的行人再識別(re-id)方法要麼忽略了此問題,要麼是基於極端假設來解決該問題。為了解決遮擋問題,作者提出檢測遮擋區域,並在特徵生成和匹配過程中去排除那些遮擋區域。
在本文中,作者介紹了一種稱為姿態引導特徵對齊(PGFA)的新方法,該方法利用姿勢界標從帶遮擋的圖片中分離出有用的資訊。在特徵構建階段,作者利用人的關鍵點資訊去生成注意力圖。生成的注意力圖會表明指定的身體部位是否被遮擋,並引導模型去關注非遮擋區域。在匹配過程中,作者將全局特徵明確劃分為多個部分,並使用姿態關鍵點資訊來得到哪些部分特徵屬於目標。僅將可見區域用於檢索。
此外,作者為遮擋行人重識別問題構建了一個大規模數據集,即OccludedDukeMTMC,這是迄今為止針對遮擋行人重識別問題最大的數據集。作者在本文構造的遮擋Re-id數據集,兩個partial Reid數據集和兩個常用的無遮擋Re-id數據集上進行了實驗。實驗結果電視,作者的方法在三個遮擋數據集上的性能大大優於現有的行人再識別方法,而在兩個無遮擋的數據集上仍保持優異的性能。

論文地址:
https://yu-wu.net/pdf/ICCV2019_Occluded-reID.pdf
引言
行人再識別的任務是從影像集合中檢索待查詢行人影像,它在近年來取得了快速的發展。之前的行人再識別方法是從整個影像中提取特徵,並將這些特徵用作視覺表徵,再整個影像集裡面去匹配。為了構建有效的表示,已有的方法要麼直接利用全局人物特徵,要麼結合身體部位的局部特徵。
但是,這些已有工作中提出的方法並未考慮到目標人被各種物體(例如汽車,樹木或其他人)遮擋的情況。當一個人被部分遮擋時,從整個影像中提取的特徵表達可能會分散目標資訊。如果模型無法區分遮擋區域和行人區域,則可能導致錯誤的檢索結果。例如,如圖1所示,在給定的查詢影像中,行人被白色汽車擋住,已有的方法可能會錯誤地檢索具有相似汽車的人的影像。

最近,有一些工作嘗試解決遮擋問題。如圖2的第一行所示,在其部分ReID的問題條件中,檢索影像是被物體遮擋住的,而庫影像仍然是整體影像。為了抑制由遮擋引入的額外資訊,這類方法首先在帶檢索的影像中手動裁剪被遮擋的目標,然後將未遮擋的部分用作新的查詢。但是,部分ReID問題有兩個局限性:(1)他們需要強有力的假設,即庫影像裡面的目標都是完整的(2)他們需要手動裁剪操作。這樣的手動過程會使裁剪結果產生人為偏見。

與部分Re-ID問題不同,本文提出了遮擋的Re-ID問題,在該問題中,檢索影像和庫影像都包含遮擋。所有待搜索影像都有遮擋,使得在檢索時至少存在一個遮擋的影像。除了整體影像之外,圖庫集也包含被遮擋的影像,這與現實世界的場景一致。此外,考慮到效率和人為因素,遮擋的Re-ID不採用人工裁剪過程。
圖2顯示了部分Re-ID和被遮擋的Re-ID兩個問題之間的區別。為了便於研究遮擋的Re-ID問題,我們引入了一個大數據集,名為OccludedDukeMTMC,該數據集是派生自DukeMTMC-ReID數據集。在新數據集中,所有查詢影像都被各種各樣的遮擋物(例如樹木,汽車,其他人)遮擋,而圖庫影像同時包含整體影像和被遮擋的影像。
為了解決這個更具挑戰性的遮擋Re-ID問題,作者提出了兩種策略來區分遮擋區域中的可見區域資訊:(1)在特徵構建階段,模型應更加註意非遮擋部分。(2)在匹配階段,作者將全局特徵顯式劃分為多個部分,並且僅考慮待檢索影像和圖庫影像之間的共同可見區域。
受這兩種策略的驅動,作者提出以姿勢關鍵點為引導資訊,在圖庫和待檢索影像之間比對提取的特徵,並將其命名為「 Pose Guided Feature Alignment(PGFA)」方法。
與已有的工作相比,作者提出的PGFA具有兩大優點:首先,PGFA不需要任何手動裁剪操作,效率更高。其次,檢測到的關鍵點資訊可以明確地指導模型關注非遮擋人的區域,並在特徵構建和匹配階段過濾遮擋區域的資訊。在Occluded-DukeMTMC數據集上進行的實驗表明,本文的方法在很大程度上優於已有的方法。
在兩個部分Re-ID數據集和兩個常用的整體基準測試集中,本文的方法效果不差。本文有兩大貢獻:(1)本文介紹了一個具有挑戰性的大規模被遮擋的re-id數據集Occluded-DukeMTMC,它是迄今為止最大的專註於帶遮擋Re-ID問題的數據集。(2)本文提出了PGFA,這是一種解決遮擋的Re-ID問題的有效方法。PGFA充分利用了檢測到的人體關鍵點資訊,並將其用來引導模型,在特徵構建階段關注非遮擋區域,並在匹配階段對齊。
方法
- 網路架構

上圖是作者提出的姿勢引導特徵對齊(PGFA)方法,該方法包括兩個階段,一個是表徵構造階段,另一個是匹配階段。
表徵構造階段主要的結構包含兩部分,一個是局部特徵分支(Partial Feature Branch),另一個是姿態引導全局特徵分支(Pose-Guided Global Feature Branch),這個分支是利用姿態估計去檢測人體關鍵點並引導更健壯的表徵結構。
匹配階段如下圖所示,待查詢影像和圖庫影像之間的最終距離由兩部分組成,一個是共享可見區域中局部特徵的距離,另一個是姿態引導全局特徵的距離。

其中,每個部分具體的實現構造過程,作者在論文中有詳細的敘述。
實驗
- 實現細節
作者使用ResNet50作為骨幹網路,並僅做了較小的修改:刪除平均池化層和全連接層,將conv4_1的stride設置為1。並通過ImageNet預訓練模型初始化模型。在實驗設置中,輸入影像的大小調整為384×128,並通過隨機翻轉和隨機遮擋進行了增強。
將批次大小設置為32,將訓練epoch設置為60。在Occluded-DukeMTMC,Market-1501和DukeMTMC-reID上,基本學習率初始化為0.1,並在40個epoch後衰減為0.01,衰減係數λ 為0.2。在Partial-REID和Partial-iLIDS上,基礎學習速率初始化為0.02,衰減係數λ設置為0.9。
為了從遮擋的影像中檢測出關鍵點,作者使用了在COCO數據集上經過預訓練的AlphaPose。設置關鍵點的置信度得分大於0.2。
- 結果對比
下圖展示了在多個測試集上的對比效果。包括Occluded-DukeMTMC,Partial-REID,Partial-iLIDS,Market-1501,DukeMTMC-reID五個數據集。


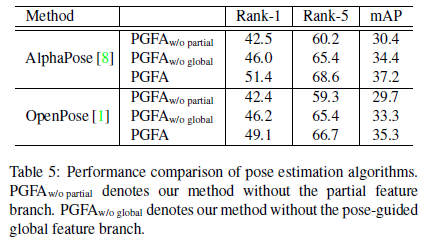
另外,作者為了驗證本文提出的各個模組的有效性。做了一系列的消融實驗(Ablation study)。如下所示,其中包括局部特徵分支和姿態引導全局特徵分支之間的平衡係數;局部特徵的參數Part Number;篩選姿態關鍵點的閾值;以及使用不同姿態估計方法下的效果對比。


結論
在本文中,作者為解決帶遮擋的ReID問題做出了貢獻。首先,本文提出了PGFA方法,該方法在遮擋式Re-ID問題上優於現有方法。其次,為便於研究帶遮擋的Re-ID問題,本文介紹了一個大型數據集Occluded-DukeMTMC。
(*本文為 AI科技大本營編譯文章,轉載請微信聯繫 1092722531)


