Java 集合看這一篇就夠了
- 2020 年 10 月 15 日
- 筆記
大家好,這裡是《齊姐聊數據結構》系列之大集合。
話不多說,直接上圖:
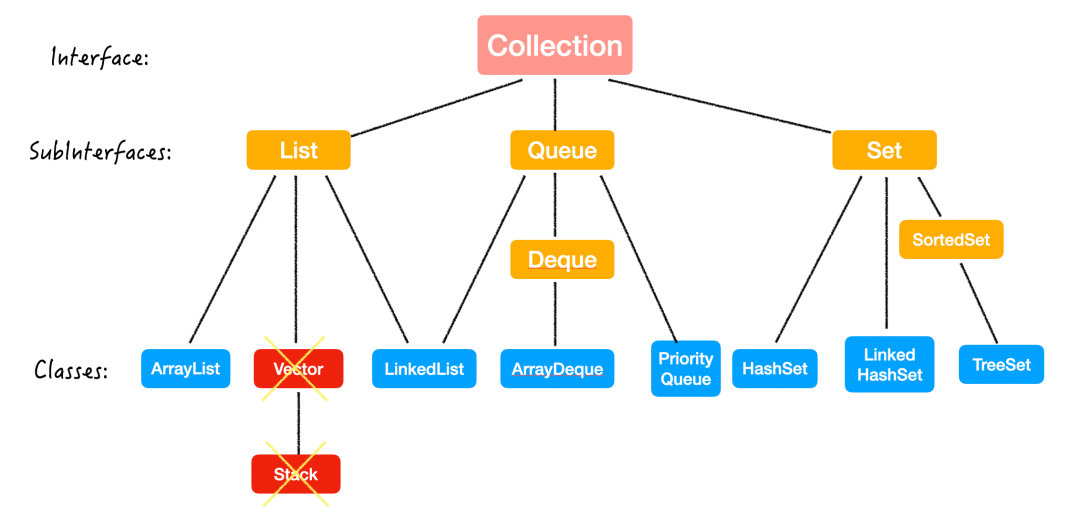
Java 集合,也稱作容器,主要是由兩大介面 (Interface) 派生出來的:
Collection 和 Map
顧名思義,容器就是用來存放數據的。
那麼這兩大介面的不同之處在於:
- Collection 存放單一元素;
- Map 存放 key-value 鍵值對。
就是單身狗放 Collection 裡面,couple 就放 Map 里。(所以你屬於哪裡?
學習這些集合框架,我認為有 4 個目標:
- 明確每個介面和類的對應關係;
- 對每個介面和類,熟悉常用的 API;
- 對不同的場景,能夠選擇合適的數據結構並分析優缺點;
- 學習源碼的設計,面試要會答啊。
關於 Map,之前那篇 HashMap 的文章已經講的非常透徹詳盡了,所以本文不再贅述。如果還沒看過那篇文章的小夥伴,快去公眾號內回復「HashMap」看文章吧~
Collection
先來看最上層的 Collection.
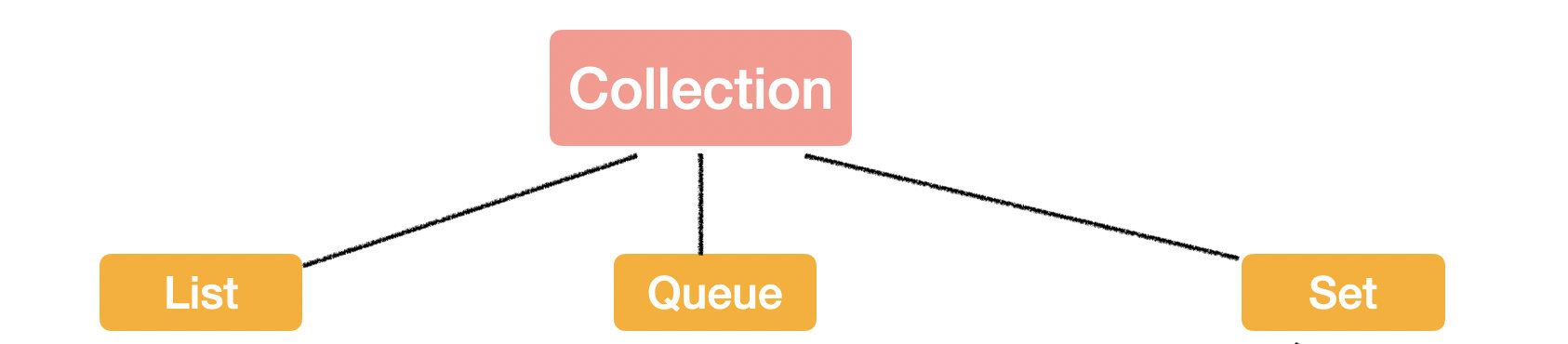
Collection 里還定義了很多方法,這些方法也都會繼承到各個子介面和實現類里,而這些 API 的使用也是日常工作和面試常見常考的,所以我們先來看下這些方法。
操作集合,無非就是「增刪改查」四大類,也叫 CRUD:
Create, Read, Update, and Delete.
那我也把這些 API 分為這四大類:
| 功能 | 方法 |
|---|---|
| 增 | add()/addAll() |
| 刪 | remove()/ removeAll() |
| 改 | Collection Interface 里沒有 |
| 查 | contains()/ containsAll() |
| 其他 | isEmpty()/size()/toArray() |
下面具體來看:
增:
boolean add(E e);
add() 方法傳入的數據類型必須是 Object,所以當寫入基本數據類型的時候,會做自動裝箱 auto-boxing 和自動拆箱 unboxing。
還有另外一個方法 addAll(),可以把另一個集合里的元素加到此集合中。
boolean addAll(Collection<? extends E> c);
刪:
boolean remove(Object o);
remove()是刪除的指定元素。
那和 addAll() 對應的,
自然就有removeAll(),就是把集合 B 中的所有元素都刪掉。
boolean removeAll(Collection<?> c);
改:
Collection Interface 里並沒有直接改元素的操作,反正刪和增就可以完成改了嘛!
查:
- 查下集合中有沒有某個特定的元素:
boolean contains(Object o);
- 查集合 A 是否包含了集合 B:
boolean containsAll(Collection<?> c);
還有一些對集合整體的操作:
- 判斷集合是否為空:
boolean isEmpty();
- 集合的大小:
int size();
- 把集合轉成數組:
Object[] toArray();
以上就是 Collection 中常用的 API 了。
在介面里都定義好了,子類不要也得要。
當然子類也會做一些自己的實現,這樣就有了不同的數據結構。
那我們一個個來看。
List
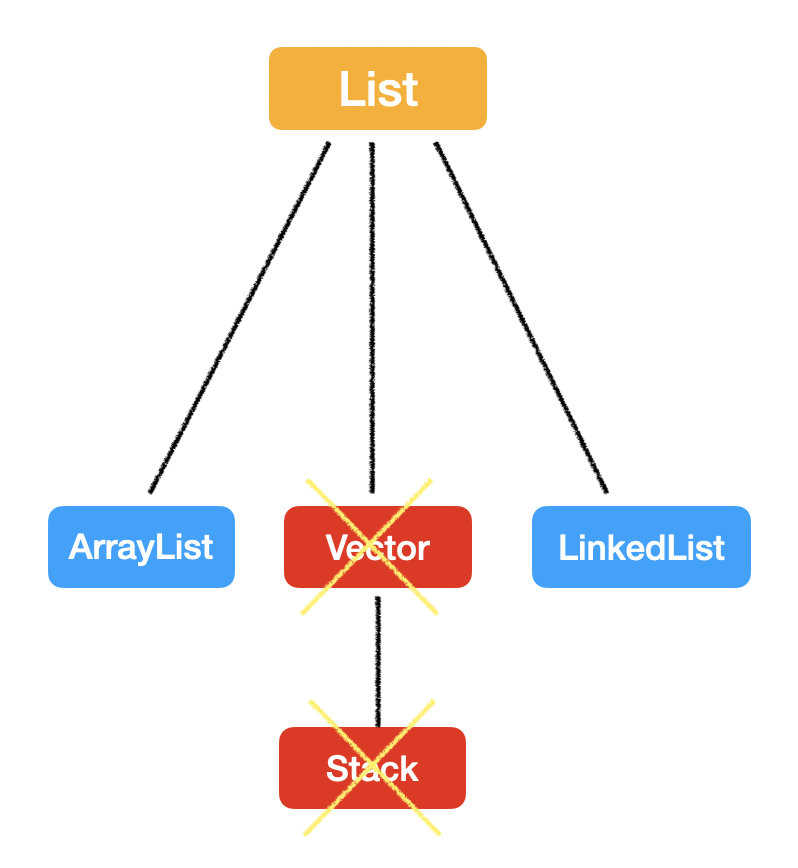
List 最大的特點就是:有序,可重複。
看官網說的:
An ordered collection (also known as a sequence).
Unlike sets, lists typically allow duplicate elements.
這一下把 Set 的特點也說出來了,和 List 完全相反,Set 是 無序,不重複的。
List 的實現方式有 LinkedList 和 ArrayList 兩種,那面試時最常問的就是這兩個數據結構如何選擇。
對於這類選擇問題:
一是考慮數據結構是否能完成需要的功能;
如果都能完成,二是考慮哪種更高效。
(萬事都是如此啊。
那具體來看這兩個 classes 的 API 和它們的時間複雜度:
| 功能 | 方法 | ArrayList | LinkedList |
|---|---|---|---|
| 增 | add(E e) | O(1) | O(1) |
| 增 | add(int index, E e) | O(n) | O(n) |
| 刪 | remove(int index) | O(n) | O(n) |
| 刪 | remove(E e) | O(n) | O(n) |
| 改 | set(int index, E e) | O(1) | O(n) |
| 查 | get(int index) | O(1) | O(n) |
稍微解釋幾個:
add(E e) 是在尾巴上加元素,雖然 ArrayList 可能會有擴容的情況出現,但是均攤複雜度(amortized time complexity)還是 O(1) 的。
add(int index, E e)是在特定的位置上加元素,LinkedList 需要先找到這個位置,再加上這個元素,雖然單純的「加」這個動作是 O(1) 的,但是要找到這個位置還是 O(n) 的。(這個有的人就認為是 O(1),和面試官解釋清楚就行了,拒絕扛精。
remove(int index)是 remove 這個 index 上的元素,所以
- ArrayList 找到這個元素的過程是 O(1),但是 remove 之後,後續元素都要往前移動一位,所以均攤複雜度是 O(n);
- LinkedList 也是要先找到這個 index,這個過程是 O(n) 的,所以整體也是 O(n)。
remove(E e)是 remove 見到的第一個這個元素,那麼
- ArrayList 要先找到這個元素,這個過程是 O(n),然後移除後還要往前移一位,這個更是 O(n),總的還是 O(n);
- LinkedList 也是要先找,這個過程是 O(n),然後移走,這個過程是 O(1),總的是 O(n).
那造成時間複雜度的區別的原因是什麼呢?
答:
-
因為 ArrayList 是用數組來實現的。
-
而數組和鏈表的最大區別就是數組是可以隨機訪問的(random access)。
這個特點造成了在數組裡可以通過下標用 O(1) 的時間拿到任何位置的數,而鏈表則做不到,只能從頭開始逐個遍歷。
也就是說在「改查」這兩個功能上,因為數組能夠隨機訪問,所以 ArrayList 的效率高。
那「增刪」呢?
如果不考慮找到這個元素的時間,
數組因為物理上的連續性,當要增刪元素時,在尾部還好,但是其他地方就會導致後續元素都要移動,所以效率較低;而鏈表則可以輕鬆的斷開和下一個元素的連接,直接插入新元素或者移除舊元素。
但是呢,實際上你不能不考慮找到元素的時間啊。。。而且如果是在尾部操作,數據量大時 ArrayList 會更快的。
所以說:
- 改查選擇 ArrayList;
- 增刪在尾部的選擇 ArrayList;
- 其他情況下,如果時間複雜度一樣,推薦選擇 ArrayList,因為 overhead 更小,或者說記憶體使用更有效率。
Vector
那作為 List 的最後一個知識點,我們來聊一下 Vector。這也是一個年齡暴露帖,用過的都是大佬。
那 Vector 和 ArrayList 一樣,也是繼承自 java.util.AbstractList
但是現在已經被棄用了,因為…它加了太多的 synchronized!
任何好處都是有代價的,執行緒安全的成本就是效率低,在某些系統里很容易成為瓶頸,所以現在大家不再在數據結構的層面加 synchronized,而是把這個任務轉移給我們程式設計師==
那麼面試常問題:Vector 和 ArrayList 的區別是什麼,只答出來這個還還不太全面。
來看 stack overflow 上的高票回答:

一是剛才已經說過的執行緒安全問題;
二是擴容時擴多少的區別。
這個得看看源碼:
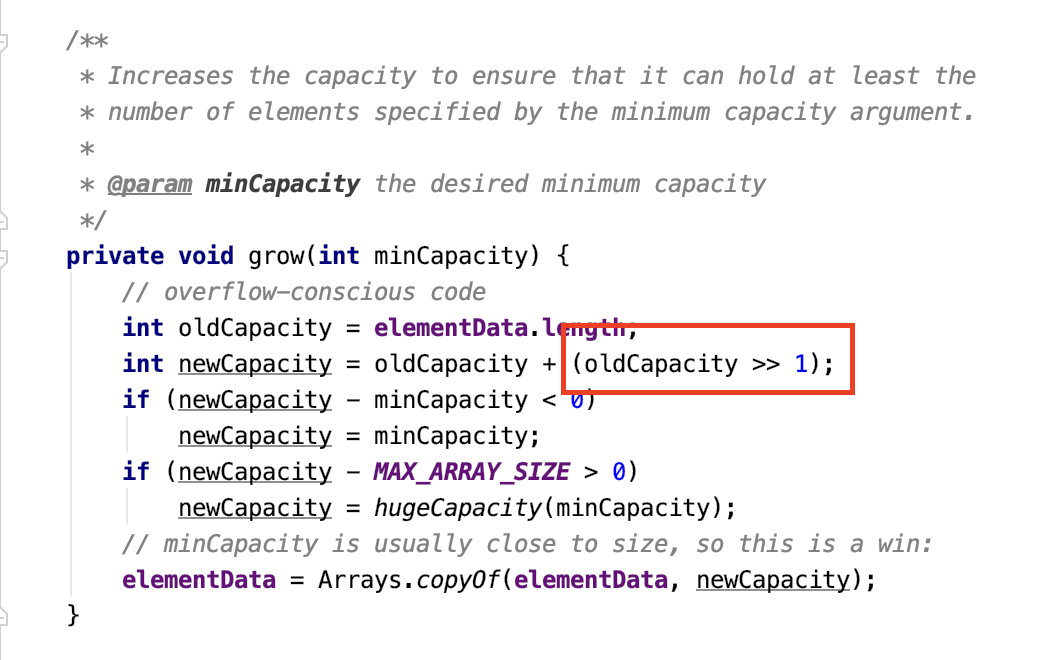
這是 ArrayList 的擴容實現,這個算術右移操作是把這個數的二進位往右移動一位,最左邊補符號位,但是因為容量沒有負數,所以還是補 0.
那右移一位的效果就是除以 2,那麼定義的新容量就是原容量的 1.5 倍。
不了解這個右移操作符的小夥伴,公眾號內回復「二進位」快複習一下吧~
再來看 Vector 的:

因為通常 capacityIncrement 我們並不定義,所以默認情況下它是擴容兩倍。
答出來這兩點,就肯定沒問題了。
Queue & Deque
Queue 是一端進另一端出的線性數據結構;而 Deque 是兩端都可以進出的。
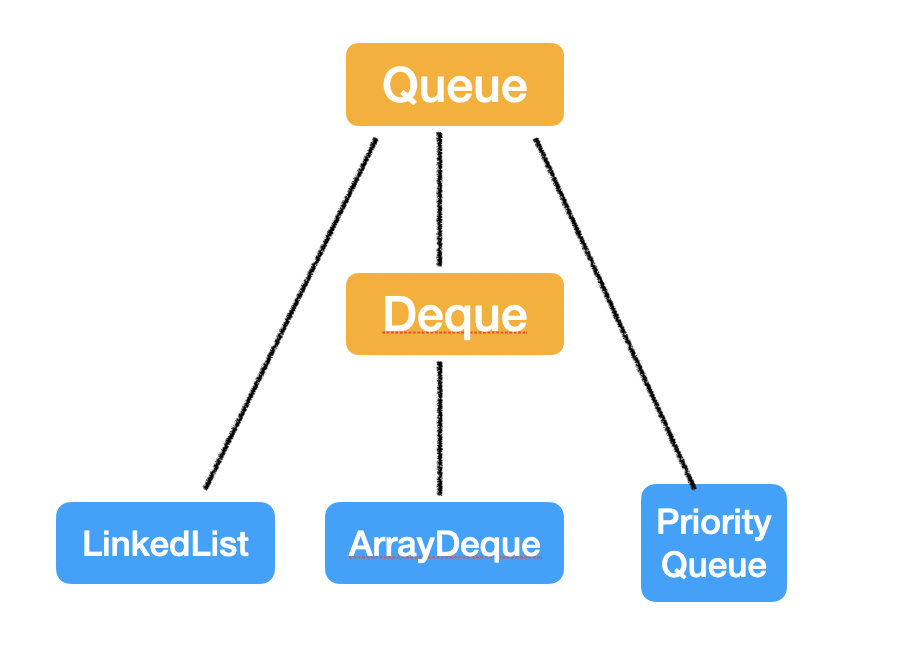
Queue
Java 中的 這個 Queue 介面稍微有點坑,一般來說隊列的語義都是先進先出(FIFO)的。
但是這裡有個例外,就是 PriorityQueue,也叫 heap,並不按照進去的時間順序出來,而是按照規定的優先順序出去,並且它的操作並不是 O(1) 的,時間複雜度的計算稍微有點複雜,我們之後單獨開一篇來講。
那 Queue 的方法官網都總結好了,它有兩組 API,基本功能是一樣的,但是呢:
- 一組是會拋異常的;
- 另一組會返回一個特殊值。
| 功能 | 拋異常 | 返回值 |
|---|---|---|
| 增 | add(e) | offer(e) |
| 刪 | remove() | poll() |
| 瞧 | element() | peek() |
為什麼會拋異常呢?
- 比如隊列空了,那 remove() 就會拋異常,但是 poll() 就返回 null;element() 就會拋異常,而 peek() 就返回 null 就好了。
那 add(e) 怎麼會拋異常呢?
有些 Queue 它會有容量的限制,比如 BlockingQueue,那如果已經達到了它最大的容量且不會擴容的,就會拋異常;但如果 offer(e),就會 return false.
那怎麼選擇呢?:
-
首先,要用就用同一組 API,前後要統一;
-
其次,根據需求。如果你需要它拋異常,那就是用拋異常的;不過做演算法題時基本不用,所以選那組返回特殊值的就好了。
Deque
Deque 是兩端都可以進出的,那自然是有針對 First 端的操作和對 Last 端的操作,那每端都有兩組,一組拋異常,一組返回特殊值:
| 功能 | 拋異常 | 返回值 |
|---|---|---|
| 增 | addFirst(e)/ addLast(e) | offerFirst(e)/ offerLast(e) |
| 刪 | removeFirst()/ removeLast() | pollFirst()/ pollLast() |
| 瞧 | getFirst()/ getLast() | peekFirst()/ peekLast() |
使用時同理,要用就用同一組。
Queue 和 Deque 的這些 API 都是 O(1) 的時間複雜度,準確來說是均攤時間複雜度。
實現類
它們的實現類有這三個:

所以說,
- 如果想實現「普通隊列 – 先進先出」的語義,就使用 LinkedList 或者 ArrayDeque 來實現;
- 如果想實現「優先隊列」的語義,就使用 PriorityQueue;
- 如果想實現「棧」的語義,就使用 ArrayDeque。
我們一個個來看。
在實現普通隊列時,如何選擇用 LinkedList 還是 ArrayDeque 呢?
來看一下 StackOverflow 上的高票回答:

總結來說就是推薦使用 ArrayDeque,因為效率高,而 LinkedList 還會有其他的額外開銷(overhead)。
那 ArrayDeque 和 LinkedList 的區別有哪些呢?

還是在剛才的同一個問題下,這是我認為總結的最好的:
- ArrayDeque 是一個可擴容的數組,LinkedList 是鏈表結構;
- ArrayDeque 里不可以存 null 值,但是 LinkedList 可以;
- ArrayDeque 在操作頭尾端的增刪操作時更高效,但是 LinkedList 只有在當要移除中間某個元素且已經找到了這個元素後的移除才是 O(1) 的;
- ArrayDeque 在記憶體使用方面更高效。
所以,只要不是必須要存 null 值,就選擇 ArrayDeque 吧!
那如果是一個很資深的面試官問你,什麼情況下你要選擇用 LinkedList 呢?
- 答:Java 6 以前。。。因為 ArrayDeque 在 Java 6 之後才有的。。
為了版本兼容的問題,實際工作中我們不得不做一些妥協。。
那最後一個問題,就是關於 Stack 了。
Stack
Stack 在語義上是 先進先出(LIFO) 的線性數據結構。
有很多高頻面試題都是要用到棧的,比如接水問題,雖然最優解是用雙指針,但是用棧是最直觀的解法也是需要了解的,之後有機會再專門寫吧。
那在 Java 中是怎麼實現棧的呢?
雖然 Java 中有 Stack 這個類,但是呢,官方文檔都說不讓用了!

原因也很簡單,因為 Vector 已經過被棄用了,而 Stack 是繼承 Vector 的。
那麼想實現 Stack 的語義,就用 ArrayDeque 吧:
Deque<Integer> stack = new ArrayDeque<>();
Set
最後一個 Set,剛才已經說過了 Set 的特定是無序,不重複的。
就和數學裡學的「集合」的概念一致。
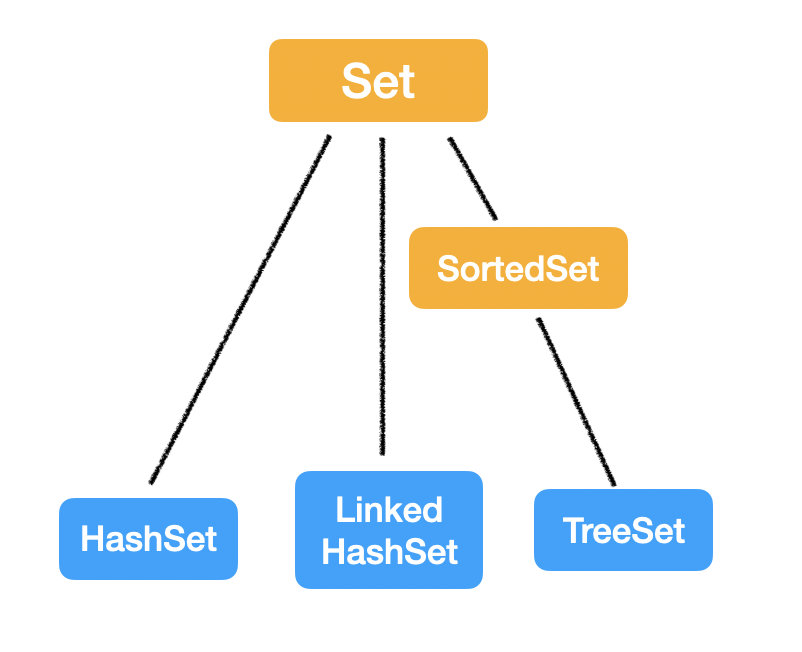
Set 的常用實現類有三個:
HashSet: 採用 Hashmap 的 key 來儲存元素,主要特點是無序的,基本操作都是 O(1) 的時間複雜度,很快。
LinkedHashSet: 這個是一個 HashSet + LinkedList 的結構,特點就是既擁有了 O(1) 的時間複雜度,又能夠保留插入的順序。
TreeSet: 採用紅黑樹結構,特點是可以有序,可以用自然排序或者自定義比較器來排序;缺點就是查詢速度沒有 HashSet 快。
那每個 Set 的底層實現其實就是對應的 Map:
數值放在 map 中的 key 上,value 上放了個 PRESENT,是一個靜態的 Object,相當於 place holder,每個 key 都指向這個 object。
那麼具體的實現原理、增刪改查四種操作,以及哈希衝突、hashCode()/equals() 等問題都在 HashMap 那篇文章里講過了,這裡就不贅述了,沒有看過的小夥伴可以在公眾號後台回復「HashMap」獲取文章哦~
總結
再回到開篇的這張圖,有沒有清楚了一些呢?
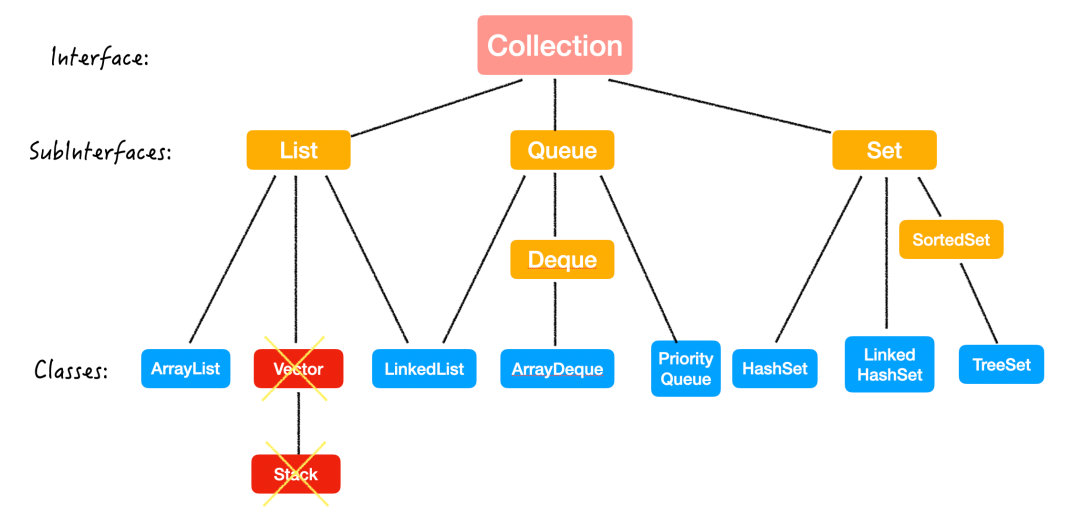
每個數據結構下面其實都有很多內容,比如 PriorityQueue 也就是堆,齊姐之前也專門寫過文章講解它的相關操作,比如很有名的 heapify() 的過程為什麼是 O(n) 的等面試常問題,感興趣的小夥伴在公眾號後台回復「堆」獲取文章吧~
如果你喜歡這篇文章,記得給我點贊留言哦~你們的支援和認可,就是我創作的最大動力,我們下篇文章見!
我是小齊,紐約程式媛,終生學習者,每天晚上 9 點,雲自習室里不見不散!
更多乾貨文章見我的 Github: //github.com/xiaoqi6666/NYCSDE

