正則表達式手冊(未完待續)
正則表達式手冊
//tool.oschina.net/uploads/apidocs/jquery/regexp.html
| 字元 | 描述 |
|---|---|
| \ | 將下一個字元標記為一個特殊字元、或一個原義字元。例如,「n」匹配字元「n」。「\n」匹配一個換行符。串列「\\」匹配「\」而「\(」則匹配「(」。 |
| ^ | 匹配輸入字元串的開始位置。例如:「^app」匹配字元串「apple」。 |
| $ | 匹配輸入字元串的結束位置。例如:「le$」匹配字元串「apple」。 |
| * | 匹配前一個字元零次或多次。例如,”zo*“能匹配「z」以及「zoo」。 |
| + | 匹配前一個字元一次或多次。例如,「zo+」能匹配「zo」以及「zoo」,但不能匹配「z」。 |
| ? | 匹配前一個字元零次或一次。例如,「do(es)?」可以匹配「does」或「does」中的「do」。 |
| {n} | n為個非負整數。匹配恰好n次。例如,「o{2}」不能匹配「Bob」中的「o」,但是能匹配「food」中的兩個o。 |
| {n,} | n是一個非負整數。至少匹配n次。例如,「o{2,}」不能匹配「Bob」中的「o」,但能匹配「foooood」中的所有o。「o{1,}」等價於「o+」。「o{0,}」則等價於「o*」。 |
| {n,m} | m和n均為非負整數,其中n<=m。最少匹配n次且最多匹配m次。例如,「o{1,3}」將匹配「fooooood」中的前三個o。「o{0,1}」等價於「o?」。請注意在逗號和兩個數之間不能有空格。 |
| ? | 當該字元緊跟在任何一個其他限制符(,+,?,{n},{n,},{n,m*})後面時,匹配模式是非貪婪的。非貪婪模式儘可能少的匹配所搜索的字元串,而默認的貪婪模式則儘可能多的匹配所搜索的字元串。例如,對於字元串「oooo」,「o+?」將匹配單個「o」,而「o+」將匹配所有「o」。 |
| . | 匹配除「\n」之外的任何單個字元。要匹配包括「\n」在內的任何字元,請使用像「(.|\n)」的模式。 |
| (pattern) | 匹配pattern並獲取這一匹配。所獲取的匹配可以從產生的Matches集合得到,在VBScript中使用SubMatches集合,在JScript中則使用$0…$9屬性。要匹配圓括弧字元”(“和”)“,請使用「\(」或「\)」。 |
| (?:pattern) | 匹配pattern但不獲取匹配結果,也就是說這是一個非獲取匹配,不進行存儲供以後使用。這在使用或字元「(|)」來組合一個模式的各個部分是很有用。例如「industr(?:y|ies)」就是一個比「industry|industries」更簡略的表達式 |
| (?=pattern) | 正向肯定預查,在任何匹配pattern的字元串開始處匹配查找字元串。這是一個非獲取匹配,也就是說,該匹配不需要獲取供以後使用。例如,「Windows(?=95|98|NT|2000)」能匹配「Windows2000」中的「Windows」,但不能匹配「Windows3.1」中的「Windows」。預查不消耗字元,也就是說,在一個匹配發生後,在最後一次匹配之後立即開始下一次匹配的搜索,而不是從包含預查的字元之後開始。 |
| (?!pattern) | 正向否定預查,在任何不匹配pattern的字元串開始處匹配查找字元串。這是一個非獲取匹配,也就是說,該匹配不需要獲取供以後使用。例如「Windows(?!95|98|NT|2000)」能匹配「Windows3.1」中的「Windows」,但不能匹配「Windows2000」中的「Windows」。預查不消耗字元,也就是說,在一個匹配發生後,在最後一次匹配之後立即開始下一次匹配的搜索,而不是從包含預查的字元之後開始 |
| (?<=pattern) | 反向肯定預查,與正向肯定預查類擬,只是方向相反。例如,「(?<=95|98|NT|2000)Windows」能匹配「2000Windows」中的「Windows」,但不能匹配「3.1Windows」中的「Windows」。 |
| (?<!pattern) | 反向否定預查,與正向否定預查類擬,只是方向相反。例如「(?<!95|98|NT|2000)Windows」能匹配「3.1Windows」中的「Windows」,但不能匹配「2000Windows」中的「Windows」。 |
| x|y | 匹配x或y。例如,「z|food」能匹配「z」或「food」。「(z|f)ood」則匹配「zood」或「food」。 |
| [xyz] | 字符集合。匹配所包含的任意一個字元。例如,「[abc]」可以匹配「plain」中的「a」。 |
| [^xyz] | 一個否定的字符集。匹配未包含的任意字元。例如,「[^abc]」可以匹配「plain」中的「p」。 |
| [a-z] | 字元範圍。匹配指定範圍內的任意字元。例如,「[a-z]」可以匹配「a」到「z」範圍內的任意小寫字母字元。 |
| [^a-z] | 一個否定的字元範圍。匹配任何不在指定範圍內的任意字元。例如,「[^a-z]」可以匹配任何不在「a」到「z」範圍內的任意字元。 |
| \b | 與單詞的邊界匹配,即單詞和空格間的位置。例如,「er\b」可以匹配「never」中的「er」,但不能匹配「verb」中的「er」。 |
| \B | 匹配非單詞邊界。「er\B」能匹配「verb」中的「er」,但不能匹配「never」中的「er」。 |
| \cx | 匹配由x指明的控制字元。例如,\cM匹配一個Control-M或回車符。x的值必須為A-Z或a-z之一。否則,將c視為一個原義的「c」字元。 |
| \d | 匹配一個數字字元。等價於[0-9]。 |
| \D | 匹配一個非數字字元。等價於[^0-9]。 |
| \f | 匹配一個換頁符。等價於\x0c和\cL。 |
| \n | 匹配一個換行符。等價於\x0a和\cJ。 |
| \r | 匹配一個回車符。等價於\x0d和\cM。 |
| \s | 匹配任何空白字元,包括空格、製表符、換頁符等等。等價於[ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字元。等價於[^ \f\n\r\t\v]。 |
| \t | 匹配一個製表符。等價於\x09和\cI。 |
| \v | 匹配一個垂直製表符。等價於\x0b和\cK。 |
| \w | 匹配包括下劃線的任何單詞字元。等價於「[A-Za-z0-9_]」。 |
| \W | 匹配任何非單詞字元。等價於「[^A-Za-z0-9_]」。 |
| \xn | 匹配n,其中n為十六進位轉義值。十六進位轉義值必須為確定的兩個數字長。例如,「\x41」匹配「A」。「\x041」則等價於「\x04&1」。正則表達式中可以使用ASCII編碼。 |
| *num* | 匹配num,其中num是一個正整數。對所獲取的匹配的引用。例如,「(.)\1」匹配兩個連續的相同字元。 |
| *n* | 標識一個八進位轉義值或一個向後引用。如果*n之前至少n個獲取的子表達式,則n為向後引用。否則,如果n為八進位數字(0-7),則n*為一個八進位轉義值。 |
| *nm* | 標識一個八進位轉義值或一個向後引用。如果*nm之前至少有nm個獲得子表達式,則nm為向後引用。如果*nm之前至少有n個獲取,則n為一個後跟文字m的向後引用。如果前面的條件都不滿足,若n和m均為八進位數字(0-7),則*nm將匹配八進位轉義值nm*。 |
| *nml* | 如果n為八進位數字(0-3),且m和l均為八進位數字(0-7),則匹配八進位轉義值nml。 |
| \un | 匹配n,其中n是一個用四個十六進位數字表示的Unicode字元。例如,\u00A9匹配版權符號(©)。 |
常用正則表達式
| 用戶名 | /[1]{3,16}$/ |
|---|---|
| 密碼 | /[2]{6,18}$/ |
| 十六進位值 | /^#?([a-f0-9]{6}|[a-f0-9]{3})$/ |
| 電子郵箱 | /^([a-z0-9_.-]+)@([\da-z.-]+).([a-z.]{2,6})$/ /[3]+(.[a-z\d]+)*@(\da-z?)+(.{1,2}[a-z]+)+$/ |
| URL | /^(https?😕/)?([\da-z.-]+).([a-z.]{2,6})([/\w .-])/?$/ |
| IP 地址 | /((2[0-4]\d|25[0-5]|[01]?\d\d?).){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)/ /^(?😦?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/ |
| HTML 標籤 | /<([a-z]+)([<]+)(?:>(.)</\1>|\s+/>)$/ |
| 刪除程式碼\注釋 | (?<!http:|\S)//.*$ |
| Unicode編碼中的漢字範圍 | /[4]+$/ |
實例1:
從字元串 str 中提取數字部分的內容(匹配一次):
var str = "abc123def";
var patt1 = /[0-9]+/;
document.write(str.match(patt1));
以下標記的文本是獲得的匹配的表達式:
123
實例2:
使用 ? 和 ***** 通配符來查找硬碟上的文件。? 通配符匹配文件名中的 0 個或 1 個字元,而 ***** 通配符匹配0個或多個字元。\w 匹配包括下劃線的任何單個字元。等價於「[A-Za-z0-9_]」。
data(\w)?.dat 將查找下列文件:
data.dat
data1.dat
data2.dat
datax.dat
dataN.dat
使用 ***** 字元代替 ? 字元擴大了找到的文件的數量。data.*.dat 匹配下列所有文件:
data.dat
data1.dat
data2.dat
data12.dat
datax.dat
dataXYZ.dat
一個簡單的示例:
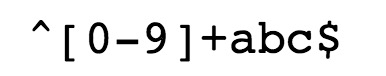
- ^ 為匹配輸入字元串的開始位置。
- [0-9]+匹配多個數字, [0-9] 匹配單個數字,+ 匹配一個或者多個。
- abc$匹配字母 abc 並以 abc 結尾,$ 為匹配輸入字元串的結束位置。
我們在寫用戶註冊表單時,只允許用戶名包含字元、數字、下劃線和連接字元(-),並設置用戶名的長度,我們就可以使用以下正則表達式來設定。
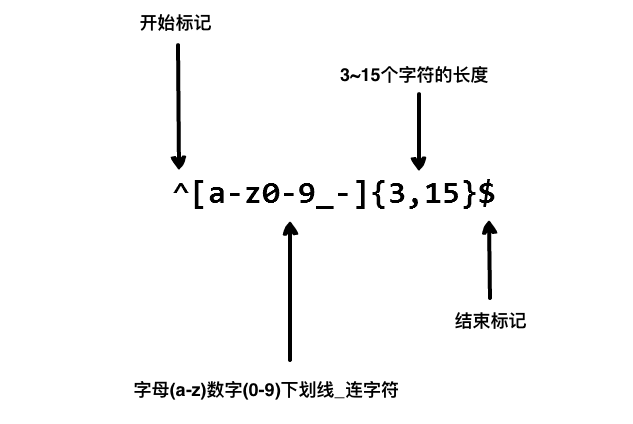
限定符
限定符用來指定正則表達式的一個給定組件必須要出現多少次才能滿足匹配。有 ***** 或 + 或 ? 或 {n} 或 {n,} 或 {n,m} 共6種。
正則表達式的限定符有:
| 字元 | 描述 |
|---|---|
| * | 匹配前面的子表達式零次或多次。例如,zo* 能匹配 “z” 以及 “zoo”。* 等價於{0,}。 |
| + | 匹配前面的子表達式一次或多次。例如,’zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等價於 {1,}。 |
| ? | 匹配前面的子表達式零次或一次。例如,”do(es)?” 可以匹配 “do” 、 “does” 中的 “does” 、 “doxy” 中的 “do” 。? 等價於 {0,1}。 |
| {n} | n 是一個非負整數。匹配確定的 n 次。例如,’o{2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的兩個 o。 |
| {n,} | n 是一個非負整數。至少匹配n 次。例如,’o{2,}’ 不能匹配 “Bob” 中的 ‘o’,但能匹配 “foooood” 中的所有 o。’o{1,}’ 等價於 ‘o+’。’o{0,}’ 則等價於 ‘o*’。 |
| {n,m} | m 和 n 均為非負整數,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,”o{1,3}” 將匹配 “fooooood” 中的前三個 o。’o{0,1}’ 等價於 ‘o?’。請注意在逗號和兩個數之間不能有空格。 |
以下正則表達式匹配一個正整數,[1-9]設置第一個數字不是 0,[0-9]* 表示任意多個數字:
/[1-9][0-9]*/
限定符出現在範圍表達式之後,因此,它應用於整個範圍表達式。
1、這裡不使用+限定符,這裡在第二個位置或後面的位置不一定需要有一個數字,0個數字也可。
2、不使用?字元,因為使用?會將整數限制到只有兩位字元。
如果你想設置 0~99 的兩位數,可以使用下面的表達式來至少指定一位但至多兩位數字。
/[0-9]{1,2}/
上面的表達式的缺點是,只能匹配兩位數字,而且可以匹配 0、00、01、10 99 的章節編號仍只匹配開頭兩位數字。改進下,匹配 1~99 的正整數表達式如下:
/[1-9][0-9]?/
或
/[1-9][0-9]{0,1}/
* 和 +限定符都是貪婪的,因為它們會儘可能多的匹配文字,只有在它們的後面加上一個 ? 就可以實現非貪婪或最小匹配。
例如,搜索 HTML 文檔,以查找在 h1 標籤內的內容。HTML 程式碼如下:
<h1>hello world!</h1>
貪婪:下面的表達式匹配從開始小於符號 (<) 到關閉 h1 標記的大於符號 (>) 之間的所有內容。
/<.*>/

非貪婪:如果你只需要匹配開始和結束 h1 標籤,下面的非貪婪表達式只匹配 <h1>。
/<.*?>/

也可以使用以下正則表達式來匹配 h1 標籤,表達式則是:
/<\w+?>/

通過在 *、+ 或 ? 限定符之後放置 ?,該表達式從”貪婪”表達式轉換為”非貪婪”表達式或者最小匹配。