如何實現文章AI偽原創?
- 2020 年 10 月 13 日
- 筆記
language-ai
文章AI偽原創,文章自動生成,NLP,自然語言技術處理,DNN語言模型,詞義相似度分析。全網首個AI偽原創開源應用類項目。
點擊右側about內的鏈接極速體驗!
程式碼託管在github,需要的可以自取://github.com/LovebuildJ/language-ai
快速開始
- 環境準備:
JDK1.8,maven3.6+,redis - 在
application.yml中配置百度AI的相關資訊
baidu:
appid: 你的app_id
appkey: 你的app_key
secret: 你的app_secret
如何獲取? 輸入//ai.baidu.com/tech/nlp_basic, 點擊立即使用, 根據提示一步一步完成即可獲得。
有免費調用額度, 對於個人而言已經夠了。
3.啟動項目, 前端頁面訪問 //localhost:8080/ai,swagger文檔訪問//localhost:8080/ai/doc.html
- 載入詞庫到redis中, 項目啟動後, 發送post請求
//localhost:8080/ai/command/initRedis初始化redis即可。該操作會將庫清空再初始化,請悉知
請求參數格式如下:
{
"appName": "",
"params": {
"password": "你的用戶名",
"username": "你的密碼"
},
"sign": "",
"timestamp": "",
"version": ""
}
也可直接使用swagger執行介面初始化
測試版本未作校驗, 所有參數默認為空即可。
項目截圖
【詞義分析】

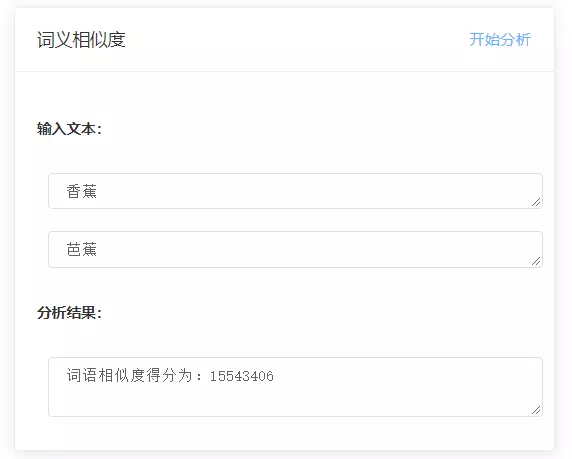
【詞義相似度計算】
【DNN語言模型計算】

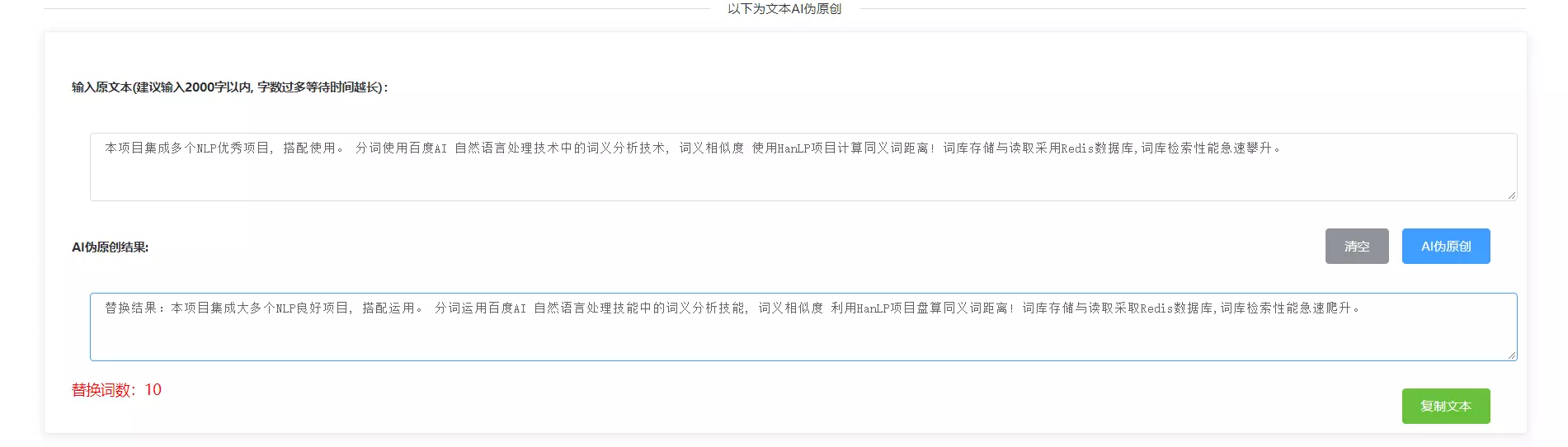
【AI偽原創】
【BootstrapSwaggerUI在線文檔】
【首頁】

源碼目錄詳解
language-ai
|- src/main
| |- java java源碼所在目錄
| |- com.chenxin
| |- auth 百度AI授權認證模組
| |- base 基礎公共抽象模組
| |- config 項目所有自定義配置模組
| |- controller 這個不用多說
| |- exception 全局異常與自定義一次模組
| |- model 項目所有使用的數據模型, dto,vo,bo等
| |- service 業務模組
| |- util 工具模組
| |- auth 授權認證模組
| |- consts 常量類
| |- http http相關
| |- nlp NLP同義詞庫載入工具
| |- system 系統相關
| |- CommonEnum.java 統一資訊處理枚舉類
|
| |- AiApplication.java 主啟動類
|
|- src/test/java
|- com.chenxin 相關測試程式碼, 經驗證, 若idea版本太低將會導致該單元測試無法使用
其他自行查看源碼, 不一一概述
關於詞庫
- 使用到的中文同義詞詞庫是哈工大的同義詞詞林(擴展版)
- 下載地址://www.ltp-cloud.com/download#down_cilin
- 項目自帶詞庫(csdn下載的)
拓展詞庫
想要更加精確的計算與替換, 就需要一個很精準龐大的詞庫, 這個詞庫大家可以自己慢慢的補充完整
只需要將詞庫添加進文件resource/res/word.txt, 按照格式進行添加即可, 然後調用初始化redis介面即可。
初始化redis介面/ai/command/initRedis
關於詞庫中詞語重複問題
這個大家無需擔心, 作者在此方面做了大量優化。 相同鍵值Key的片語,將會全部存儲至redis中,以Key0,Key1的形式存儲,
查詢時, 會將所有相同Key的片語全部找出, 並進行去重, 然後在進行其他操作, 計算詞義相似度等等。相同的Key,為了提升
查詢效率, 默認取相同Key的前20組!
技術圖譜
本項目集成多個NLP優秀項目, 搭配使用。 分詞使用百度AI 自然語言處理技術中的詞義分析技術, 詞義相似度
使用HanLP項目計算同義詞距離!
自然語言處理技術(百度AI提供技術支援)
- 詞義分析技術
- 詞向量表示
- 詞義相似度
- DNN語言模型
- 依存句法分析
- 短文本相似度
自然語言處理(hanLP提供技術支援)
HanLP是一系列模型與演算法組成的NLP工具包,目標是普及自然語言處理在生產環境中的應用。
同義詞詞庫
- 哈工大的同義詞詞林(擴展版)
技術架構
後端
- SpringBoot, 簡單配置, 快速開發
- MyBatis , 複雜數據操作(輕量級版本無需資料庫, 提高靈活性)
- Spring Data Jpa , 簡單數據操作(輕量級版本無需資料庫, 提高靈活性)
- SwaggerUI BootstrapSwaggerUI, 在線介面文檔, 增強美化, 介面文檔導出
- Redis 數據存儲與快取
- Async 非同步多執行緒, 提升文章切割替換速度(單核cpu可能效果不太明顯)
前端
本項目的頁面只是簡單作為測試, 後續會打造一個完整的產品網站。
- Vue
- ElementUI
問題與優化
- Q: 當文本長度稍微大一點的時候,文本變臉就變得十分緩慢, 因為這涉及到將幾萬的詞庫載入到記憶體然後進行詞義距離計算
- A:這時候載入詞庫比對的思路,明顯已經不適用了。因此採用高性能的redis資料庫,進行詞庫的存儲與讀取,極大的提升了同義詞的查找效率
- 優點 同義詞精確匹配, 替換性能提升十幾倍
- Q:只能有一組同義詞, 例如 安分守己 – 循規蹈矩 和 循規蹈矩 – 安分守己。那 安分守己 – 誠實本分就添加不進詞庫。 初版先犧牲詞庫豐富性而達到高性能
- A: 現在已優化, 自動給同名鍵增加後綴, 後使用redis模糊查詢進行匹配 (真正的性能和效率並存)
- Q:當文本過長,百度AI介面會拋出異常
- A:用戶端或者服務端做好文本切片的操作
- Q: 當用戶直接輸入文章, 幾千字如何處理?
- A: 根據文本大小進行切片, 採用非同步多執行緒處理, 提升程式性能
- Q: 直接粘貼文章進行AI偽原創可能會報json注入異常
- A: 建議去掉空格, 回車等。或者換成轉義字元。
關於作者
熱衷於ai,分散式微服務,web應用,大數據等領域。工作室:1024程式碼工作室,有需求的可以聯繫作者哦,交流也是可以滴。
郵箱:[email protected]
其他
為什麼會使用多個NLP項目, 原因是因為最初是想使用百度AI將整個項目完成。 但由於百度自然語言處理API
對於普通用戶調用有次數限制, 超量需要收費, 因此數據量比較大的處理將給了HanLP項目處理。將數據量較小
的分詞交給百度AI處理。
- 關於同義詞庫文件的位置, 不建議移動和改變, 文件夾以及名字都是。後續有時間, 再優化這個問題吧。
