NLP硬核入門-條件隨機場CRF
- 2019 年 11 月 11 日
- 筆記
本文需要的前序知識儲備是:隱馬爾科夫模型HMM。
實際上HMM和CRF的學習沒有先後順序。但是兩者很相似,在學習了HMM後更容易上手CRF,所以建議先學習HMM後學習CRF。
1 CRF概述
1.1隨機場的定義
在這一小節,我們將會由泛化到特例,依次介紹隨機場、馬爾科夫隨機場、條件隨機場、線性鏈條件隨機場的概念。
(1)隨機場是一個圖模型,是由若干個結點(隨機變數)和邊(依賴關係)組成的圖模型,當給每一個結點按照某種分布隨機賦予一個值之後,其全體就叫做隨機場。
(2)馬爾科夫隨機場是隨機場的特例,它假設隨機場中任意一個結點的賦值,僅僅和它的鄰結點的取值有關,和不相鄰的結點的取值無關。用學術語言表示是:滿足成對、局部或全局馬爾科夫性。
(3)條件隨機場CRF是馬爾科夫隨機場的特例,它假設模型中只有X(輸入變數,觀測值)和Y(輸出變數,狀態值)兩種變數。輸出變數Y構成馬爾可夫隨機場,輸入變數X不具有馬爾科夫性。
(4)線性鏈條件隨機場,是狀態序列是線性鏈的條件隨機場。
注1:馬爾科夫性:隨機過程中某事件的發生只取決於它的上一事件,是「無記憶」過程。
我們的應用領域是NLP,所以本文只針對線性鏈條件隨機場進行討論。
線性鏈條件隨機場有以下性質:
(1)對於狀態序列y,y的值只與相鄰的y有關係,體現馬爾科夫性。
(2)任意位置的y與所有位置的x都有關係。
(3)我們研究的線性鏈條件隨機場,假設狀態序列Y和觀測序列X有相同的結構,但是實際上後文公式的推導,對於狀態序列Y和觀測序列X結構不同的條件隨機場也適用。
(4)觀測序列X是作為一個整體,去影響狀態序列Y的值,而不是隻影響相同或鄰近位置(時刻)的Y。
(5)線性鏈條件隨機場的示意圖如下:

注二:李航老師的《統計學習方法》里,使用了兩種示意圖來描述線性鏈條件隨機場,一種是上文所呈現的,這張圖更能夠體現性質(4),另一種如下圖,關注點是X和Y同結構:

1.2CRF的應用
線性鏈條件隨機場CRF是在給定一組隨機變數X(觀測值)的條件下,獲取另一組隨機變數Y(狀態值)的條件概率分布模型。在NLP領域,線性鏈條件隨機場被廣泛用於標註任務(NER、分詞等)。
1.3 構建CRF的思路(重要)
我們先給出構建CRF模型的核心思路,現在暫不需要讀懂這些思路的本質思想,但是我們要帶著這些思路去閱讀後續的內容。
(1)CRF是判別模型,是黑箱模型,不關心概率分布情況,只關心輸出結果。
(2)CRF最重要的工作,是提取特徵,構建特徵函數。
(3)CRF使用特徵函數給不同的標註網路打分,根據分數選出可能性最高的標註網路。
(4)CRF模型的計算過程,使用的是以e為底的指數。這個建模思路和深度學習輸出層的softmax是一致的。先計算各個可能情況的分數,再進行softmax歸一化操作。
2 CRF模型的概率計算
(對數學公式推導沒興趣的童鞋,只需要看2.1和2.2)
2.1 標記符號和參數
先約定一下CRF的標記符號:
觀測值序列:

狀態值序列:

轉移(共現)特徵函數及其權重:

狀態(發射)特徵函數及其權重:

簡化後的特徵函數及其權重:

特徵函數t的下標:k1
特徵函數s的下標:k2
簡化後的特徵函數f的下標:k
2.2 一個栗子
在進行公式推導前,我們先通過一個直觀的例子,初步了解下CRF。
例:輸入觀測序列為X=(x1,x2,x3),輸出狀態序列為Y=(y1,y2,y3),狀態值集合為{1,2}。在已知觀測序列後,得到的特徵函數如下。求狀態序列為Y=(y1,y2,y3)=(1,2,2)的非規範化條件概率。

解:參照狀態序列取值和特徵函數定義,可得特徵函數t1,t5,s1,s2,s4取值為1,其餘特徵函數取值為0。乘上權重後,可得狀態序列(1,2,2)的非規範化條件概率為:1+0.2+1+0.5+0.5=3.2
2.3特徵函數
在這一小節,我們描述下特徵函數,以及它的簡化形式和矩陣形式。
(1)線性鏈條件隨機場的原始參數化形式
分數:

歸一化概率:

其中,歸一項為:

t為定義在邊上的特徵函數,通常取值0或1,依賴於兩個相鄰結點的狀態,λ為其權重。t有時被稱為轉移特徵,其實稱為共現特徵更合適些。因為圖模型更強調位置關係而不是時序關係。
s為定義在節點上的特徵函數,通常取值0或1,依賴於單個結點的狀態,μ為其權重。s有時被稱為狀態特徵。
需要強調的是:CRF模型中涉及的條件概率,不是真實的概率,而是通過分值softmax歸一化成的概率。
(2)線性鏈條件隨機場的簡化形式
特徵函數:

權重:

對特徵函數在各個位置求和,將局部特徵函數轉化為全局特徵函數:

歸一化概率:

向量化:

(3)線性鏈條件隨機場的矩陣形式
構建矩陣Mi(x)。位置i和觀測值序列x是矩陣的自變數。
矩陣的維度是m*m,m為狀態值y的集合的元素個數,矩陣的行表示的是位置i-1的狀態,矩陣的列表示的是位置i的狀態,矩陣各個位置的值表示位置i-1狀態和位置i狀態的共現分數,並以e為底取指數。

2.4 前向後向演算法
(1)前向演算法模型
(a)αi(yi=s|x)表示狀態序列y在位置i取值s,在位置1~i取值為任意值的可能性分數的非規範化概率。
定義:

(b)遞歸公式:

(c)人為定義:

(d)歸一項:

(2)後向演算法模型
(a)βi(yi=s|x)表示狀態序列y在位置i取值s,在位置i+1~n取值為任意值的可能性分數的非規範化概率。
定義:

(b)遞歸公式:

(c)人為定義:

(d)歸一化項:

註:在前向演算法和後向演算法中,人為地定義了α(0)和β(n+1),採用的是李航老師書里的定義方法。但是,我認為採用先驗概率(類似HMM中的初始概率分布)或者全部定義成1更合適。因為這裡的概率模型應該表現得更通用一點,而不要引入實際預測序列的第一項和最後一項的資訊。
2.5 一些概率和期望的計算
(1)兩個常用的概率公式
狀態序列y,位置i的取值為特定值,其餘位置為任意值的可能性分數的歸一化條件概率:

狀態序列y,位置i-1,i的取值為特定值,其餘位置為任意值的可能性分數的歸一化條件概率:

(1)兩個常用的期望公式
特徵函數f關於條件分布P(Y|X)的數學期望:

特徵函數f關於聯合分布P(X,Y)的數學期望:

3 CRF模型的訓練和預測
3.1學習訓練問題
CRF模型採用正則化的極大似然估計最大化概率。
採用的最優化演算法可以是:迭代尺度法IIS,梯度下降法,擬牛頓法。
相應的知識可以通過最優化方法的資料進行學習,本文篇幅有限,就不作展開了。
3.2預測解碼問題
和HMM完全一樣,採用維特比演算法進行預測解碼,這裡不作展開。
4 CRF的優缺點(重要)
4.1CRF相對於HMM的優點
(1)規避了馬爾科夫性(有限歷史性),能夠獲取長文本的遠距離依賴的資訊。
(2)規避了齊次性,模型能夠獲取序列的位置資訊,並且序列的位置資訊會影響預測出的狀態序列。
(3)規避了觀測獨立性,觀測值之間的相關性資訊能夠被提取。
(4)不是單向圖,而是無向圖,能夠充分提取上下文資訊作為特徵。
(5)改善了標記偏置LabelBias問題,因為CRF相對於HMM能夠更多地獲取序列的全局概率資訊。
(6)CRF的思路是利用多個特徵,對狀態序列進行預測。HMM的表現形式使他無法使用多個複雜特徵。
4.2條件隨機場CRF的缺點
(1)CRF訓練代價大、複雜度高。
(2)每個特徵的權重固定,特徵函數只有0和1兩個取值。
(3)模型過於複雜,在海量數據的情況下,業界多用神經網路。
(4)需要人為構造特徵函數,特徵工程對CRF模型的影響很大。
(5)轉移特徵函數的自變數只涉及兩個相鄰位置,而CRF定義中的馬爾科夫性,應該涉及三個相鄰位置。
4.3標記偏置LabelBias
在HMM中的體現:對於某一時刻的任一狀態,當它向後一時進行狀態刻轉移時,會對轉移到的所有狀態的概率做歸一化,這是一種局部的歸一化。即使某個轉移概率特別高,其轉移概率也不超過1。即使某個轉移概率特別低,如果其它幾個轉移概率同樣低,那麼歸一化後的轉移概率也不會接近0。
在CRF被規避的原因:CRF使用了全局的歸一化。在進行歸一化之前,使用分數來標記狀態路徑的可能性大小。待所有路徑所有位置的分數都計算完成後,再進行歸一化。某些某個狀態轉移的子路徑有很高的分數,會對整條路徑的概率產生很大的影響。
5 基於TensorFlow的BiLSTM-CRF
BiLSTM-CRF是當前用得比較廣泛的序列標註模型。
BiLSTM-CRF模型由BiLSTM和CRF兩個部分組成。
BiLSTM使用的是分類任務的配置,最終輸出一個標註好的序列。也就是說,即使沒有CRF,BiLSTM也能獨立完成標註任務。
CRF接收BiLSTM輸出的標註序列,進行計算,最後輸出修正後的標註序列。
TensorFlow提供了CRF的開發包,路徑為:tf.contrib.crf。需要強調的是,TensorFlow的CRF,提供的是一個嚴重簡化後的CRF,和原始CRF差異較大。雖然減小了模型複雜度,但是在準確率上也一定會有所損失。
下面簡要介紹下TensorFlow中CRF模組的幾個關鍵函數。
(1)crf_log_likelihood
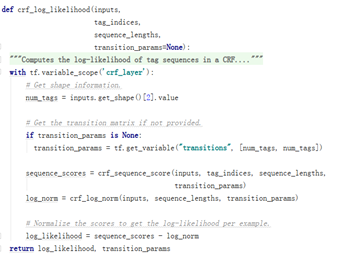
BiLSTM模組輸出的序列,通過參數inputs輸入CRF模組。
CRF模組通過crf_sequence_score計算狀態序列可能性分數,通過crf_log_norm計算歸一化項。
最後返回log_likelihood對數似然。
(2)crf_sequence_score

crf_sequence_score通過crf_unary_score計算狀態特徵分數,通過crf_binary_score計算共現特徵分數。
(3)crf_unary_score

crf_unary_score利用掩碼的方式,計算得出一個類似交叉熵的值。
(4)crf_binary_score

crf_binary_score構造了一個共現矩陣transition_params,表示不同狀態共現的概率,這個矩陣是可訓練的。最後通過共現矩陣返回共現特徵分數。
(5)crf_log_norm

歸一化項。
知乎文章地址:
https://zhuanlan.zhihu.com/p/87638630
由於微信公眾號文章有修改字數的限制,故本文後續的糾錯和更新將呈現在知乎的同名文章里。
參考文獻
[1] 李航 統計學習方法 清華大學出版社
[2] 條件隨機場CRF(一/二/三) 劉建平Pinard https://www.cnblogs.com/pinard/p/7048333.html
本文轉載自公眾號:數論遺珠,作者:阮智昊


