Hive數據倉庫你了解了嗎
- 2019 年 11 月 11 日
- 筆記
在工作中我們經常使用的資料庫,資料庫一般存放的我們系統中常用的數據,一般為百萬級別。如果數據量龐大,達到千萬級、億級又需要對他們進行關聯運算,該怎麼辦呢?
前面我們已經介紹了HDFS和MapReduce了,它倆結合起來能夠進行各種運算,可是MapReduce的學習成本太高了,如果有一種工具可以直接使用sql將hdfs中的數據查出來,並自動編寫mapreduce進行運算,這就需要使用到我們的hive數據倉庫。
Hive基本概念
什麼是Hive
Hive是基於Hadoop的一個數據倉庫工具,可以將結構化的數據文件映射為一張資料庫表,並提供類SQL查詢功能。為什麼使用Hive
- 直接使用hadoop所面臨的問題
人員學習成本太高
項目周期要求太短
MapReduce實現複雜查詢邏輯開發難度太大 - 為什麼要使用Hive
操作介面採用類SQL語句,提供快速開發的能力。
避免了去寫MapReduce,減少開發人員的學習成本。
擴展功能很方便
Hive的特點
- 可擴展
Hive可以自由的擴展集群的規模,一般情況下不需要重啟服務。 - 延展性
Hive支援用戶自定義函數,用戶可以根據自己的需求來實現自己的函數。注意:這裡說的函數可不是存儲過程噢。 - 容錯
良好的容錯行,節點出現問題SQL仍可以完成執行
基本組成
-
用戶介面:包括CLI、JDBC/ODBC、WebGUI -
元數據存儲:通常是存儲在關係資料庫如 mysql,derby中。 -
解釋器、編譯器、優化器、執行器
各組件的基本功能
- 用戶介面主要有三個:CLI、JDBC/ODBC和WebGUI。其中,CLI為shell命令行;JDBC/ODBC是Hive的JAVA實現,與傳統資料庫JDBC類似;WebGUI是通過瀏覽器訪問Hive
- 元數據存儲:Hive將元數據存儲在資料庫中。Hive中的元數據包括表的名字,表的列和分區及其屬性,是否為外部表,表的數據所在的目錄等等。
- 解釋器、編譯器、優化器完成HQL查詢語句從此法分析、語法分析、編譯、優化以及查詢計劃的生成。生成的查詢計劃存儲在HDFS中,並且隨後使用MapReduce執行。
Hive與Hadoop的關係
sequenceDiagram 客戶端->>Hive處理轉換成MapReduce: 發送HSQL語句 Hive處理轉換成MapReduce->>MapReduce運行: 提交任務到Hadoop MapReduce運行->>執行結果文件放到HDFS或本地: 執行結果Hive與傳統資料庫對比
| — | Hive | RDBMS |
|---|---|---|
| 查詢語言 | HQL | SQL |
| 數據存儲 | HDFS | Raw Device or Local FS |
| 執行 | MapReduce | Excutor |
| 執行延遲 | 高 | 低 |
| 處理數據規模 | 大 | 小 |
| 索引 | 0.8版本後加入點陣圖索引 | 有複雜的索引 |
==hive中具有sql資料庫,用來存儲元數據資訊(如:表的屬性,數據的位置)。hive只適合用來做批量數據統計分析。讀多寫少==
Hive的數據存儲
- Hive中所有的數據都存儲在HDFS中,沒有專門的數據存儲格式(可支援Text,SequenceFile,ParqueFile,RCFile等)
- 只需要在創建表的時候告訴Hive數據中的列分隔符和行分隔符。默認列分隔符為ascii碼的控制符�01,行分隔符為換行符。
- Hive中包含以下數據模型:DB、Table、External Table、Partition、Bucket。
-
db:在hdfs中表現為hive.metastore.warehouse.dir目錄下的一個文件夾 -
table:在hdfs中表現為所屬db目錄下的一個文件夾 -
external table:與table類似,不過其數據存放位置可以在任意指定路徑。刪除表時只會刪除元數據,不會刪除實際數據 -
partition:在hdfs中表現為table目錄下的子目錄 -
bucket: 在hdfs中表現為同一個表目錄下根據hash散列之後的多個文件
Hive的安裝部署
安裝
單機版(內置關係型資料庫derby) 元資料庫mysql版 這裡使用常用的mysql版,使用derby的話不太方便,因為derby會將文件保存在你當前啟動的目錄。如果下次你換個目錄啟動,會發現之前保存的數據不見了。元資料庫mysql版安裝
安裝mysql資料庫
mysql安裝僅供參考,不同版本mysql有各自的安裝流程。# 刪除原有的mysql rpm -qa | grep mysql rpm -e mysql-libs-5.1.66-2.el6_3.i686 --nodeps rpm -ivh MySQL-server-5.1.73-1.glibc23.i386.rpm rpm -ivh MySQL-client-5.1.73-1.glibc23.i386.rpm # 修改mysql的密碼,並記得設置允許用戶遠程連接 /usr/bin/mysql_secure_installation # 登錄mysql mysql -u root -p 配置hive
配置HIVE_HOME環境變數
vi conf/hive-env.sh #配置其中的$hadoop_home配置元資料庫資訊
vi hive-site.xml #添加如下內容 <configuration> <!--配置mysql的連接地址--> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value> <description>JDBC connect string for a JDBC metastore</description> </property> <!--配置mysql的驅動--> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <!--配置登錄用戶名--> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>username to use against metastore database</description> </property> <!--配置登錄密碼--> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>root</value> <description>password to use against metastore database</description> </property> </configuration>放驅動包
安裝hive和mysql完成後,將mysql的連接jar包拷貝到$HIVE_HOME/lib目錄下 如果出現沒有許可權的問題,在mysql授權mysql -uroot -p #執行下面的語句 *.*:表示所有庫下的所有表 %:任何ip地址或主機都可以連接 GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENDIFIED BY 'root' WITH GRANT OPTION; FLUSH PRIVILEGES;Jline包版本不一致問題
到這一步其實已經安裝好了,但是由於hadoop中的jline包版本和我們安裝hive的jline包版本不一致,會導致hql無法被執行。 因此我們還要把hive的lib目錄中的jline.2.12.jar替換掉$HADOOP_HOME/share/hadoop/yarn/lib/jline.0.9.94.jar啟動hive
bin/hive登錄hive
1.bin/hive 2.bin/beeline !connect jdbc:hive2://server1:10000 3.bin/beeline -u jdbc:hive2://server1:10000 -n hadoop創建表
創建外部表
create table tb_external(id int,name string) row format delimited fields terminated by',' location 'hdfs://kris/myhiveexternal';在hdfs中已在對應路徑存在文件
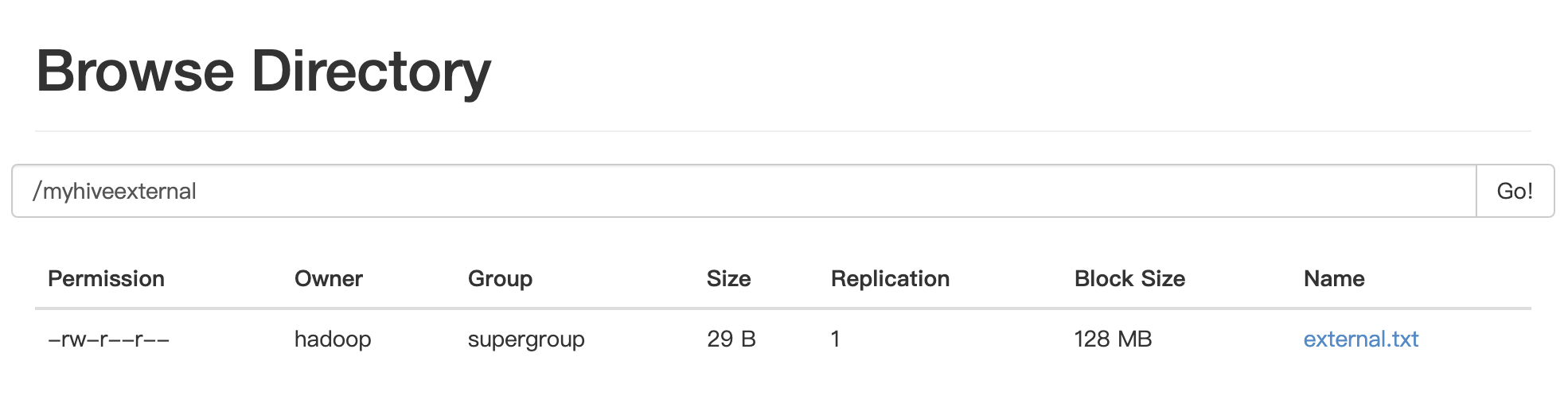
現在試試直接查詢
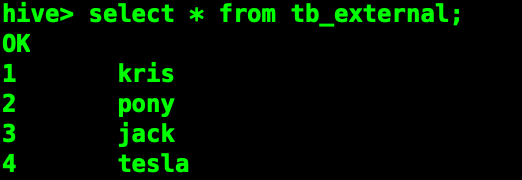
==為了保證數據的安全,我們一般把源數據表設置為外部表。數據只能通過外部載入導入==
創建帶桶的表
hive> create table student(id INT,age INT,name STRING) > partitioned by(stat_date STRING) > clustered by(id) sorted by(age) into 2 buckets > row format delimited fields terminated by ',';修改表
增加分區
alter table student add partition(stat_date='20190613') partition(stat_date='20190614'); alter table student add partition(stat_date='20190615') location '/user/hive/warehouse/student';刪除分區
alter table student drop partition(stat_date='20190613');創建的分區會在hdfs對應的路徑上創建文件夾

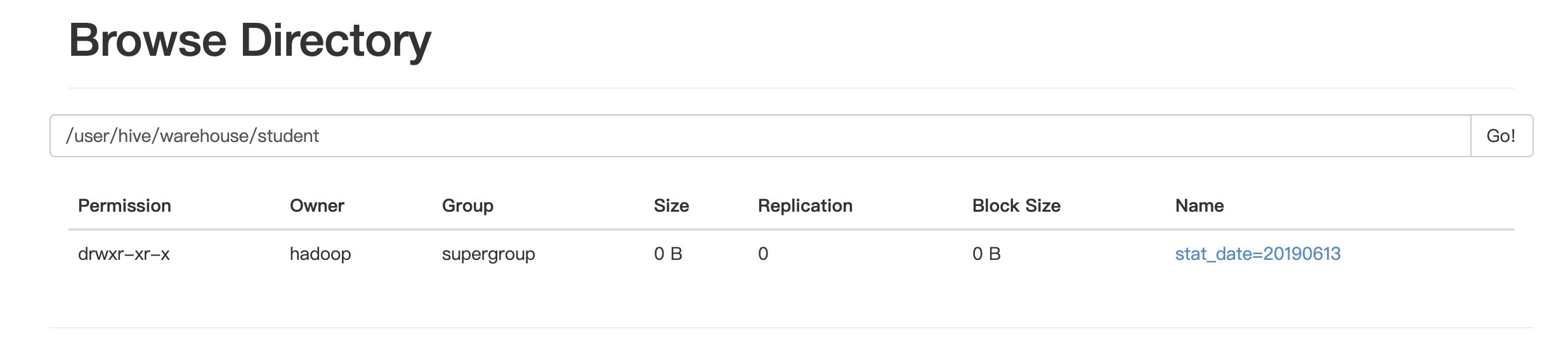
==如果增加的分區帶了路徑,那麼不會在hdfs的路徑上顯示對應的文件夾==
顯示錶分區
show partitions student;重命名表
alter table student rename to students;增加列
alter table students add columns(name1 string);==增加的列會在所有列後面,在partition列前面==
替換所有列
alter table students replace columns(id int,age int,name string);顯示命令
#查看錶 show tables #查看資料庫 show databases #查看分區 show partitions table_name #查看方法 show functions #顯示錶詳細資訊 desc extended table_name #格式話表資訊 desc formatted table_name載入數據
使用load data操作 hive會將文件複製到表對應的hdfs文件夾下
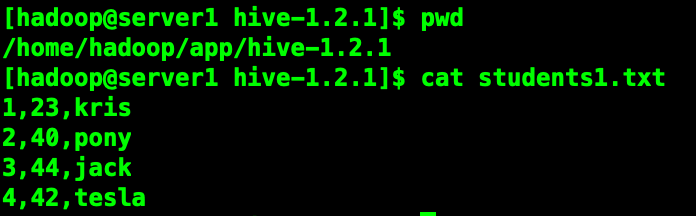
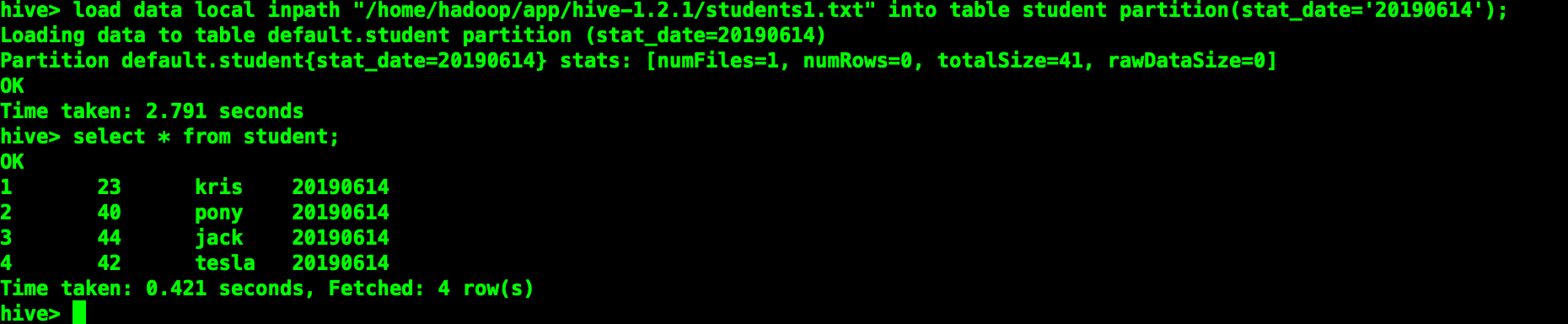
載入本地數據
load data local inpath "students1.txt" [overwrite] into table students partition(stat_date="20190614");加上overwrite會講原有對應分區的數據清除。
如果目標表(分區)已經有一個文件,並且文件名和filepath中的文件名衝突,那麼現有的文件會被新文件所替代。
導出數據
保存select查詢結果的幾種方式:
1、將查詢結果保存到一張新的hive表中
create table t_tmp as select * from t_p;2、將查詢結果保存到一張已經存在的hive表中
insert into table t_tmp select * from t_p;3、將查詢結果保存到指定的文件目錄(可以是本地,也可以是hdfs)
insert overwrite local directory '/home/hadoop/test' select * from t_p; insert overwrite directory '/aaa/test' select * from t_p;分桶示例
插入分桶表的數據需要是已經分好桶的,創建分桶的表並不會自動幫我們進行分桶。
#設置變數,設置分桶為true, 設置reduce數量是分桶的數量個數 set mapreduce.job.reduces=2; # 或者選擇以下方式 set hive.enforce.bucketing = true; # 向分桶表中插入數據 insert into student partition(stat_date='20190614') select id,age,name from tmp_stu where stat_date='20190614' cluster by(id);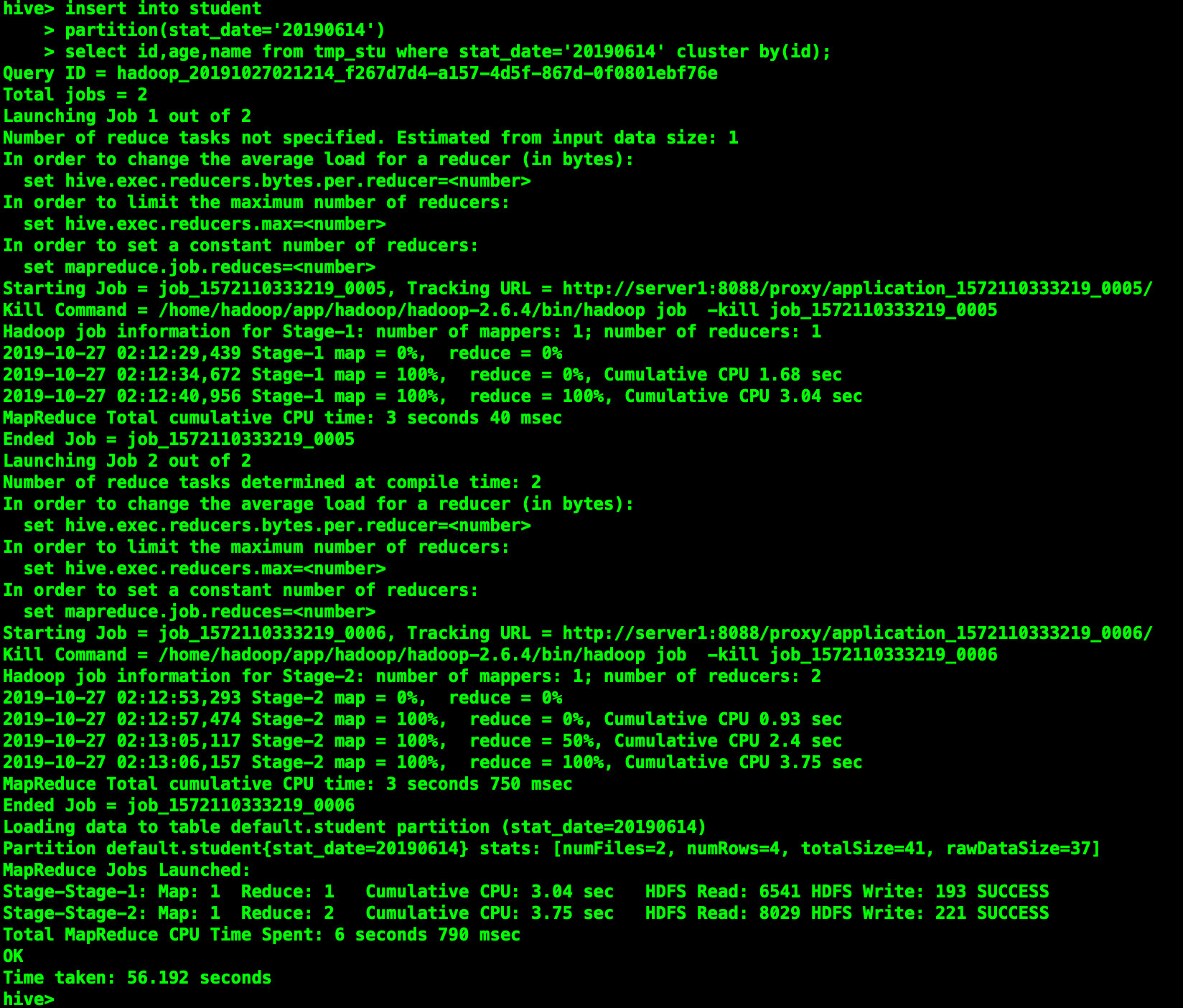
可見在hdfs上根據id分成了兩個桶
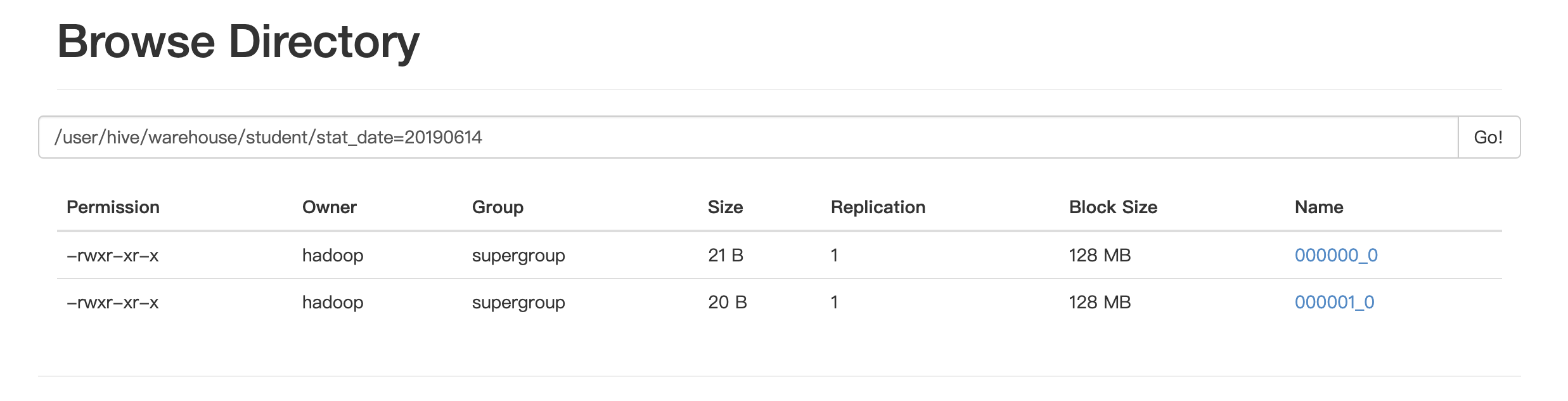
讓我們看看其中一個桶的內容

注意:
==1.order by 會對輸入做全局排序,因此只有一個reducer,會導致當輸入規模較大時,需要較長的計算時間。==
==2.sort by不是全局排序,它是在數據進去reduce task時有序。因此,如果用sort by進行排序,並且設置mapreduce.job.reduces>1,則sort by只保證每個reduce task的輸出有序,不保證全局有序。==
==3.distribute by根據distribute by指定的內容將數據分到同一個reducer==
==4.cluster by除了具有distribute by的功能外,還會對該欄位進行排序。因此我們可以這麼認為cluster by=distribute by + sort by==
==但是cluster by只能指定同一欄位,當我們要對某一欄位進行分桶,又要對另一欄位進行排序時,用distribute by + sort by更加靈活。==
==分桶表的作用:最大的作用是用來提高join操作的效率;==
思考:select a.id,a.name,b.addr from a join b on a.id=b.id;
如果a表和b表已經是分桶表,而且分桶的欄位是id欄位。做這個join操作時,還需要全表做笛卡爾積嗎?(文末給出答案)
分桶原理
數據分桶的原理: 跟MR中的HashPartitioner的原理一模一樣 MR中:按照key的hash值去模除以reductTask的個數 Hive中:按照分桶欄位的hash值去模除以分桶的個數 Hive也是 針對某一列進行桶的組織。Hive採用對列值哈希,然後除以桶的個數求余的方式決定該條記錄存放在哪個桶當中。數據分桶的作用
好處: 1、方便抽樣 2、提高join查詢效率如何將數據插入分桶表
將數據導入分桶表主要通過以下步驟
第一步:
從hdfs或本地磁碟中load數據,導入中間表(也就是上文用到的tmp_stu)第二步:
通過從中間表查詢的方式的完成數據導入 分桶的實質就是對 分桶的欄位做了hash 然後存放到對應文件中,所以說如果原有數據沒有按key hash ,需要在插入分桶的時候hash, 也就是說向分桶表中插入數據的時候必然要執行一次MAPREDUCE,這也就是分桶表的數據基本只能通過從結果集查詢插入的方式進行導入==我們需要確保reduce 的數量與表中的bucket 數量一致,為此有兩種做法==
1.讓hive強制分桶,自動按照分桶表的bucket 進行分桶。(推薦) set hive.enforce.bucketing = true; 2.手動指定reduce數量 set mapreduce.job.reduces = num; / set mapreduce.reduce.tasks = num; 並在 SELECT 後增加CLUSTER BY 語句 覺得不錯記得給我點贊加關注喔~ 公眾號:喜訊XiCent
