HBase 系列(二)—— HBase 系統架構及數據結構
- 2019 年 10 月 3 日
- 筆記
一、基本概念
一個典型的 Hbase Table 表如下:
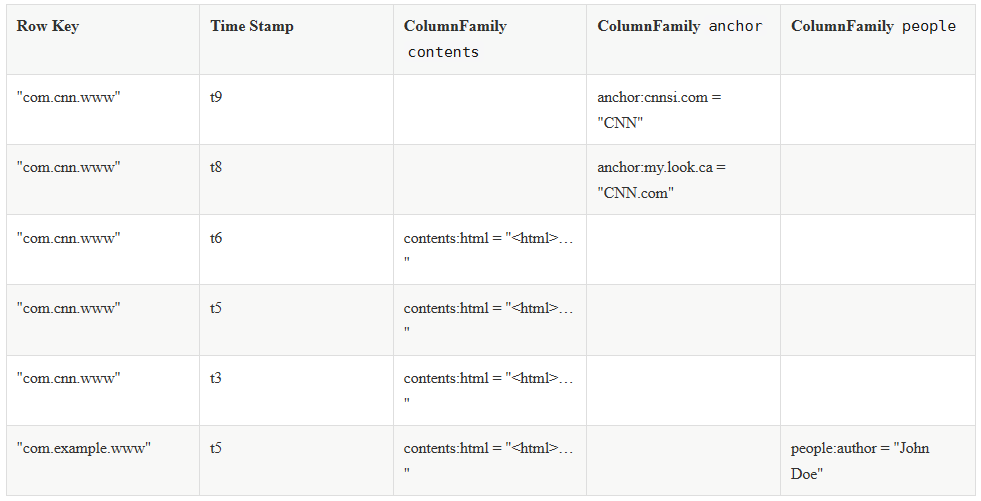
1.1 Row Key (行鍵)
Row Key 是用來檢索記錄的主鍵。想要訪問 HBase Table 中的數據,只有以下三種方式:
-
通過指定的
Row Key進行訪問; -
通過 Row Key 的 range 進行訪問,即訪問指定範圍內的行;
-
進行全表掃描。
Row Key 可以是任意字元串,存儲時數據按照 Row Key 的字典序進行排序。這裡需要注意以下兩點:
-
因為字典序對 Int 排序的結果是 1,10,100,11,12,13,14,15,16,17,18,19,2,20,21,…,9,91,92,93,94,95,96,97,98,99。如果你使用整型的字元串作為行鍵,那麼為了保持整型的自然序,行鍵必須用 0 作左填充。
-
行的一次讀寫操作時原子性的 (不論一次讀寫多少列)。
1.2 Column Family(列族)
HBase 表中的每個列,都歸屬於某個列族。列族是表的 Schema 的一部分,所以列族需要在創建表時進行定義。列族的所有列都以列族名作為前綴,例如 courses:history,courses:math 都屬於 courses 這個列族。
1.3 Column Qualifier (列限定符)
列限定符,你可以理解為是具體的列名,例如 courses:history,courses:math 都屬於 courses 這個列族,它們的列限定符分別是 history 和 math。需要注意的是列限定符不是表 Schema 的一部分,你可以在插入數據的過程中動態創建列。
1.4 Column(列)
HBase 中的列由列族和列限定符組成,它們由 :(冒號) 進行分隔,即一個完整的列名應該表述為 列族名 :列限定符。
1.5 Cell
Cell 是行,列族和列限定符的組合,並包含值和時間戳。你可以等價理解為關係型資料庫中由指定行和指定列確定的一個單元格,但不同的是 HBase 中的一個單元格是由多個版本的數據組成的,每個版本的數據用時間戳進行區分。
1.6 Timestamp(時間戳)
HBase 中通過 row key 和 column 確定的為一個存儲單元稱為 Cell。每個 Cell 都保存著同一份數據的多個版本。版本通過時間戳來索引,時間戳的類型是 64 位整型,時間戳可以由 HBase 在數據寫入時自動賦值,也可以由客戶顯式指定。每個 Cell 中,不同版本的數據按照時間戳倒序排列,即最新的數據排在最前面。
二、存儲結構
2.1 Regions
HBase Table 中的所有行按照 Row Key 的字典序排列。HBase Tables 通過行鍵的範圍 (row key range) 被水平切分成多個 Region, 一個 Region 包含了在 start key 和 end key 之間的所有行。
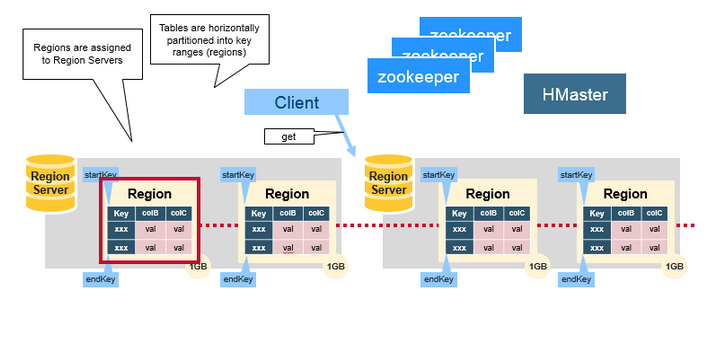
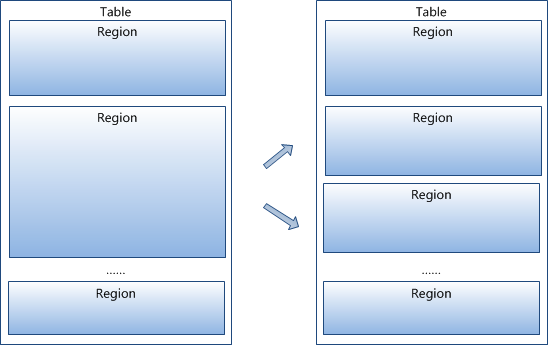
每個表一開始只有一個 Region,隨著數據不斷增加,Region 會不斷增大,當增大到一個閥值的時候,Region 就會等分為兩個新的 Region。當 Table 中的行不斷增多,就會有越來越多的 Region。
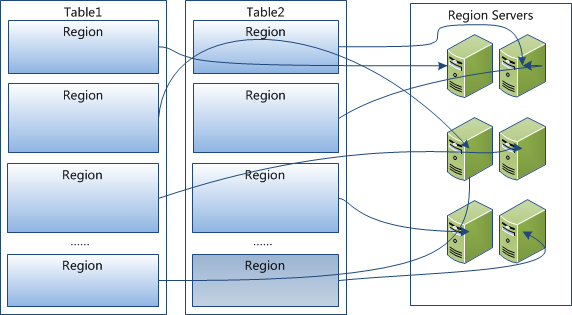
Region 是 HBase 中分散式存儲和負載均衡的最小單元。這意味著不同的 Region 可以分布在不同的 Region Server 上。但一個 Region 是不會拆分到多個 Server 上的。
2.2 Region Server
Region Server 運行在 HDFS 的 DataNode 上。它具有以下組件:
- WAL(Write Ahead Log,預寫日誌):用於存儲尚未進持久化存儲的數據記錄,以便在發生故障時進行恢復。
- BlockCache:讀快取。它將頻繁讀取的數據存儲在記憶體中,如果存儲不足,它將按照
最近最少使用原則清除多餘的數據。 - MemStore:寫快取。它存儲尚未寫入磁碟的新數據,並會在數據寫入磁碟之前對其進行排序。每個 Region 上的每個列族都有一個 MemStore。
- HFile :將行數據按照 KeyValues 的形式存儲在文件系統上。
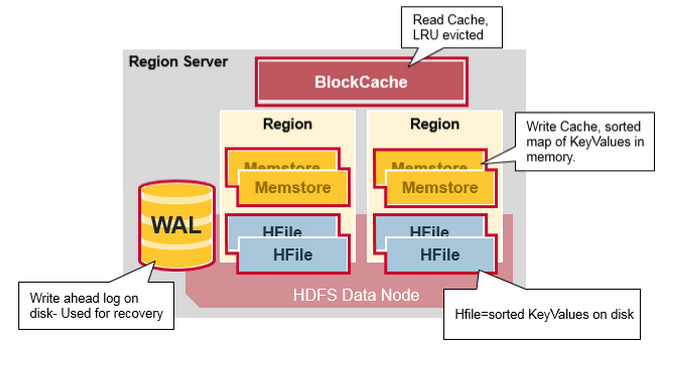
Region Server 存取一個子表時,會創建一個 Region 對象,然後對錶的每個列族創建一個 Store 實例,每個 Store 會有 0 個或多個 StoreFile 與之對應,每個 StoreFile 則對應一個 HFile,HFile 就是實際存儲在 HDFS 上的文件。
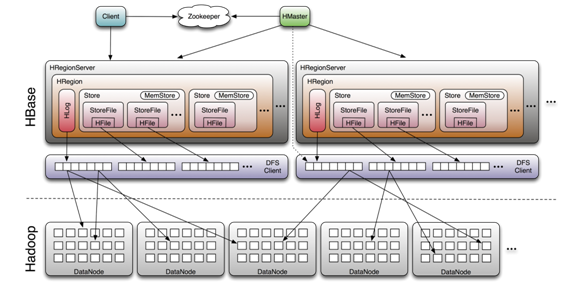
三、Hbase系統架構
3.1 系統架構
HBase 系統遵循 Master/Salve 架構,由三種不同類型的組件組成:
Zookeeper
-
保證任何時候,集群中只有一個 Master;
-
存貯所有 Region 的定址入口;
-
實時監控 Region Server 的狀態,將 Region Server 的上線和下線資訊實時通知給 Master;
-
存儲 HBase 的 Schema,包括有哪些 Table,每個 Table 有哪些 Column Family 等資訊。
Master
-
為 Region Server 分配 Region ;
-
負責 Region Server 的負載均衡 ;
-
發現失效的 Region Server 並重新分配其上的 Region;
-
GFS 上的垃圾文件回收;
-
處理 Schema 的更新請求。
Region Server
-
Region Server 負責維護 Master 分配給它的 Region ,並處理髮送到 Region 上的 IO 請求;
-
Region Server 負責切分在運行過程中變得過大的 Region。
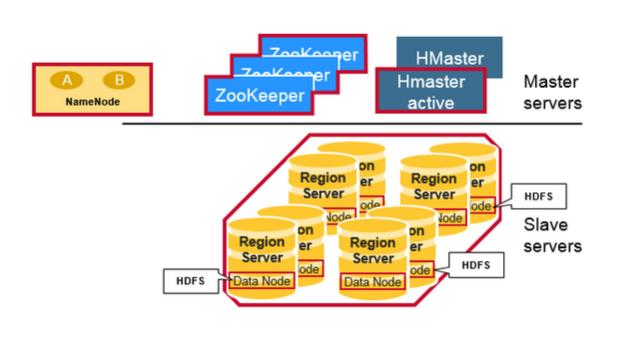
3.2 組件間的協作
HBase 使用 ZooKeeper 作為分散式協調服務來維護集群中的伺服器狀態。 Zookeeper 負責維護可用服務列表,並提供服務故障通知等服務:
-
每個 Region Server 都會在 ZooKeeper 上創建一個臨時節點,Master 通過 Zookeeper 的 Watcher 機制對節點進行監控,從而可以發現新加入的 Region Server 或故障退出的 Region Server;
-
所有 Masters 會競爭性地在 Zookeeper 上創建同一個臨時節點,由於 Zookeeper 只能有一個同名節點,所以必然只有一個 Master 能夠創建成功,此時該 Master 就是主 Master,主 Master 會定期向 Zookeeper 發送心跳。備用 Masters 則通過 Watcher 機制對主 HMaster 所在節點進行監聽;
-
如果主 Master 未能定時發送心跳,則其持有的 Zookeeper 會話會過期,相應的臨時節點也會被刪除,這會觸發定義在該節點上的 Watcher 事件,使得備用的 Master Servers 得到通知。所有備用的 Master Servers 在接到通知後,會再次去競爭性地創建臨時節點,完成主 Master 的選舉。
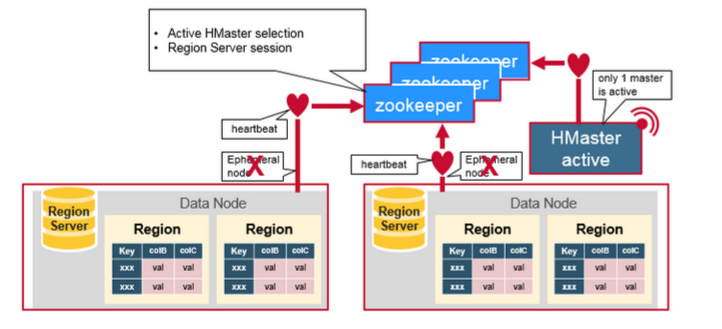
四、數據的讀寫流程簡述
4.1 寫入數據的流程
-
Client 向 Region Server 提交寫請求;
-
Region Server 找到目標 Region;
-
Region 檢查數據是否與 Schema 一致;
-
如果客戶端沒有指定版本,則獲取當前系統時間作為數據版本;
-
將更新寫入 WAL Log;
-
將更新寫入 Memstore;
-
判斷 Memstore 存儲是否已滿,如果存儲已滿則需要 flush 為 Store Hfile 文件。
更為詳細寫入流程可以參考:HBase - 數據寫入流程解析
4.2 讀取數據的流程
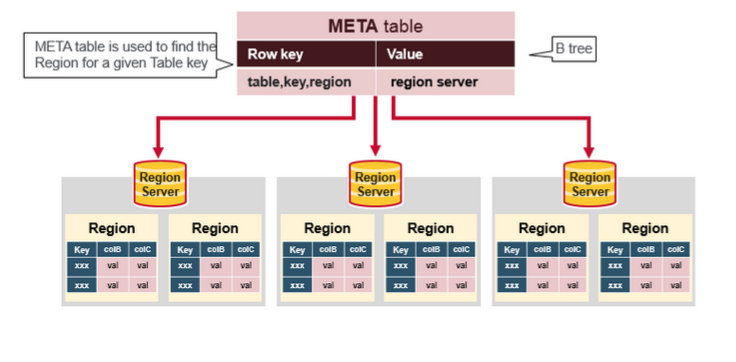
以下是客戶端首次讀寫 HBase 上數據的流程:
-
客戶端從 Zookeeper 獲取
META表所在的 Region Server; -
客戶端訪問
META表所在的 Region Server,從META表中查詢到訪問行鍵所在的 Region Server,之後客戶端將快取這些資訊以及META表的位置; -
客戶端從行鍵所在的 Region Server 上獲取數據。
如果再次讀取,客戶端將從快取中獲取行鍵所在的 Region Server。這樣客戶端就不需要再次查詢 META 表,除非 Region 移動導致快取失效,這樣的話,則將會重新查詢並更新快取。
註:META 表是 HBase 中一張特殊的表,它保存了所有 Region 的位置資訊,META 表自己的位置資訊則存儲在 ZooKeeper 上。
更為詳細讀取數據流程參考:
參考資料
本篇文章內容主要參考自官方文檔和以下兩篇部落格,圖片也主要引用自以下兩篇部落格:
官方文檔:
更多大數據系列文章可以參見 GitHub 開源項目: 大數據入門指南
