入職大廠,齊姐精選的 9 道 Java 集合面試題
- 2020 年 10 月 10 日
- 筆記
Java 集合框架其實都講過了,有一篇講 Collection 的,有一篇講 HashMap 的,那沒有看過的小夥伴快去補下啦,文末也都有鏈接;看過的小夥伴,那本文就是檢測學習成果的時候啦
今天這篇文章是單純的從面試的角度出發,以回答面試題為線索,再把整個 Java 集合框架複習一遍,希望能幫助大家拿下面試。
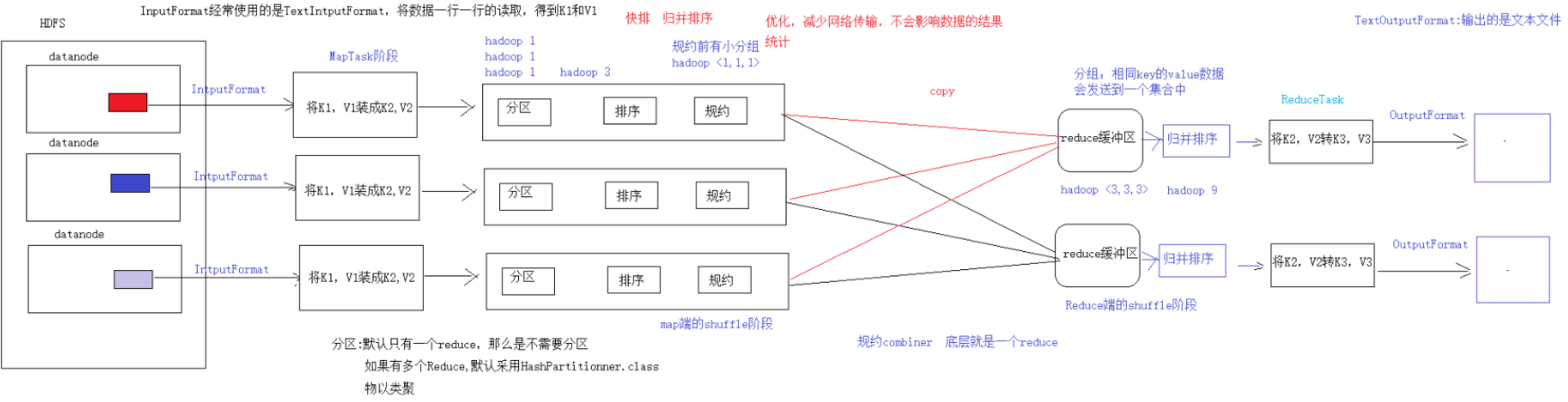
先上圖:

當面試官問問題時,我會先把問題歸類,鎖定這個知識點在我的知識體系中的位置,然後延展開來想這一塊有哪些重點內容,面試官問這個是想考察什麼、接下來還想問什麼。
這樣自己的思路不會混亂,還能預測面試官下一個問題,或者,也可以引導面試官問出你精心準備的問題,這場面試本質上就是你在主導、你在 show off 自己紮實的基礎知識和良好的溝通交流能力。
其實我在 LRU 那篇文章里就說到過這個觀點,然後就有讀者問我,說會不會被面試官看穿?
答:看出來了又怎樣?面試官閱人無數,是有可能看出來的,但是也只會莞爾一笑,覺得這個同學很用心。
精心準備面試既是對面試官個人時間的尊重,也是表明了你對這家公司的興趣,這樣的員工不是每家公司都想要的嗎?
好了,進入正題,今天就來解決這 9 大面試題。
1. ArrayList vs LinkedList
這題的問法很多,比如
-
最簡單的就直接問 ArrayList 和 LinkedList 的區別和聯繫; -
或者問你什麼時候要選擇 ArrayList,什麼時候選擇 LinkedList; -
或者在你們聊到某個場景、或者在演算法題中,面試官問你如何選擇。
萬變不離其宗。
首先結論是:
-
絕大多數的情形下都偏向於用 ArrayList,除非你有明確的要使用LinkedList的理由。 -
如果你不確定用哪個,就用 ArrayList。
兩者在實現層面的區別是:
-
ArrayList是用一個可擴容的數組來實現的 (re-sizing array); -
LinkedList是用doubly-linked list來實現的。
而數組和鏈表之間最大的區別就是數組是可以隨機訪問的(random access)。
這個特點造成了在數組裡可以通過下標用 O(1) 的時間拿到任何位置的數,而鏈表則做不到,只能從頭開始逐個遍歷。
兩者在增刪改查操作上的區別:
-
在「改查」這兩個功能上,因為數組能夠隨機訪問,所以 ArrayList 的效率高; -
在「增刪」這兩個功能上,如果不考慮找到這個元素的時間,數組因為物理上的連續性,當要增刪元素時,在尾部還好,但是其他地方就會導致後續元素都要移動,所以效率較低;而鏈表則可以輕鬆的斷開和下一個元素的連接,直接插入新元素或者移除舊元素。
但是呢,實際上你不能不考慮找到元素的時間啊。。。雖然 LinkedList 可以 O(1) 的時間插入和刪除元素,可以你得先找到地方啊!
不是有個例子么,修理這個零件只需要 1 美元,但是找到這個零件需要 9999 美元。我們平時修 bug 也是如此,重點是找到 root cause 的過程。
而且如果是在尾部操作,數據量大時 ArrayList 會更快的。
事實上,LinkedList 是很多性能問題的 bug,那麼為什麼呢?
因為 ListNode 在物理記憶體里的不連續,導致它用了很多小的記憶體片段,這會影響很多進程的性能以及 cache-locality(局部性);所以即便是理論上的時間複雜度和 ArrayList 一樣時,也會導致實際上比 ArrayList 慢很多。
2. ArrayList vs Vector
答:
-
Vector是執行緒安全的,而ArrayList是執行緒不安全的; -
擴容時擴多少的區別,文鄒鄒的說法就是 data growth methods不同,-
Vector默認是擴大至 2 倍; -
ArrayList默認是擴大至 1.5 倍。
-
回顧下這張圖,

Vector 和 ArrayList 一樣,也是繼承自 java.util.AbstractList,底層也是用數組來實現的。
但是現在已經被棄用了,因為它是執行緒安全的。任何好處都是有代價的,執行緒安全的代價就是效率低,在某些系統里很容易成為瓶頸,所以現在大家不再在數據結構的層面加 synchronized,而是把這個任務轉移給我們程式設計師。
那怎麼知道擴容擴多少的呢?
看源碼:

這是 Vecotr 的擴容實現,因為通常並不定義 capacityIncrement,所以默認情況下它是擴容兩倍。
VS

這是 ArrayList 的擴容實現,算術右移操作是把這個數的二進位往右移動一位,最左邊補符號位,但是因為容量沒有負數,所以還是補 0.
那右移一位的效果就是除以 2,那麼定義的新容量就是原容量的 1.5 倍。
3. ArrayDeque vs LinkedList
首先要清楚它們之間的關係:

答:
-
ArrayDeque 是一個可擴容的數組,LinkedList 是鏈表結構; -
ArrayDeque 里不可以存 null 值,但是 LinkedList 可以; -
ArrayDeque 在操作頭尾端的增刪操作時更高效,但是 LinkedList 只有在當要移除中間某個元素且已經找到了這個元素後的移除才是 O(1) 的; -
ArrayDeque 在記憶體使用方面更高效。 -
所以,只要不是必須要存 null 值,就選擇 ArrayDeque 吧!
那如果是一個很資深的面試官問你,什麼情況下你要選擇用 LinkedList 呢?
答:Java 6 以前。因為 ArrayDeque 在 Java 6 之後才有的。
為了版本兼容的問題,實際工作中我們不得不做一些妥協。
4. HashSet 實現原理
答:
HashSet 是基於 HashMap 來實現的,底層採用 Hashmap 的 key 來儲存元素,主要特點是無序的,基本操作都是 O(1) 的時間複雜度,很快。
所以它的實現原理可以用 HashMap 的來解釋。
5. HashMap 實現原理
答:
-
在 JDK1.6/1.7,數組 + 鏈表; -
在 JDK 1.8,數組 + 紅黑樹。
具體說來,
對於 HashMap 中的每個 key,首先通過 hash function 計算出一個哈希值,這個哈希值就代表了在桶里的編號,而「桶」實際上是通過數組來實現的,但是桶有可能比數組大呀,所以把這個哈希值模上數組的長度得到它在數組的 index,就這樣把它放在了數組裡。

這是理想情況下的 HashMap,但現實中,不同的元素可能會算出相同的哈希值,這就是哈希碰撞,即多個 key 對應了同一個桶。
為了解決哈希碰撞呢,Java 採用的是 Separate chaining 的解決方式,就是在碰撞的地方加個鏈子,也就是上文說的鏈表或者紅黑樹。
具體的 put() 和 get()這兩個重要 API 的操作過程和原理,大家可以在公眾號後台回復「HashMap」獲取文章閱讀。
6. HashMap vs HashTable
答:
-
Hashtable是執行緒安全的,HashMap並非執行緒安全; -
HashMap允許key中有null值,Hashtable是不允許的。這樣的好處就是可以給一個默認值。
其實 HashMap 與 Hashtable 的關係,就像 ArrayList 與 Vector,以及 StringBuilder 與 StringBuffer。
Hashtable 是早期 JDK 提供的介面,HashMap 是新版的。這些新版的改進都是因為 Java 5.0 之後允許數據結構不考慮執行緒安全的問題,因為實際工作中我們發現沒有必要在數據結構的層面上上鎖,加鎖和放鎖在系統中是有開銷的,內部鎖有時候會成為程式的瓶頸。
所以 HashMap, ArrayList, StringBuilder 不再考慮執行緒安全的問題,性能提升了很多。
7. 為什麼改 equals() 一定要改 hashCode()?
答:
首先基於一個假設:任何兩個 object 的 hashCode 都是不同的。也就是 hash function 是有效的。
那麼在這個條件下,有兩個 object 是相等的,那如果不重寫 hashCode(),算出來的哈希值都不一樣,就會去到不同的 buckets 了,就迷失在茫茫人海中了,再也無法相認,就和 equals() 條件矛盾了,證畢。
-
hashCode()決定了key放在這個桶里的編號,也就是在數組裡的index; -
equals()是用來比較兩個object是否相同的。
8. 如何解決哈希衝突?
一般來說哈希衝突有兩大類解決方式:
-
Separate chaining -
Open addressing
Java 中採用的是第一種 Separate chaining,即在發生碰撞的那個桶後面再加一條「鏈」來存儲。

那麼這個「鏈」使用的具體是什麼數據結構,不同的版本稍有不同,上文也提到過了:
-
JDK1.6 和 1.7 是用鏈表存儲的,這樣如果碰撞很多的話,就變成了在鏈表上的查找,worst case 就是 O(n);
-
JDK 1.8 進行了優化,當鏈表長度較大時(超過 8),會採用紅黑樹來存儲,這樣大大提高了查找效率。
(話說,這個還真的喜歡考,已經在多次面試中被問過了,還有面試官問為什麼是超過「8」才用紅黑樹 🤔)
第二種方法 open addressing 也是非常重要的思想,因為在真實的分散式系統里,有很多地方會用到 hash 的思想但又不適合用 seprate chaining。
這種方法是順序查找,如果這個桶里已經被佔了,那就按照「某種方式」繼續找下一個沒有被占的桶,直到找到第一個空的。

如圖所示,John Smith 和 Sandra Dee 發生了哈希衝突,都被計算到 152 號桶,於是 Sandra 就去了下一個空位 – 153 號桶,當然也會對之後的 key 發生影響:Ted Baker 計算結果本應是放在 153 號的,但鑒於已經被 Sandra 佔了,就只能再去下一個空位了,所以到了 154 號。
這種方式叫做 Linear probing 線性探查,就像上圖所示,一個個的順著找下一個空位。當然還有其他的方式,比如去找平方數 Double hashing.
9. Collection vs Collections
這倆看似相近,實則相差十萬八千里,就好像好人和好人卡的區別似的。
Collection 是
-
集合介面;
-
是
Java 集合框架的root interface; -
落腳點是一個
interface; -
包含了以下這些介面和類:

想系統學習 Collection,可以在公眾號內回復「集合」,獲取爆款文章。
而 Collections 是工具類 utility class,是集合的操作類,提供了一些靜態方法供我們使用,比如:
-
addAll() -
binarySearch() -
sort() -
shuffle() -
reverse()
好了,以上就是集合的常考面試題匯總和答案了,希望不僅能幫助你拿下面試,也能真的理解透徹,靈活運用。
最近看到自己的文章在其他平台被他人搬運,請大家認準全網統一唯一標識「碼農田小齊」,並且懇請大家如果看到沒有寫明作者和來源出處的我的文章,告知我一聲,這些文章都是自己的心肝寶貝啊嗷嗚~
最後,如果你覺得一個人堅持的很難,想有小夥伴一起學習、互相監督打氣的,記得加入我的自習室。
我是小齊,紐約程式媛,終生學習者,每天晚上 9 點,雲自習室里不見不散!
更多乾貨文章見我的 Github: //github.com/xiaoqi6666/NYCSDE