Hadoop理論基礎
- 2020 年 10 月 10 日
- 筆記
Hadoop是 Apache 旗下的一個用 java 語言實現開源軟體框架,是一個開發和運行處理大規模數據的軟體平台。允許使用簡單的編程模型在大量電腦集群上對大型數據集進行分散式處理。
特性:擴容能力,成本低,高效 ,可靠性
首次啟動 HDFS 時,必須對其進行格式化操作。本質上是一些清理和準備工作,因為此時的 HDFS 在物理上還是不存在的
常用埠號
- namenode 50070
- datenode 50075
- secondarynamenode 50090
- yarn.resoucemanager 8088
- 歷史伺服器 19888
目錄結構及文件分塊位置資訊叫做元數據。
HDFS存儲規則儘可能不存儲小文件,因為一條元數據理論上150kb,若10W個小文件,存儲元數據記憶體就要15M。
HDFS讀寫數據流程
1)寫數據
1. 客戶端向namenode發出申請
2. namenode查看是否有許可權, 是否有同名文件
3. namenode向客戶端返回是否允許上傳
4. 對文件進行切割, 切割成大小為128MB的block塊, 1.x 默認64MB, 2.x 默認128MB
5. 開始上傳第一個block
6. namenode根據配置文件中指定的備份數量及副本放置策略進行文件分配, 返回datenode地址,通過機架感知選出datenode列表,如node01,node03
機架感知–3副本機制: 判斷客戶端所在位置, 如果客戶端在當前HDFS集群上的一台, 那麼第一個副本會放在客戶端所在的機器上, 第二個副本不同於第一個, 放在不同於第一台的另一個機架, 第三個與第二個在同一個機架上, 但在不同的節點上.
7. 客戶端請求2台datenode中的node01上傳數據, 本質上是調用RPC, 建立pipeline連接, node01繼續調用node03, 將整個pipeline連接完成,然後逐步返回客戶端
8. 客戶端開始向node01開始上傳第一個block塊, 先從磁碟讀取放到本地記憶體快取, 以packet為單位, 默認64KB, node01收到一個packet就會傳給node03, node01每傳一個packet就將其放入一個應答隊列等待應答.
9. 數據被分割成一個個packet數據包在pipeline上一次傳輸, 在pipeline反方向上, 備份節點存儲成功後逐個發送ack正確碼, 最終由pipeline中第一個DataNode節點node01將pipeline ack確認碼發送給Client.
10. 繼續依次上傳一個個block塊
2)讀數據
1. 客戶端向namenode發起RPC請求, 確定文件block的所在位置
2. namenode返回元數據, 對於每個block, namenode都會返回副本所在datenode地址
3. 返回的datenode地址會根據集群拓撲結構算出與客戶端的距離, 並進行排序.
排序兩個規則: 網路拓撲結構中與客戶端距離近的排靠前, 心跳機制中彙報超時的datenode狀態為stale的排靠後
4. 客戶端通過排靠前的datenode讀取block, 若客戶端就是datenode, 則從本地直接讀取
5. 底層本質上是建立 socket stream (FSDateInputFormat) , 重複的調用父類DataInputFormat的read方法, 直到這塊讀取完畢
6. 讀完列表的block, 文件讀取還沒有結束, 客戶端繼續向block申請下一批block
7. 讀完一個block會進行checksum驗證, 如果讀取datenode出現錯誤, 會通知namenode, 找下一個存有這個block備份的datenode
8. read方法的並行讀取block塊, 不是一塊一塊讀取, namenode只返回datenode的地址, 不返回塊的數據
9. 最終讀取的所有block合併成一個大文件
MapReduce 框架結構
一個完整的 mapreduce 程式在分散式運行時有三類實例進程:
- MRAppMaster:負責整個程式的過程調度及狀態協調
- MapTask:負責 map 階段的整個數據處理流程
- ReduceTask:負責 reduce 階段的整個數據處理流程
MR編程(天龍八部)
map階段:2步
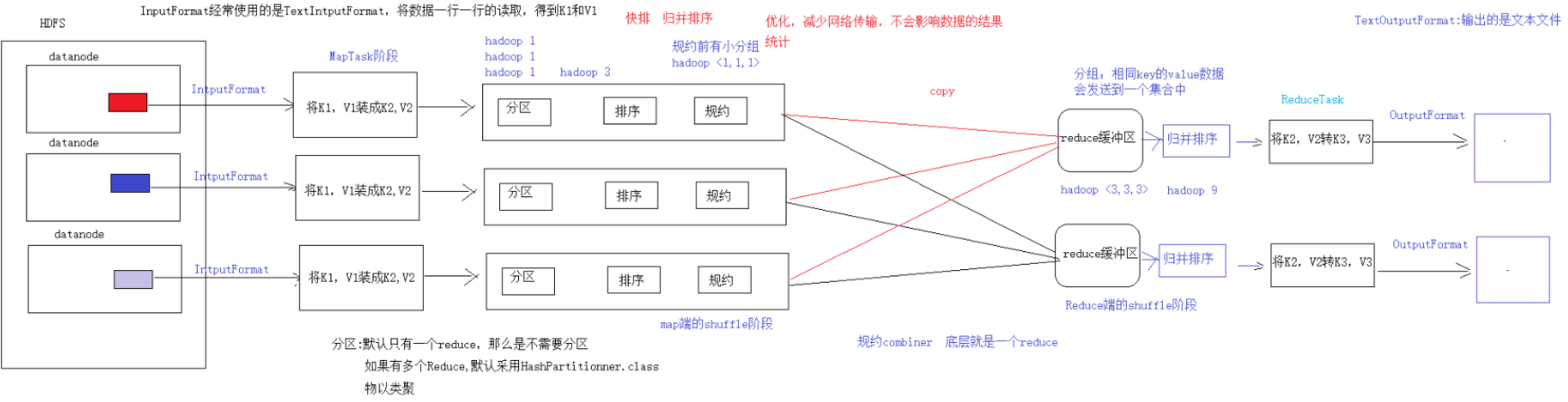
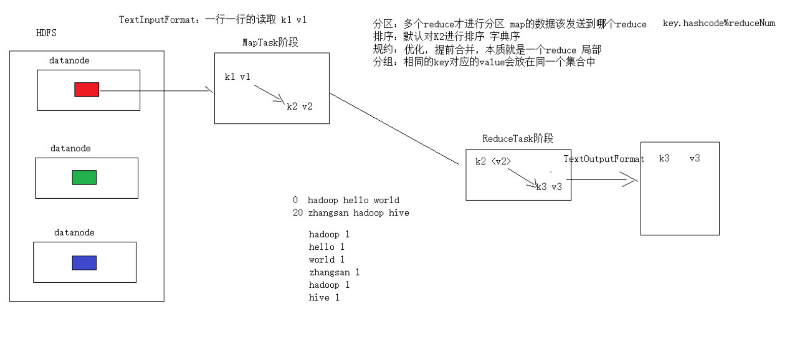
第一步:設置InputFormat(通常使用TextInputFormat)的類型和數據的路徑—獲取數據的過程(可以得到K1,V1)
第二步:自定義Mapper–將K1,V1轉為K2,V2
shuffle階段:4步
第三步:分區的動作,如果有多個reduce才去考慮分區,默認只有一個reduce,分區可以省略
第四步:排序,默認對K2進行排序(字典序)–管好K2就行
第五步:規約,combiner是一個局部的reduce,map端的合併,是對mapreduce的優化操作,不會影響任何結果,減少網路傳輸,默認可以省略
第六步:分組,相同的K(K2)對應的V會放到同一個集合中—將map傳遞的K2,V2變成新的K2,V2
Reduce階段:2步
第七步:自定義Reducer 得到K2,V2,轉為K3,V3
第八步:設置OutputFormat和數據的路徑–生成結果文件
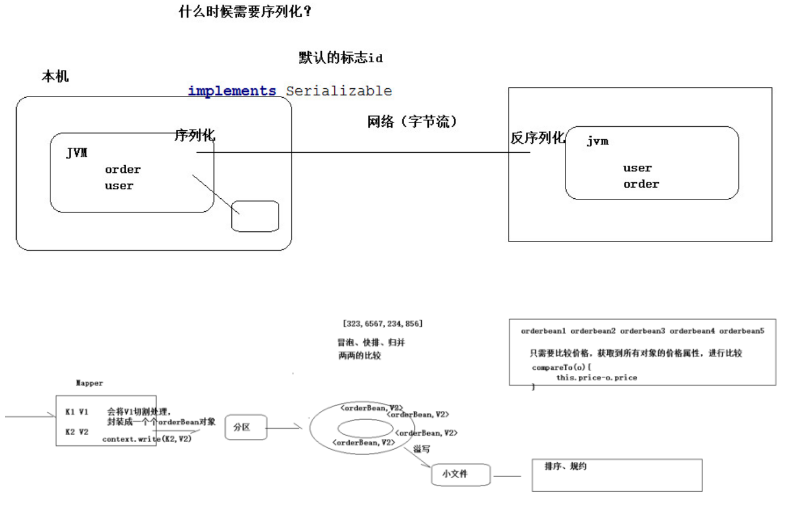
序列化(Serialization)是指把結構化對象轉化為位元組流。
反序列化(Deserialization)是序列化的逆過程。把位元組流轉為結構化對象。
//反序列化的方法,反序列化時, //從流中讀取到的各個欄位的順序應該與序列化時 //寫出去的順序保持一致 @Override public void readFields(DataInput in) throws IOException { upflow = in.readLong(); dflow = in.readLong(); sumflow = in.readLong(); } //序列化的方法 @Override public void write(DataOutput out) throws IOException { out.writeLong(upflow); out.writeLong(dflow); out.writeLong(sumflow); } @Override public int compareTo(FlowBean o) { //實現按照 sumflow 的大小倒序排序 return sumflow>o.getSumflow()?-1:1; }
compareTo方法用於將當前對象與方法的參數進行比較。 如果指定的數與參數相等返回 0。 如果指定的數小於參數返回 -1。 如果指定的數大於參數返回 1。
例如:o1.compareTo(o2) 返回正數的話,當前對象(調用 compareTo 方法的對象 o1)要排在比較對象(compareTo 傳參對象 o2)後面,返回負數的話,放在前面。
分組
Mapreduce 中會將 map 輸出的 kv 對,按照相同 key 分組,然後分發給不同的 reducetask。 默認的分發規則為:根據 key 的 hashcode%reducetask 數來分發
combiner規約
每一個 map 都可能會產生大量的本地輸出,Combiner 的作用就是對 map 端的輸出先做一次合併,以減少在 map 和 reduce 節點之間的數據傳輸量,以提高網路 IO 性能,是 MapReduce 的一種優化手段之一。
- combiner 是 MR 程式中 Mapper 和 Reducer 之外的一種組件
- combiner 組件的父類就是 Reducer
- combiner 和 reducer 的區別在於運行的位置:
- combiner 是在每一個 maptask 所在的節點運行
- reducer 是接收全局所有 Mapper 的輸出結果;
- combiner 的意義就是對每一個 maptask 的輸出進行局部匯總,以減小網路傳輸量
具體實現步驟:
- 自定義一個 combiner 繼承 Reducer,重寫 reduce 方法
- 在 job 中設置: job.setCombinerClass(CustomCombiner.class)
combiner 能夠應用的前提是不能影響最終的業務邏輯,而且,combiner 的輸出 kv 應該跟 reducer 的輸入 kv 類型要對應起來。
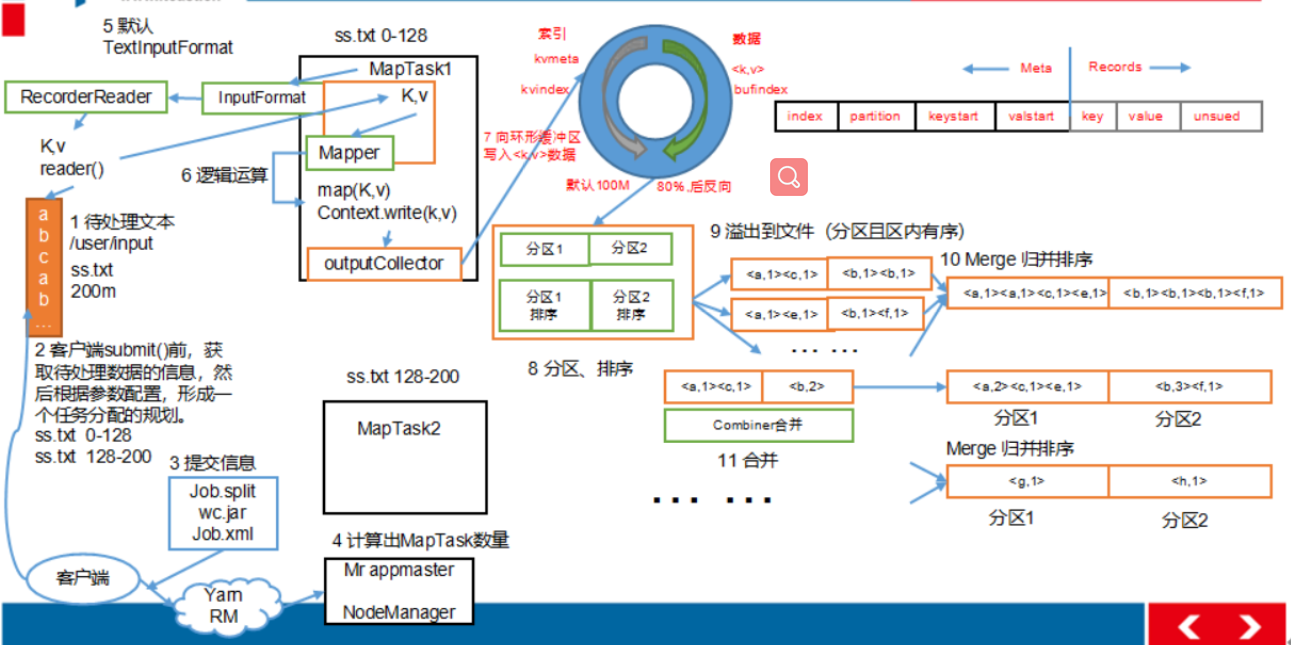
MapTask 工作機制
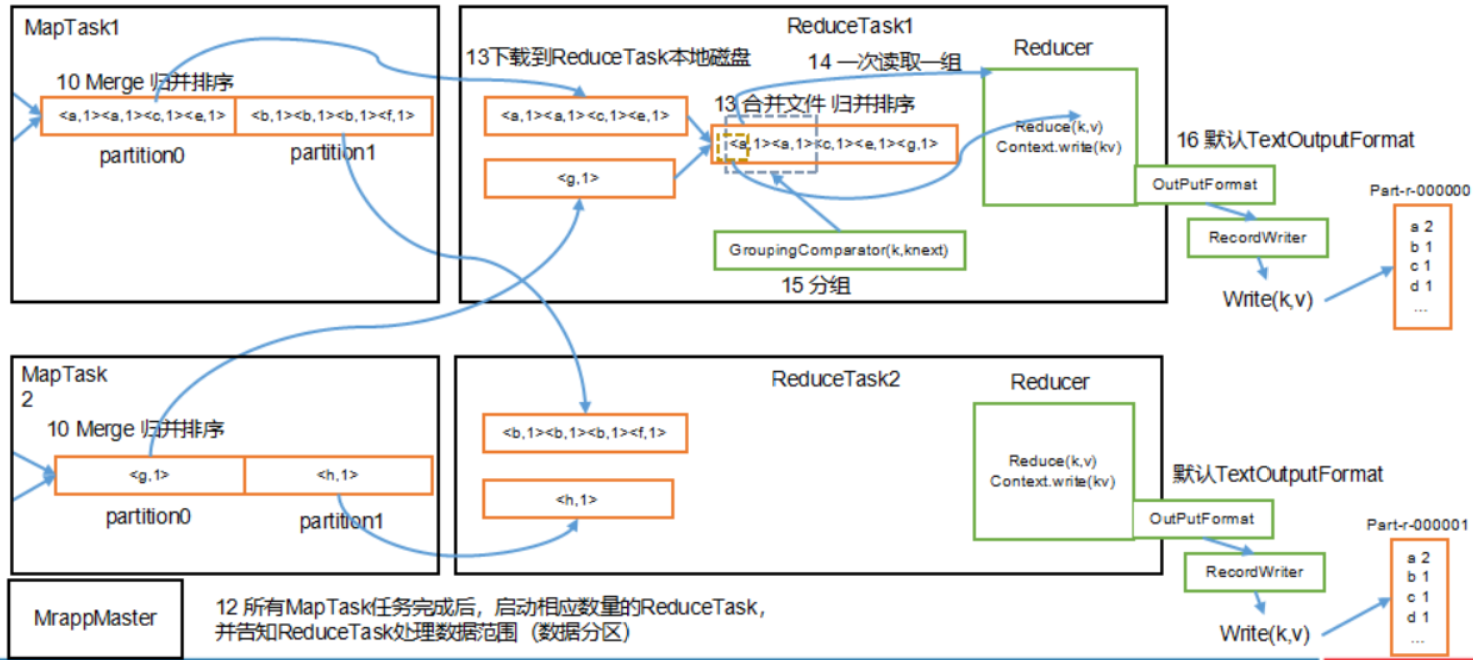
ReduceTask 工作機制
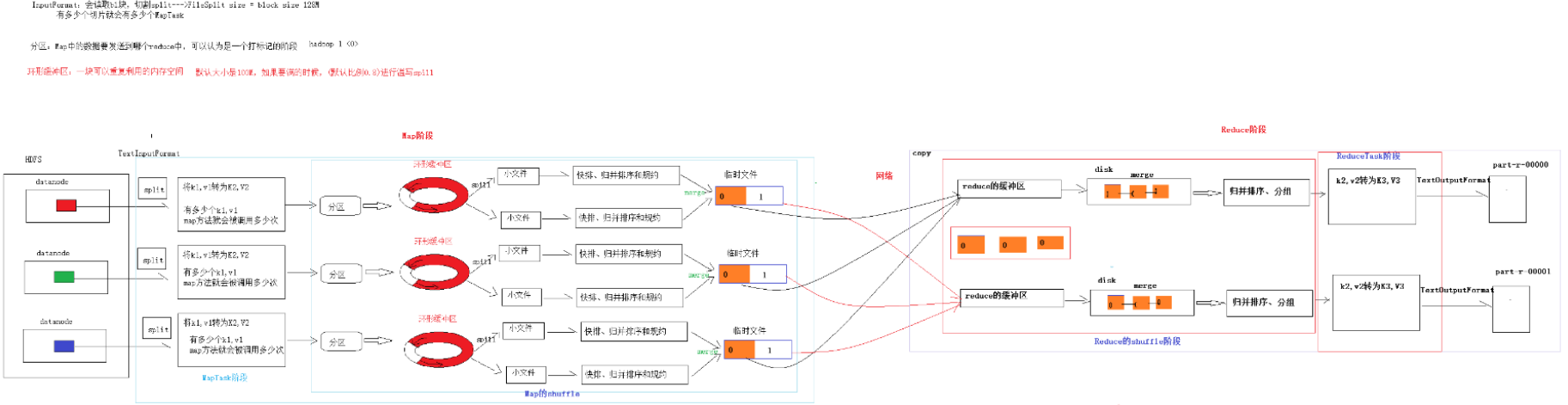
Shuffle 機制
map 階段處理的數據如何傳遞給 reduce 階段,是 MapReduce 框架中最關鍵的一個流程,這個流程就叫 shuffle。

- 將map端結果輸出到環形緩衝區, 默認為100M, 保存的是<key, value>和分區資訊多個ReduceTask時才需要分區
- 當環形緩衝去到達80%時, 寫入磁碟中, 在寫入之前對數據進行快排, 如果配置了combiner, 還會對有相同分區號和key進行排序
Combiner規約:作用就是對map端的輸出先做一次合併, 以減少在map和reduce節點之間的數據傳輸量, 以提高網路IO性能, 是MR的一種優化手段之一
- 將所有溢出的臨時文件進行一次合併操作, 確保一個MapTask最終只生成一個文件
- Reduce複製一份數據, 默認保存在記憶體的緩衝區中, 到達閾值, 將數據寫到磁碟
- Reduce複製數據同時, 開啟兩個執行緒對記憶體到本地的數據進行合併
- 進行合併數據同時, 進行排序, 因為Map端已進行局部排序, Reduce只需保證數據整體有效
壓縮機制map輸出壓縮(減少shuffle過程中網路傳輸)reduce輸出壓縮(減少HDFS存儲)
壓縮
DEFLATE:自帶,不可切分,和文本處理一樣, 不需要修改
Gzip:自帶,不可切分,和文本處理一樣, 不需要修改
Bzip2:自帶,可以切分,和文本處理一樣, 不需要修改
LZO:需要安裝,可以切分,建立索引指定輸入格式
snappy:需要安裝,不可切分,和文本處理一樣, 不需要修改
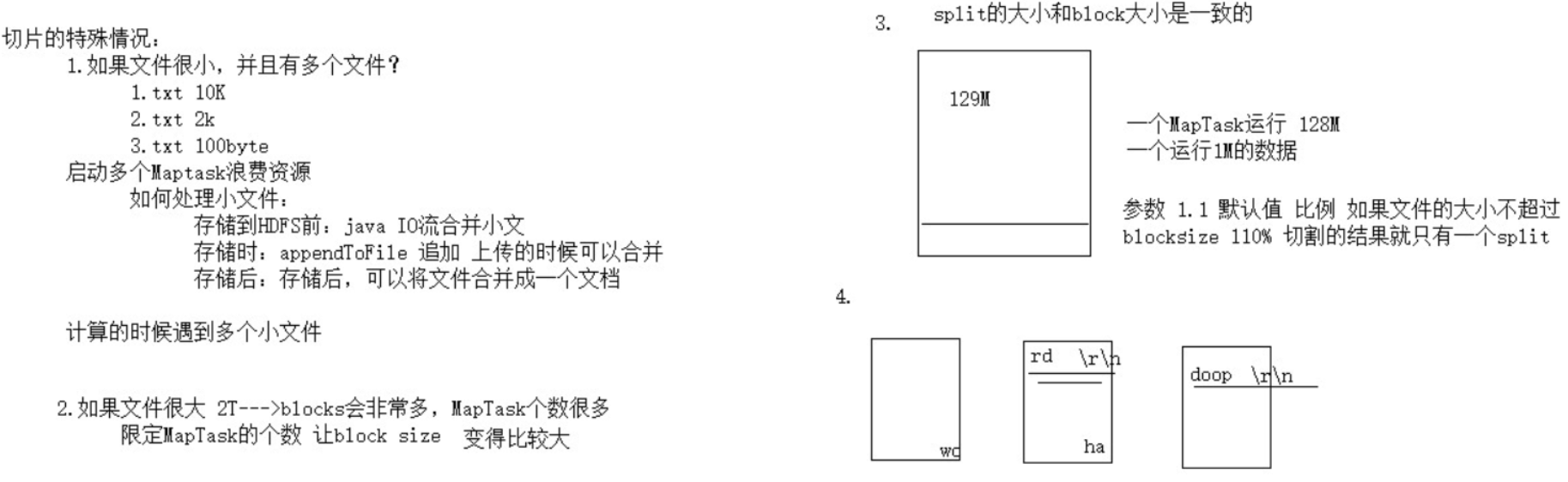
切片機制
- 單純按照文件內容切分
- 切片大小等於block塊大小
- 不考慮數據集整體, 逐個針對文件切片
- 切片公式: max(0, min(Long_max, blockSize))
DistributedCache 分散式快取
Map 端 Join 解決數據傾斜,我們為每一個 MapTask 準備一個表的全表數據文件。這種機制叫做 Map Side Join。適用於關聯表中有小表的情形。
CombineTextInputFormat
小文件處理場景 將 HDFS 上多個小文件合併到一個 InputSplit中,然後會啟用一個 Map 來處理這裡面的文件,以此減少 MR 整體作業的運行時間。
元數據的管理機制 checkpoint
NameNode 維護整個文件系統元數據
按照類型劃分:文件資訊、塊資訊、datanode節點資訊
按照形式劃分:記憶體元數據、文件元數據
- 記憶體元數據:文件資訊、塊資訊、datanode節點資訊
- 文件元數據:只包含文件資訊,其他資訊是在datanode啟動的時候進行上報
fsimage鏡像文件
通常很大,保存的是一個小時前文件資訊,是元數據的一個持久化的檢查點,包含 Hadoop 文件系統中的所有目錄和文件元數據資訊,但不包含文件塊位置的資訊。文件塊位置資訊只存儲在記憶體中,是在 datanode 加入集群的時候,namenode 詢問 datanode 得到的,並且間斷的更新。
edits日誌
通常比較小,保存最近更改的文件資訊,存放的是 Hadoop 文件系統的所有更改操作(文件創建,刪除或修改)的日誌,文件系統客戶端執行的更改操作首先會被記錄到 edits 文件中,只有當所有的寫操作都執行完成之後,寫操作才會返回成功。
SecondaryNameNode
職責是合併NameNode的edit logs到fsimage文件中, 減小edit logs文件的大小和得到一個最新的fsimage文件
Secondary Namenode將namenode上積累的所有edits和一個最新的fsimage下載到本地, 並載入到記憶體進行merge, 這個過程稱為checkpoint. 一個小時檢查一次fsimage,更新edits的數據到fsimage中。
安全模式(其中有個概念叫最小的副本的副本率)
HDFS所處的一種特殊狀態,在這種狀態下,文件系統只接受讀數據請求,而不接受刪除、修改等變更請求,是一種保護機制,用於保證集群中的數據塊的安全性。 如果 HDFS 處於安全模式下,不允許 HDFS 客戶端進行任何修改文件的操作,包括上傳文件,刪除文件,重命名,創建文件夾,修改副本數等操作。
Yarn
是一個資源管理, 任務調度系統
ResourceManager:所有資源的監控, 分配和管理, 是一個全局的資源管理系統
NodeManager:每一個節點的維護,是每個節點上的資源和任務管理器,它是管理這台機器的代理,負責該節點程式的運行,以及該節點資源的管理和監控
ApplicationMaster:具體每一個應用程式的調度和協調, 分配任務, 用戶提交的每個應用程式均包含一個AppMaster
對於所有的applications, RM擁有絕對的控制權和對資源的分配權. 而每個AM則會和RM協商資源, 同時和NodeManager通訊來執行和監控task.
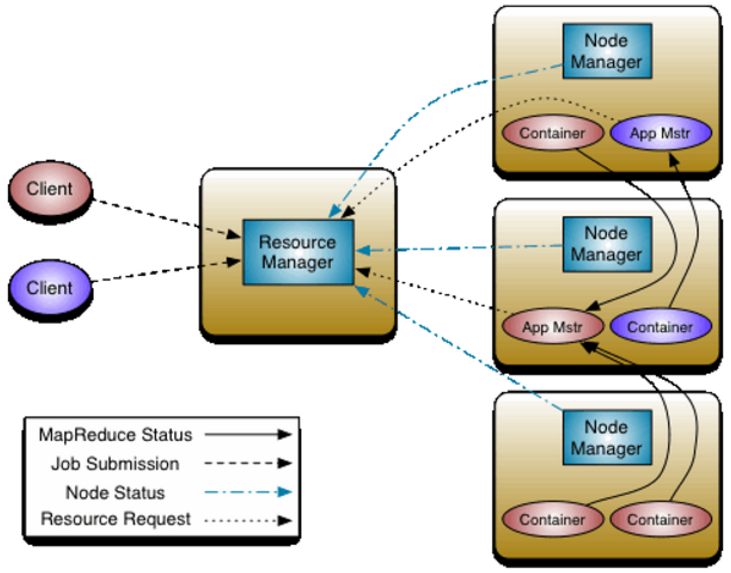
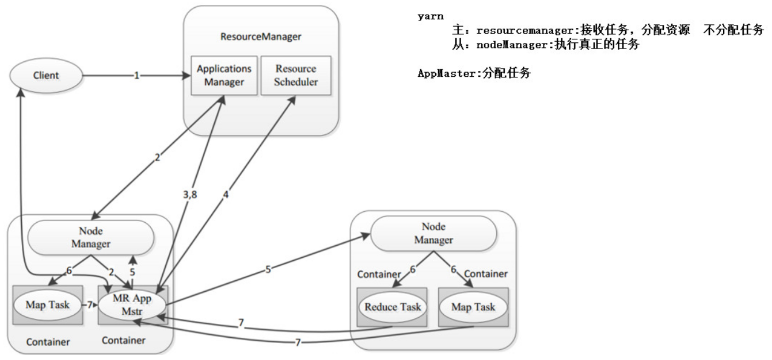
Yarn工作流程
- 客戶端向RM提交程式, 包括AppMaster的必須資訊,例如 ApplicationMaster 程式、啟動 ApplicationMaster 的命令、用戶程式等。
- RM啟動Container用來運行AppMaster
- 啟動中的AppMaster向RM註冊, 啟動完成後與RM保持心跳
- AppMaster向RM申請相應數量的Container
- RM返回AppMaster申請的Container資訊, 由AppMaster對其進行初始化
- AppMaster與NM進行通訊, 要求NM啟動Container, 兩者保持心跳, 從而對NM運行的任務進行管理和監控
- AppMaster對運行中的Container進行監控, Container通過RPC協議對相應的NM彙報資訊
- 客戶端通過AppMaster獲取運行狀態進度等資訊
- 結束後, AppMaster向RM進行註銷, 並回收Container
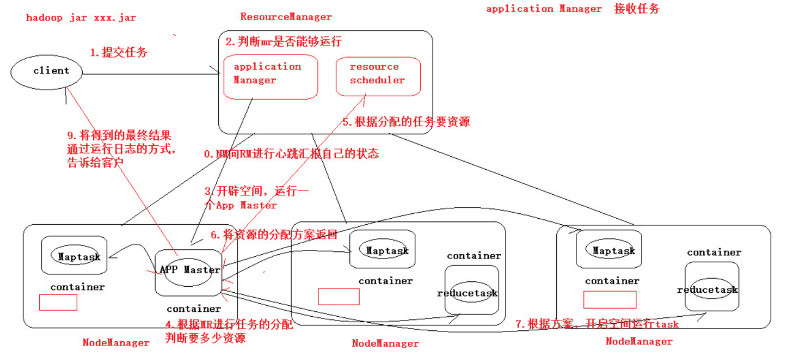
調度器
1)先進先出調度器(企業一定不會):先進先出, 同一個時間隊列只有一個任務執行
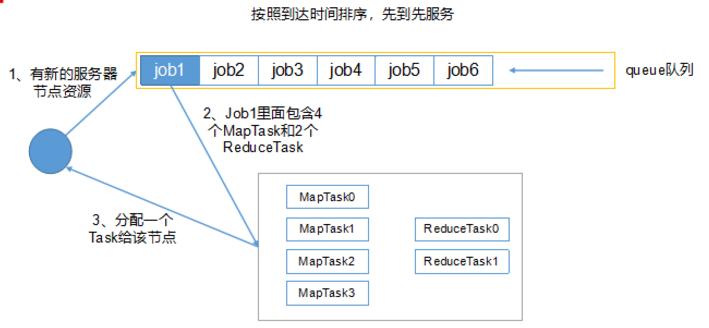
2)容量調度器(Hadoop2.7.2默認調度器):多隊列, 每個隊列內部先進先出, 同一個時間隊列只有一個任務執行, 隊列並行度為隊列個數,
-
- 每個隊列可配置資源
- 對同一用戶提交的作業所佔資源進行限定
- 首先, 計算每個隊列中正在進行的任務與所分得資源的比值, 選出一個值最小的隊列, 也就是最閑的
- 其次, 按照作業優先順序和提交時間順序, 同時考慮用戶資源量限制和記憶體限制, 對隊列中的任務排序
- 隊列同時按照提交任務的順序並行運行

3)公平調度器:多隊列, 每個隊列內部按照缺額大小分配資源啟動任務, 同一時間隊列只有一個任務執行, 隊列並行度大於隊列個數,支援多隊列多用戶, 每個隊列的資源量可以配置, 所以任務共享資源量
-
- 每個隊列的任務按照優先順序分配資源, 優先順序越高資源越多, 但是每個任務都可以分配到資源能保證公平
- 任務理想計算資源與實際計算資源的差值叫做缺額
- 同一隊列中, 缺額越大, 任務優先順序越高, 可多個作業同時運行


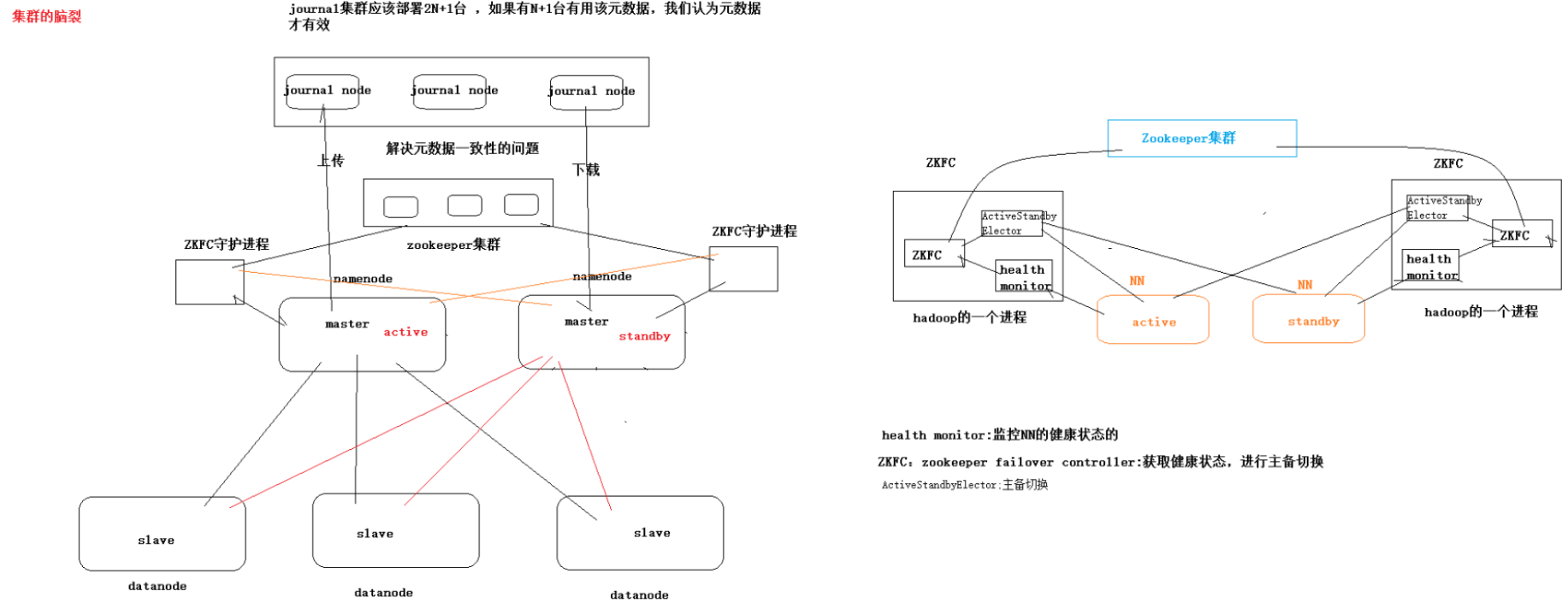
Hadoop High Availability
HA(High Available), 高可用,是保證業務連續性的有效解決方案,一般有兩個或兩個以上的節點,分為活動節點(Active)及備用節點(Standby)。
腦裂
在HA環境中, active的NM出現假死狀態, stanby接收不到active的心跳, 判斷active的NM處於宕機, 但實際上未死亡, stanby轉換為active, 若此時原來active的NM復活, 此時有兩台active的NM, 稱為腦裂
危害
1. 造成資源爭奪
2. 造成數據不統一
Hadoop Federation
聯邦機制就是會有多個NameNode。多個 NameNode 的情況意味著有多個 namespace(命名空間),區別於 HA 模式下的多 NameNode,它們是擁有著同一個 namespace。
概括:
- 多個 NN 共用一個集群里的存儲資源,每個 NN 都可以單獨對外提供服務。
- 每個 NN 都會定義一個存儲池,有單獨的 id,每個 DN 都為所有存儲池提供存儲。
- DN 會按照存儲池 id 向其對應的 NN 彙報塊資訊,同時,DN 會向所有 NN 彙報本地存儲可用資源情況。
缺點
並沒有完全解決單點故障問題。 所以一般集群規模真的很大的時候,會採用 HA+Federation 的部署方案。也就是每個聯合的 namenodes 都是 ha 的。
Hadoop參數調優
- 在hdfs-site.xml文件中配置多目錄,最好提前配置好,否則更改目錄需要重新啟動集群
- NameNode有一個工作執行緒池,用來處理不同DataNode的並發心跳以及客戶端並發的元數據操作。
- dfs.namenode.handler.count=20 * log2(Cluster Size),比如集群規模為10台時,此參數設置為60
- 編輯日誌存儲路徑dfs.namenode.edits.dir設置與鏡像文件存儲路徑dfs.namenode.name.dir盡量分開,達到最低寫入延遲
- 伺服器節點上YARN可使用的物理記憶體總量,默認是8192(MB),注意,如果你的節點記憶體資源不夠8GB,則需要調減小這個值,而YARN不會智慧的探測節點的物理記憶體總量。 yarn.nodemanager.resource.memory-mb
- 單個任務可申請的最多物理記憶體量,默認是8192(MB)。yarn.scheduler.maximum-allocation-mb
Hadoop宕機
- 如果MR造成系統宕機。此時要控制Yarn同時運行的任務數,和每個任務申請的最大記憶體。調整參數:yarn.scheduler.maximum-allocation-mb(單個任務可申請的最多物理記憶體量,默認是8192MB)
- 如果寫入文件過量造成NameNode宕機。那麼調高Kafka的存儲大小,控制從Kafka到HDFS的寫入速度。高峰期的時候用Kafka進行快取,高峰期過去數據同步會自動跟上。
Hadoop基準測試