你知道CPU結構也會影響Redis性能嗎?
啦啦啦,我是賣身不賣藝的二哈,ε=(´ο`*)))唉錯啦(我是開車的二哈),我又來了,鐵子們一起開車呀!
今天來分析下CPU結構對Redis性能會有影響嗎?
在進行Redis性能分析的時候,通常我們會考慮下面這些方面,如:
1. 縮短 key 的長度
2. 禁止使用 keys *
我們都知道 keys *, 在使用的時候 Redis 會處於阻塞狀態,導致其它任何命令在你的 Redis 實例中都無法執行。這個情況在 Redis 數據量大的時候就很明顯,嚴重影響系統的運行。(一般我們用 scan 來代替)
3. 進行數據壓縮
在把數據存入 Redis 中,我們一般不會使用完整全名的數據,一般會進行適當的數據壓縮,這樣可以提高 Redis 性能,方便我們數據的儲存。
4. 設置過期時間
我們對一些不是永久性需要的數據,可以進行鍵的過期時間設置,這樣到時間後,數據就會自動清除,節省我們 Redis 存儲空間(記憶體)。
5. 使用回收策略
為數據設置相關的過期回收策略,節省記憶體的開銷,提高 Redis 運行的性能。( Redis 目前有8種回收策略,有興趣可以查看 redis.conf ,多了LFU)。
6. 適當使用 bit (點陣圖)
適當使用 bit,可節省我們 Redis 存儲的成本,即記憶體的大小。
7. 對所存儲的數據欄位進行優化
如:我們只需要在 Redis 存儲關鍵資訊即可,詳細資訊存儲到磁碟上即可。
8. 使用管道進行數據操作
對於命令執行操作,我們要使用管道 pipeline,這樣可以節省 Redis 傳輸過程的成本,提高 Redis 的性能。我們知道如果不適用管道,命令是一個一個進行操作,如果我們加上管道,這樣由原來的單條命令變成多條命令進行傳輸操作,節省多次傳輸過程的網路開銷。
N …. (還有很多很多~~)
但是,我們可能有時候會真正忽略 Redis 運行的前提條件,單核 CPU 和多核 CPU 對 Redis 性能影響也是相差甚遠。在電腦組成原理中,我們都知道 CPU 是電腦的核心構成之一,中央處理器(Central Processing Unit),是電腦系統的運算和控制中心。一個CPU處理器中一般包含有多個運行核心(物理核),運行核心我們也叫作物理核,一般包含一級快取(L1 Cache)和二級快取(L2 Cache)。其架構圖如下所示:
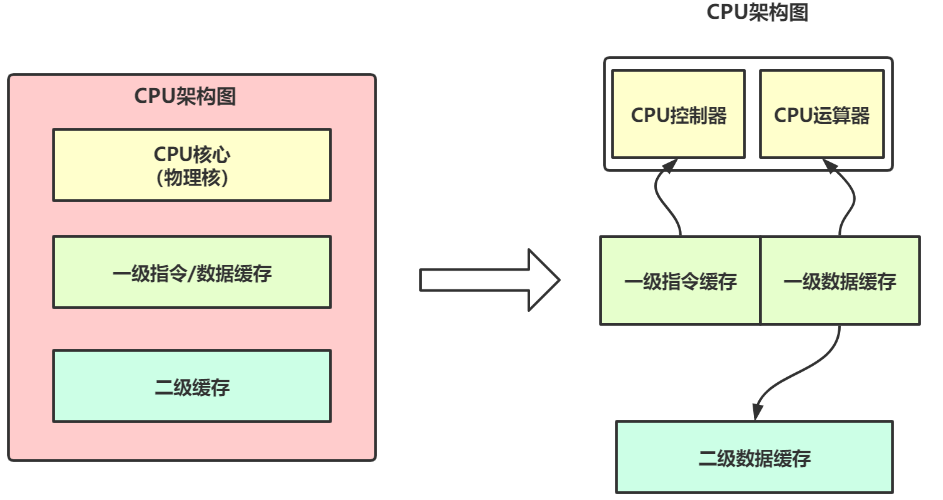
對於 L1 快取和 L2 快取,在每個物理核上都是獨自擁有的,訪問速度非常快,基本都在 ns 級別。我們設想如果把數據運行的指令放在這兩個快取上,那麼可以大大提高電腦的訪問性能。這樣我們可以設想這樣一個情形:
如果,我們把 Redis 實例的數據和指令綁定到一個 CPU 核上,那麼當 Redis 頻繁執行數據訪問和操作時,都是基於CPU 上的快取進行操作,那麼性能是不是大大的提高了,沒錯,事實就是如此。但是,我們電腦一般都是多核 CPU 的,在進行數據訪問和操作時,系統不會只有一個執行緒在進行操作,是有很多很多的執行緒在同時進行操作,會同時操作我們的CPU,也就是我們所說的多執行緒操作CPU。如果一個執行緒此時在CPU1上運行,後來又跑到了CPU2上運行,這時在CPU1上保留的數據和指令不在CPU2,這時要重新進行數據載入,會降低執行緒執行的效率,上述所發生的過程,我們也叫作上下文切換,這在作業系統內核環境下,是很常見的現象。
所以,我們要避免執行緒來回在CPU上進行切換,導致指令和數據進行多次載入,增加鎖處理的時間。我們從CPU結構出發,如果在多核CPU上,如果我們的每個Redis實例都只在一個CPU上運行的話,那麼我們離解決問題的步伐是不是又更近了一步。(問題都是一步一步的剖析,慢慢解開其真容(*╹▽╹*))。
對相關進程進行綁定,我們可以使用 taskset :
taskset 是依據執行緒PID(TID)查詢或設置執行緒的CPU親和性(Affiliation)(與哪個CPU核心綁定)。
如果有夥伴們不知道 taskset 如何使用,沒關係,可以使用 man 或者 help 手冊進行查看相關參數使用( man taskset 或 taskset -h )。在進行綁定的時候,我們要知道自己機器的CPU的核數( cat /proc/cpuinfo ),以方便我們準確的進行CPU綁定,不會說不知道自己CPU核數隨便綁定一個超過自己CPU核數的數。
例子:假如我們要綁定CPU0這個CPU核,那麼命令如下:
taskset -c 0 ./redis-server
這時,我們可以通過 Redis 的壓測工具進行相關測試 redis-benchmark
例如:對 GET 、PUT 和 SET 進行測試:
redis-benchmark -h 127.0.0.1 -p 6379 -c 50 -n 10000 -t get
redis-benchmark -h 127.0.0.1 -p 6379 -c 50 -n 10000 -t put
redis-benchmark -h 127.0.0.1 -p 6379 -c 50 -n 10000 -t set
可以發現Redis實例的性能大大提升。
Redis實例還可以和網路中斷程式綁在 CPU Socket 上,這樣能減小Redis 跨 Socket 訪問記憶體的網路開銷。(在網路傳輸過程中,這也是一個非常值得考慮優化的問題)。
這裡或許會有夥伴會問了(一個cpu物理核內部不是還有邏輯核嗎,我們不應該綁定在邏輯核上嗎?)
這個小夥伴思考的好!別急,我先給你們維基百科(面向搜索引擎)下這些知識點:
- CPU:中央處理單元,記住:CPU不等於物理核,也不等於邏輯核。
- 物理核: 真實的cpu核,可以單獨執行指令,由獨立電路元件實體以及L1、L2快取構成。
- 邏輯核(LCPU):在一個物理核內,邏輯層面的核。(內部物理核通過高速運算誕生的概念)。
- 超執行緒(HT):超執行緒可以在一個邏輯核等待指令執行的間隔(等待從cache或記憶體中獲取下一條指令),把時間片分配到另一個邏輯核。高速在這兩個邏輯核之間切換,讓應用程式感知不到這個間隔,誤認為自己是獨佔了一個核。
注意啦!!這裡裡面的三角關係:
一個CPU可以有多個物理核。但是如果作業系統開啟了超執行緒,一個物理核可以分成 n 個邏輯核,n為超執行緒的數量。(分身)
來讓我們看看單核CPU的草圖:
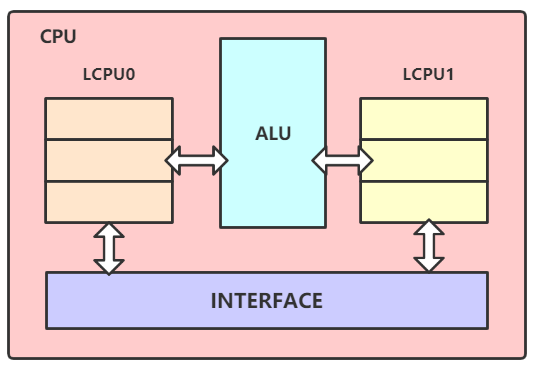
我們可以從上圖看出,一個CPU核內在沒有開啟超執行緒的時候 ,內部是有兩個邏輯核的,但是為什麼我們不把 Redis 實例綁定在其中一個邏輯核上,而是綁定在它們的物理核上呢?把 Redis實例綁定在一個物理核上,可以讓該實例的主進程、子進程、後台執行緒都共享這個物理核內的兩個邏輯核,這樣可以使這些執行緒和進程不必只爭搶一個邏輯核,一定程度上避免的CPU競爭。(因為內部有兩個供他們選擇使用,不會只因為使用一個而來回切換)。
以上這些操作,都是小小的起步,如果我們還需要進一步提升Redis性能,我們需要從源碼程度去解讀Redis,深入研究,在必要時刻我們可以修改Redis的源碼,從根源上尋找適合當前問題最佳扳手。
二哈,今天的分享就到這裡啦~~,下次再見,鐵子們~
如果覺得本文還不錯,記得幫忙三連下,讓更多的夥伴一起上車,啟動我們的二哈旅行車(*^▽^*),Thanks♪(・ω・)ノ。
空間(記憶體)。


