Zookeeper基礎理論
- 2020 年 10 月 9 日
- 筆記
Zookeeper是分散式開源協調服務, 主要用來解決分散式集群中應用系統的一致性問題. 本質上是分散式小文件存儲系統。
特性
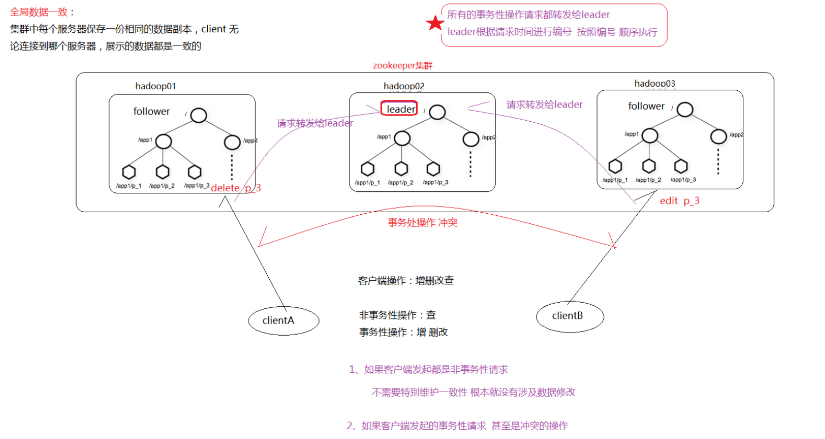
- 全局數據一致性(集群中每個伺服器保存一份相同的數據副本,Client 無論連接到哪個伺服器,展示的數據都是一致的,這是最重要的特徵)

- 可靠性
- 順序性
- 數據更新原子性(要不成功,要不失敗),實時性
集群角色
Leader
Zookeeper 集群工作的核心,事務請求(寫操作)的唯一調度和處理者,保證集群事務處理的順序性; 集群內部各個伺服器的調度者。 對於 create , setData , delete 等有寫操作的請求,則需要統一轉發給leader 處理, leader 需要決定編號、執行操作,這個過程稱為一個事務 。
Follower
處理客戶端非事務(讀操作)請求,轉發事務請求給 Leader,參與集群 Leader 選舉投票。 此外,針對訪問量比較大的 zookeeper 集群,還可新增觀察者角色。
Observer
觀察者角色,觀察 Zookeeper 集群的最新狀態變化並將這些狀態同步過來,其對於非事務請求可以進行獨立處理,對於事務請求,則會轉發給 Leader伺服器進行處理。 不會參與任何形式的投票只提供非事務服務,通常用於在不影響集群事務處理能力的前提下提升集群的非事務處理能力。
集群搭建指的是 ZooKeeper 分散式模式安裝。通常由 2n+1台 servers 組成。這是因為為了保證 Leader 選舉(基於 Paxos 演算法的實現)能過得到多數的支援,所以 ZooKeeper 集群的數量一般為奇數。

數據模型
採用樹形層次結構,每個節點稱為Znode。Znode兼具文件和目錄兩種特點,像文件維護著數據,元資訊等數據結構,又像目錄一樣可以作為路徑標識。Znode具有原子性操作。存儲大小有限制,1M。Znode通過路徑引用。
Znode有兩種
- 臨時節點(不允許擁有子節點,會話結束,自動刪除,也可以手動刪除)
- 永久節點
Znode序列化特效:如果創建的時候指定的話,該 Znode 的名字後面會自動追加一個不斷增加的序列號。序列號對於此節點的父節點來說是唯一的,這樣便會記錄每個子節點創建的先後順序。它的格式為「%10d」(10 位數字,沒有數值的數位用 0 補充,例如「0000000001」),那麼可以分為:
- 永久序列化節點
- 臨時序列化加點
- 永久非序列化節點
- 臨時非序列化節點

Watcher機制
分散式數據訂閱 / 發布功能,Watcher機製為以下三個過程:客戶端向服務端註冊Watcher、服務端事件發生觸發 Watcher、客戶端回調 Watcher 得到觸發事件情況
特點:一次性觸發,事件封裝,非同步發送,先註冊再觸發
其中連接狀態事件(type=None, path=null)不需要客戶端註冊,客戶端只要有需要直接處理就行了。
選舉機制
選舉機制默認的演算法是 FastLeaderElection,採用投票數大於半數則勝出的邏輯(服務ID,選舉狀態,數據ID,邏輯時鐘)
全新集群選舉:給自己投票,有一台超過半數直接成為Leader。
非全新集群選舉 :對於運行正常的 zookeeper 集群,中途有機器 down 掉,需要重新選舉時,選舉過程就需要加入以下
- 數據 ID:數據新的 version 就大,數據每次更新都會更新 version。
- 伺服器 ID:就是我們配置的 myid 中的值,每個機器一個。
- 邏輯時鐘:值從 0 開始遞增,每次選舉對應一個值. 同一次選舉中,這個值是一致的。
這樣選舉的標準就變成:
- 邏輯時鐘小的選舉結果被忽略,重新投票;
- 統一邏輯時鐘後,數據 id 大的勝出;
- 數據 id 相同的情況下,伺服器 id 大的勝出;
獨佔鎖:寫操作,所有客戶端來獲取鎖, 只有一個可以獲得, 使用臨時節點實現,數據對象只對一個事務可見
共享鎖:讀操作,使用臨時節點實現,數據對所有事務都可見
控制時序:所有人都可以得到鎖, 只不過有個順序, 某個節點下的臨時順序子節點實現
Zokeeper適合分散式鎖的原因:每個節點都是天然的順序發號器;節點具有遞增性,可以規定最小的獲得鎖;節點監聽機制,可以保障佔有鎖方式有序且高效。
ZK在分散式集群中的作用