深度解密Go語言之 pprof
- 2019 年 11 月 11 日
- 筆記
相信很多人都聽過「雷神 3」關於性能優化的故事。在一個 3D 遊戲引擎的源碼里,John Carmack 將 1/sqrt(x) 這個函數的執行效率優化到了極致。
一般我們使用二分法,或者牛頓迭代法計算一個浮點數的平方根。但在這個函數里,作者使用了一個「魔數」,根本沒有迭代,兩步就直接算出了平方根。令人嘆為觀止!
因為它是最底層的函數,而遊戲里涉及到大量的這種運算,使得在運算資源極其緊張的 DOS 時代,遊戲也可以流暢地運行。這就是性能優化的魅力!
工作中,當業務量比較小的時候,用的機器也少,體會不到性能優化帶來的收益。而當一個業務使用了幾千台機器的時候,性能優化 20%,那就能省下幾百台機器,一年能省幾百萬。省下來的這些錢,給員工發年終獎,那得多 Happy!
一般而言,性能分析可以從三個層次來考慮:應用層、系統層、程式碼層。
應用層主要是梳理業務方的使用方式,讓他們更合理地使用,在滿足使用方需求的前提下,減少無意義的調用;系統層關注服務的架構,例如增加一層快取;程式碼層則關心函數的執行效率,例如使用效率更高的開方演算法等。
做任何事,都要講究方法。在很多情況下,迅速把事情最關鍵的部分完成,就能拿到絕大部分的收益了。其他的一些邊邊角角,可以慢慢地縫合。一上來就想完成 100%,往往會陷入付出了巨大的努力,卻收穫寥寥的境地。
性能優化這件事也一樣,識別出性能瓶頸,會讓我們付出最小的努力,而得到最大的回報。
Go 語言里,pprof 就是這樣一個工具,幫助我們快速找到性能瓶頸,進而進行有針對性地優化。
什麼是 pprof
程式碼上線前,我們通過壓測可以獲知系統的性能,例如每秒能處理的請求數,平均響應時間,錯誤率等指標。這樣,我們對自己服務的性能算是有個底。
但是壓測是線下的模擬流量,如果到了線上呢?會遇到高並發、大流量,不靠譜的上下游,突發的尖峰流量等等場景,這些都是不可預知的。
線上突然大量報警,介面超時,錯誤數增加,除了看日誌、監控,就是用性能分析工具分析程式的性能,找到瓶頸。當然,一般這種情形不會讓你有機會去分析,降級、限流、回滾才是首先要做的,要先止損嘛。回歸正常之後,通過線上流量回放,或者壓測等手段,製造性能問題,再通過工具來分析系統的瓶頸。
一般而言,性能分析主要關注 CPU、記憶體、磁碟 IO、網路這些指標。
Profiling 是指在程式執行過程中,收集能夠反映程式執行狀態的數據。在軟體工程中,性能分析(performance analysis,也稱為 profiling),是以收集程式運行時資訊為手段研究程式行為的分析方法,是一種動態程式分析的方法。
Go 語言自帶的 pprof 庫就可以分析程式的運行情況,並且提供可視化的功能。它包含兩個相關的庫:
-
runtime/pprof
對於只跑一次的程式,例如每天只跑一次的離線預處理程式,調用 pprof 包提供的函數,手動開啟性能數據採集。 -
net/http/pprof
對於在線服務,對於一個 HTTP Server,訪問 pprof 提供的 HTTP 介面,獲得性能數據。當然,實際上這裡底層也是調用的 runtime/pprof 提供的函數,封裝成介面對外提供網路訪問。
pprof 的作用
pprof 是 Go 語言中分析程式運行性能的工具,它能提供各種性能數據:

allocs 和 heap 取樣的資訊一致,不過前者是所有對象的記憶體分配,而 heap 則是活躍對象的記憶體分配。
The difference between the two is the way the pprof tool reads there at start time. Allocs profile will start pprof in a mode which displays the total number of bytes allocated since the program began (including garbage-collected bytes).
上圖來自參考資料【wolfogre】的一篇 pprof 實戰的文章,提供了一個樣常式序,通過 pprof 來排查、分析、解決性能問題,非常精彩。
- 當 CPU 性能分析啟用後,Go runtime 會每 10ms 就暫停一下,記錄當前運行的 goroutine 的調用堆棧及相關數據。當性能分析數據保存到硬碟後,我們就可以分析程式碼中的熱點了。
- 記憶體性能分析則是在堆(Heap)分配的時候,記錄一下調用堆棧。默認情況下,是每 1000 次分配,取樣一次,這個數值可以改變。棧(Stack)分配 由於會隨時釋放,因此不會被記憶體分析所記錄。由於記憶體分析是取樣方式,並且也因為其記錄的是分配記憶體,而不是使用記憶體。因此使用記憶體性能分析工具來準確判斷程式具體的記憶體使用是比較困難的。
- 阻塞分析是一個很獨特的分析,它有點兒類似於 CPU 性能分析,但是它所記錄的是 goroutine 等待資源所花的時間。阻塞分析對分析程式並發瓶頸非常有幫助,阻塞性能分析可以顯示出什麼時候出現了大批的 goroutine 被阻塞了。阻塞性能分析是特殊的分析工具,在排除 CPU 和記憶體瓶頸前,不應該用它來分析。
pprof 如何使用
我們可以通過
報告生成、Web 可視化介面、互動式終端三種方式來使用pprof。
—— 煎魚《Golang 大殺器之性能剖析 PProf》
runtime/pprof
拿 CPU profiling 舉例,增加兩行程式碼,調用 pprof.StartCPUProfile 啟動 cpu profiling,調用 pprof.StopCPUProfile() 將數據刷到文件里:
import "runtime/pprof" var cpuprofile = flag.String("cpuprofile", "", "write cpu profile to file") func main() { // ………… pprof.StartCPUProfile(f) defer pprof.StopCPUProfile() // ………… }net/http/pprof
啟動一個埠(和正常提供業務服務的埠不同)監聽 pprof 請求:
import _ "net/http/pprof" func initPprofMonitor() error { pPort := global.Conf.MustInt("http_server", "pprofport", 8080) var err error addr := ":" + strconv.Itoa(pPort) go func() { err = http.ListenAndServe(addr, nil) if err != nil { logger.Error("funcRetErr=http.ListenAndServe||err=%s", err.Error()) } }() return err }pprof 包會自動註冊 handler, 處理相關的請求:
// src/net/http/pprof/pprof.go:71 func init() { http.Handle("/debug/pprof/", http.HandlerFunc(Index)) http.Handle("/debug/pprof/cmdline", http.HandlerFunc(Cmdline)) http.Handle("/debug/pprof/profile", http.HandlerFunc(Profile)) http.Handle("/debug/pprof/symbol", http.HandlerFunc(Symbol)) http.Handle("/debug/pprof/trace", http.HandlerFunc(Trace)) }第一個路徑 /debug/pprof/ 下面其實還有 5 個子路徑:
goroutine
threadcreate
heap
block
mutex
啟動服務後,直接在瀏覽器訪問:
就可以得到一個匯總頁面:
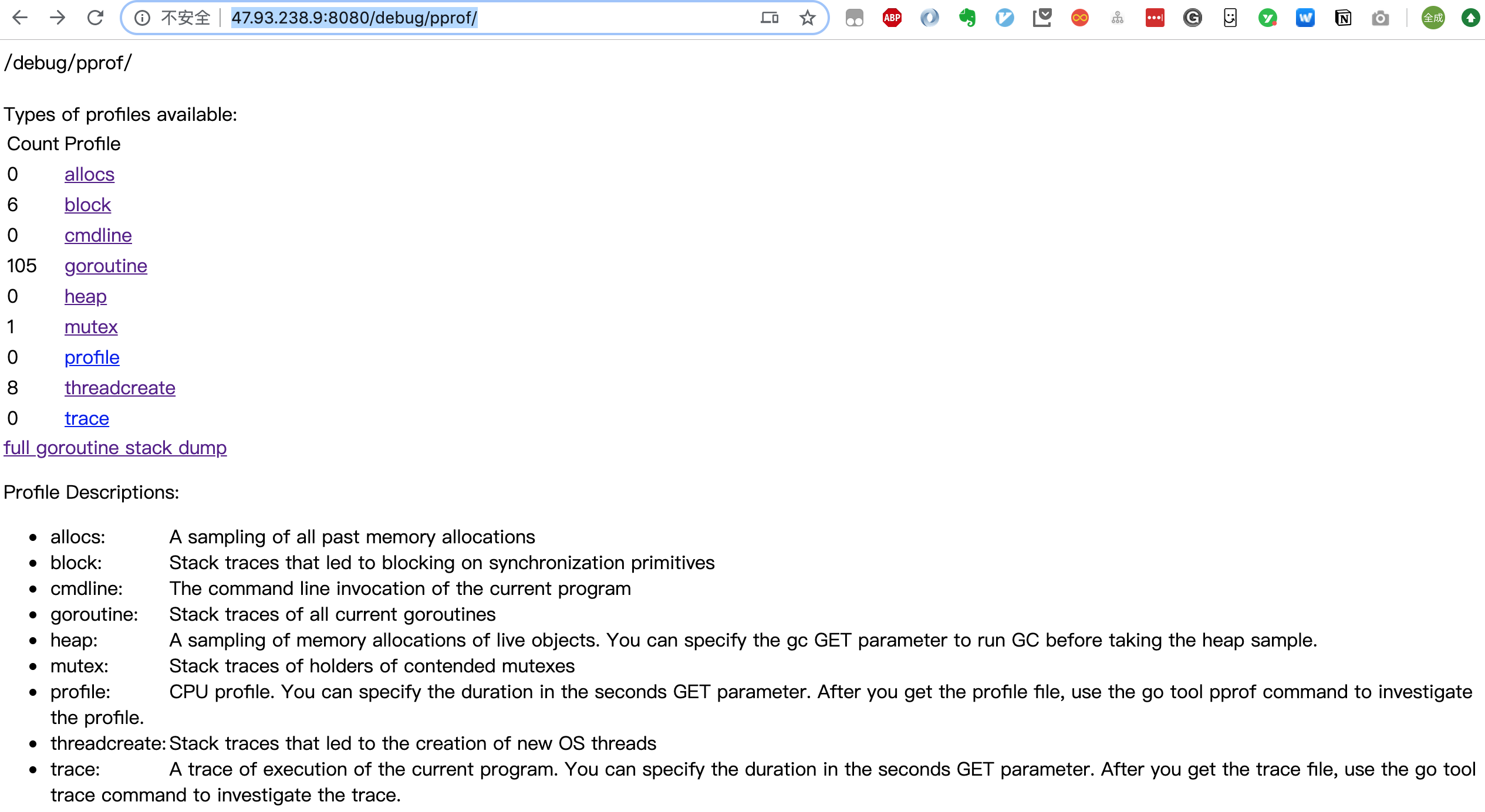
可以直接點擊上面的鏈接,進入子頁面,查看相關的匯總資訊。
關於 goroutine 的資訊有兩個鏈接,goroutine 和 full goroutine stack dump,前者是一個匯總的消息,可以查看 goroutines 的總體情況,後者則可以看到每一個 goroutine 的狀態。頁面具體內容的解讀可以參考【大彬】的文章。
點擊 profile 和 trace 則會在後台進行一段時間的數據取樣,取樣完成後,返回給瀏覽器一個 profile 文件,之後在本地通過 go tool pprof 工具進行分析。
當我們下載得到了 profile 文件後,執行命令:
go tool pprof ~/Downloads/profile
就可以進入命令行互動式使用模式。執行 go tool pprof -help 可以查看幫助資訊。
直接使用如下命令,則不需要通過點擊瀏覽器上的鏈接就能進入命令行交互模式:
go tool pprof http://47.93.238.9:8080/debug/pprof/profile當然也是需要先後台採集一段時間的數據,再將數據文件下載到本地,最後進行分析。上述的 Url 後面還可以帶上時間參數:?seconds=60,自定義 CPU Profiling 的時長。
類似的命令還有:
# 下載 cpu profile,默認從當前開始收集 30s 的 cpu 使用情況,需要等待 30s go tool pprof http://47.93.238.9:8080/debug/pprof/profile # wait 120s go tool pprof http://47.93.238.9:8080/debug/pprof/profile?seconds=120 # 下載 heap profile go tool pprof http://47.93.238.9:8080/debug/pprof/heap # 下載 goroutine profile go tool pprof http://47.93.238.9:8080/debug/pprof/goroutine # 下載 block profile go tool pprof http://47.93.238.9:8080/debug/pprof/block # 下載 mutex profile go tool pprof http://47.93.238.9:8080/debug/pprof/mutex進入互動式模式之後,比較常用的有 top、list、web 等命令。
執行 top:

得到四列數據:
| 列名 | 含義 |
|---|---|
| flat | 本函數的執行耗時 |
| flat% | flat 占 CPU 總時間的比例。程式總耗時 16.22s, Eat 的 16.19s 佔了 99.82% |
| sum% | 前面每一行的 flat 佔比總和 |
| cum | 累計量。指該函數加上該函數調用的函數總耗時 |
| cum% | cum 占 CPU 總時間的比例 |
其他類型,如 heap 的 flat, sum, cum 的意義和上面的類似,只不過計算的東西不同,一個是 CPU 耗時,一個是記憶體大小。
執行 list,使用正則匹配,找到相關的程式碼:
list Eat直接定位到了相關長耗時的程式碼處:
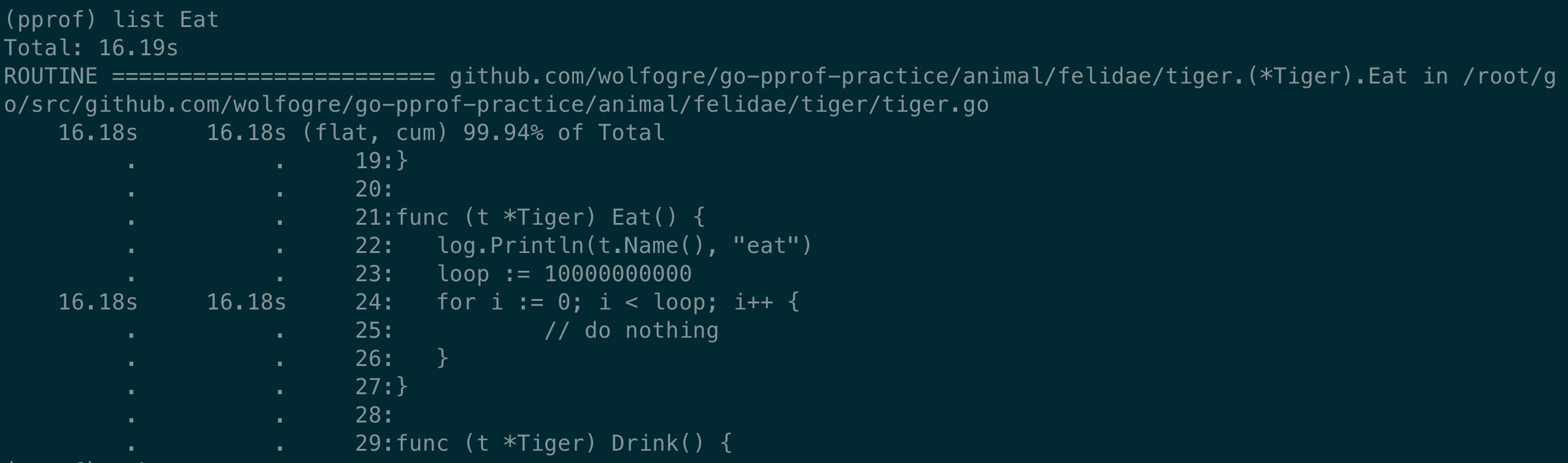
執行 web(需要安裝 graphviz,pprof 能夠藉助 grapgviz 生成程式的調用圖),會生成一個 svg 格式的文件,直接在瀏覽器里打開(可能需要設置一下 .svg 文件格式的默認打開方式):

圖中的連線代表對方法的調用,連線上的標籤代表指定的方法調用的取樣值(例如時間、記憶體分配大小等),方框的大小與方法運行的取樣值的大小有關。
每個方框由兩個標籤組成:在 cpu profile 中,一個是方法運行的時間佔比,一個是它在取樣的堆棧中出現的時間佔比(前者是 flat 時間,後者則是 cumulate 時間佔比);框越大,代表耗時越多或是記憶體分配越多。
另外,traces 命令還可以列出函數的調用棧:

除了上面講到的兩種方式(報告生成、命令行交互),還可以在瀏覽器里進行交互。先生成 profile 文件,再執行命令:
go tool pprof --http=:8080 ~/Downloads/profile進入一個可視化操作介面:
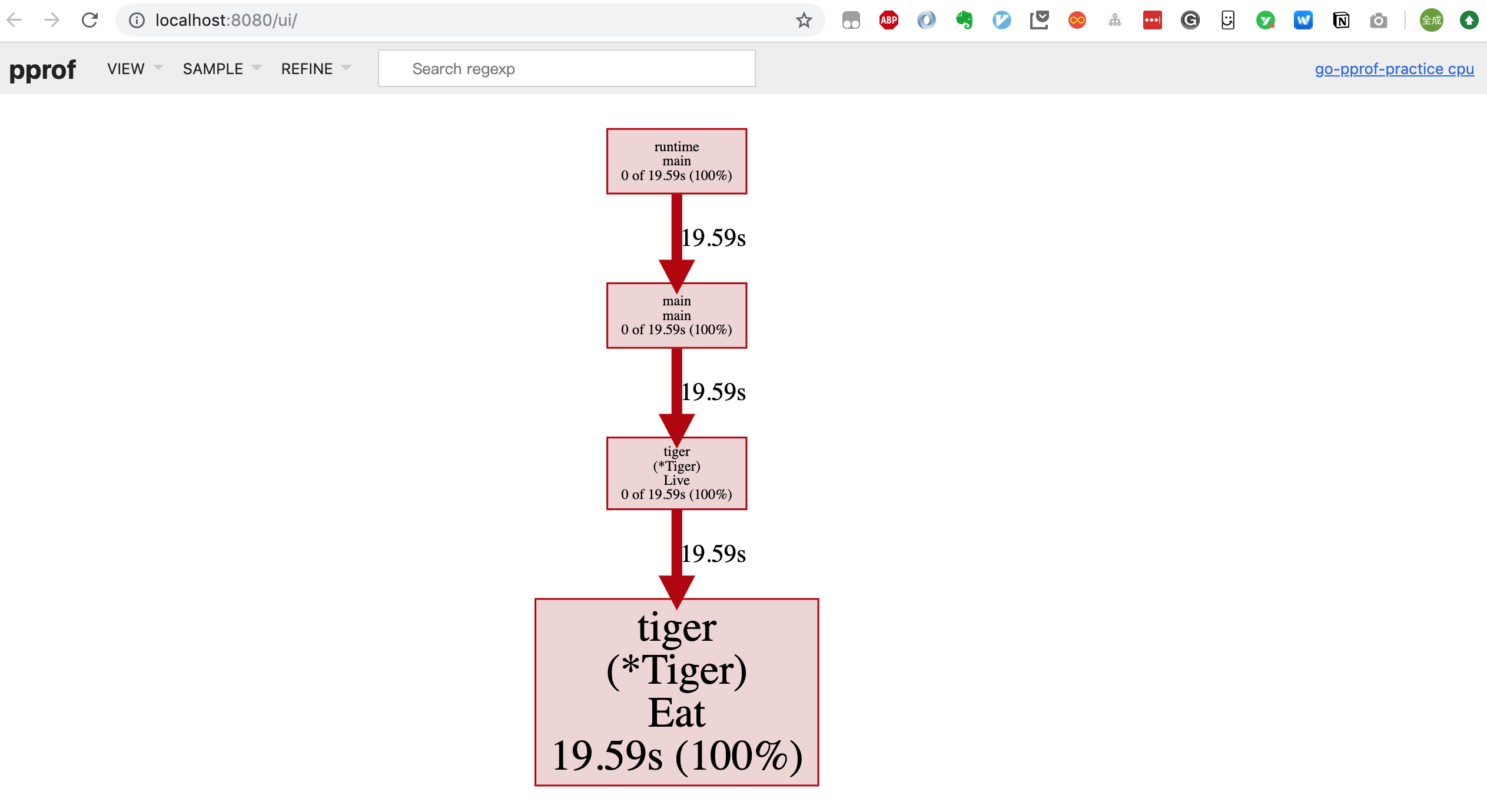
點擊菜單欄可以在:Top/Graph/Peek/Source 之間進行切換,甚至可以看到火焰圖(Flame Graph):
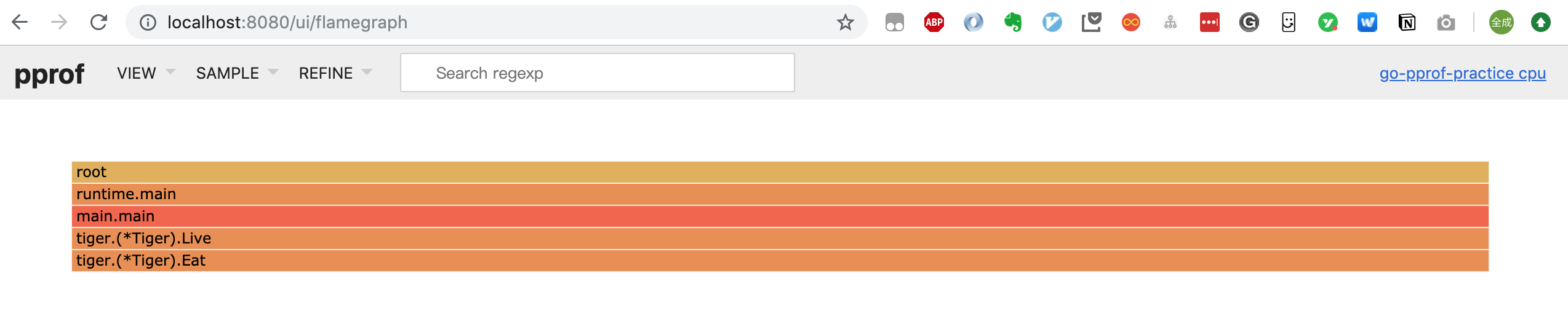
它和一般的火焰圖相比剛好倒過來了,調用關係的展現是從上到下。形狀越長,表示執行時間越長。註:我這裡使用的 go 版本是 1.13,更老一些的版本 pprof 工具不支援 -http 的參數。當然也可以下載其他的庫查看火焰圖,例如:
go get -u github.com/google/pprof 或者 go get github.com/uber/go-torchpprof 進階
我在參考資料部分給出了一些使用 pprof 工具進行性能分析的實戰文章,可以跟著動手實踐一下,之後再用到自己的平時工作中。
Russ Cox 實戰
這部分主要內容來自參考資料【Ross Cox】,學習一下大牛的優化思路。
事情的起因是這樣的,有人發表了一篇文章,用各種語言實現了一個演算法,結果用 go 寫的程式非常慢,而 C++ 則最快。然後 Russ Cox 就鳴不平了,哪受得了這個氣?馬上啟用 pprof 大殺器進行優化。最後,程式不僅更快,而且使用的記憶體更少了!
首先,增加 cpu profiling 的程式碼:
var cpuprofile = flag.String("cpuprofile", "", "write cpu profile to file") func main() { flag.Parse() if *cpuprofile != "" { f, err := os.Create(*cpuprofile) if err != nil { log.Fatal(err) } pprof.StartCPUProfile(f) defer pprof.StopCPUProfile() } ... }使用 pprof 觀察耗時 top5 的函數,發現一個讀 map 的函數耗時最長:mapaccess1_fast64,而它出現在一個遞歸函數中。

一眼就能看到框最大的 mapacess1_fast64 函數。執行 web mapaccess1 命令,更聚焦一些:

調用 mapaccess1_fast64 函數最多的就是 main.FindLoops 和 main.DFS,是時候定位到具體的程式碼了,執行命令:list DFS,定位到相關的程式碼。
優化的方法是將 map 改成 slice,能這樣做的原因當然和 key 的類型是 int 而且不是太稀疏有關。
The take away will be that for smaller data sets, you shouldn』t use maps where slices would suffice, as maps have a large overhead.
修改完之後,再次通過 cpu profiling,發現遞歸函數的耗時已經不在 top5 中了。但是新增了長耗時函數:runtime.mallocgc,佔比 54.2%,而這和分存分配以及垃圾回收相關。
下一步,增加採集記憶體數據的程式碼:
var memprofile = flag.String("memprofile", "", "write memory profile to this file") func main() { // ………… FindHavlakLoops(cfgraph, lsgraph) if *memprofile != "" { f, err := os.Create(*memprofile) if err != nil { log.Fatal(err) } pprof.WriteHeapProfile(f) f.Close() return } // ………… }繼續通過 top5、list 命令找到記憶體分配最多的程式碼位置,發現這回是向 map 里插入元素使用的記憶體比較多。改進方式同樣是用 slice 代替 map,但 map 還有一個特點是可以重複插入元素,因此新寫了一個向 slice 插入元素的函數:
func appendUnique(a []int, x int) []int { for _, y := range a { if x == y { return a } } return append(a, x) }好了,現在程式比最初的時候快了 2.1 倍。再次查看 cpu profile 數據,發現 runtime.mallocgc 降了一些,但仍然佔比 50.9%。
Another way to look at why the system is garbage collecting is to look at the allocations that are causing the collections, the ones that spend most of the time in mallocgc.
因此需要查看垃圾回收到底在回收哪些內容,這些內容就是導致頻繁垃圾回收的「罪魁禍首」。
使用 web mallocgc 命令,將和 mallocgc 相關的函數用矢量圖的方式展現出來,但是有太多樣本量很少的節點影響觀察,增加過濾命令:
go tool pprof --nodefraction=0.1 profile
將少於 10% 的取樣點過濾掉,新的矢量圖可以直觀地看出,FindLoops 觸發了最多的垃圾回收操作。繼續使用命令 list FindLoops 直接找到程式碼的位置。
原來,每次執行 FindLoops 函數時,都要 make 一些臨時變數,這會加重垃圾回收器的負擔。改進方式是增加一個全局變數 cache,可以重複利用。壞處是,現在不是執行緒安全的了。
使用 pprof 工具進行的優化到這就結束了。最後的結果很不錯,基本上能達到和 C++ 同等的速度和同等的記憶體分配大小。
我們能得到的啟發就是先使用 cpu profile 找出耗時最多的函數,進行優化。如果發現 gc 執行比較多的時候,找出記憶體分配最多的程式碼以及引發記憶體分配的函數,進行優化。
原文很精彩,雖然寫作時間比較久遠(最初寫於 2011 年)了,但仍然值得一看。另外,參考資料【wolfogre】的實戰文章也非常精彩,而且用的招式和這篇文章差不多,但是你可以運行文章提供的樣常式序,一步步地解決性能問題,很有意思!
查找記憶體泄露
記憶體分配既可以發生在堆上也可以在棧上。堆上分配的記憶體需要垃圾回收或者手動回收(對於沒有垃圾回收的語言,例如 C++),棧上的記憶體則通常在函數退出後自動釋放。
Go 語言通過逃逸分析會將儘可能多的對象分配到棧上,以使程式可以運行地更快。
這裡說明一下,有兩種記憶體分析策略:一種是當前的(這一次採集)記憶體或對象的分配,稱為 inuse;另一種是從程式運行到現在所有的記憶體分配,不管是否已經被 gc 過了,稱為 alloc。
As mentioned above, there are two main memory analysis strategies with pprof. One is around looking at the current allocations (bytes or object count), called inuse. The other is looking at all the allocated bytes or object count throughout the run-time of the program, called alloc. This means regardless if it was gc-ed, a summation of everything sampled.
加上 -sample_index 參數後,可以切換記憶體分析的類型:
go tool pprof -sample_index=alloc_space http://47.93.238.9:8080/debug/pprof/heap共有 4 種:
| 類型 | 含義 |
|---|---|
| inuse_space | amount of memory allocated and not released yet |
| inuse_objects | amount of objects allocated and not released yet |
| alloc_space | total amount of memory allocated (regardless of released) |
| alloc_objects | total amount of objects allocated (regardless of released) |
參考資料【大彬 實戰記憶體泄露】講述了如何通過類似於 diff 的方式找到前後兩個時刻多出的 goroutine,進而找到 goroutine 泄露的原因,並沒有直接使用 heap 或者 goroutine 的 profile 文件。同樣推薦閱讀!
總結
pprof 是進行 Go 程式性能分析的有力工具,它通過取樣、收集運行中的 Go 程式性能相關的數據,生成 profile 文件。之後,提供三種不同的展現形式,讓我們能更直觀地看到相關的性能數據。
得到性能數據後,可以使用 top、web、list等命令迅速定位到相應的程式碼處,並進行優化。
「過早的優化是萬惡之源」。實際工作中,很少有人會關注性能,但當你寫出的程式存在性能瓶頸,qa 壓測時,qps 上不去,為了展示一下技術實力,還是要通過 pprof 觀察性能瓶頸,進行相應的性能優化。
參考資料
【Russ Cox 優化過程,並附上程式碼】https://blog.golang.org/profiling-go-programs
【google pprof】https://github.com/google/pprof
【使用 pprof 和火焰圖調試 golang 應用】https://cizixs.com/2017/09/11/profiling-golang-program/
【資源合集】https://jvns.ca/blog/2017/09/24/profiling-go-with-pprof/
【Profiling your Golang app in 3 steps】https://coder.today/tech/2018-11-10_profiling-your-golang-app-in-3-steps/
【案例,壓測 Golang remote profiling and flamegraphs】https://matoski.com/article/golang-profiling-flamegraphs/
【煎魚 pprof】https://segmentfault.com/a/1190000016412013
【鳥窩 pprof】https://colobu.com/2017/03/02/a-short-survey-of-golang-pprof/
【關於 Go 的 7 種性能分析方法】https://blog.lab99.org/post/golang-2017-10-20-video-seven-ways-to-profile-go-apps.html
【pprof 比較全】https://juejin.im/entry/5ac9cf3a518825556534c76e
【通過實例來講解分析、優化過程】https://artem.krylysov.com/blog/2017/03/13/profiling-and-optimizing-go-web-applications/
【Go 作者 Dmitry Vyukov】https://github.com/golang/go/wiki/Performance
【wolfogre 非常精彩的實戰文章】https://blog.wolfogre.com/posts/go-ppof-practice/
【dave.cheney】https://dave.cheney.net/high-performance-go-workshop/dotgo-paris.html
【實戰案例】https://www.cnblogs.com/sunsky303/p/11058808.html
【大彬 實戰記憶體泄露】https://segmentfault.com/a/1190000019222661
【雷神 3 性能優化】https://diducoder.com/sotry-about-sqrt.html