如何用5000行JS擼一個關係型資料庫
首先聲明,我不是標題黨,我真的是用5000行左右的JS實現了一個輕量級的關係型資料庫JSDB,核心是一個SQL編譯器,支援增刪改查。
源程式碼放到github上了://github.com/lavezhang/jsdb
如果你需要修改程式引入新的特性,請嚴格遵守GPL協議。
如果轉發此文,請註明來源。

前言
工作太忙,好久沒寫這種長文章了,難得今年國慶超長,又不便外出,這才有時間「不務正業」。
為什麼要用一周的時間寫這麼個玩意兒?看起來也沒什麼用處,畢竟,沒有哪個系統需要在瀏覽器中跑一個關係型資料庫。
如果要搞一個”年度最無用項目”的頒獎,估計JSDB榜上有名。
我一直有一個夢想,要研發一款咱們中國人自己的列式存儲分散式資料庫!(此處應有掌聲^_^)
古人講,不積跬步無以至千里,JSDB就算探索資料庫自研的一個開端吧。
為什麼用TypeScript?因為coding效率非常高,跟Python差不多,而且有瀏覽器就能運行,非常方便,很適合做技術預研,正式開發時再改為C或Rust。
如文章開頭所言,JSDB的核心是一個SQL編譯器,準確地說,是解釋器。學習過《編譯原理》的同學,對這個不會陌生。
解釋器也是屬於編譯器的範疇,所以,後面仍然會沿用「SQL編譯器」的說法。
概述
按照執行順序,JSDB的程式碼由四個部分構成:
1、詞法分析,得到 token 列表。參見GitHub源程式碼,SqlLexer.ts 文件,基於狀態機實現,詳見 lex_state_flow.xlsx 文件。
2、語法語義分析,得到抽象語法數。參見 SqlParser.ts 文件,自上而下解析,這是行數最多的一個文件。
3、對抽象語法樹的執行。參見SqlDatabase.ts文件,以及ast目錄下的幾十個語法節點的compute(ctx)方法。
4、單元測試和應用範例。test目錄和test.html文件里運行著所有的單元測試,index.html文件就是文章開頭的體驗頁面,語法高亮功能基於第三方組件codemirror實現,在 static/codemirror 目錄里。
JSDB確實是一個關係型資料庫,參照SQL92標準實現,但它並不完整,只實現了最核心的一小部分功能,可以滿足日常基本需求。主要特性有:
01、create table 語句
02、insert 語句
03、update 語句
04、delete 語句
05、select 語句,含:distinct / from / join / left join / where / group by / having / order by / limit
06、算數運算符:+、-、*、/、%
07、關係運算符:>、>=、<、<=、=、<>
08、條件運算符:and、or、not
09、其它操作符:like、not like、is null、is not null、between
10、動態佔位符:?
11、標準函數,目前只實現了:ifnull、len、substr、substring、instr、concat。
如果需要增加新的標準函數,可以在SqlContext類的構造函數中實現,所有的標準函數都註冊到SqlContext.standardFunctions欄位中。
尚未實現的重要特性有:
1、with / sub query / exists / alter / truncate 等
2、數據存儲。一直在記憶體中運行,大家可以修改程式,寫入瀏覽器localStorage中。
3、事務。這個需要事務日誌來實現,以後再搞,不過在記憶體中模擬一個,問題也不大。
4、並發鎖。JS是單執行緒,沒有真正的並發,有了一個不用實現它的好理由。
5、其它功能。詳見大學時的《資料庫原理》。
如果大家多多點贊,我就把它實現得更加完整。^_^
本文針對編譯器和資料庫的入門讀者,寫了很多小白的內容,高手請飄過。
第一章 詞法分析
關於詞法分析,程式本身並不難。無論何種程式語言,它的詞法分析模組一般都不超過300行,有些甚至只有幾十行。
很多人喜歡用 lex/yacc/antr 之類的工具來自動生成,我不喜歡,我就是喜歡手擼的感覺。
詞法分析就是要識別源程式碼中的一個個token,一般包括:關鍵字、標識符、字元串、數值、布爾值、空值、運算符、操作符、分隔符。
例如,一條SQL語句:
select name, (total_score / 4) as avg_score from student where id = '010123'
涉及如下token:
關鍵字:select、as、from、where
標識符:name、total_score、avg_score、student、id
字元串:’010123′
數值:4
運算符:/、=
分隔符:, ( )
如何識別這些token呢?兩種辦法:硬實現、狀態機。
硬實現,就是用一大坨的 if/else 識別每一個字元。
舉例來說,如果當前字元是一個單引號,程式就認為是一個字元串的開始,於是用一個while循環來判斷,直到遇到另一個單引號,表示字元串的結束。
硬實現的最大問題在於,條件分支太多,很容易遺漏或判斷錯誤。
比如,字元串中是要處理轉義符的,遇到換行符則要記錄錯誤。
再比如,’>=’ 和 ‘> =’ 是不一樣的,前者表示大於等於號,後者表示兩個運算符:大於號和等於號,因為中間有個空格,而硬寫的程式往往會忽略掉這些空白符,什麼時候空白符該忽略,什麼時候不該忽略,必須把規則一條條列出來,針對處理。
類似的情況還非常多,所以,硬寫出來的詞法分析程式,無一例外,都是非常複雜的。
給大家看一段用 java 硬實現的字元串識別程式:
if (c == '\'') { while (pos < len) { c = source.charAt(pos++); if (c == '\\') { c = source.charAt(pos++); if (c == 'n') { buf.append('\n'); } else if (c == 'r') { buf.append('\r'); } else if (c == 't') { buf.append('\t'); } else { buf.append(c); } } else if (c == '\'') { return addToken(buf.toString(), SqlConstants.STRING, line); } else { buf.append(c); } } }
上述java程式是我很久之前寫的,整個詞法程式漏洞百出。
即使是硬實現,也要提前梳理各種轉換關係,既然這樣,為什麼不用狀態機呢?
狀態機是老一輩電腦科學家發明的理論,基於狀態機和BNF產生式,詞法分析程式完全可以被形式化了。
一個字元串識別的狀態機範例如下:
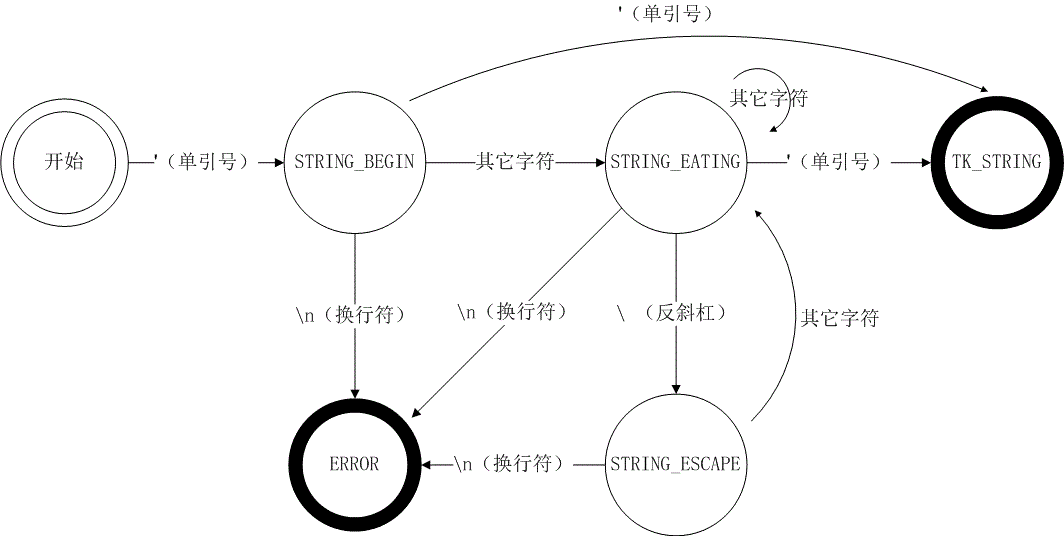
一個字元串就涉及4個狀態,完整的SQL詞法涉及幾十個狀態,如果都用狀態流轉圖畫出來,實在太複雜,所以,一般都改用等價的表格來表示。
我在github上放了一個叫 lex_state_flow.xlsx 的Excel文件,截圖如下:
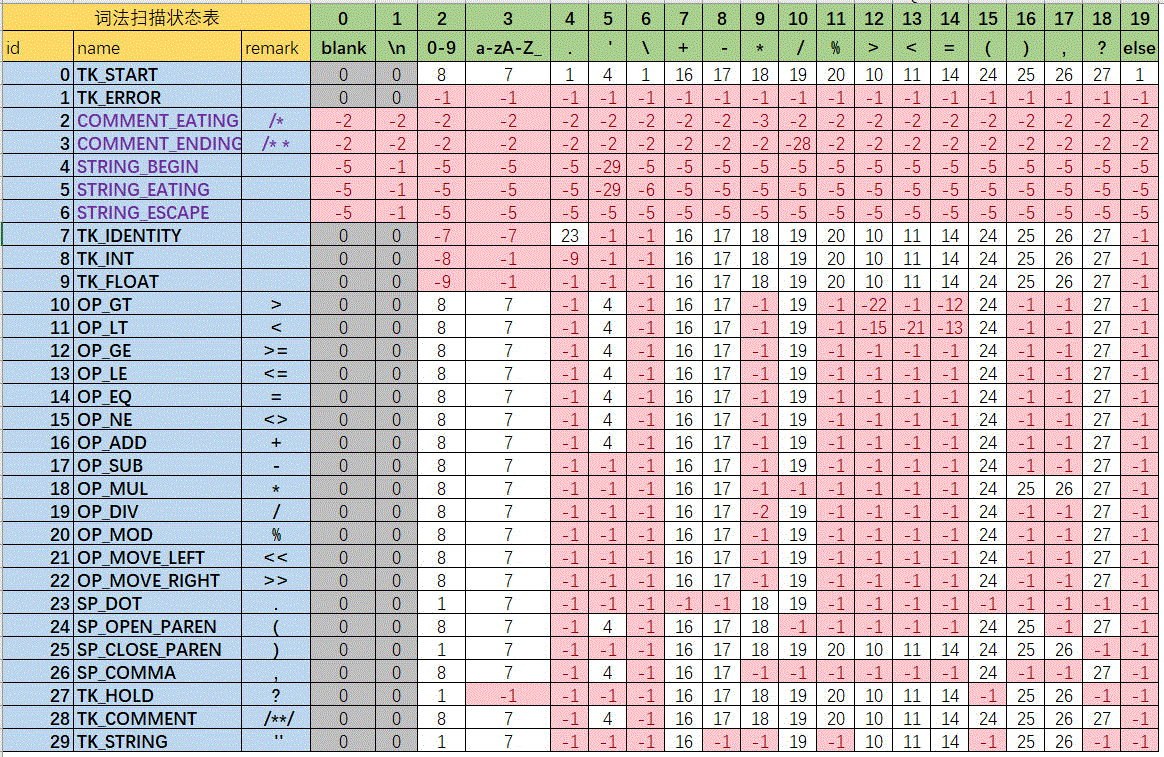
需要特別解釋兩點:
1、狀態2到狀態6的名字用紫色標記,因為這幾個狀態是中間狀態,最終不能獨立存在。
2、狀態轉換的單元格有三種顏色:灰色、白色、紅色。
灰色表示回到初始狀態;
白色表示正數狀態,轉換狀態時,前面的快取內容作為一個token,當前新字元進入新的狀態;比如,當前狀態是 TK_IDENTITY,這時輸入一個字元 ‘>’,則緩衝區的內容得到一個標識符token,新輸入的 ‘>’ 字元進入 TK_GT 狀態。
紅色表示負數狀態,轉換狀態時,前面的內容加上當前字元一起進入新的狀態。比如,當前狀態是 TK_GT,這時輸入一個字元 『=』,則緩衝區的內容 ‘>’ 加上新輸入的 ‘=’,得到 ‘>=’ ,進入新的狀態 TK_GE,表示大於等於。
詞法分析的核心,正是這個狀態表格。要完成這樣一張表格,看著容易,實際並不容易,我也是花了一天時間。因為一旦遺漏了某個狀態或輸入字元,整個表格都要改一遍,擼得手都起繭子了。
完成狀態表格後,基於此實現的詞法掃描程式,就可以非常簡單了。文件名為 SqlLexer.ts,程式碼如下:
const TK_START = 0; //起始 const TK_ERROR = 1; //錯誤 const TK_IDENTITY = 7; //標識符(下劃線當作字母處理) const TK_INT = 8; //整數(不支援科學計數法) const TK_FLOAT = 9; //浮點數(不支援科學計數法) const TK_GT = 10; //操作符:大於 > const TK_LT = 11; //操作符:小於 < const TK_GE = 12; //操作符:大於等於 >= const TK_LE = 13; //操作符:小於等於 <= const TK_EQ = 14; //操作符:等於 = const TK_NE = 15; //操作符:不等於 <> const TK_ADD = 16; //操作符:加 + const TK_SUB = 17; //操作符:減 - const TK_MUL = 18; //操作符:乘 * const TK_DIV = 19; //操作符:除 / const TK_MOD = 20; //操作符:模(取余) % const TK_MOVE_LEFT = 21; //操作符:左移 << const TK_MOVE_RIGHT = 22; //操作符:右移 >> const TK_DOT = 23; //分隔符:點 . const TK_OPEN_PAREN = 24; //分隔符:左圓括弧 ( const TK_CLOSE_PAREN = 25; //分隔符:右圓括弧 ) const TK_COMMA = 26; //分隔符:逗號 , const TK_HOLD = 27; //佔位符 ? const TK_COMMENT = 28; //注釋 /**/ const TK_STRING = 29; //字元串 'abc' const TK_SELECT = 50; //關鍵字:select const TK_FROM = 51; //關鍵字:from const TK_WHERE = 52; //關鍵字:where const TK_AS = 53; //關鍵字:as const TK_DISTINCT = 54; //關鍵字:distinct const TK_LEFT = 55; //關鍵字:left const TK_JOIN = 56; //關鍵字:join const TK_ON = 57; //關鍵字:on const TK_CASE = 58; //關鍵字:case const TK_WHEN = 59; //關鍵字:when const TK_THEN = 60; //關鍵字:then const TK_ELSE = 61; //關鍵字:else const TK_END = 62; //關鍵字:end const TK_IS = 63; //關鍵字:is const TK_NOT = 64; //關鍵字:not const TK_NULL = 65; //關鍵字:null const TK_TRUE = 66; //關鍵字:true const TK_FALSE = 67; //關鍵字:false const TK_AND = 68; //關鍵字:and const TK_OR = 69; //關鍵字:or const TK_BETWEEN = 70; //關鍵字:between const TK_IN = 71; //關鍵字:in const TK_LIKE = 72; //關鍵字:like const TK_GROUP = 73; //關鍵字:group const TK_BY = 74; //關鍵字:by const TK_HAVING = 75; //關鍵字:having const TK_ORDER = 76; //關鍵字:order const TK_ASC = 77; //關鍵字:asc const TK_DESC = 78; //關鍵字:desc const TK_LIMIT = 79; //關鍵字:limit const TK_INSERT = 80; //關鍵字:insert const TK_INTO = 81;//關鍵字:into const TK_VALUES = 82;//關鍵字:values const TK_UPDATE = 83;//關鍵字:update const TK_SET = 84;//關鍵字:set const TK_DELETE = 85;//關鍵字:delete const TK_CREATE = 86;//關鍵字:create const TK_TABLE = 87;//關鍵字:table /** * 詞法狀態流轉圖。 * 詳見:lex_state_flow.xlsx 文件。 */ const STATE_FLOW_TABLE = [ [0, 0, 8, 7, 1, 4, 1, 16, 17, 18, 19, 20, 10, 11, 14, 24, 25, 26, 27, 1], [0, 0, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1], [-2, -2, -2, -2, -2, -2, -2, -2, -2, -3, -2, -2, -2, -2, -2, -2, -2, -2, -2, -2], [-2, -2, -2, -2, -2, -2, -2, -2, -2, -2, -28, -2, -2, -2, -2, -2, -2, -2, -2, -2], [-5, -1, -5, -5, -5, -29, -5, -5, -5, -5, -5, -5, -5, -5, -5, -5, -5, -5, -5, -5], [-5, -1, -5, -5, -5, -29, -6, -5, -5, -5, -5, -5, -5, -5, -5, -5, -5, -5, -5, -5], [-5, -1, -5, -5, -5, -5, -5, -5, -5, -5, -5, -5, -5, -5, -5, -5, -5, -5, -5, -5], [0, 0, -7, -7, 23, -1, -1, 16, 17, 18, 19, 20, 10, 11, 14, 24, 25, 26, 27, -1], [0, 0, -8, -1, -9, -1, -1, 16, 17, 18, 19, 20, 10, 11, 14, 24, 25, 26, 27, -1], [0, 0, -9, -1, -1, -1, -1, 16, 17, 18, 19, 20, 10, 11, 14, 24, 25, 26, 27, -1], [0, 0, 8, 7, -1, 4, -1, 16, 17, -1, 19, -1, -22, -1, -12, 24, -1, -1, 27, -1], [0, 0, 8, 7, -1, 4, -1, 16, 17, -1, 19, -1, -15, -21, -13, 24, -1, -1, 27, -1], [0, 0, 8, 7, -1, 4, -1, 16, 17, -1, 19, -1, -1, -1, -1, 24, -1, -1, 27, -1], [0, 0, 8, 7, -1, 4, -1, 16, 17, -1, 19, -1, -1, -1, -1, 24, -1, -1, 27, -1], [0, 0, 8, 7, -1, 4, -1, 16, 17, -1, 19, -1, -1, -1, -1, 24, -1, -1, 27, -1], [0, 0, 8, 7, -1, 4, -1, 16, 17, -1, 19, -1, -1, -1, -1, 24, -1, -1, 27, -1], [0, 0, 8, 7, -1, 4, -1, 16, 17, -1, 19, -1, -1, -1, -1, 24, -1, -1, 27, -1], [0, 0, 8, 7, -1, -1, -1, 16, 17, -1, 19, -1, -1, -1, -1, 24, -1, -1, 27, -1], [0, 0, 8, 7, -1, -1, -1, 16, 17, -1, -1, -1, -1, -1, -1, 24, 25, 26, 27, -1], [0, 0, 8, 7, -1, -1, -1, 16, 17, -2, 19, -1, -1, -1, -1, 24, -1, -1, 27, -1], [0, 0, 8, 7, -1, -1, -1, 16, 17, -1, 19, -1, -1, -1, -1, 24, -1, -1, 27, -1], [0, 0, 8, 7, -1, -1, -1, 16, 17, -1, 19, -1, -1, -1, -1, 24, -1, -1, 27, -1], [0, 0, 8, 7, -1, -1, -1, 16, 17, -1, 19, -1, -1, -1, -1, 24, -1, -1, 27, -1], [0, 0, 1, 7, -1, -1, -1, -1, -1, 18, 19, -1, -1, -1, -1, -1, -1, -1, -1, -1], [0, 0, 8, 7, -1, 4, -1, 16, 17, 18, -1, -1, -1, -1, -1, 24, 25, -1, 27, -1], [0, 0, 1, 7, -1, -1, -1, 16, 17, 18, 19, 20, 10, 11, 14, 24, 25, 26, -1, -1], [0, 0, 8, 7, -1, 4, -1, 16, 17, -1, -1, -1, -1, -1, -1, 24, -1, -1, 27, -1], [0, 0, 1, -1, -1, -1, -1, 16, 17, 18, 19, 20, 10, 11, 14, -1, 25, 26, -1, -1], [0, 0, 8, 7, -1, 4, -1, 16, 17, 18, 19, 20, 10, 11, 14, 24, 25, 26, 27, -1], [0, 0, 1, 7, -1, -1, -1, 16, -1, -1, 19, -1, 10, 11, 14, -1, 25, 26, -1, -1] ]; /** * SQL詞法分析類。 */ class SqlLexer { /** * 掃描指定的SQL語句,返回所有單詞。 * 用一個元組來表示單詞的三個欄位:類型(狀態)、內容、行號(從1開始)。 * @param sql 要掃描的SQL語句。 */ public scan(sql: string): Array<[number, string, number]> { let tokens = new Array<[number, string, number]>(); let pos = 0; let len = sql.length; let buf = ''; let c = ''; let j = 0; let state = TK_START; let beginLine = 1; let totalLine = 1; while (pos < len) { c = sql[pos++]; if (c == ' ' || c == '\t' || c == '\r') { j = 0; } else if (c == '\n') { j = 1; } else if (c >= '0' && c <= '9') { j = 2; } else if ((c >= 'a' && c <= 'z') || (c >= 'A' && c <= 'Z') || c == '_') { j = 3; } else if (c == '.') { j = 4; } else if (c == '\'') { j = 5; } else if (c == '\\') { j = 6; } else if (c == '+') { j = 7; } else if (c == '-') { j = 8; } else if (c == '*') { j = 9; } else if (c == '/') { j = 10; } else if (c == '%') { j = 11; } else if (c == '>') { j = 12; } else if (c == '<') { j = 13; } else if (c == '=') { j = 14; } else if (c == '(') { j = 15; } else if (c == ')') { j = 16; } else if (c == ',') { j = 17; } else if (c == '?') { j = 18; } else { j = 19; } //如果新狀態的值小於0,表示帶著當前快取區的內容,直接轉換到新的狀態; //如果新狀態的值大於等於0,則用當前緩衝區的內容構造一個舊狀態的單詞,然後從當前字元開始進入新的狀態。 let nextState = STATE_FLOW_TABLE[state][j]; if (nextState < 0) { buf += c; } else { let token = this.newToken(state, buf, beginLine); if (token) { tokens.push(token); beginLine = totalLine; } buf = j > 1 ? c : ''; if (c == '\n') { beginLine++; } } state = Math.abs(nextState); //處理最後一個單詞 if (pos >= len) { let token = this.newToken(state, buf, beginLine); if (token) { tokens.push(token); beginLine = totalLine; } } else if (c == '\n') { totalLine++; } } return tokens; } private newToken(state: number, value: string, line: number): [number, string, number] { if (value.length <= 0) { return null; } if (state == TK_IDENTITY) { value = value.toLowerCase(); switch (value) { case 'select': state = TK_SELECT; break; case 'from': state = TK_FROM; break; case 'where': state = TK_WHERE; break; case 'as': state = TK_AS; break; case 'distinct': state = TK_DISTINCT; break; case 'left': state = TK_LEFT; break; case 'join': state = TK_JOIN; break; case 'on': state = TK_ON; break; case 'case': state = TK_CASE; break; case 'when': state = TK_WHEN; break; case 'then': state = TK_THEN; break; case 'else': state = TK_ELSE; break; case 'end': state = TK_END; break; case 'is': state = TK_IS; break; case 'not': state = TK_NOT; break; case 'null': state = TK_NULL; break; case 'true': state = TK_TRUE; break; case 'false': state = TK_FALSE; break; case 'and': state = TK_AND; break; case 'or': state = TK_OR; break; case 'between': state = TK_BETWEEN; break; case 'in': state = TK_IN; break; case 'like': state = TK_LIKE; break; case 'group': state = TK_GROUP; break; case 'by': state = TK_BY; break; case 'having': state = TK_HAVING; break; case 'order': state = TK_ORDER; break; case 'asc': state = TK_ASC; break; case 'desc': state = TK_DESC; break; case 'limit': state = TK_LIMIT; break; case 'insert': state = TK_INSERT; break; case 'into': state = TK_INTO; break; case 'values': state = TK_VALUES; break; case 'update': state = TK_UPDATE; break; case 'set': state = TK_SET; break; case 'delete': state = TK_DELETE; break; case 'create': state = TK_CREATE; break; case 'table': state = TK_TABLE; break; default: break; } } else if (state > TK_ERROR && state < TK_IDENTITY) {//無效字元 state = TK_ERROR; } return [state, value, line]; } }
細心的同學可能會發現,程式碼里的關鍵字狀態,並沒有出現在狀態表格中。
原則上來講,每個關鍵字都是一個單獨的狀態。但是,如果都列入狀態表格,這個表格就超級複雜了。比如,為了識別一個關鍵字select,要依次檢查連續字元 『s』 ‘e’ ‘l’ ‘e’ ‘c’ ‘t’ ,即使到了最後一個字元 ‘t’ ,也不意味著結束,後面跟上一個數字 ‘1’,立馬就不是關鍵字了,而是一個普通的標識符 select1。而JSDEB一共支援38個關鍵字,都要併入表格,簡直難以想像。所以,通常的做法是,先統一作為標識符來識別,完成一個token時,再進一步判斷是否為某個關鍵字,而在狀態表格中就不畫了。
一個token用一個三元組來表達,在TypeScript中是Tuple類型,實際就是JavaScript中的數組。這裡有三個值,分別是number、string、number類型。
第0個值,number類型,表示token的類型,對應於狀態表格中的狀態id;
第1個值,string類型,表示token的內容,對於字元串 ‘abc’ 來說,存的不是 abc,而是 ‘abc’,也就是說,原原本本保存,後面在執行的時候才會翻譯為 abc;
第2個值,number類型,表示token所在的行號,提示詞法錯誤的時候,可以明確告知在哪一行。
有的同學可能會問,為什麼不用一個class來表示。其實也可以用class表示,但是,掃描一段源程式碼,得到的token非常多,如果用class表示,會浪費更多的資源,不如用數組,返璞歸真,簡單實用。
用一組單元測試來驗證程式是否正確。
程式碼中的Assert類是一個簡單的斷言類,用於單元測試中的條件檢查。
/test/SqlLexerTest.ts 文件包含了所有詞法掃描的測試用例。截取一段程式碼如下:
Assert.runCase('scan identity', function () { let lexer = new SqlLexer(); let tokens = lexer.scan('id _name'); Assert.isEqual(tokens.length, 2); Assert.isEqual(tokens[0], [TK_IDENTITY, 'id', 1]); Assert.isEqual(tokens[1], [TK_IDENTITY, '_name', 1]); });
到這裡詞法分析就結束了,得到一個token列表,接下來,會對這個token列表進行掃描,也就是語法解析。
第二章 語法解析
語法解析也叫語法分析,讀入token列表,輸出抽象語法樹。
在編譯器設計中,以抽象語法樹的形式構造一條SQL語句。例如SQL:
SELECT id, t.stf_name AS name FROM student t WHERE id = 123
會被解析成如下樹結構:
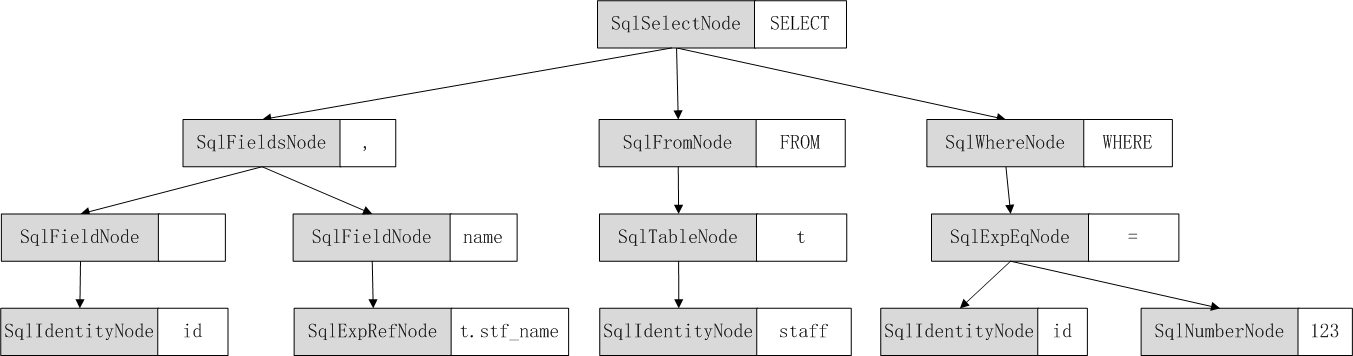
自上而下,遞歸解析,識別出每一個節點。
每種語法節點都是一個單獨的class,比如,SqlSelectNode、SqlFromNode、SqlWhereNode、SqlIdentityNode、StringNumberNode,等等。
數量有點多,一共39個。這39個類都是繼承自語法節點基類SqlNode。
/** * SQL語法節點基類。 */ class SqlNode { /** * 構造函數。 * @param parent 父節點。 * @param value 節點值 * @param line 所在行號(從1開始)。 */ protected constructor(parent: SqlNode, value: string, line: number) { this.parent = parent; if (parent) { parent.nodes.push(this); } this.value = value; this.line = line; this.nodes = []; } public value: string; public line: number; public parent: SqlNode; public nodes: Array<SqlNode>; /** * 類型推導。 * @param ctx 上下文。 */ public typeDeriva(ctx: SqlContext): SqlColumnType { return SqlColumnType.varchar; } /** * 計算節點的值。 * @param ctx 上下文。 */ public compute(ctx: SqlContext): any { return null; } }
詳細介紹一下:
value欄位,用於保存節點的值。SqlStringNode存的是類似 ‘abc’這樣的值,SqlNumber存的是類似 123 這樣的值,SqlSelectNode存的是 select。
line欄位,用於保存節點所在的行號。這個行號是從前一階段的詞法分析中得到的,就是token三元組的最後一個值。
nodes欄位,用於保存子節點。例如,SqlExpAddNode的value是 + 或 – ,它的nodes是兩個表達式節點,表示這個表達式的結果相加或相減。
compute方法,用於計算表達式的值。例如,id = 3,如果運行時id的值為3,則運行時返回True,否則返回False。再例如,a * 3,如果運行時a的值為10,則運行時返回30。
typeDeriva方法,用於類型推導。如果資料庫列id是number類型,那麼 id + 100 的結果也應該是numer類型;如果 id列是varchar類型,那麼 id + 100也是varchar類型。這就是類型推導。
類型推導非常重要,主要用於類型安全檢查。比如,count(*)的結果一定是numer類型,如果寫出 substr(count(*),1) 這樣的表達式,就應該給出語法錯誤。此外,類型推導還可以用於提前確定查詢結果集中每一列的類型,構造好結果集,以容納接下來返回的數據。比如,對於C#或Java,查詢資料庫後得到DataTable或RecordSet,可以獲取到每一列的類型資訊,這些類型資訊在正式查詢資料庫之前通過語法分析就已經得到了。
推導出的類型,理論上來說,應該跟compute方法返回的值,保持一致。
實現各個語法節點子類的時候,重點是重寫compute和typeDeriva這兩個方法。
接下來講如何構造這些語法節點。
有的節點具有明確的特徵,比如 select節點,以關鍵字SELECT開頭,只要掃描這個關鍵字,就可以認為是一條SELECT語句,然後按照SELECT語句的規則繼續往下掃描。
有的節點則不那麼容易判斷,具有二義性。
比如 減號 -,如果是 a – b,則表示相減;如果是a = -b,則表示負號。
再比如關鍵字 AND,如果是 a AND b,則表示條件與;如果是 a BETWEEN b AND c,則表示一個數值範圍或字元串範圍。
這種情況下,需要通過上下文分析、優先順序判斷、消除文法左遞歸的辦法,來消除二義性。
JSDB實現的只是SQL92的子集,SELECT語法如下:
select -> 'select' ['distinct'] fields [from] [where] [groupby] [having] [orderby] [limit]
fields -> field [',' field]*
insert -> 'insert' 'into' identity 'values' '(' identity [',' identity] * ')' 'values' params
update -> 'update' identity 'set' identity '=' exp_or [',' identity '=' exp_or]* [ where ]
delete -> 'delete' 'from' identity [ where ]
create_table -> 'create' 'table' identity '(' field_declare [',' field_declare] ')'
field_declare-> identity ('varchar' | 'number')
from -> 'from' table
field -> exp_or [['as'] identity]
table -> identity ['as' identity]
join -> ['left'] 'join' table 'on' exp_or
where -> 'where' exp_or
groupby -> 'group' 'by' exp_or [',' exp_or]*
having -> 'having ' [exp_or]
orderby -> 'order' 'by' order [',' order]*
order -> exp_or ['asc' | 'desc']
limit -> 'limit' exp_or [',' exp_or]
params -> '(' exp_or [',' exp_or]+ ')'
exp_or -> exp_or 'or' exp_and | exp_and
exp_and -> exp_and 'and' exp_eq | exp_eq
exp_eq -> exp_eq ('=' | '<>' | 'in' | 'not' 'in' | 'is' | 'is' 'not' | 'between' | 'like' | 'not' 'like') exp_rel | exp_rel
exp_rel -> exp_add ('<' | '<=' | '>' | '>=') exp_add | exp_add
exp_add -> exp_add ('+' | '-') exp_mult | exp_mult
exp_mul -> exp_mul ('*' | '/' | '%') exp_unary | exp_unary
exp_unary -> ('+' | '-' | 'not') exp_unary | factor
exp_ref -> identity '.' (identity | '*')
exp_func -> identity '(' exp_or [',' exp_or]* | empty) ')'
exp_case -> 'case' [exp_or] ['when' exp_or 'then' exp_or]+ ['else' exp_or] 'end'
exp_hold -> '?'
factor -> identity | string | number | bool | star | exp_hold | exp_ref | exp_func | exp_case | '(' exp_or ')'
identity -> ('_' | a-z | A-Z)['_' | a-z | A-Z | 0-9]*
star -> '*'
string -> ''' (*)* '''
number -> [0-9]+ ['.' [0-9]+]
bool -> 'true' | 'false'
null -> 'null'
由於簡化了SELECT語法,所以相對來說還算簡單。唯一有難度的地方,在於表達式的解析,採用的方法是抄自「龍書」《編譯原理》。
自上而下,根據優先順序,依次解析 exp_or、exp_and、exp_eq、exp_rel、exp_add、exp_mult、exp_unary、factor。
先看一個簡單點的方法,parseExpRefNode,用於解析類似 t.id 這樣的欄位引用表達式。
先嘗試解析第一個標識符,然後是一個分隔符點,最後是結尾的標識符。如果解析失敗,則添加一個SqlError。
public parseExpRefNode(parent: SqlNode): SqlExpRefNode { let beginToken = this.peekAndCheck(); if (!beginToken) { return null; } let beginIndex = this.pos; let node1 = this.parseIdentityNode(null); if (!node1) { this.moveTo(beginIndex); return null; } let dotToken = this.peek(); if (!dotToken || dotToken[0] != TK_DOT) { this.moveTo(beginIndex); return null; } let endToken = this.moveNext(); if (!endToken) { this.errors.push(new SqlError('語法錯誤:' + beginToken[1] + '後缺少引用項的名稱。', beginToken[2])); return null; } if (endToken[0] == TK_MUL || endToken[0] == TK_IDENTITY) { this.moveNext(); return new SqlExpRefNode(parent, beginToken[1] + dotToken[1] + endToken[1], beginToken[2]); } this.errors.push(new SqlError('語法錯誤:' + beginToken[1] + '後的引用項無效。', beginToken[2])); return null; }
接下來看parseExpOrNode、parseExpAndNode兩個方法,分別用於解析條件OR和AND的節點。由於函數是一層層調用進去的,所以,實際上的構造節點順序是反過來的,從factor開始,然後才依次是 unary、mult、add、rel、req、and、or 。
先是從左到右挨個解析,放到一個列表中,然後把列表中的元素轉換為一棵二叉樹,函數返回的是這棵二叉樹的根節點。
parseExpOrNode類:
public parseExpOrNode(parent: SqlNode): SqlExpOrNode { let beginToken = this.peekAndCheck(); if (!beginToken) { return null; } let node1 = this.parseExpAndNode(parent); if (this.errors.length > 0) { return null; } if (node1 == null) { if (this.errors.length == 0) { this.errors.push(new SqlError('詞法錯誤:解析邏輯或表達式失敗。', beginToken[2])); } return null; } let nodeList = [node1]; let opToken = this.peek(); while (opToken && opToken[0] == TK_OR) { let node = new SqlExpOrNode(parent, opToken[1], opToken[2]); nodeList.push(node); let node2Token = this.moveNext(); if (!node2Token) { this.errors.push(new SqlError('詞法錯誤:符號' + opToken[1] + "後面缺少表達式。", opToken[2])); return null; } let node2 = this.parseExpAndNode(parent); if (this.errors.length > 0) { return null; } if (!node2) { if (this.errors.length == 0) { this.errors.push(new SqlError('詞法錯誤:解析符號' + opToken[1] + "右側表達式失敗。", opToken[2])); } return null; } nodeList.push(node2); opToken = this.peek(); } if (nodeList.length % 2 == 0) { this.errors.push(new SqlError('詞法錯誤:邏輯或表達式數量錯誤。', opToken[2])); return null; } //把列錶轉換為二叉樹 let rootNode = null; for (let i in nodeList) { let node = nodeList[i]; if (!rootNode) { rootNode = node; } else if (node instanceof SqlExpOrNode) { this.setNodeParent(rootNode, node); rootNode = node; } else { this.setNodeParent(node, rootNode); } } if (parent && rootNode) { this.setNodeParent(rootNode, parent); } return rootNode; }
parseExpAndNode類:
public parseExpAndNode = function (parent): SqlExpAndNode { let beginToken = this.peekAndCheck(); if (!beginToken) { return null; } let node1 = this.parseExpEqNode(parent); if (this.errors.length > 0) { return null; } if (!node1) { this.errors.push(new SqlError('詞法錯誤:解析邏輯與表達式失敗。', beginToken[2])); return null; } let nodeList = [node1]; let opToken = this.peek(); while (opToken && opToken[0] == TK_AND) { let node = new SqlExpAndNode(parent, opToken[1], opToken[2]); nodeList.push(node); let node2Token = this.moveNext(); if (!node2Token) { this.errors.push(new SqlError('詞法錯誤:符號' + opToken[1] + "後面缺少表達式。", opToken[2])); return null; } let node2 = this.parseExpEqNode(parent); if (this.errors.length > 0) { return null; } if (!node2) { this.errors.push(new SqlError('詞法錯誤:解析符號' + opToken[1] + "右側表達式失敗。", opToken[2])); return null; } nodeList.push(node2); opToken = this.peek(); } if (nodeList.length % 2 == 0) { this.errors.push(new SqlError('詞法錯誤:邏輯與表達式數量錯誤。' + opToken[1] + "右側表達式失敗。", opToken[2])); return null; } //把列錶轉換為二叉樹 let rootNode = null; for (let i in nodeList) { let node = nodeList[i]; if (!rootNode) { rootNode = node; } else if (node instanceof SqlExpAndNode) { this.setNodeParent(rootNode, node); rootNode = node; } else { this.setNodeParent(node, rootNode); } } if (parent && rootNode) { this.setNodeParent(rootNode, parent); } return rootNode; }
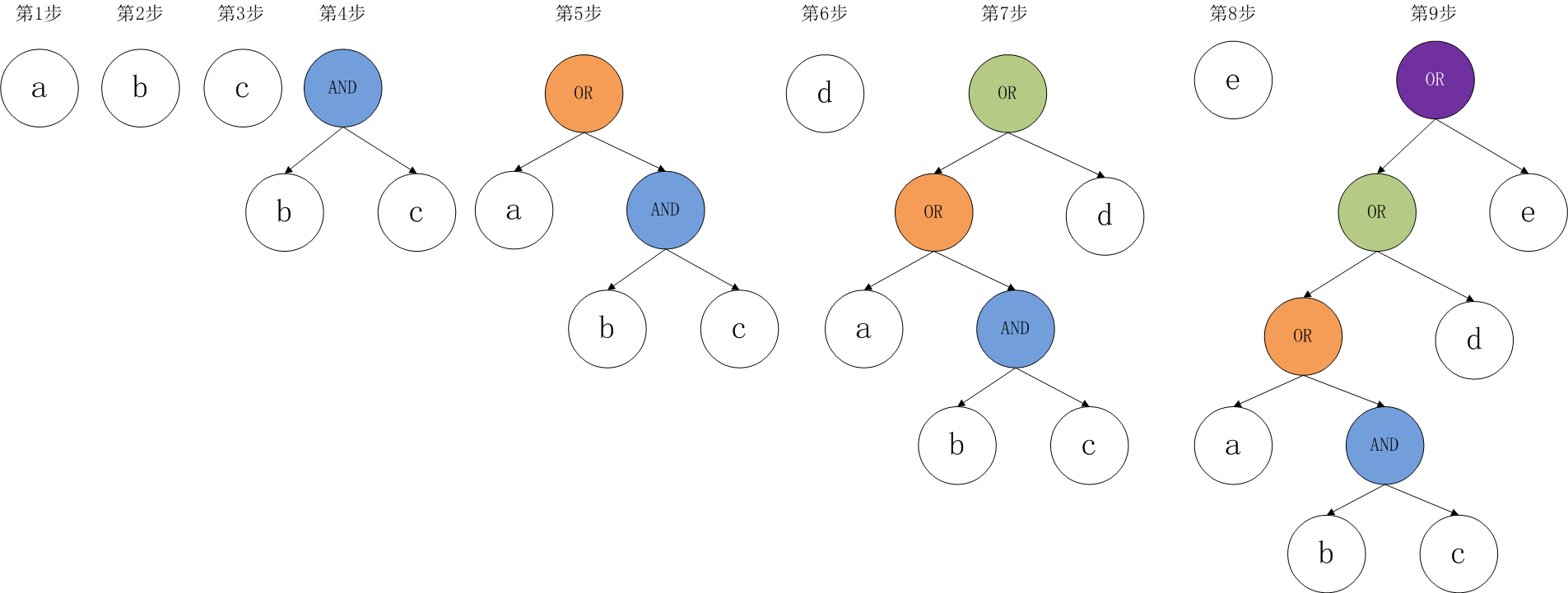
看著有點暈?沒關係,我畫一張圖,演示一下表達式 a OR b AND c OR d OR e 是如何轉換為二叉樹的。
測試程式碼:
Assert.runCase('parse exp', function () { let parser = new SqlParser("a OR b AND c OR d OR e"); let node = parser.parseExpOrNode(null); console.log(node.toString()); });
輸出如下二叉樹結構:
|--SqlExpOrNode@1:or
|--SqlExpOrNode@1:or
|--SqlExpOrNode@1:or
|--SqlIdentityNode@1:a
|--SqlExpAndNode@1:and
|--SqlIdentityNode@1:b
|--SqlIdentityNode@1:c
|--SqlIdentityNode@1:d
|--SqlIdentityNode@1:e
構造該二叉樹的步驟如下圖所示:
構造完抽象語法樹後,不用生成機器碼,直接在語法樹上計算。
第三章 計算語法樹
前面提到過,語法樹節點基類SqlNode里有一個compute方法,用於計算節點的值,子類會重寫該方法,實現具體的計算邏輯。
語法節點太多了,咱們只講幾個關鍵節點的計算邏輯:
SqlNumberNode類,根據value欄位的值是否有小數點,相應返回parseInt(this.value)或parseFloat(this,value)。
public compute(ctx: SqlContext): any { return this.value.indexOf('.') >= 0 ? parseFloat(this.value) : parseInt(this.value); }
SqlStringNode類,根據value欄位的值返回字元串,去掉首尾的單引號,如果有轉義符,要進行轉義。
public compute(ctx: SqlContext): any { if (!this.value) { return ''; } //處理字元串轉義 let s = ''; for (let i = 1; i < this.value.length - 1; i++) { let c = this.value[i]; if (c == '\\') {//escape c = this.value[++i]; if (c == 'r') { c = '\r'; } else if (c == 'n') { c = '\n'; } else if (c == 't') { c = '\t'; } s += c; } else { s += c; } } return s; }
SqlExpRelNode類,計算左右兩個子節點的值,比較其大小,返回True或False。
public compute(ctx: SqlContext): any { let left = this.nodes[0].compute(ctx); if (left instanceof SqlError) { return left; } let right = this.nodes[1].compute(ctx); if (right instanceof SqlError) { return right; } if (this.value == '>') { return left > right; } else if (this.value == '>=') { return left >= right; } else if (this.value == '<') { return left < right; } else if (this.value == '<=') { return left <= right; } return false; }
SqlExpAddNode類,計算左右兩個子節點的值,根據value欄位的值是 ‘+’ 還是 ‘-‘,相應執行相加或相減。
public compute(ctx: SqlContext): any { let left = this.nodes[0].compute(ctx); if (left instanceof SqlError) { return left; } let right = this.nodes[1].compute(ctx); if (right instanceof SqlError) { return right; } if (typeof left == 'number' && typeof right == 'number') { if (this.value == '+') { return left + right; } else if (this.value == '-') { return left - right; } } return null; }
SqlExpMulNode類,計算左右兩個子節點的值,根據value欄位的值是 ‘*’ 、’/’ 還是 ‘%’,相應執行相乘、相除、取余。
SqlExpAndNode類,計算左右兩個子節點的值,如果都為True,才返回True,否則返回False。
SqlExpOrNode類,計算左右兩個子節點的值,如果都為False,才返回False,否則返回True。
SqlExpUnaryNode類,一元操作符,只有一個節點,計算其值。根據操作符的值是’+’、’-‘、’not’,執行相應的取正、取負、取反邏輯。
SqlExpFuncNode類,執行函數。首先從SqlContext.standardFunctions欄位取一下,如果取到了,說明是標準函數,直接執行,否則再看是不是聚合函數。聚合函數的執行比較複雜,咱們單獨講。
SqlInsertNode類,執行插入邏輯,返回受影響行數。
SqlUpdateNode類,執行更新邏輯,返回受影響行數。
SqlDeleteNode類,執行刪除邏輯,返回受影響行數。
SqlSelectNode類,執行查詢邏輯,返回一個二維表SqlDataTable實例。這個最複雜,咱們接下來重點講。
其它語法節點的執行邏輯,請參見源程式碼。
接下來,重點講一下SqlSelectNode類和SqlExpFuncNode類的實現邏輯,也就是SELECT語句到底是怎麼實現數據查詢的,這貨老複雜了,燒了不少腦細胞,大夥一定要給個贊。
第四章 SELECT語句
一條SELECT語句的執行,可以分為如下幾個步驟:
1、根據 from 節點,以及可能存在的 join 節點,合併出一張寬表(fullTable)。這裡我沒有做任何優化,直接生成一個笛卡爾積,所以,測試的數據量千萬不要太大,否則,運行的速度夠你酸爽的~~~
//主表 let fromTableName = this.getFromTableNode().nodes[0].value; let fromTableAlias = this.getFromTableNode().value; if (fromTableAlias) { ctx.tableAliasMap[fromTableAlias] = fromTableName; ctx.tableAliasMap[fromTableName] = fromTableAlias; } let fromTable: SqlDataTable = ctx.database.tables[fromTableName]; if (!fromTable) { return new SqlError('不存在指定的主表:' + fromTableName, this.getFromTableNode().line); } let tableList = new Array<SqlDataTable>(); tableList.push(fromTable); //構造寬表的結構 let fullTable = new SqlDataTable('__full__'); for (let j = 0; j < fromTable.columnNames.length; j++) { let col = fromTable.getColumnByIndex(j); fullTable.addColumn((fromTableAlias ? fromTableAlias : fromTableName) + '.' + col.name, col.type); } let joinNodes = this.getJoinNodes(); for (let k = 0; k < joinNodes.length; k++) { let joinNode = joinNodes[k]; let joinTableNode = joinNode.nodes[0]; let joinTableName = joinTableNode.nodes[0].value; let joinTableAlias = joinTableNode.value; if (joinTableAlias && joinTableAlias == fromTableName) { return new SqlError('聯結表別名與主表名衝突。', joinTableNode.line); } if (joinTableAlias && joinTableAlias == fromTableAlias) { return new SqlError('聯結表別名與主表別名衝突。', joinTableNode.line); } if (!joinTableAlias && joinTableName == fromTableName) { return new SqlError('聯結表名與主表名衝突,必須指定別名。', joinTableNode.line); } if (!joinTableAlias && joinTableName == fromTableAlias) { return new SqlError('聯結表名與主表別名衝突,必須指定別名。', joinTableNode.line); } if (joinTableAlias) { ctx.tableAliasMap[joinTableAlias] = joinTableName; ctx.tableAliasMap[joinTableName] = joinTableAlias; } let joinTable: SqlDataTable = ctx.database.tables[joinTableName]; if (!joinTable) { return new SqlError('不存在指定的聯結表:' + joinTableName, joinTableNode.line); } for (let j = 0; j < joinTable.columnNames.length; j++) { let col = joinTable.getColumnByIndex(j); fullTable.addColumn((joinTableAlias ? joinTableAlias : joinTableName) + '.' + col.name, col.type); } tableList.push(joinTable); } //構造寬表的數據 let fullTableRowCount = tableList[0].rows.length; for (let i = 1; i < tableList.length; i++) { fullTableRowCount *= tableList[i].rows.length; } for (let i = 0; i < fullTableRowCount; i++) { fullTable.addDataRow(fullTable.newRow()); } if (fullTableRowCount > 0) { let joinTableRowCount = fullTableRowCount; let colStart = 0; for (let i = 0; i < tableList.length; i++) { let table = tableList[i]; joinTableRowCount /= table.rows.length; let rowIndex = 0; while (rowIndex < fullTableRowCount) { for (let j = 0; j < table.rows.length; j++) { for (let k = 0; k < joinTableRowCount; k++) { for (let m = 0; m < table.columnNames.length; m++) { fullTable.setValueByIndex(rowIndex, colStart + m, table.rows[j].values[m]); } if (i == 0) {//from table fullTable.rows[rowIndex].id = table.rows[j].id; } rowIndex++; } } } colStart += table.columnNames.length; } } ctx.dataTable = fullTable;
2、如果有 join節點,執行聯結規則。JSDB只支援 join 和 left join 這兩種最常用的聯結方式,其它聯結方式暫不支援。執行on條件節點,如果返回False,表示沒有join上,這時再判斷是join還是left join,如果是join,就直接刪除;如果是left join,就填上null值。
不太好理解的是repeatJoinRows這個欄位,這是為了處理重複join的問題。比如,from表有一條記錄,外鍵ID對應一個 join表中的兩條記錄,也就是說,join表存在id重複的情況。針對這種情況,需要把重複join的數據也保留下來。
//join篩選 if (joinNodes.length > 0) { let filteredRowIndexSet = []; for (let i = fullTable.rows.length - 1; i >= 0; i--) { ctx.rowIndex = i; let joinFaildCount = 0; for (let k = 0; k < joinNodes.length; k++) { let joinNode = joinNodes[k]; let joinTableNode = joinNode.nodes[0]; let joinOnNode = joinNode.nodes[1]; let v = joinOnNode.compute(ctx); if (v instanceof SqlError) { return v; } if (v != true) { if (joinNode.value == 'join') { joinFaildCount = joinNodes.length + 1;//must be deleted } else {//left join joinFaildCount++; } //沒join上的欄位設置為null值 for (let j = 0; j < fullTable.columnNames.length; j++) { let colTableName = fullTable.columnNames[j].split('.')[0]; if (colTableName == joinTableNode.value || colTableName == joinTableNode.nodes[0].value) { fullTable.setValueByIndex(i, j, null); } } } } let rid = fullTable.rows[i].id; if (typeof filteredRowIndexSet[rid] == 'undefined') { filteredRowIndexSet[rid] = {rowIndex: i, failures: joinFaildCount, repeatJoinRows: []}; } else if (joinFaildCount < filteredRowIndexSet[rid].failures) { filteredRowIndexSet[rid].rowIndex = i; filteredRowIndexSet[rid].failures = joinFaildCount; } else if (joinFaildCount == 0) { if (filteredRowIndexSet[rid].failures == 0) { filteredRowIndexSet[rid].repeatJoinRows.push(fullTable.rows[i]); } else { filteredRowIndexSet[rid].rowIndex = i; filteredRowIndexSet[rid].failures = joinFaildCount; } } } //刪除未join上的行 for (let i = fullTable.rows.length - 1; i >= 0; i--) { let r = filteredRowIndexSet[fullTable.rows[i].id]; if (r.failures > joinNodes.length) { fullTable.deleteRow(i); continue; } if (r.rowIndex == i) { continue; } let needDelete = true; for (let k = 0; k < r.repeatJoinRows.length; k++) { if (r.repeatJoinRows[k] == fullTable.rows[i]) { needDelete = false; break; } } if (needDelete) { fullTable.deleteRow(i); } } }
3、如果有 where 節點,執行篩選規則。就是執行SqlWhereNode節點,不符合條件的記錄,直接刪除。
//where篩選 let whereExpNode = this.getWhereExpNode(); if (whereExpNode) { for (let i = fullTable.rows.length - 1; i >= 0; i--) { ctx.rowIndex = i; if (whereExpNode) { let v = whereExpNode.compute(ctx); if (v instanceof SqlError) { return v; } if (v != true) { fullTable.deleteRow(i); } } } }
4、如果有 group by 節點,則執行分組規則。這個最複雜,分為以下幾個步驟:
4.1 首先要提取出 fields、having、orderby 這三個節點中的聚合表達式。
4.2 根據 group by的節點,以及上一步得到的聚合表達式列表,構造一張分組計算中間表,寫入上下文中,後面聚合函數計算時會用到。
4.3 遍歷寬表fullTable,計算分組中間表的值,得到分組中間表groupByMidTable。這段程式碼不好理解,實際邏輯是在SqlExpFuncNode類中。為了遍歷一次就能算出所有聚合表達式的值,我封裝了一個SqlGroupByValue類,該類用於記錄一個聚合表達式的當前最新的count行數、sum匯總、distinctValues去重值列表,以及當前最新值,這個當前最新值可以是行數、匯總,也可以是最大值、最小值、平均值,取決於具體的聚合函數。所以,一定要注意,普通SqlDataTable的單元值是string或number,但是分組中間表的單元值是SqlGroupByValue。
4.4 基於分組中間表groupByMidTable,根據fields節點進行計算,得到結果表resultTable。為什麼要再算一遍?因為,對於 count(*) * 10 這樣的表達式,在4.3小節中實際只計算了count(*),乘以10的步驟是在這裡計算的。另外,並不是所有聚合表達式都是要返回的,有些聚合表達式是在having或order節點中出現的,並不在fields節點中,所以,必須在這一步中集中處理一下。
//分組 let groupByNode = this.getGroupByNode(); let havingNode = this.getHavingNode(); let orderByNode = this.getOrderByNode(); //找出用到的所有聚合表達式 let funcNodeList: SqlExpFuncNode[] = []; for (let j = 0; j < fieldNodes.length; j++) { this.loadAggregateFunctions(fieldNodes[j], funcNodeList); } if (havingNode) { this.loadAggregateFunctions(havingNode, funcNodeList); } if (orderByNode) { this.loadAggregateFunctions(orderByNode, funcNodeList); } let funcNodeCount = 0; for (let m in funcNodeList) { funcNodeCount++; } if (groupByNode || funcNodeCount > 0) { //構造分組中間表 let t = new SqlDataTable('__group__'); if (groupByNode) { for (let k = 0; k < groupByNode.nodes.length; k++) { let gNode = groupByNode.nodes[k]; let col = t.addColumn(gNode.toSql(), gNode.typeDeriva(ctx)); if (col) { col.node = gNode; } } } for (let i in funcNodeList) { let fNode = funcNodeList[i]; let col = t.addColumn(fNode.toSql(), fNode.typeDeriva(ctx)); if (col) { col.node = fNode; } } ctx.groupByMidTable = t; //計算分組中間表的數據 for (let i = 0; i < fullTable.rows.length; i++) { ctx.rowIndex = i; for (let j = 0; j < t.columnNames.length; j++) { let col = t.getColumnByIndex(j); let expNode = col.node; let v = expNode.compute(ctx); if (v instanceof SqlError) { return v; } } } ctx.isGroupByMidTableFinished = true; ctx.dataTable = ctx.groupByMidTable; //計算結果表的數據 for (let i = 0; i < ctx.dataTable.rows.length; i++) { ctx.rowIndex = i; if (havingNode) { let hv = havingNode.compute(ctx); if (hv instanceof SqlError) { return hv; } if (hv != true) { continue; } } let rowValues = []; for (let j = 0; j < fieldExpNodes.length; j++) { let fNode = fieldExpNodes[j]; let fCol = ctx.dataTable.getColumnByName(fNode.toSql()); if (fCol) { let fVal = ctx.dataTable.rows[i].values[fCol.index]; if (fVal instanceof SqlGroupByValue) { fVal = fVal.value; } rowValues.push(fVal); } else { let v = fNode.compute(ctx); if (v instanceof SqlError) { return v; } rowValues.push(v); } } resultTable.addRow(rowValues); } }
涉及的函數表達式,尤其是聚合函數表達式,計算程式碼如下:
public compute(ctx: SqlContext): any { let fnName = this.value; let isDistinct = this.nodes.length > 1 && this.nodes[0] instanceof SqlModifiersNode && this.nodes[0].nodes[0].value == 'distinct'; let paramNodes = isDistinct ? this.nodes[1].nodes : (this.nodes.length > 0 ? this.nodes[0].nodes : []); // // 執行非聚合函數 // if (!this.isAggregate()) { let fn = ctx.standardFunctions['_' + fnName]; if (!fn) { return new SqlError('不存在指定的函數:' + fnName, this.line); } //計算實參的值 let fnArgs = []; for (let i = 0; i < paramNodes.length; i++) { let v = paramNodes[i].compute(ctx); if (v instanceof SqlError) { return v; } fnArgs.push(v); } return fn(fnArgs); } // // 執行聚合函數 // //檢查分組中間表 let t: SqlDataTable = ctx.groupByMidTable; if (!t) { return new SqlError('分組中間表未初始化。', this.line); } let k = this.toSql(); let col = t.getColumnByName(k); if (!col) { return new SqlError('分組中間表中不存在指定的聚合列:' + k, this.line); } //檢查分組中間表是否已完成,如果已完成,則可以直接取值 if (ctx.isGroupByMidTableFinished) { let gv: SqlGroupByValue = t.getValueByIndex(ctx.rowIndex, col.index); return gv ? gv.value : null; } //分組中間表還沒有完成,需要繼續計算 let fnArgs = []; for (let i = 0; i < paramNodes.length; i++) { let pNode = paramNodes[i]; let v = null; if (pNode instanceof SqlStarNode) { v = 1;// TODO: 這裡應該改為判斷該行所有列是否都不為null } else { v = pNode.compute(ctx); } if (v instanceof SqlError) { return v; } fnArgs.push(v); } if (fnArgs.length != 1) { return new SqlError('函數' + fnName + '的參數個數錯誤。', this.line); } let v = fnArgs[0]; if (v == null) { return null; } //分組的中間數據行 let groupByNode = ctx.selectNode.getGroupByNode(); let groupByExpNodes = groupByNode ? groupByNode.nodes : []; let groupByValues = []; for (let i = 0; i < groupByExpNodes.length; i++) { let bv = groupByExpNodes[i].compute(ctx); if (bv instanceof SqlError) { return bv; } groupByValues.push(bv); } let r = t.addDataRow(new SqlDataRow(groupByValues, false)); //分組計算 let gv: SqlGroupByValue = r.values[col.index]; if (!gv) { gv = new SqlGroupByValue(); r.values[col.index] = gv; } if (fnName == 'count') { if (isDistinct) { v = v + ''; if (!gv.distinctValues[v]) { gv.distinctValues[v] = 1; gv.value = gv.value == null ? 1 : gv.value + 1; } } else { gv.value = gv.value == null ? 1 : gv.value + 1; } } else if (fnName == 'sum') { gv.value = gv.value == null ? v : v + gv.value; } else if (fnName == 'max') { if (gv.value == null || v > gv.value) { gv.value = v; } } else if (fnName == 'min') { if (gv.value == null || v < gv.value) { gv.value = v; } } else if (fnName == 'avg') { gv.sum += v; gv.count++; gv.value = gv.sum / gv.count; } return null; }
5、如果沒有 group by 節點,直接在where篩選後的fullTable上根據fields節點進行計算,得到結果表resultTable。這個就簡單很多了。
//計算結果表的數據 for (let i = 0; i < ctx.dataTable.rows.length; i++) { ctx.rowIndex = i; let rowValues = []; for (let j = 0; j < fieldExpNodes.length; j++) { let v = fieldExpNodes[j].compute(ctx); if (v instanceof SqlError) { return v; } rowValues.push(v); } resultTable.addRow(rowValues); }
6、如果有 order by 節點,則對結果表resultTable進行排序。由於排序規則可能包含多個條件,這裡要分為三個步驟來計算:
6.1 遍歷resultTable表,每一行數據都得到一個orderByValues數組,包含了排序要用的值。如果是多個排序條件,數組就包含多個值。
6.2 計算每個排序條件的方向,默認是asc。
6.3 根據排序表達式的值,以及排序方向,對數據行進行排序。這裡調用的是Array類的sort方法,傳入一個function,實現自定義排序。
//排序 if (orderByNode && orderByNode.nodes.length > 0) { //計算每一行的排序值 let rows = resultTable.rows; for (let i = 0; i < rows.length; i++) { ctx.rowIndex = i; let row = rows[i]; for (let m = 0; m < orderByNode.nodes.length; m++) { let oVal = orderByNode.nodes[m].nodes[0].compute(ctx); if (oVal instanceof SqlError) { return oVal; } row.orderByValues.push(oVal); } } //計算每個排序項的方向 let directions: boolean[] = []; for (let k = 0; k < orderByNode.nodes.length; k++) { directions.push(orderByNode.nodes[k].value == 'desc'); } //對數據行進行排序 rows.sort(function (a: SqlDataRow, b: SqlDataRow) { let m = 0; while (m < directions.length) { if (a.orderByValues[m] == b.orderByValues[m]) { m++; } else { if (directions[m]) {//desc return a.orderByValues[m] < b.orderByValues[m] ? 1 : -1; } else { return a.orderByValues[m] > b.orderByValues[m] ? 1 : -1; } } } return 0; }); }
7、如果有 limit 節點,則返回指定範圍的數據,也就是分頁時要用的東西。如果是limit n,則返回前面n行數據;如果是limit m, n,則從第m行開始,返回n行數據的。
let limitNode = this.getLimitNode(); if (limitNode) { let limitNums = []; for (let i = 0; i < limitNode.nodes.length; i++) { let v = limitNode.nodes[i].compute(ctx); if (v instanceof SqlError) { return v; } if (typeof v != 'number') { return new SqlError('無效的limit值:' + v, limitNode.line); } limitNums.push(v); } if (limitNums.length == 1) { let end = limitNums[0]; if (resultTable.rows.length > end) { resultTable.rows.splice(end, resultTable.rows.length - end); } } else if (limitNums.length == 2) { let begin = limitNums[0]; let end = limitNums[0] + limitNums[1] - 1; resultTable.rows.splice(end + 1, resultTable.rows.length - end - 1); resultTable.rows.splice(0, begin); } }
到這裡就得到最終的結果表了。
相對於SELECT語句,其它語句就簡單多了。
第五章 其它語句
DELETE語句的執行分為兩步:執行where篩選,然後根據row.id進行刪除。
public compute(ctx: SqlContext): any { let tableName = this.nodes[0].nodes[0].value; let table: SqlDataTable = ctx.database.tables[tableName]; if (!table) { return new SqlError('不存在指定的表:' + tableName, this.line); } ctx.dataTable = table; let deletedCount = 0; if (this.nodes.length >= 2) { for (let i = table.rows.length - 1; i >= 0; i--) { ctx.rowIndex = i; ctx.holdIndex = -1; let v = this.nodes[1].compute(ctx); if (v instanceof SqlError) { return v; } if (v) { table.deleteRow(i); deletedCount++; } } } else { deletedCount = table.rows.length; table.rows = []; } return deletedCount; }
UPDATE語句也分為兩步:執行where篩選,然後set規則更新指定列的數據。
public compute(ctx: SqlContext): any { let tableName = this.nodes[0].nodes[0].value; let table: SqlDataTable = ctx.database.tables[tableName]; if (!table) { return new SqlError('不存在指定的表:' + tableName, this.line); } ctx.dataTable = table; let updateCols = []; let updateValueNodes = []; for (let j in this.nodes[1].nodes) { let setNode = this.nodes[1].nodes[j]; let colName = setNode.nodes[0].value; let col = table.getColumnByName(colName); if (!col) { return new SqlError('不存在指定的列:' + colName, setNode.nodes[0].line); } updateCols.push(col); updateValueNodes.push(setNode.nodes[1]); } let updateRowIndexList = []; if (this.nodes.length == 2) { for (let i = 0; i < table.rows.length; i++) { updateRowIndexList.push(i); } } else if (this.nodes.length == 3) { for (let i = 0; i < table.rows.length; i++) { ctx.rowIndex = i; ctx.holdIndex = -1; let whereValue = this.nodes[2].compute(ctx); if (whereValue instanceof SqlError) { return whereValue; } if (whereValue) { updateRowIndexList.push(i); } } } for (let i in updateRowIndexList) { ctx.rowIndex = updateRowIndexList[i]; ctx.holdIndex = -1; for (let j in updateCols) { let col = updateCols[j]; let v = updateValueNodes[j].compute(ctx); if (v instanceof SqlError) { return v; } table.setValueByIndex(ctx.rowIndex, col.index, v); } } return updateRowIndexList.length; }
INSERT語句也分為兩步:根據表構造創建一個空行,然後更新指定列的數據。
public compute(ctx: SqlContext): any { let tableName = this.nodes[0].value; let table = ctx.database.tables[tableName]; if (!table) { return new SqlError('不存在指定的表:' + tableName, this.line); } let fieldsNodes = this.nodes[1].nodes; let valuesNodes = this.nodes[2].nodes; let row = table.newRow(); ctx.holdIndex = -1; for (let j = 0; j < fieldsNodes.length; j++) { let colName = fieldsNodes[j].value; let colIndex = table.getColumnByName(colName).index; let valueNode = valuesNodes[j]; let v = valueNode.compute(ctx); if (v instanceof SqlError) { return v; } row.values[colIndex] = v; } table.addDataRow(row); return 1; }
CREATE TABLE語句,在 SqlDatabase 中創建一個新的 SqlDataTable 實例。
public compute(ctx: SqlContext): any { let table = new SqlDataTable(this.nodes[0].value); let paramsNode = this.nodes[1]; let columnNames = []; for (let i = 0; i < paramsNode.nodes.length; i++) { let fieldDeclareNode = paramsNode.nodes[i]; let colName = fieldDeclareNode.value; let colType = fieldDeclareNode.nodes[0].value; if (columnNames.indexOf(colName) >= 0) { return new SqlError('列名重複:' + colName, fieldDeclareNode.line); } table.addColumn(colName, colType); columnNames.push(fieldDeclareNode); } return ctx.database.addTable(table); }
至此,幾個主要的語句都介紹了。
最後,我們寫幾個測試範例,展示一下運行結果,這幾個測試範例,在文章開頭的「體驗頁面」上都有展示。
第六章 程式展示
通過JS創建三張表:t_gender(性別字典表)、t_dept(部門字典表)、t_staff(員工表)。
var database = new SqlDatabase(); database.execute("create table t_gender(id number, name varchar(100))"); database.execute("create table t_dept(dept_id number, dept_name varchar)"); database.execute("create table t_staff(id varchar, name varchar, gender number, dept_id number)"); database.execute("insert into t_gender(id, name)values(1, 'Male')"); database.execute("insert into t_gender(id, name)values(2, 'Female')"); database.execute("insert into t_dept(dept_id, dept_name)values(101, 'Tech')"); database.execute("insert into t_dept(dept_id, dept_name)values(102, 'Finance')"); database.execute("insert into t_staff(id, name, gender, dept_id)values('016001', 'Jack', 1, 102)"); database.execute("insert into t_staff(id, name, gender, dept_id)values('016002', 'Bruce', 1, null)"); database.execute("insert into t_staff(id, name, gender, dept_id)values('016003', 'Alan', null, 101)"); database.execute("insert into t_staff(id, name, gender, dept_id)values('016004', 'Hellen', 2, 103)"); database.execute("insert into t_staff(id, name, gender, dept_id)values('016005', 'Linda', 2, 101)"); database.execute("insert into t_staff(id, name, gender, dept_id)values('016006', 'Royal', 3, 104)");
然後準備幾條範例sql,方便大家執行查詢,也可以自己寫一個新的sql。
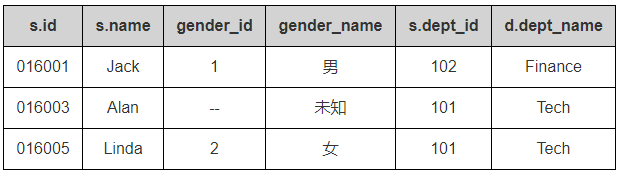
SELECT s.id, s.name, ifnull(s.gender, '--') AS gender_id, /*處理空值*/ (CASE g.name WHEN 'Male' THEN '男' WHEN 'Female' THEN '女' ELSE '未知' END) AS gender_name, s.dept_id, d.dept_name FROM t_staff s LEFT JOIN t_gender g ON g.id=s.gender LEFT JOIN t_dept d ON d.dept_id=s.dept_id WHERE d.dept_name IS NOT NULL LIMIT 3
執行結果:
文章到這裡就結束了,歡迎大家指正,多給Star,多給贊 ^_^
