TensorFlow如何提高GPU訓練效率和利用率
- 2019 年 11 月 10 日
- 筆記
前言
首先,如果你現在已經很熟悉tf.data+estimator了,可以把文章x掉了╮( ̄▽ ̄””)╭
但是!如果現在還是在進行session.run(..)的話!尤其是苦惱於GPU顯示記憶體都塞滿了利用率卻上不去的童鞋,這篇文章或許可以給你打開新世界的大門噢( ̄∇ ̄)
如果發現經過一系列改良後訓練效率大大提高了,記得回來給小夕發小紅包( ̄∇ ̄)
不過,這並不是一篇怒貼一堆程式碼,言(三)簡(言)意(兩)賅(語)就結束的CSDN文風的文章。。。所以伸手黨們也可以X掉了╮( ̄▽ ̄””)╭
緣起
很早很早之前,在小夕剛接觸tensorflow和使用GPU加速計算的時候,就產生過一個疑惑。為什麼顯示卡的顯示記憶體都快滿了,GPU利用率還顯示這麼低呢?好浪費呀,但是又無可奈何。當時GPU利用率100%的情況基本是僅存於一塊顯示卡塞4、5個不費顯示記憶體的小任務的情況。
在比較極端的情況下,甚至GPU的利用率會降到10%以下,就像這樣:

而大部分情況下寫出來的程式碼train起來後是這樣的:

可以看到,雖然顯示卡的顯示記憶體都塞滿了,但是顯示卡功率(最左邊那一欄,114W和69W)和利用率(最右邊那一欄,35%和38%)卻遠遠沒有達到極限。大部分人的想法是,算了算了這不重要,我去做實驗了再見【wei笑】
然而!如果你在做大型實驗,train一次跑幾天呢?這個細節會極大的影響你的實驗效率和DDL到來前的實驗次數!想一下,完全一樣的model和設置,你的程式碼要train一周,然而隔壁老王只需要train三天╮( ̄▽ ̄””)╭
路人甲:我有256張顯示卡
小夕:好了這篇文章你可以X掉了
那麼,我們有沒有可能一直這樣呢:
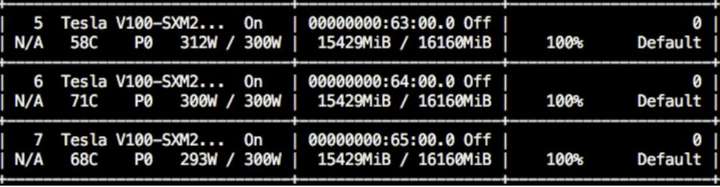
是不是這功率和利用率看起來不可思議!不要懷疑這是PS的圖!這只是小夕的日常截圖!tricks用的好GPU利用率掉不下來99%,然鵝程式碼寫的足夠蠢,也可以上不去5%!
那麼問題來了,到底是什麼導致的這個差異呢?
不要急,我們來放大一下那些gpu利用率只有30%幾的程式碼在訓練時的gpu利用率的變化情況(好像句子有點長
watch -n 0.1 nvidia-smi
ps:(可能掉幀太嚴重了看著不連貫╮( ̄▽ ̄””)╭,建議在自己的機器上試一下,會直觀的多~)
看!是不是一下子就發現問題啦?可以看到,其實gpu利用率並不是一直在比較低的水平,而是很有規律的周期性的從0漲到接近100再跌到0,再重新漲到100再跌回0。如果同時開著列印日誌的窗口,你就會發現這個周期恰好跟每個訓練step的時長一致!也就是說,在每個step,其實有一些時間並沒有花在GPU里,那當然就是花在cpu里啦。
那在cpu里幹什麼的呢?當然就是load下一個batch、預處理這個batch以及在gpu上跑出結果後列印日誌、後處理、寫summary甚至保存模型等,這一系列的花銷都要靠cpu去完成。回顧一下我們常寫的程式碼:
create_graph() create_model_saver() create_summary_writer() create_session() do_init() for i in range(num_train_steps): load_batch(...) # cpu preprocess(...) # cpu feed_dict = {...} # cpu fetch_list = [...] # cpu buf = session.run(fetch_list, feed_dict) # gpu postprocess(buf) # cpu print(...) # cpu if i % x == 0: summary_writer.write(...) # cpu if i % xx == 0: model_saver.save(...) # cpu
看,尤其是preprocess(…)任務比較重的話就容易導致程式碼在cpu里也要跑好一段時間,gpu利用率自然就會上不去而且呈現周期性變化啦。
那麼有沒有什麼辦法降低cpu時間,提高gpu時間呢?
一個很自(愚)然(蠢)的想法就是把一切訓練程式碼都用tf的api重寫不就好啦,甚至最外層的那個for i in range(num_train_steps)其實都可以用tf.while_loop重寫呀。嗯,小夕還真的這麼嘗試過,然後發現

TF api這特喵的都是些什麼鬼!各種跟numpy和python內置函數重名卻行為不一致是什麼鬼!卧槽這個api少了個參數我該怎麼辦?python里就一行程式碼就能搞定的事情我為什麼寫了幾十行??

所以除了函數式編程的大牛,小夕極力的不建議重蹈覆轍!尤其是我們這些遇到彙編會哭,看到Lisp會崩潰的90後小仙女!
所以沒辦法把整個train loop都描述進計算圖了?
別怕別怕,好在後來其實tensorflow已經封裝了一個特別好(多)用(坑)的上層API來把整個train loop都能輕鬆的封裝在計算圖中,從而實現超級高的GPU利用率和訓練效率!
Estimator
不用管它為啥叫Estimator,只需要知道,它把我們剛才想做的事情基本都給封裝好了就行。把剛才的那個經典的寫法搬過來
1. create_model() 2. create_model_saver() 3. create_summary_writer() 4. create_session() 5. do_init() 6. for i in range(num_train_steps): 7. load_batch(...) # cpu 8. preprocess(...) # cpu 9. feed_dict = {...} # cpu 10. fetch_list = [...] # cpu 11. buf = session.run(fetch_list, feed_dict) # gpu 12. postprocess(buf) # cpu 13. print(...) # cpu 14. if i % x == 0: 15. summary_writer.write(...) # cpu 16. if i % xx == 0: 17. model_saver.save(...) # cpu
1-5行在estimator中都封裝好啦,你只需要把相關配置塞進estimator的RunConfig就可以啦~
7-9行也封裝好啦,你只需要把數據集載入和預處理的相關程式碼的函數塞給estimator.train的input_fn~
第10行也封裝好啦,你只需要把要fetch的loss、train_op丟進estimator的EstimatorSpec~
第11行也封裝好啦,你只需要把描述模型計算圖的函數塞給estimator的model_fn~
第12-13行不用操心細節了,global_step和loss自動完成了,剩下的丟給tf.Print和LoggingTensorHook吧~
第14-17行不用你寫了,自動完成了
╮(╯▽╰)╭
經過這麼一頓折騰,我們發現GPU利用率大大提高啦~直逼80%甚至90%。那麼還有沒有可以壓榨的空間呢?
其實這時仔細一分析就會發現雖然estimator把大部分的程式碼寫進計算圖裡了,但是從數據的載入和預處理依然是在cpu里串列進行呀,而且比如一個batch有128個樣本,那麼estimaor內部在run每個step的時候還是要等著這128個樣本串列的處理完才行。這顯然就是最後的瓶頸啦!有沒有辦法消除掉呢?·當然有,那就是
tf.data
TF的dataset API可以說讓人又愛又恨了,它確實看似提供了一種把整個預處理都搬進計算圖進行並行化處理的途徑,但是!如果你真的完全用tensorflow API來做複雜的預處理的話,真的會讓人瘋掉的QAQ因此,這裡在用tf.data之前,小夕極力的建議先把數據集儘可能的transform成預處理後的樣子,包括做分詞、做截斷、做word2id等,不過padding和input_mask可以留在TF裡面做,畢竟都只需要一行。
那做完這些預處理後,數據該怎麼存儲會更方便後續的讀取和處理呢?最最最建議的方式還是使用tf.records來存儲,磁碟、記憶體的存儲和IO效率都會相比傳統方式更快一些,x和y也不用分開了。當然這樣的唯一的壞處就是不能直接打開看數據集╮( ̄▽ ̄””)╭畢竟數據集被做成了二進位文件。
但是實在比較懶不想用tf.record的話,那麼小夕極力建議把x和y分開存儲,並且盡量讓tf.data在讀取數據的時候做完上面的那些必要的預處理,以避開難用的字元串基礎操作API並且減輕訓練時的cpu和記憶體壓力。
tf.data還有一個很大的好處就是可以很天然的支援以streaming的方式讀取數據,這樣在面對大數據集時就不會發生數據load完後發現顯示卡被占的尷尬事件了╮( ̄▽ ̄””)╭
好像講了這麼久,還是沒講怎麼用tf.data加速QAQ,來來來進入正題啦。
想想哈,沒用tf.data的時候,我們寫出來的程式碼實際跑起來就是這個樣子的:
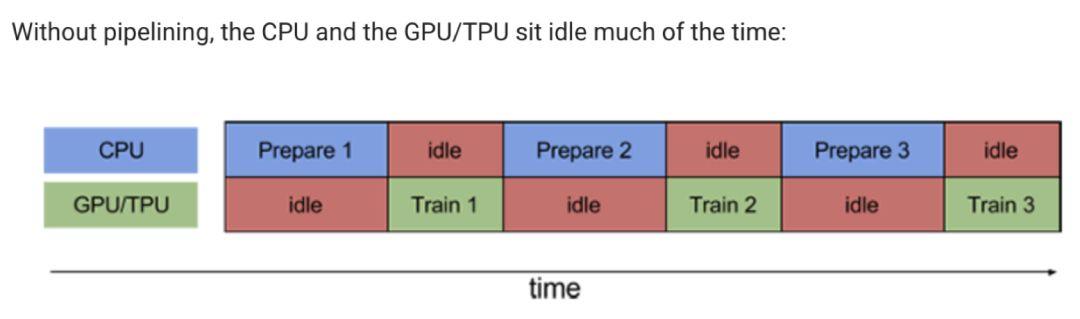
這也是文章開頭小夕解釋的為什麼gpu利用率上不去並且周期性變化的重要原因。那麼我們可以不可以消除idle,像下面這樣讓prepare和train的過程並行進行呢?
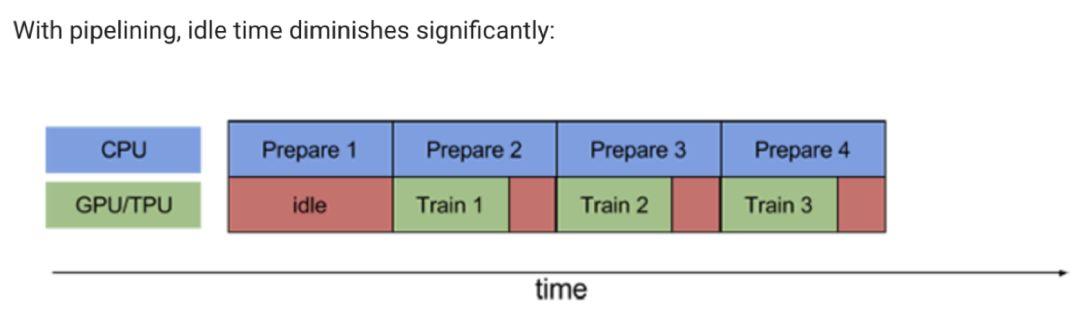
當然可以!那就是
prefetch
從prefetch的意思就可以理解,那就是預先獲取下一個step要load的batch。使用tf.data裡面的叫做prefetch的神奇api就可以輕鬆完成啦,這個api里的參數buffer_size就是講的是額外的fetch多少份,比如buffer_size=1,然後我們要prefetch的是batch的話,那麼模型每次prepare完一個batch後,就會自動再額外的prepare一個batch,這樣下一個train step到來的時候就可以直接從記憶體中取走這個事先prepare好的batch啦。(詳情見後面)
等下,看上圖的話,有木有發現,如果prepare一個batch耗時很短的話確實兩全齊美,但是如果耗時比較久,尤其一下子prefetch好幾個batch的話,一旦prepare的用時超過了train一個step的用時,那麼每個train step的性能就會受限於prepare的效率啦。放大一下這個問題的話如下圖所示
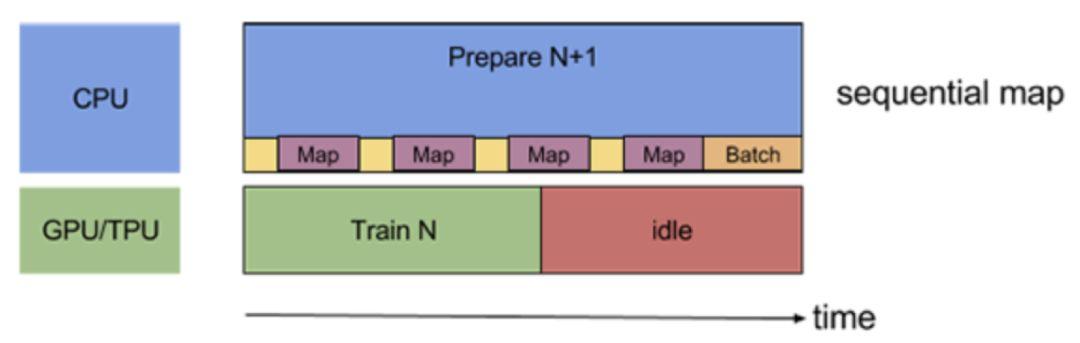
看,prepare用時太久反而會導致train完一個step後gpu空閑了(雖然其實下個step的batch可能已經prepare好了)
那麼能不能確保prepare階段的用時小於train階段的用時呢?
parallel mapping
一個很簡單的想法當然就是讓樣本並行處理啦~如果batch size是128,prefetch size=1,那麼準備一個batch要串列的跑128*2=256次的預處理,但是如果我們開4個執行緒去跑,是不是就看起來快多啦。幸運的是我們也不用自己手擼多執行緒了,tf.data.Dataset在map(預處理)函數里有一個參數num_parallel_calls,給這個參數賦值就可以並行parse啦。如圖,
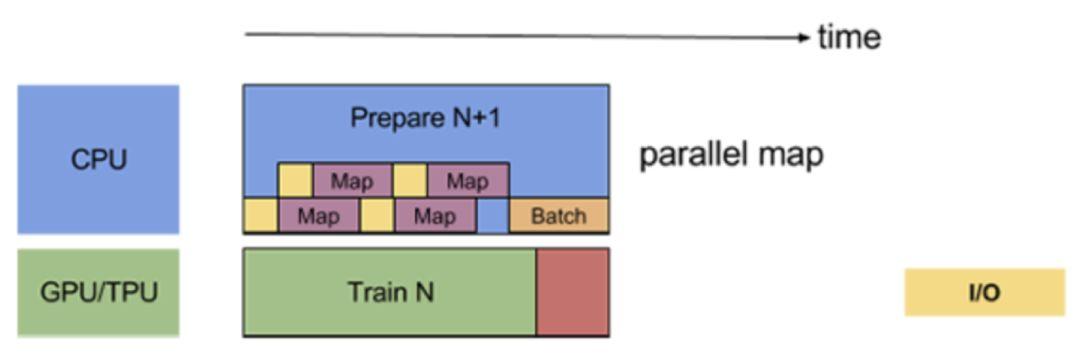
這樣的話只要prefetch的buffer_size和map的num_parrellel_calls取得合適,基本就可以實現不間斷的train啦,也就是幾乎達到100%的GPU利用率!
好啦,思想明白了,程式碼就容易理解啦。不使用tf.record,直接從預處理好的純文本格式的數據集load數據時的典型過程如下
def build_input(..): x = tf.data.XXDataset(..) x = x.map(..., num_parallel_calls=N) # parellel y = tf.data.XXDataset(..) y = y.map(..., num_parallel_calls=N) dataset = tf.data.Dataset.zip((x, y)) dataset = dataset.repeat(num_epochs) if is_train: dataset = dataset.shuffle(..) dataset = dataset.batch(batch_size) dataset = dataset.prefetch(buffer_size=1) # prefetch iterator = dataset.make_xx_iterator() return iterator.get_next()
當然,如果用上tf.record後,就不用分別從x和y倆文件中讀數據啦,感興趣的童鞋可自行去了解一下。
補充福利
當然,剛從傳統的程式碼遷移到tf.data+estimator的時候可能會不太適應,最主要的還是debug的方式,不能像之前一樣直接session.run(debug_tensor)了,那怎麼辦呢?
一般來說我們列印tensor有兩種情況,一種是計算圖出錯時需要列印一次或幾次來定位問題,一種是像global_step,loss等需要周期性check。對於這兩種情況,之前是習慣session.run的時候把要列印的tensor也run出來,而現在這兩種情況可以區分對待啦。
對於第一種,小夕感覺最高效的還是直接在計算圖裡插tf.Print(..),使用非常方便,debug能力很強大!如果列印還需要配合global step,加一條tf.cond就搞定啦。對於第二種,其實global step和loss的話estimator默認就會列印出來,如果是其他需要周期性列印的tensor,那麼就用tf.train.LoggingTensorHook包裝一下然後丟進estimator.train里吧~習慣之後竟然還感覺挺方便的m(_ _)m
最後,願天下沒有空閑的顯示卡

關注【OpenCV與AI深度學習】
長按或者掃描下面二維碼即可關注



