(數據科學學習手札70)面向數據科學的Python多進程簡介及應用
- 2019 年 11 月 8 日
- 筆記
本文對應腳本已上傳至我的
Github倉庫https://github.com/CNFeffery/DataScienceStudyNotes
一、簡介
進程是電腦系統中資源分配的最小單位,也是作業系統可以控制的最小單位,在數據科學中很多涉及大量計算、CPU密集型的任務都可以通過多進程並行運算的方式大幅度提升運算效率從而節省時間開銷,而在Python中實現多進程有多種方式,本文就將針對其中較為易用的幾種方式進行介紹。
二、利用multiprocessing實現多進程
multiprocessing是Python自帶的用於管理進程的模組,通過合理地利用multiprocessing,我們可以充分榨乾所使用機器的CPU運算性能,在multiprocessing中實現多進程也有幾種方式。
2.1 Process
Process是multiprocessing中最基礎的類,用於創建進程,先來看看下面的示例:
single_process.py
import multiprocessing import datetime import numpy as np import os def job(): print(f'進程{os.getpid()}開始計算:', datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')) for j in range(100): _ = np.sum(np.random.rand(10000000)) print(f'進程{os.getpid()}結束運算:', datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')) if __name__ == '__main__': process = multiprocessing.Process(target=job) process.start()
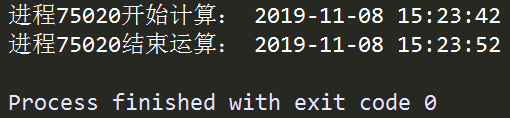
在上面的例子中,我們首先定義了函數job(),其連續執行一項運算任務100次,並在開始和結束的時刻列印該進程對應的pid,用來唯一識別一個獨立的進程,接著利用Process()將一個進程實例化,其主要參數如下:
target: 需要執行的運算函數
args: target函數對應的傳入參數,元組形式傳入
在process創建完成之後,我們對其調用.start()方法執行運算,這樣我們就實現了單個進程的創建與使用,在此基礎上,我們將上述例子多執行緒化:
multi_processes.py
import multiprocessing import datetime import numpy as np import os def job(): print(f'進程{os.getpid()}開始計算:', datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')) for j in range(100): _ = np.sum(np.random.rand(10000000)) print(f'進程{os.getpid()}結束運算:', datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')) if __name__ == '__main__': process_list = [] for i in range(multiprocessing.cpu_count() - 1): process = multiprocessing.Process(target=job) process_list.append(process) for process in process_list: process.start() for process in process_list: process.join()
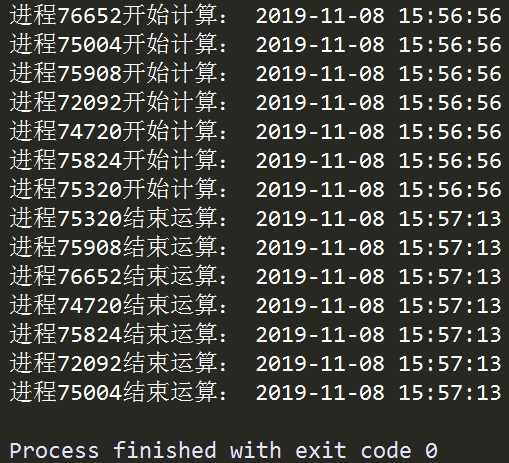
在上面的例子中,我們首先初始化用於存放多個執行緒的列表process_list,接著用循環的方式創建了CPU核心數-1個進程並添加到process_list中,再接著用循環的方式將所有進程逐個激活,最後使用到.join()方法,這個方法用於控制進程之間的並行,如下例:
join_demo.py
import multiprocessing import os import datetime import time def job(): print(f'進程{os.getpid()}開始:', datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')) time.sleep(5) print(f'進程{os.getpid()}結束:', datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')) if __name__ == '__main__': process1 = multiprocessing.Process(target=job) process2 = multiprocessing.Process(target=job) process1.start() process1.join() process2.start() process2.join() print('='*200) process3 = multiprocessing.Process(target=job) process4 = multiprocessing.Process(target=job) process3.start() process4.start() process3.join() process4.join()
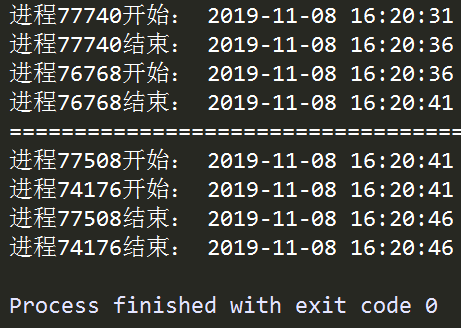
觀察對應進程執行的開始結束時間資訊可以發現,一個進程對象在.start()之後,若在其他的進程對象.start()之前調用.join()方法,則必須等到先前的進程對象運行結束才會接著執行.join()之後的非.join()的內容,即前面的進程阻塞了後續的進程,這種情況下並不能實現並行的多進程,要想實現真正的並行,需要現行對多個進程執行.start(),接著再對這些進程對象執行.join(),才能使得各個進程之間相互獨立,了解了這些我們就可以利用Process來實現多進程運算;
2.2 Pool
除了上述的Process,在multiprocessing中還可以使用Pool來快捷地實現多進程,先來看下面的例子:
Pool_demo.py
from multiprocessing import Pool import numpy as np from pprint import pprint def job(n): return np.mean(np.random.rand(n)), np.std(np.random.rand(n)) if __name__ == '__main__': with Pool(5) as p: pprint(p.map(job, [i**10 for i in range(1, 6)]))
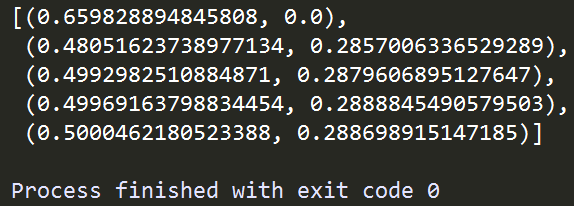
在上面的例子中,我們使用Pool這個類,將自編函數job利用.map()方法作用到後面傳入序列每一個位置上,與Python自帶的map()函數相似,不同的是map()函數將傳入的函數以串列的方式作用到傳入的序列每一個元素之上,而Pool()中的.map()方法則根據前面傳入的並行數量5,以多進程並行的方式執行,大大提升了運算效率。
三、利用joblib實現多進程
與multiprocessing需要將執行運算的語句放置於含有if name == ‘main‘:的腳本文件中下不同,joblib將多進程的實現方式大大簡化,使得我們可以在IPython互動式環境下中靈活地使用它,先看下面這個例子:
from joblib import Parallel, delayed import numpy as np import time import datetime def job(i): start = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S') time.sleep(5) end = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S') return start, end result = Parallel(n_jobs=5, verbose=1)(delayed(job)(j) for j in range(5)) result
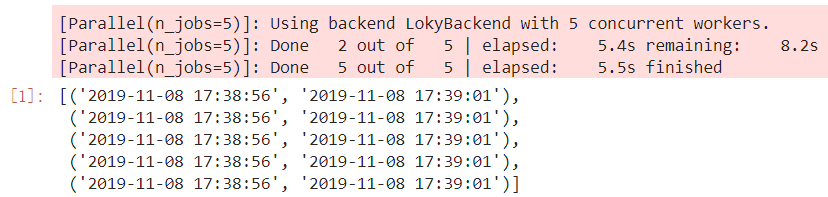
在上面的例子中,我們從joblib中導入Parallel和delayed,僅用Parallel(n_jobs=5, verbose=1)(delayed(job)(j) for j in range(5))一句就實現了並行運算的功能,其中n_jobs控制並行進程的數量,verbose參數控制是否列印進程運算過程,如果你熟悉scikit-learn,相信這兩個參數你一定不會陌生,因為scikit-learn中RandomForestClassifier等可以並行運算的演算法都是通過joblib來實現的。
以上就是本文的全部內容,如有筆誤望指出!

